Diagnostiquer les problèmes en examinant les configurations et les métriques
La supervision des performances d’Azure Load Balancer peut donner un avertissement précoce des éventuelles défaillances. Azure Monitor fournit de nombreuses métriques importantes que vous utilisez pour examiner la tendance des performances de Load Balancer. Vous pouvez également déclencher des alertes si une ou plusieurs machines virtuelles échouent aux requêtes de la sonde d’intégrité.
Dans l’exemple de scénario, vous supervisez les performances du système à charge équilibrée pour vérifier que les performances sont conformes aux exigences. Si les performances dévient et que les connexions aux machines virtuelles commencent à échouer, vous dépannez le système pour déterminer la cause du problème et le corriger. À la fin de cette unité, vous êtes en mesure de :
- Décrire les métriques disponibles pour mesurer le débit et les performances d’un système à charge équilibrée.
- Utiliser la page Resource Health du portail Azure pour superviser l’intégrité de votre système.
- Expliquer comment résoudre les problèmes courants dans un système à charge équilibrée.
Utiliser Azure Monitor pour résoudre les problèmes de Load Balancer
Avec Azure Monitor, vous pouvez capturer et examiner des journaux de diagnostic et des données de performances pour Load Balancer.
Superviser la connectivité
Vous pouvez visualiser des métriques pour Load Balancer dans le volet Métriques du portail Azure. Pour résoudre les problèmes de connectivité, les métriques les plus importantes sont Disponibilité du chemin des données et État de la sonde d’intégrité.

Load Balancer teste constamment la disponibilité du chemin pour l’adresse IP front-end, par le biais des règles d’équilibrage de charge et du pool de back-ends pour les applications qui s’exécutent sur vos machines virtuelles. Ces informations sont enregistrées sous forme de métrique Disponibilité du chemin des données. L’application de la métrique Moy indique la disponibilité moyenne d’un intervalle de temps donné. Cette agrégation est une valeur comprise entre 0 (aucune disponibilité) et 100, où au moins un chemin est disponible à partir de l’adresse IP front-end sur une machine virtuelle du pool back-end.
La métrique État de la sonde d’intégrité est similaire, mais elle s’applique uniquement à la sonde d’intégrité pour les machines virtuelles, plutôt qu’au chemin complet par le biais de Load Balancer. Là encore, l’agrégation Moyenne pour cet indicateur de performance fournit une valeur comprise entre 0 (aucune machine virtuelle n’est saine et ne parvient à répondre) et 100, où toutes les machines virtuelles répondent à la sonde d’intégrité.
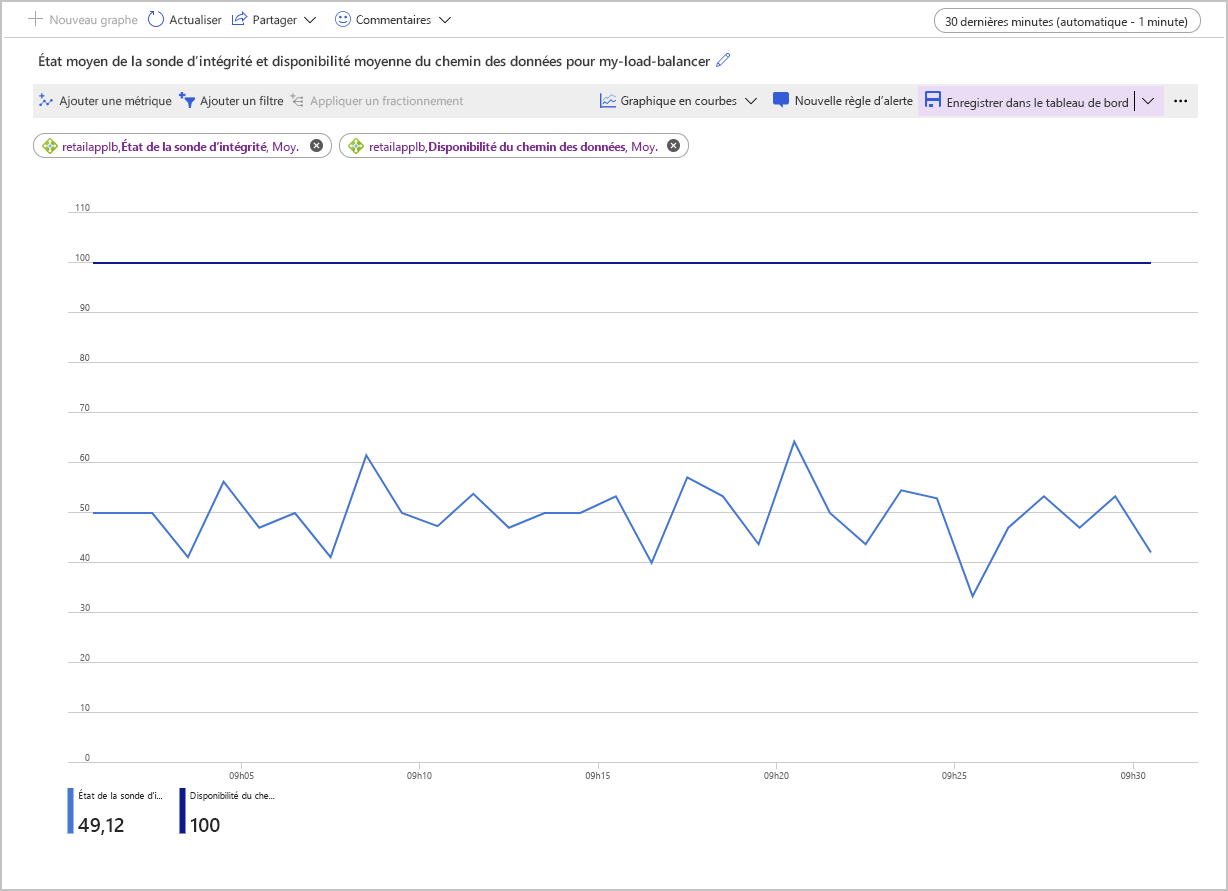
La capture d’écran suivante montre le graphique de la disponibilité moyenne du chemin des données et de l’état moyen de la sonde d’intégrité pour un équilibreur de charge doté de deux machines virtuelles dans le pool de back-ends. L’un des ordinateurs ne répond pas à la sonde d’intégrité. L’état moyen de la sonde d’intégrité tourne autour de 50 %.
Une autre façon d’examiner ces métriques consiste à utiliser l’agrégation Nombre. Cette approche peut fournir d’autres informations sur les éventuels problèmes de votre configuration. L’exemple suivant montre les graphiques pour le nombre de métriques État de la sonde d’intégrité et Disponibilité du chemin des données. Le graphique montre le nombre de sondes qui ont abouti sur une période donnée.
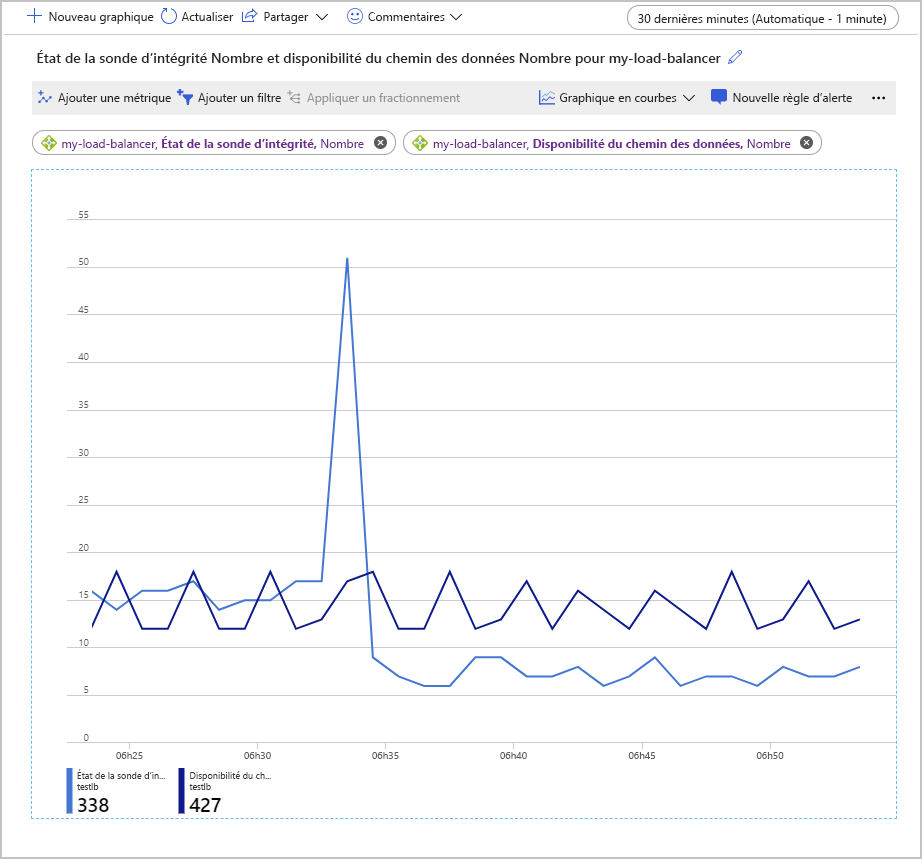
Dans ce graphique, il est intéressant de noter que le nombre de sondes Disponibilité du chemin des données qui ont réussi est resté dans une plage constante. En revanche, le nombre de vérifications de l’état de la sonde d’intégrité qui ont réussi a momentanément monté en flèche, avant de chuter à la moitié environ de la valeur précédant le pic.
Dans la configuration utilisée pour générer ce graphique, le pool back-end contenait uniquement deux machines virtuelles. L’une de ces machines a été arrêtée, pour simuler une défaillance. La métrique Disponibilité du chemin des données indique qu’il est toujours possible pour une application cliente de se connecter à l’application en cours d’exécution sur la machine virtuelle opérationnelle restante. Mais la métrique État de la sonde d’intégrité indique que l’intégrité globale du pool de back-ends a chuté de moitié par rapport à ce qu’elle était avant.
Afficher l’intégrité du service
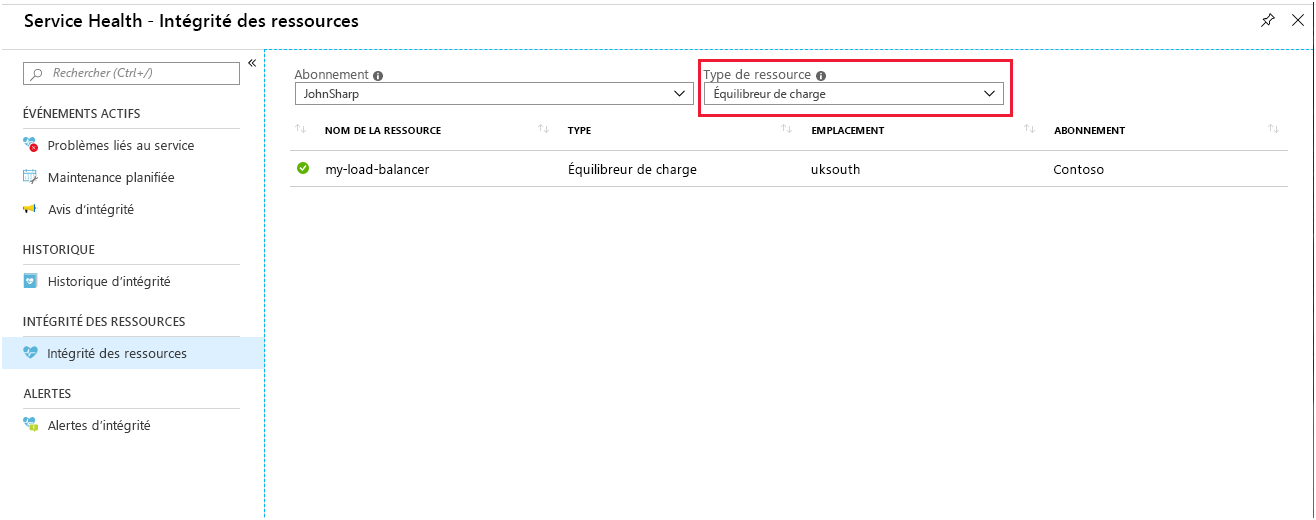
La page Resource Health pour Load Balancer indique l’état général de votre système. Vous accédez à cette page dans le portail à partir d’Azure Monitor. Sélectionnez Service Health, sélectionnez Resource Health, puis sélectionnez Load Balancer comme type de ressource.
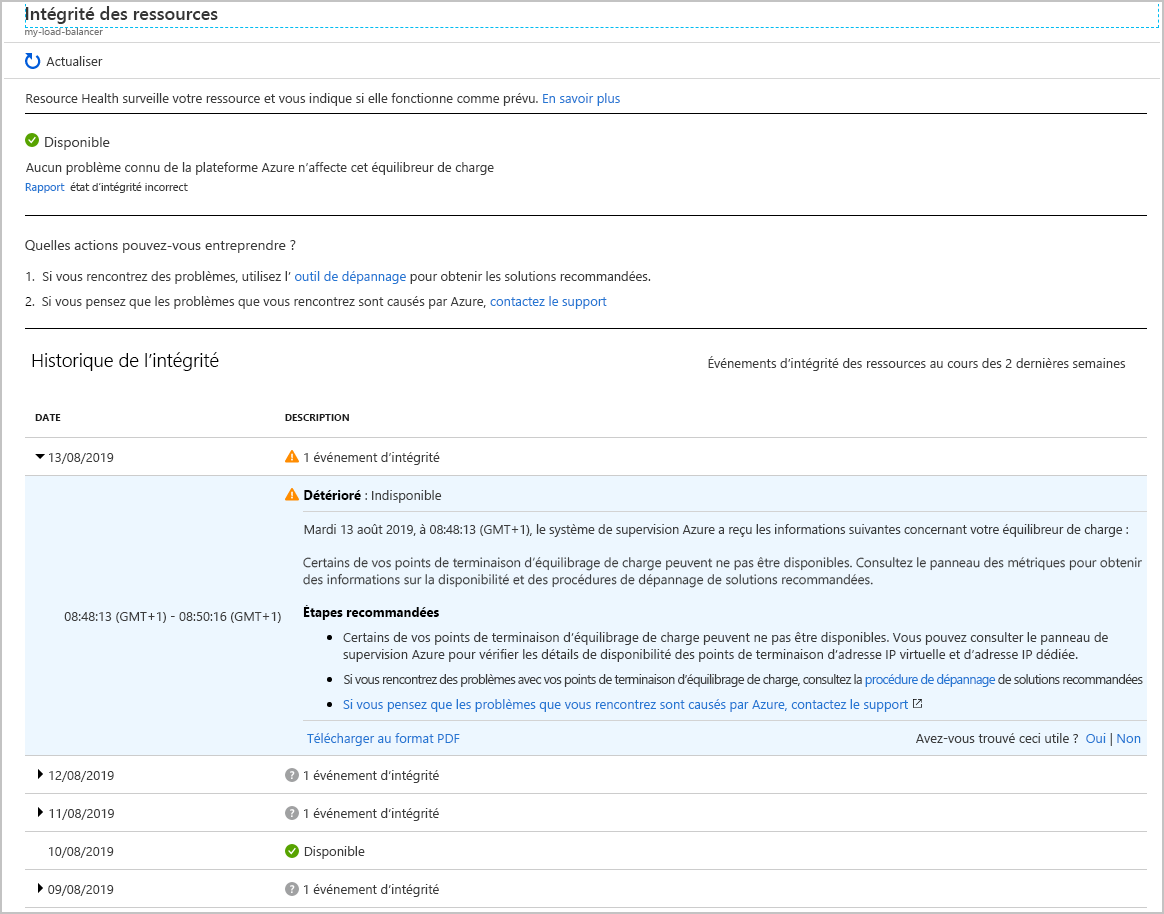
Sélectionnez votre équilibreur de charge. Vous voyez un rapport détaillant l’historique de l’intégrité de votre service. Vous pouvez développer n’importe quel élément dans le rapport pour en voir les détails. L’image suivante montre le résumé qui a été généré quand l’une des machines virtuelles du pool back-end a été mise hors connexion.
Superviser la charge de travail par machine virtuelle
Les autres métriques disponibles pour Load Balancer vous permettent de suivre le nombre d’octets et de paquets réseau qui transitent par Load Balancer par front-end. Un front-end est défini comme une combinaison de l’adresse IP de Load Balancer, du protocole utilisé pour accepter les demandes entrantes et du numéro de port utilisé par la règle d’équilibrage de charge pour la connexion aux machines virtuelles. Ces métriques peuvent donner une mesure du débit de votre système par machine virtuelle active.
Le graphique suivant montre le nombre moyen de paquets transitant par Load Balancer pendant l’exécution d’une charge de travail test de 500 utilisateurs simultanés pendant deux minutes. La charge de travail a été exécutée deux fois. La première fois, le pool de back-ends contenait deux instances de machine virtuelle. Pour la deuxième exécution, l’une des machines virtuelles a été arrêtée (pour simuler une défaillance).
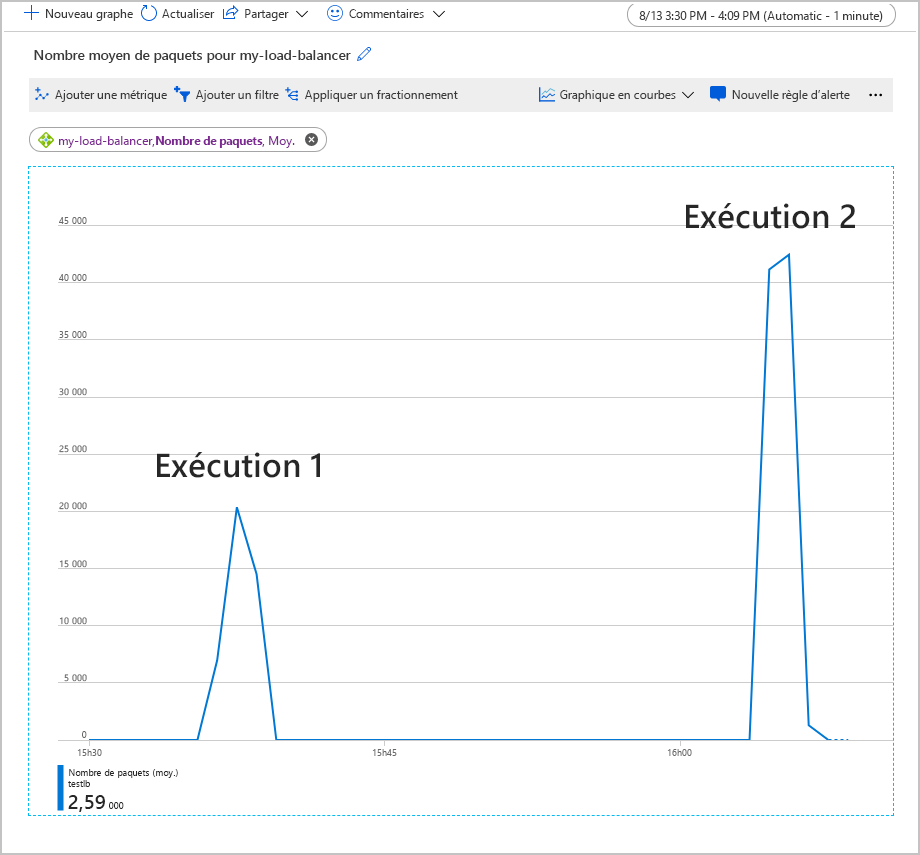
Dans ce graphique, le nombre moyen de paquets par front-end a doublé quand l’une des machines virtuelles a été arrêtée. Ce volume de travail peut surcharger la machine virtuelle restante, en entraînant des temps de réponse plus longs et d’éventuelles expirations.
Investiguer et corriger des problèmes courants avec Load Balancer
Cette section aborde certains scénarios de défaillance courants que vous pouvez rencontrer avec Load Balancer. Chaque scénario résume les symptômes d’une défaillance et la manière dont vous pouvez résoudre le problème.
Les machines virtuelles derrière Load Balancer ne répondent pas au trafic sur le port de la sonde
Ce problème peut être dû aux erreurs suivantes :
Les machines virtuelles du pool de back-ends n’écoutent pas le port de la sonde approprié.
Vérifiez que la sonde d’intégrité est correctement définie dans Load Balancer. Vérifiez que le code d’application en cours d’exécution sur chaque machine virtuelle répond correctement aux requêtes de la sonde. Ces requêtes doivent retourner un message de réponse HTTP 200 (OK).
Le groupe de sécurité réseau du sous-réseau de réseau virtuel qui héberge les machines virtuelles bloque le port de la sonde.
Dans la configuration du groupe de sécurité réseau, vérifiez le sous-réseau de réseau virtuel qui contient les machines virtuelles. Vérifiez que le groupe de sécurité réseau autorise le trafic provenant de Load Balancer à traverser le port de la sonde d’intégrité.
Vous tentez d’accéder à Load Balancer à partir de la même machine virtuelle et de la même carte réseau virtuelle. Ce problème n’est pas lié à la sonde, mais il s’agit d’un scénario de chemin des données non pris en charge.
Vous tentez d’accéder au front-end Load Balancer à partir d’une machine virtuelle du pool back-end.
Ces deux problèmes sont dus à la conception de l’application. Évitez d’envoyer des demandes à la même instance de Load Balancer à partir d’une machine virtuelle du pool de back-ends.
Une machine virtuelle du pool de back-ends n’est pas saine
Dans ce cas, la plupart des machines virtuelles répondent normalement, contrairement à une ou deux autres. Étant donné que certaines machines virtuelles acceptent le trafic, la sonde d’intégrité est probablement correctement configurée. Le groupe de sécurité réseau du sous-réseau ne bloque pas le port utilisé par la sonde d’intégrité. Le problème est probablement lié aux machines virtuelles qui ne sont pas saines. Il peut être dû au fait que les machines virtuelles sont inaccessibles ou en panne, ou qu’il y a un problème d’application sur ces machines.
Pour déterminer la cause du problème lié à une machine virtuelle non saine, effectuez les étapes suivantes :
- Connectez-vous à une machine virtuelle non saine pour vérifier qu’elle est opérationnelle. Vérifiez que la machine virtuelle peut répondre à des vérifications de base, comme des demandes ping, rdp ou ssh à partir d’une autre machine virtuelle du pool de back-ends.
- Si la machine virtuelle est opérationnelle et accessible, vérifiez que l’application est en cours d’exécution.
- Exécutez la commande
netstat -an, puis vérifiez que les ports utilisés par la sonde d’intégrité et l’application sont listés en tant que LISTENING.
Erreurs de configuration dans Load Balancer
Load Balancer vous oblige à configurer correctement les règles de routage qui dirigent le trafic entrant du front-end vers le pool back-end. Si une règle d’acheminement est manquante ou n’est pas configurée correctement, le trafic qui arrive au serveur front-end est supprimé. Une fois le trafic supprimé, l’application est signalée aux clients comme inaccessibles.
Validez la route par le biais de Load Balancer entre le front-end et le pool back-end. Vous pouvez utiliser des outils comme Ping, TCPing et netsh, qui sont disponibles pour Windows et Linux. Vous pouvez également utiliser psping sur Windows. Les sections suivantes décrivent comment utiliser ces outils.
Utiliser ping
La commande ping teste la connectivité ping par le biais d’un point de terminaison en utilisant le protocole ICMP. Pour vérifier qu’une route est disponible entre votre client et une machine virtuelle par le biais de Load Balancer, exécutez la commande suivante. Remplacez <adresse ip> par l’adresse IP de l’instance Load Balancer.
ping -n 10 <ip address>
| Switch | Description |
|---|---|
| -n | Le commutateur spécifie le nombre de demandes ping à envoyer. |
Une sortie classique ressemble à ceci :
ping -n 10 nn.nn.nn.nn
Pinging nn.nn.nn.nn with 32 bytes of data:
Reply from nn.nn.nn.nn: bytes=32 time=34ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Ping statistics for nn.nn.nn.nn:
Packets: Sent = 10, Received = 10, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 29ms, Maximum = 34ms, Average = 30ms
Utiliser PsPing
La commande PsPing teste la connectivité ping par le biais d’un point de terminaison. Cette commande mesure également la latence et la disponibilité de la bande passante pour un service. Pour vérifier qu’une route est disponible entre votre client et une machine virtuelle par le biais de Load Balancer, exécutez la commande suivante. Remplacez <ip address> et <port> par l’adresse IP et le port front-end de l’instance Load Balancer.
psping -n 100 -i 0 -q -h <ip address>:<port>
| Indicateur | Description |
|---|---|
| -n | Spécifie le nombre de commandes ping à effectuer. |
| -i | Indique l’intervalle, en secondes, entre les itérations. |
| -q | Supprime la sortie pendant les commandes ping. Seul un résumé est présenté à la fin. |
| -h | Imprime un histogramme qui montre la latence des demandes. |
Une sortie classique ressemble à ceci :
TCP connect to nn.nn.nn.nn:nn:
101 iterations (warmup 1) ping test: 100%
TCP connect statistics for nn.nn.nn.nn:nn:
Sent = 100, Received = 100, Lost = 0 (0% loss),
Minimum = 7.48ms, Maximum = 9.08ms, Average = 8.30ms
Latency Count
7.48 3
7.56 2
7.65 2
7.73 2
7.82 7
7.90 4
7.98 4
8.07 6
8.15 9
8.24 9
8.32 11
8.40 7
8.49 11
8.57 12
8.66 3
8.74 2
8.82 2
8.91 1
8.99 2
9.08 1
Utiliser tcping
L’utilitaire tcping est similaire à ping, à ceci près qu’il fonctionne sur une connexion TCP au lieu d’une connexion ICMP. Utilisez tcping de la façon suivante :
tcping <ip address> <port>
Une sortie classique ressemble à ceci :
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.042ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.810ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.266ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.181ms
Ping statistics for nn.nn.nn.nn:nn
4 probes sent.
4 successful, 0 failed. (0.00% fail)
Approximate trip times in milli-seconds:
Minimum = 9.042ms, Maximum = 9.810ms, Average = 9.325ms
Utiliser netsh
L’utilitaire netsh est un outil de configuration réseau à usage général. Utilisez la commande trace dans netsh pour capturer le trafic réseau. Effectuez ensuite l’analyse à l’aide d’un outil comme Wireshark. Utilisez netsh trace pour examiner les paquets réseau envoyés et reçus par psping lors du test de la connectivité par le bais de Load Balancer de la façon suivante :
Démarrez une trace réseau à partir d’une invite de commandes exécutée en tant qu’administrateur. L’exemple suivant trace le trafic client Internet (requêtes HTTP) vers et à partir de l’adresse IP spécifiée. Remplacez <ip address> par l’adresse de l’instance Load Balancer. Les données de trace sont écrites dans un fichier nommé trace.etl.
netsh trace start ipv4.address=<ip address> capture=yes scenario=internetclient tracefile=trace.etlExécutez psping pour tester la connectivité par le biais de Load Balancer.
psping -n 100 -i 0 -q <ip address>:<port>Arrêtez le traçage.
netsh trace stopCette commande prend quelques minutes pour s’exécuter, car elle met en corrélation et fusionne les informations lors de la création du fichier de sortie de trace.
Démarrez Wireshark et ouvrez le fichier de trace.
Ajoutez le filtre suivant à la trace. Remplacez <nn> par le numéro de port front-end de Load Balancer.
TCP.Port==80 or TCP.Port==<nn>Ajoutez la source et la destination de la requête HTTP en tant que champs à la sortie de trace.
Examinez les messages de trace :
- S’il n’y a aucun paquet entrant dans Load Balancer, il s’agit probablement d’un problème de sécurité réseau ou d’un problème lié à un routage défini par l’utilisateur.
- Si aucun paquet sortant n’est retourné au client, il s’agit probablement d’un problème de configuration d’application ou d’un problème lié à un routage défini par l’utilisateur.
Blocage du port par un pare-feu de machine virtuelle ou un groupe de sécurité réseau
Si le réseau et Load Balancer sont configurés correctement, si la machine virtuelle est opérationnelle et l’application en cours d’exécution, il se peut que la configuration du pare-feu ou du groupe de sécurité réseau des machines virtuelles bloque le port utilisé par la sonde d'intégrité ou l’application. Les étapes suivantes permettent de déterminer si c'est le cas :
S’il existe un pare-feu sur la machine virtuelle, il peut bloquer les demandes sur les ports utilisés par la sonde d’intégrité et l’application. Vérifiez la configuration du pare-feu sur l’hôte pour vous assurer qu’il autorise le trafic sur les ports utilisés par la sonde d’intégrité et l’application.
Vérifiez que tous les groupes de sécurité réseau pour la carte réseau de la machine virtuelle autorisent l’entrée et la sortie sur les ports nécessaires. Recherchez une règle Refuser tout dans le groupe de sécurité réseau sur la carte réseau de la machine virtuelle dont la priorité est plus élevée que celle de la règle par défaut.
Important
Vous pouvez associer un groupe de sécurité réseau à un sous-réseau et aux cartes réseau individuelles des machines virtuelles dans le sous-réseau. Vous avez peut-être configuré le groupe de sécurité réseau de sorte qu’un sous-réseau autorise le trafic à traverser un port. Toutefois, si le groupe de sécurité réseau d’une machine virtuelle ferme ce même port, les demandes n’aboutissent pas à cette machine virtuelle.
Limitations de Load Balancer
Load Balancer fonctionne au niveau de la couche 4 dans la pile réseau ISO et n’examine pas ni ne manipule le contenu des paquets réseau. Vous ne pouvez pas l’utiliser pour implémenter un routage basé sur le contenu.
Toutes les demandes client sont terminées par une machine virtuelle du pool de back-ends. Load Balancer est invisible pour les clients. Si aucune machine virtuelle n’est disponible, la requête client échoue. Les applications clientes ne peuvent pas communiquer avec Load Balancer ou l’un de ses composants, ni en interroger l’état.
Si vous avez besoin d’implémenter un équilibrage de charge basé sur le contenu des messages, envisagez d’utiliser Azure Application Gateway. Vous pouvez aussi configurer un serveur web proxy pour gérer les requêtes client entrantes et les diriger vers des machines virtuelles spécifiques.