Découvrir Apache Spark
Apache Spark est un framework de traitement des données distribué qui permet l’analytique de données à grande échelle en coordonnant le travail sur plusieurs nœuds de traitement dans un cluster.
Comment Spark fonctionne
Les applications Apache Spark s’exécutent comme des ensembles de processus indépendants sur un cluster, coordonnées par l’objet SparkContext du programme principal (appelé programme pilote). SparkContext se connecte au gestionnaire de cluster, qui alloue des ressources aux applications à l’aide d’une implémentation d’Apache Hadoop YARN. Une fois connecté, Spark acquiert des exécuteurs sur les nœuds du cluster pour exécuter le code de vos applications.
SparkContext exécute la fonction principale et les opérations parallèles sur les nœuds du cluster, puis collecte les résultats des opérations. Les nœuds lisent et écrivent des données depuis et vers le système de fichiers et mettent en cache les données transformées en mémoire en tant que jeux de données distribués résilients (RDD, Resilient Distributed Dataset).
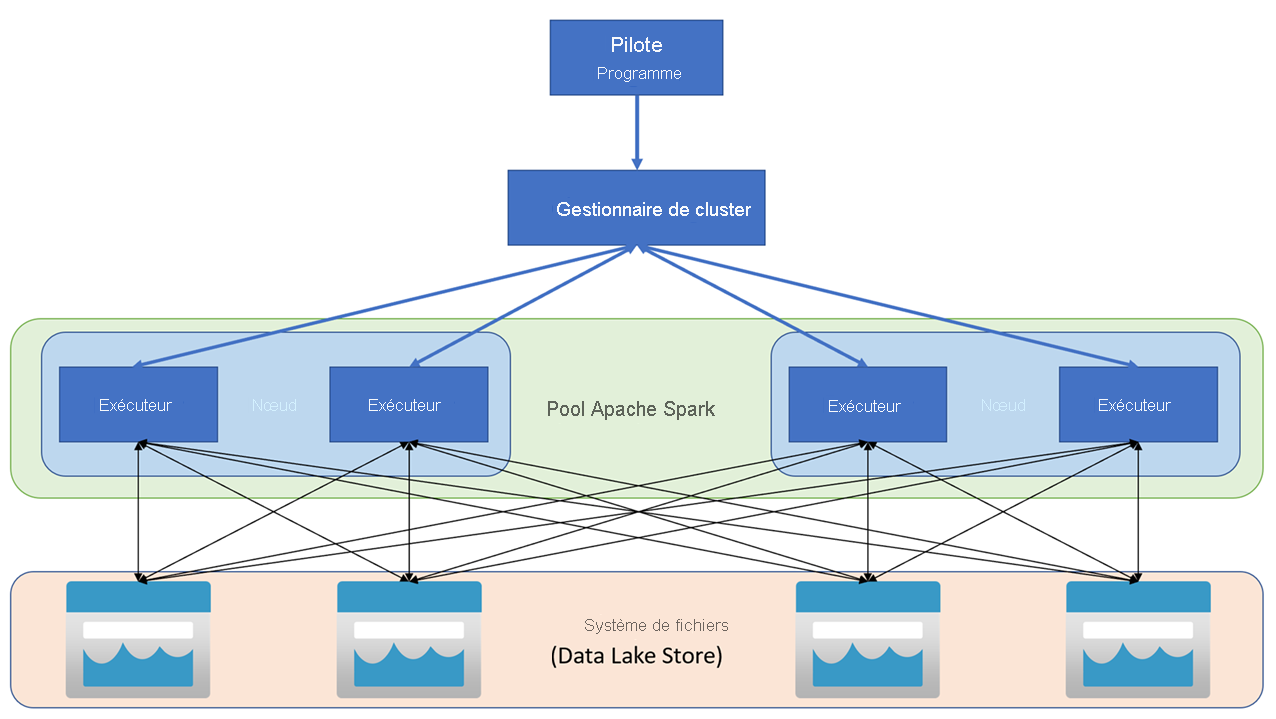
SparkContext est responsable de la conversion d’une application en graphe orienté acyclique (DAG, directed acyclic graph). Le graphe se compose de tâches individuelles qui sont exécutées dans un processus de l’exécuteur sur les nœuds. Chaque application obtient ses propres processus d’exécution qui restent pour la durée de toute l’application et exécutent des tâches sur plusieurs threads.
Pools Spark dans Azure Synapse Analytics
Dans Azure Synapse Analytics, un cluster est implémenté en tant que pool Spark, qui fournit un runtime pour les opérations Spark. Vous pouvez créer un ou plusieurs pools Spark dans un espace de travail Azure Synapse Analytics à l’aide du portail Azure ou dans Azure Synapse Studio. Lors de la définition d’un pool Spark, vous pouvez spécifier des options de configuration pour le pool, notamment :
- Un nom pour le pool Spark.
- La taille de la machine virtuelle utilisée pour les nœuds du pool, notamment l’option d’utiliser des nœuds GPU à accélération matérielle.
- Le nombre de nœuds dans le pool et si la taille du pool est fixe ou si des nœuds individuels peuvent être mis en ligne de façon dynamique pour mettre à l’échelle automatiquement le cluster, auquel cas vous pouvez spécifier le nombre minimal et maximal de nœuds actifs.
- La version du runtime Spark à utiliser dans le pool, qui dicte les versions des composants individuels tels que Python, Java et autres qui sont installés.
Conseil
Pour plus d’informations sur les options de configuration d’un pool Spark, consultez Configurations des pools Apache Spark dans Azure Synapse Analytics dans la documentation Azure Synapse Analytics.
Les pools Spark dans un espace de travail Azure Synapse Analytics sont serverless : ils démarrent à la demande et s’arrêtent lorsqu’ils sont inactifs.