Comprendre les phases des pipelines
Les pipelines vous permettent d’automatiser les étapes de votre processus de déploiement. Votre processus peut inclure plusieurs groupes logiques de travaux que vous voulez exécuter. Dans cette unité, vous allez découvrir les phases des pipelines et comment les utiliser pour ajouter des processus de contrôle qualité à vos déploiements Bicep.
Qu’est-ce que les phases des pipelines ?
Les phases vous aident à diviser votre pipeline en plusieurs blocs logiques. Chaque phase peut contenir un ou plusieurs travaux. Les travaux contiennent une liste ordonnée d’étapes qui doivent être effectuées, comme exécuter des scripts en ligne de commande.
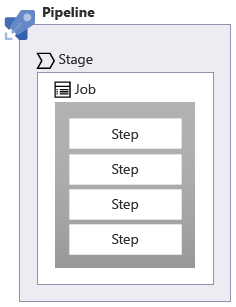
Les phases peuvent être utilisées dans votre pipeline pour marquer une séparation des problématiques. Par exemple, quand vous travaillez avec du code Bicep, la validation du code est un problème distinct du déploiement de votre fichier Bicep. Quand vous utilisez un pipeline automatisé, la génération et le test de votre code sont souvent appelés intégration continue (CI). Le déploiement de code dans un pipeline automatisé est souvent appelé déploiement continu (CD).
Dans les phases CI, vous vérifiez la validité des modifications apportées à votre code. Les phases CI fournissent une assurance qualité. Elles peuvent être exécutées sans impacter votre environnement de production actif.
Dans de nombreux langages de programmation, le code doit être généré pour que quelqu’un puisse l’exécuter. Quand un fichier Bicep est déployé, il est converti, ou transpilé, de Bicep en JSON. Les outils effectuent ce processus automatiquement. Dans la plupart des cas, vous n’avez pas besoin de transformer manuellement le code Bicep en modèles JSON dans votre pipeline. Nous utilisons néanmoins toujours le terme d’intégration continue quand nous parlons du code Bicep, car les autres parties de l’intégration continue s’appliquent toujours, comme la validation de votre code.
Une fois que vos phases CI ont été exécutées avec succès, vous êtes plus confiant quant à la réussite du déploiement de vos modifications. Dans les phases CD, vous déployez votre code sur chacun de vos environnements. Vous commencez en général par des environnements de test ou d’autres environnements hors production, puis vous passez aux environnements de production. Dans ce module, nous allons déployer sur un seul environnement. Dans un prochain module, vous apprendrez à étendre votre pipeline de déploiement pour déployer le code sur plusieurs environnements, comme des environnements hors production et des environnements de production.
Les phases s’exécutent en séquence. Vous pouvez contrôler comment et quand chaque phase s’exécute. Par exemple, vous pouvez configurer vos phases CD pour qu’elles s’exécutent seulement après l’exécution réussie de vos phases CI. Vous pouvez aussi avoir plusieurs phases CI qui doivent s’exécuter en séquence, par exemple générer votre code, puis le tester. Vous pouvez aussi inclure une phase de restauration appelée rollback qui s’exécute uniquement en cas d’échec des phases de déploiement précédentes.
« Shift Left »
En utilisant des phases, vous pouvez vérifier la qualité de votre code avant de le déployer. Ces phases sont parfois appelées décalage vers la gauche.
Imaginez une chronologie des activités que vous effectuez quand vous écrivez du code. La chronologie commence par les phases de planification et de conception. Elle continue ensuite par les phases de génération et de test. Vous finissez par les phases de déploiement et de support de votre solution.
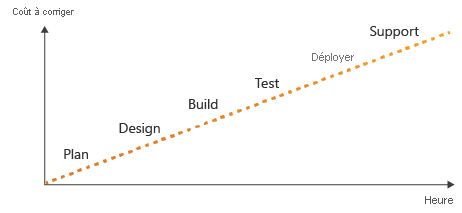
Une règle bien établie dans le développement logiciel est que plus tôt vous identifiez une erreur dans le processus (c’est-à-dire à une étape la plus à gauche dans la chronologie), plus il est facile et rapide de la corriger et moins cela vous coûte cher. Plus vous identifiez tardivement une erreur dans le processus, plus il est difficile de la résoudre.
L’objectif est donc de décaler la découverte des problèmes vers la gauche du diagramme précédent. Tout au long de ce module, vous verrez comment ajouter davantage de validation et de tests à votre pipeline à mesure qu’il progresse.
Vous pouvez même ajouter la validation avant le début de votre déploiement. Quand vous utilisez des outils comme Azure DevOps, les demandes de tirage (pull requests) représentent généralement les modifications qu’un membre de votre équipe veut apporter au code sur votre branche principale. Il est utile de créer un autre pipeline qui exécute automatiquement vos étapes CI pendant le processus de revue de la demande de tirage. Cette technique vous aide à vérifier que le code fonctionne toujours, même avec les modifications proposées. Si la validation réussit, vous pouvez avoir une certaine confiance dans le fait que la modification n’entraîne pas de problèmes une fois fusionnée avec votre branche principale. Si la vérification échoue, vous savez qu’il y a davantage de travail à effectuer avant que la demande de tirage soit prête pour la fusion.
Important
La validation et les tests automatisés sont efficaces seulement dans la mesure où les tests que vous écrivez le sont. Il est important de prendre en compte les éléments à tester et les étapes à effectuer pour garantir un déploiement correct.
Définir une phase de pipeline
Chaque pipeline contient au moins une phase. Si votre pipeline n’a qu’une seule phase, vous n’avez pas besoin de la définir explicitement. Azure Pipelines le fait automatiquement pour vous. Quand vous avez plusieurs phases dans un pipeline, vous devez définir chacune d’elles. Les phases s’exécutent dans la séquence que vous spécifiez.
Imaginez que vous avez créé un fichier Bicep que vous devez déployer deux fois : une fois sur l’infrastructure aux États-Unis et une fois sur l’infrastructure en Europe. Avant de déployer, vous validez votre code Bicep. Voici une illustration d’un pipeline multiphase qui définit ce processus :
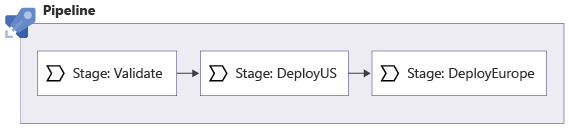
Notez que cet exemple comporte trois phases. La phase Validation est similaire à une phase CI. Ensuite, les phases de déploiement Deploy US et Deploy Europe s’exécutent. Chaque phase déploie le code dans l’un des environnements.
Voici comment les phases sont définies dans un fichier YAML de pipeline :
stages:
- stage: Test
jobs:
- job: Test
- stage: DeployUS
jobs:
- job: DeployUS
- stage: DeployEurope
jobs:
- job: DeployEurope
Contrôler la séquence des phases
Par défaut, les phases s’exécutent dans l’ordre que vous définissez. Une phase s’exécute uniquement si la phase précédente a réussi. Vous pouvez ajouter des dépendances entre les phases pour changer l’ordre.
En reprenant l’exemple précédent, imaginez que vous voulez exécuter les deux déploiements en parallèle, comme ceci :
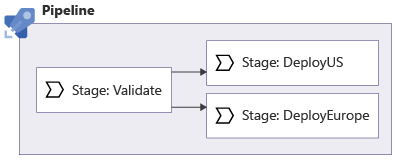
Vous pouvez spécifier les dépendances entre les phases en utilisant le mot clé dependsOn :
stages:
- stage: Test
jobs:
- job: Test
- stage: DeployUS
dependsOn: Test
jobs:
- job: DeployUS
- stage: DeployEurope
dependsOn: Test
jobs:
- job: DeployEurope
Quand vous utilisez le mot clé dependsOn, Azure Pipelines attend que la phase dépendante se termine correctement avant de commencer la phase suivante. Si Azure Pipelines détecte que toutes les dépendances pour plusieurs phases ont été satisfaites, il peut exécuter ces phases en parallèle.
Notes
En réalité, les phases et les travaux s’exécutent en parallèle uniquement s’il y a suffisamment d’agents pour exécuter plusieurs travaux en même temps. Quand vous utilisez des agents hébergés par Microsoft, il peut être nécessaire d’acheter des travaux parallèles supplémentaires pour y parvenir.
Parfois, vous voulez exécuter une phase quand une phase précédente échoue. Par exemple, voici un pipeline différent. Si le déploiement échoue, une phase de restauration appelée Rollback s’exécute immédiatement après :
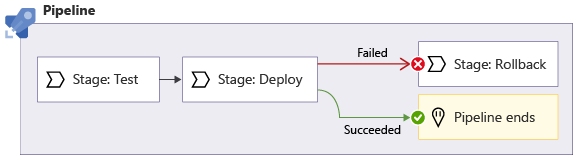
Vous pouvez utiliser le mot clé condition pour spécifier une condition qui doit être remplie avant qu’une phase s’exécute :
stages:
- stage: Test
jobs:
- job: Test
- stage: Deploy
dependsOn: Test
jobs:
- job: Deploy
- stage: Rollback
condition: failed('Deploy')
jobs:
- job: Rollback
Dans l’exemple précédent, quand tout se passe bien, Azure Pipelines exécute d’abord la phase Validate, puis il exécute la phase Deploy. Il ignore la phase Restauration. Cependant, si la phase Déploiement échoue, Azure Pipelines exécute la phase Restauration. Vous allez en découvrir davantage sur la restauration plus loin dans ce module.
Chaque travail s’exécute sur un nouvel agent. Cela signifie que chaque travail commencera à partir d’un environnement propre. Par conséquent, dans chaque travail, la première étape consiste généralement à extraire le code source.
Phases de déploiement Bicep
Un pipeline de déploiement Bicep classique contient plusieurs phases. À mesure que le pipeline progresse dans les phases, l’objectif est de devenir de plus en plus confiant que les étapes ultérieures vont réussir. Voici les phases courantes pour un pipeline de déploiement Bicep :

- Lint (linting) : utilisez le linter Bicep pour vérifier que le fichier Bicep est bien formé et ne contient pas d’erreurs évidentes.
- Validate (validation) : utilisez le processus de validation préalable d’Azure Resource Manager pour détecter les problèmes qui peuvent se produire quand vous déployez.
- Preview (prévisualisation) : utilisez la commande de simulation pour valider la liste des modifications qui seront appliquées à votre environnement Azure. Demandez à une personne de vérifier manuellement les résultats de la simulation et approuvez le pipeline pour continuer.
- Deploy (déploiement) : soumettez votre déploiement à Resource Manager et attendez qu’il se termine.
- Smoke Test (test de détection de fumée) : exécutez les vérifications post-déploiement de base sur certaines des ressources importantes que vous avez déployées. Ces vérifications sont appelées tests de détection de fumée d’infrastructure.
Votre organisation peut avoir une séquence de phases différente, ou vous devrez peut-être intégrer vos déploiements Bicep dans un pipeline qui déploie d’autres composants. Une fois que vous avez compris le fonctionnement des phases, vous pouvez concevoir un pipeline répondant à vos besoins.
Tout au long de ce module, vous allez en découvrir davantage sur les phases listées ici et vous allez créer progressivement un pipeline qui inclut chaque phase. Vous allez aussi découvrir :
- Comment les pipelines arrêtent le processus de déploiement si quelque chose d’inattendu se produit dans une des phases précédentes.
- Comment configurer votre pipeline pour qu’il s’interrompe jusqu’à ce que vous ayez vérifié manuellement ce qui s’est produit dans une phase précédente.