Réseaux neuronaux convolutifs
Bien que vous puissiez utiliser des modèles d’apprentissage profond pour n’importe quel type de Machine Learning, ils sont particulièrement utiles pour traiter les données qui se composent de grands tableaux de valeurs numériques, comme des images. Les modèles Machine Learning qui fonctionnent avec des images sont la base d’une intelligence artificielle appelée vision par ordinateur, et les techniques d’apprentissage profond ont été responsables de la conduite d’avancées étonnantes dans ce domaine au cours des dernières années.
Au cœur du succès de deep learning dans ce domaine est un type de modèle appelé réseau neuronal convolutionnel, ou CNN. Un CNN fonctionne généralement en extrayant des fonctionnalités d’images, puis en alimentant ces fonctionnalités dans un réseau neuronal entièrement connecté pour générer une prédiction. Les couches d’extraction de caractéristiques du réseau ont pour effet de réduire le nombre de caractéristiques de l'ensemble potentiellement énorme de valeurs de pixels individuels à un ensemble de caractéristiques plus petit qui prend en charge la prédiction d’étiquette.
Couches dans un réseau CNN
Les CNN se composent de plusieurs couches, chacune effectuant une tâche spécifique dans l'extraction de caractéristiques ou la prédiction d'étiquettes.
Couches de convolution
L’un des types de couche principal est une couche convolutionnelle qui extrait des fonctionnalités importantes dans les images. Une couche convolutionnelle fonctionne en appliquant un filtre aux images. Le filtre est défini par un noyau qui se compose d’une matrice de valeurs de poids.
Par exemple, un filtre 3x3 peut être défini comme suit :
1 -1 1
-1 0 -1
1 -1 1
Une image est également simplement une matrice de valeurs de pixels. Pour appliquer le filtre, vous la superposez sur une image et calculez une somme pondérée des valeurs de pixels d’image correspondantes sous le noyau de filtre. Le résultat est ensuite affecté à la cellule centrale d'un bloc 3x3 équivalent dans une nouvelle matrice de valeurs ayant la même taille que l'image. Par exemple, supposons qu’une image de 6 x 6 a les valeurs de pixel suivantes :
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
L'application du filtre à la zone 3x3 en haut à gauche de l'image se fait comme suit :
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Le résultat est affecté à la valeur de pixel correspondante dans la nouvelle matrice comme suit :
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Le filtre est maintenant déplacé (convolué), généralement en utilisant une taille de pas de 1 (donc en se déplaçant d’un pixel vers la droite), et la valeur du pixel suivant est calculée.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Nous pouvons donc maintenant remplir la valeur suivante de la nouvelle matrice.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Le processus se répète jusqu'à ce que nous ayons appliqué le filtre sur tous les ensembles de 3x3 pixels de l'image pour produire une nouvelle matrice de valeurs, cela ressemble à ceci :
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
En raison de la taille du noyau de filtre, nous ne pouvons pas calculer les valeurs des pixels à la périphérie ; nous appliquons donc généralement une valeur de remplissage (souvent 0) :
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
La sortie de la convolution est généralement transmise à une fonction d’activation, qui est souvent une fonction d’unité linéaire rectifiée (ReLU) qui garantit que les valeurs négatives sont définies sur 0 :
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
La matrice résultante est une carte de caractéristiques de valeurs de caractéristiques qui peut être utilisée pour entraîner un modèle Machine Learning.
Remarque : Les valeurs de la carte de fonctionnalités peuvent être supérieures à la valeur maximale d’un pixel (255), par conséquent, si vous souhaitez visualiser la carte de fonctionnalités en tant qu’image, vous devez normaliser les valeurs de fonctionnalité comprises entre 0 et 255.
Le processus de convolution est illustré dans l’animation ci-dessous.

- Une image est passée à la couche convolutionnelle. Dans ce cas, l’image est une forme géométrique simple.
- L’image est composée d’un tableau de pixels avec des valeurs comprises entre 0 et 255 (pour les images de couleur, il s’agit généralement d’un tableau à 3 dimensions avec des valeurs pour les canaux rouges, verts et bleus).
- Un noyau de filtre est généralement initialisé avec des pondérations aléatoires (dans cet exemple, nous avons choisi des valeurs pour mettre en évidence l’effet qu’un filtre peut avoir sur les valeurs de pixels ; mais dans un VRAI CNN, les pondérations initiales seraient généralement générées à partir d’une distribution gaussienne aléatoire). Ce filtre sera utilisé pour extraire une carte de fonctionnalités à partir des données d’image.
- Le filtre est appliqué à l’ensemble de l’image, en calculant les valeurs des caractéristiques en appliquant une somme des poids multiplié par leurs valeurs de pixel correspondantes à chaque position. Une fonction d’activation d’unité linéaire rectifiée (ReLU) est appliquée pour garantir que les valeurs négatives sont définies sur 0.
- Après la convolution, le mappage de caractéristiques contient les valeurs de caractéristique extraites, qui mettent souvent en évidence les attributs visuels clés de l’image. Dans ce cas, la carte de fonctionnalités met en surbrillance les bords et les angles du triangle dans l’image.
En règle générale, une couche convolutionnelle applique plusieurs noyaux de filtre. Chaque filtre produit une carte de caractéristiques différente, et toutes les cartes de fonctionnalités sont transmises à la couche suivante du réseau.
Couches de regroupement
Après avoir extrait des valeurs de caractéristiques à partir d’images, les couches de regroupement (ou d’échantillonnage inférieur) sont utilisées pour réduire le nombre de valeurs de fonctionnalité tout en conservant les fonctionnalités de différenciation clés qui ont été extraites.
L’un des types les plus courants de regroupement est le regroupement maximal dans lequel un filtre est appliqué à l’image, et seule la valeur maximale de pixels dans la zone de filtre est conservée. Par exemple, appliquer un noyau de regroupement 2x2 à la partie suivante d’une image produirait le résultat 155.
0 0
0 155
Notez que l’effet du filtre de regroupement 2x2 consiste à réduire le nombre de valeurs comprises entre 4 et 1.
Comme pour les couches convolutionnelles, les couches de regroupement fonctionnent en appliquant le filtre sur l’ensemble de la carte des caractéristiques. L’animation ci-dessous montre un exemple de regroupement maximal pour une carte d’images.

- La carte de caractéristiques extraite par un filtre dans une couche convolutionnelle contient un tableau de valeurs de caractéristiques.
- Un noyau de regroupement est utilisé pour réduire le nombre de valeurs de fonctionnalités. Dans ce cas, la taille du noyau est 2x2. Elle produit donc un tableau avec un quart du nombre de valeurs de caractéristiques.
- Le noyau de regroupement est convolué sur le plan des fonctionnalités, en conservant uniquement la valeur de pixel la plus élevée à chaque position.
Suppression de couches
L’un des défis les plus difficiles dans un réseau CNN est d’éviter le surajustement, où le modèle résultant fonctionne bien avec les données d’entraînement, mais n’est pas bien généralisé aux nouvelles données sur lesquelles il n’a pas été entraîné. Une technique que vous pouvez utiliser pour atténuer le surajustement consiste à inclure des couches où le processus d'entraînement supprime de façon aléatoire des cartes de caractéristiques. Cela peut sembler contre-intuitif, mais il s’agit d’un moyen efficace de s’assurer que le modèle n’apprend pas à être sur-dépendant des images d’entraînement.
D’autres techniques que vous pouvez utiliser pour atténuer le surajustement incluent le glissement aléatoire, la mise en miroir ou la réduction des images d’entraînement pour générer des données qui varient entre les époques d’entraînement.
Aplatir les couches
Après avoir utilisé des couches convolutionnelles et de regroupement pour extraire les caractéristiques saillantes dans les images, les mappages de caractéristiques résultants sont des tableaux multidimensionnels de valeurs de pixels. Une couche d'aplatissement est utilisée pour aplatir les cartes de caractéristiques en un vecteur de valeurs qui peut être utilisé comme entrée pour une couche entièrement connectée.
Couches entièrement connectées
En règle générale, un CNN se termine par un réseau entièrement connecté dans lequel les valeurs de fonctionnalité sont passées dans une couche d’entrée, via une ou plusieurs couches masquées, et génèrent des valeurs prédites dans une couche de sortie.
Une architecture CNN de base peut ressembler à ceci :
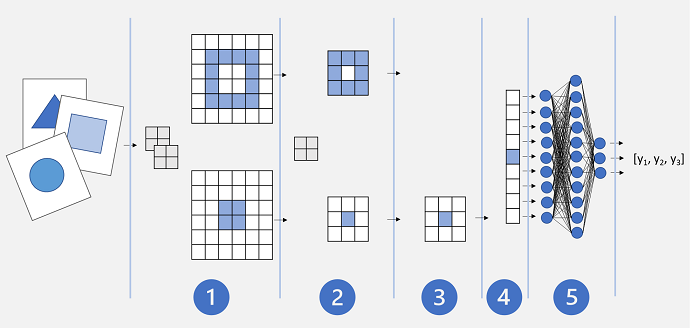
- Les images sont transmises dans une couche convolutionnelle. Dans ce cas, il existe deux filtres. Chaque image produit donc deux mappages de caractéristiques.
- Les mappages de fonctionnalités sont passés à une couche de regroupement, où un noyau de regroupement 2x2 réduit la taille des mappages de fonctionnalités.
- Une couche de suppression supprime de façon aléatoire certains mappages de fonctionnalités afin d’empêcher le surajustement.
- Une couche d’aplatissement prend les tableaux de cartes de fonctionnalités restants et les aplatit dans un vecteur.
- Les éléments vectoriels sont alimentés dans un réseau entièrement connecté, ce qui génère les prédictions. Dans ce cas, le réseau est un modèle de classification qui prédit les probabilités pour trois classes d’images possibles (triangle, carré et cercle).
Formation d’un modèle CNN
Comme avec n’importe quel réseau neuronal profond, un CNN est formé en passant des lots de données d’apprentissage à travers elle sur plusieurs époques, en ajustant les pondérations et les valeurs de biais en fonction de la perte calculée pour chaque époque. Dans le cas d’une CNN, la rétropropagation des pondérations ajustées comprend les pondérations de noyau de filtre utilisées dans les couches convolutionnelles ainsi que les poids utilisés dans les couches entièrement connectées.