Comprendre Delta Lake
Delta Lake est une couche de stockage open source qui ajoute la sémantique d’une base de données relationnelle au traitement du lac de données basé sur Spark. Les tables dans les lakehouses Microsoft Fabric sont des tables Delta, qui sont indiquées par l’icône Delta triangulaire (▴) sur les tables dans l’interface utilisateur des lakehouses.
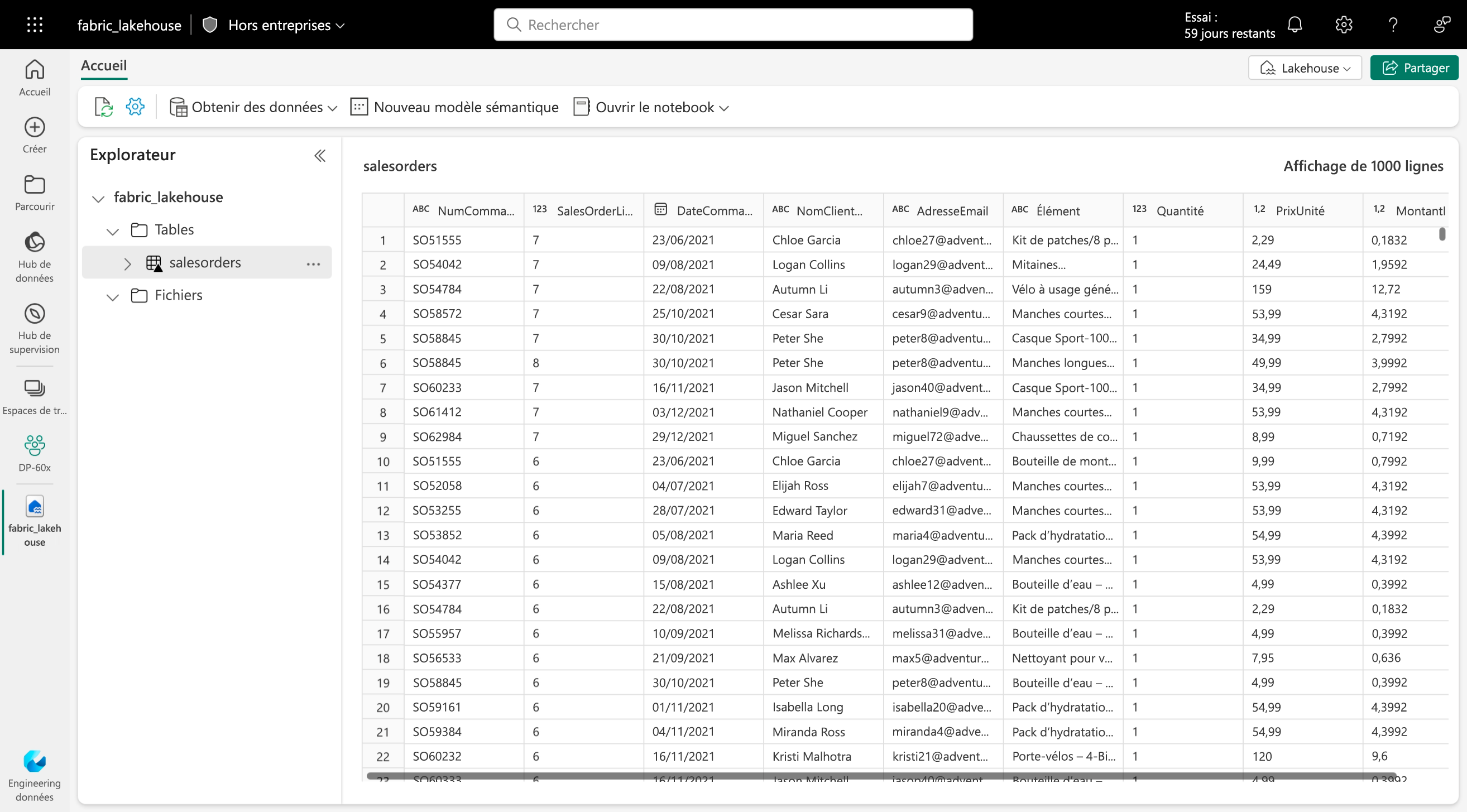
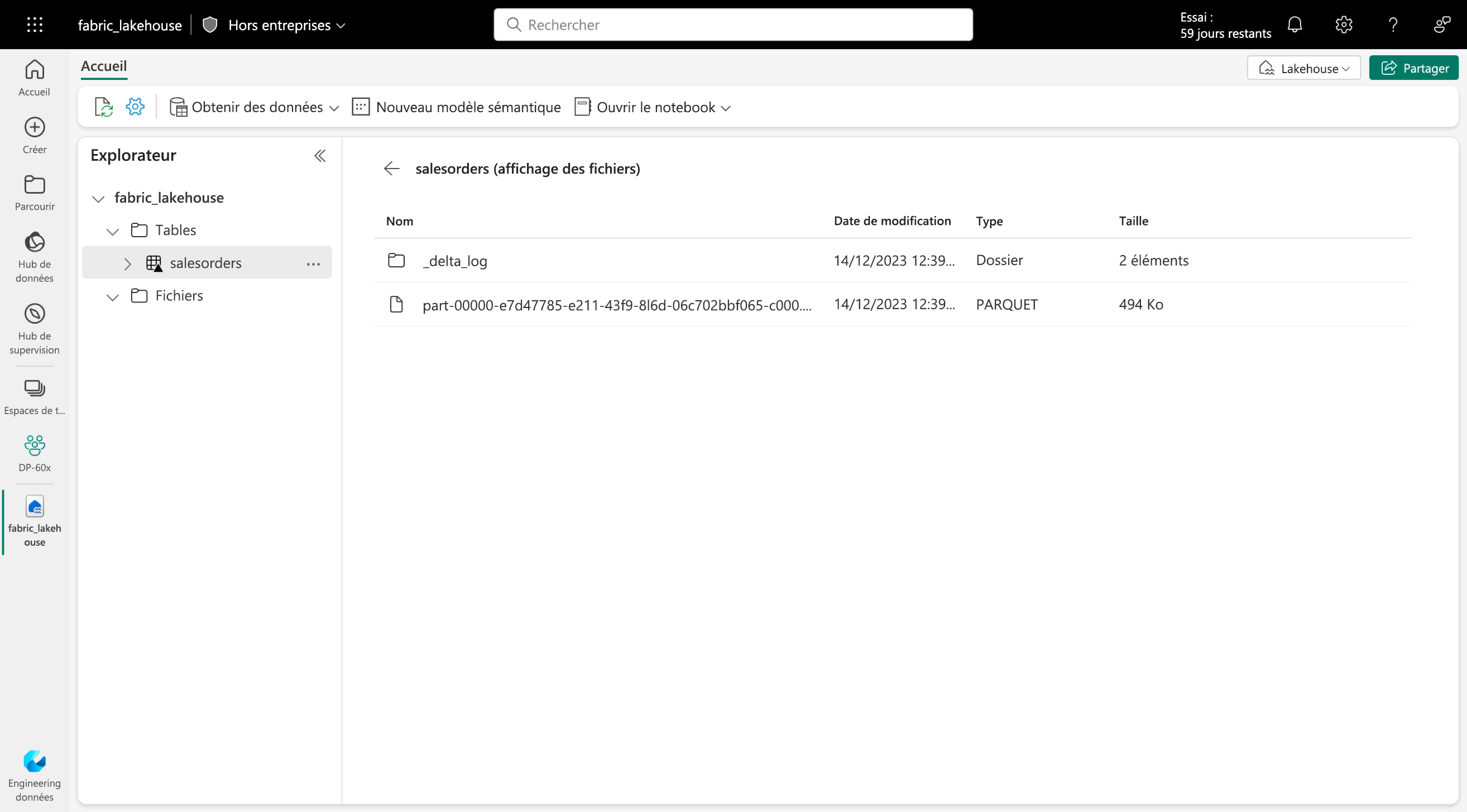
Les tables Delta sont des abstractions de schéma sur des fichiers de données stockés au format Delta. Pour chaque table, le lakehouse stocke un dossier contenant des fichiers de données Parquet et un dossier _delta_Log dans lequel les détails de transaction sont journalisés au format JSON.
Les avantages d’utiliser des tables Delta sont les suivants :
- Des tables relationnelles qui prennent en charge l’interrogation et la modification des données. Avec Apache Spark, vous pouvez stocker des données dans des tables Delta qui prennent en charge les opérations CRUD (créer, lire, mettre à jour et supprimer). En d’autres termes, vous pouvez sélectionner, insérer, mettre à jour et supprimer des lignes de données de la même façon que dans un système de base de données relationnelle.
- Prise en charge des transactions ACID. Les bases de données relationnelles sont conçues pour prendre en charge les modifications de données transactionnelles qui fournissent l’atomicité (transactions terminées sous forme d’une unité de travail unique), la cohérence (les transactions laissent la base de données dans un état cohérent), l’isolation (les transactions in-process ne peuvent pas interférer entre elles) et la durabilité (lorsqu’une transaction se termine, les modifications apportées sont persistantes). Delta Lake apporte cette même prise en charge transactionnelle à Spark en implémentant un journal des transactions et en appliquant une isolation sérialisable pour les opérations simultanées.
- Contrôle de version des données et voyage dans le temps. Étant donné que toutes les transactions sont enregistrées dans le journal des transactions, vous pouvez suivre plusieurs versions de chaque ligne de table et même utiliser la fonctionnalité de voyage dans le temps pour récupérer une version précédente d’une ligne dans une requête.
- Prise en charge des données de traitement par lots et de diffusion en continu. Bien que la plupart des bases de données relationnelles incluent des tables qui stockent des données statiques, Spark inclut la prise en charge native des données de diffusion en continu via l’API Spark Structured Streaming. Les tables Delta Lake peuvent être utilisées en tant que récepteurs (destinations) et sources pour la diffusion en continu de données.
- Formats standard et interopérabilité. Les données sous-jacentes des tables Delta sont stockées au format Parquet, qui est couramment utilisé dans les pipelines d’ingestion de lac de données. En outre, vous pouvez utiliser le point de terminaison d’analytique SQL pour le lakehouse Microsoft Fabric afin d’interroger des tables Delta en SQL.