Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : ✔️ Machines virtuelles Linux
Cet article explique comment résoudre les problèmes de performances de mémoire qui se produisent sur des machines virtuelles Linux dans Microsoft Azure.
La première étape de travail sur les problèmes liés à la mémoire consiste à évaluer les éléments suivants :
- Utilisation de la mémoire par les applications hébergées sur le système
- Niveau approprié de mémoire disponible sur le système
Vous pouvez commencer par analyser les modèles de charge de travail pour déterminer si le système est configuré correctement. Ensuite, vous devrez peut-être envisager de mettre à l’échelle la machine virtuelle ou de choisir entre une architecture NUMA (accès à la mémoire non uniforme) et UMA (accès à la mémoire uniforme). En outre, il est utile de déterminer si les performances de l’application bénéficieraient de Transparent HugePages (THP). La meilleure approche consiste à collaborer avec le fournisseur d’applications pour comprendre les exigences de mémoire recommandées.
Zones clés affectées par la mémoire
Allocation de mémoire de processus : la mémoire est une ressource nécessaire pour chaque processus, y compris le noyau. La quantité de mémoire requise dépend de la conception et de l’objectif du processus. La mémoire est généralement affectée à la pile ou au tas. Par exemple, les bases de données en mémoire telles que SAP HANA s’appuient fortement sur la mémoire pour stocker et traiter efficacement les données.
Utilisation du cache de page : la mémoire peut également être consommée indirectement par le biais d’une augmentation du cache de page. Le cache de page est une représentation en mémoire d’un fichier qui a été lu précédemment à partir d’un disque. Ce cache permet d’éviter les lectures répétées de disque. Le meilleur exemple de ce processus est un serveur de fichiers qui tire parti de cette fonctionnalité de noyau sous-jacente.
Architecture de la mémoire : il est important de savoir quelles applications s’exécutent sur la même machine virtuelle et s’ils peuvent concurrencer la mémoire disponible. Vous devrez peut-être également vérifier si la machine virtuelle est configurée pour utiliser l’architecture NUMA ou UMA. Selon les besoins en mémoire d’un processus, l’architecture UMA peut être préférable afin que la ram complète puisse être traitée sans pénalité. En revanche, pour le calcul haute performance (HPC) qui implique de nombreux petits processus ou processus qui s’intègrent dans l’un des nœuds NUMA, vous pouvez tirer parti de la localité du cache du processeur.
Dépassement de mémoire : il est également important de déterminer si le noyau autorise le surcommitment de la mémoire. Selon la configuration, chaque demande de mémoire est remplie jusqu’à ce que la quantité demandée ne soit plus disponible.
Espace d’échange L’activation de l’échange améliore la stabilité globale du système en fournissant une mémoire tampon pendant les conditions de mémoire faible. Cette mémoire tampon permet au système de rester résilient sous pression. Pour plus d’informations, consultez cet article sur le noyau Linux.
Comprendre les outils de résolution des problèmes de mémoire
Vous pouvez utiliser les outils de ligne de commande suivants pour résoudre les problèmes.
libre
Pour afficher la quantité de mémoire disponible et utilisée sur un système, utilisez la free commande.

Cette commande génère un résumé de la mémoire réservée et disponible, y compris l’espace d’échange total et utilisé.
pidstat et vmstat
Pour une vue plus détaillée de l’utilisation de la mémoire par des processus individuels, utilisez la pidstat -r commande.
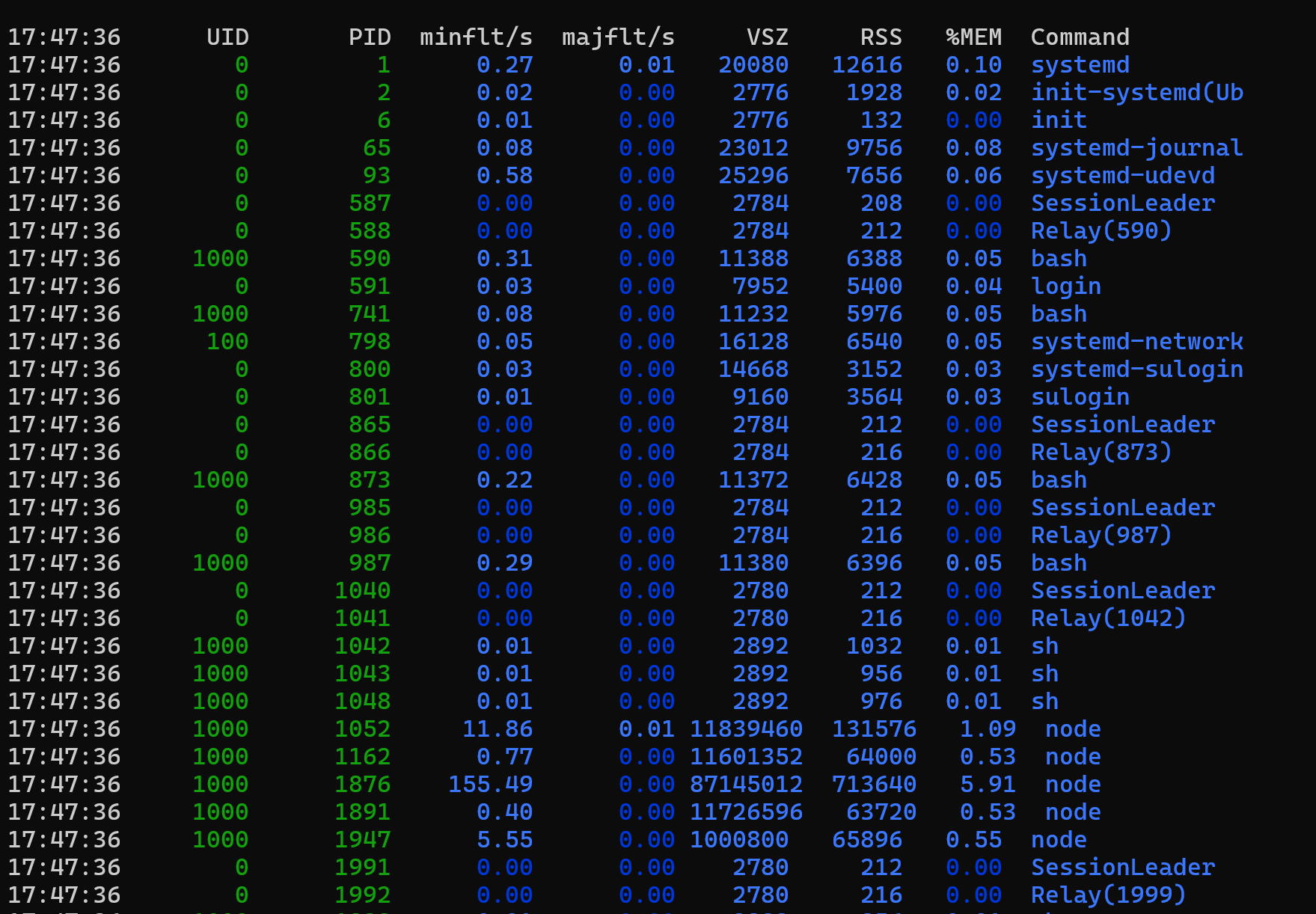
Lorsque vous analysez les rapports d’utilisation de la mémoire, deux colonnes importantes à observer sont VSZ et RSS:
- VSZ (Taille de jeu virtuel) indique la quantité totale de mémoire virtuelle (en kilo-octets) qu’un processus se réserve.
- RSS (Taille d’ensemble résidente) indique la quantité de mémoire virtuelle actuellement conservée dans la RAM (par exemple, mémoire engagée).
Une autre métrique utile est majflt/s (nombre d’erreurs de page principales par seconde). Ce nombre mesure la fréquence à laquelle une page mémoire doit être lue à partir d’un appareil d’échange. Si vous avez des préoccupations concernant la forte utilisation de la mémoire d’échange, vérifiez la quantité à l’aide de l’outil vmstat pour surveiller les statistiques de page-in et de page-out au fil du temps.
Exemple de sortie vmstat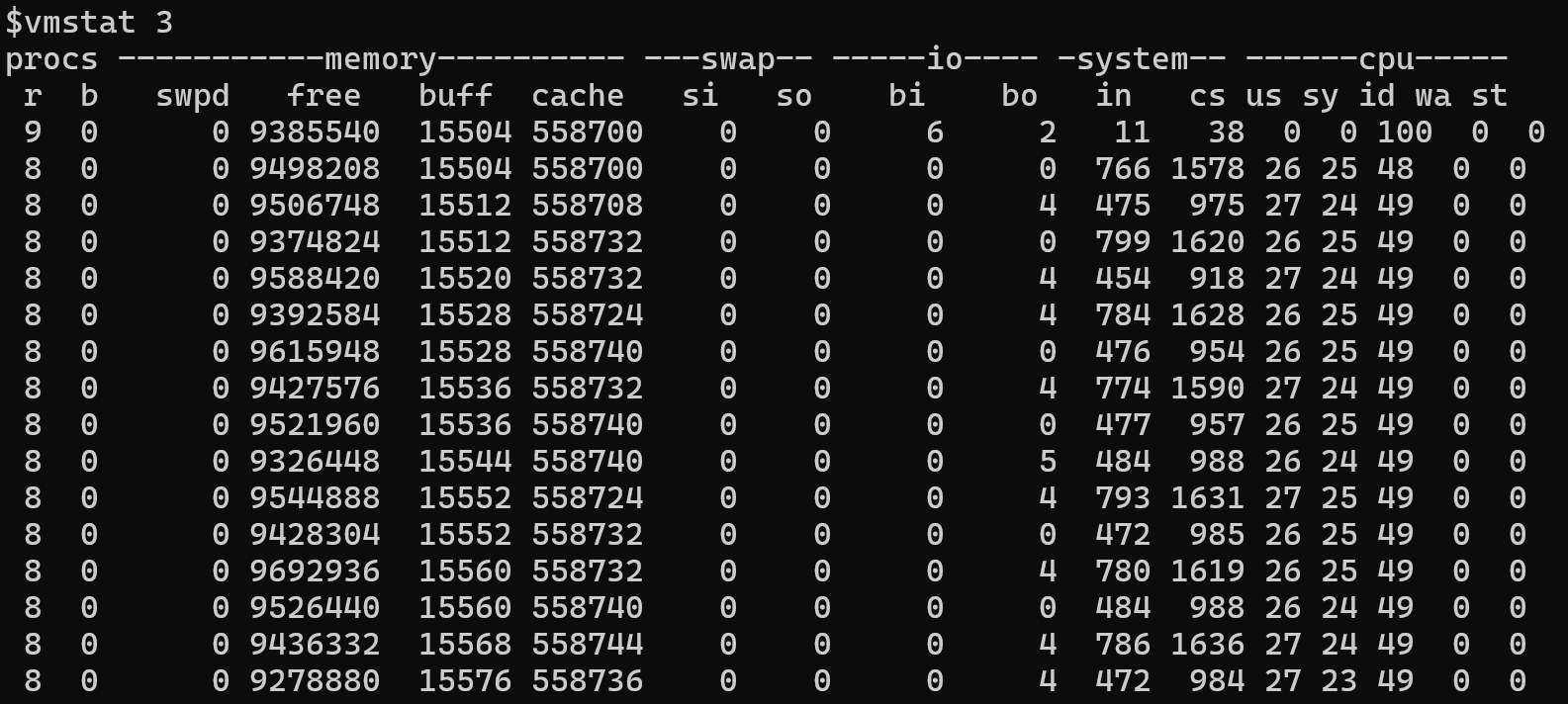
Dans cet exemple, vous pouvez observer que de nombreuses pages de mémoire sont lues ou écrites pour échanger. Ces valeurs élevées indiquent généralement que le système manque de mémoire disponible. Cette condition peut se produire parce que plusieurs processus sont concurrents pour la mémoire, ou parce que la plupart des applications ne peuvent pas utiliser la mémoire disponible.
Une raison courante de l’indisponibilité de la mémoire est l’utilisation d’HugePages. Les HugePages sont une mémoire réservée. Toutes les applications ne peuvent pas utiliser la mémoire réservée. Dans certaines situations, vous devrez peut-être évaluer si vos applications ont besoin d’HugePages ou fonctionnent plus efficacement à l’aide de Transparent HugePages (THP). Le THP permet au noyau de gérer dynamiquement les pages de mémoire volumineuses. Par exemple, la machine virtuelle Java (JVM) peut tirer parti de THP en activant l’indicateur suivant :
-XX:+UseTransparentHugePages
Pour plus d’informations sur THP, consultez Transparent HugePage Support.
Pour plus d’informations sur HugePages, consultez Pages HugeTLB.
Test de l’utilisation de THP dans un exemple de programme
Pour observer comment THP est utilisé par le système, vous pouvez exécuter un petit programme C qui alloue environ 256 Mo de RAM. Le programme utilise l'appel système madvise pour indiquer au noyau Linux que cette région de mémoire utilise de grandes pages si le THP est pris en charge.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#define LARGE_MEMORY_SIZE (256 * 1024 * 1024) // 256MB
int main() {
char str[2];
// Allocate a large memory area
void *addr = mmap(NULL, LARGE_MEMORY_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED) {
perror("mmap");
return 1;
}
// Use madvise to give advice about the memory usage
if (madvise(addr, LARGE_MEMORY_SIZE, MADV_HUGEPAGE) != 0) {
perror("madvise");
munmap(addr, LARGE_MEMORY_SIZE);
return 1;
}
// Initialize the memory
int *array = (int *)addr;
for (int i = 0; i < LARGE_MEMORY_SIZE / sizeof(int); i++) {
array[i] = i;
}
memset(addr, 0, LARGE_MEMORY_SIZE);
printf("Press Enter to continue\n");
fgets(str,2,stdin);
// Clean up
if (munmap(addr, LARGE_MEMORY_SIZE) == -1) {
perror("munmap");
return 1;
}
return 0;
}
Si vous exécutez le programme, il n’est pas directement observable si THP est utilisé par le programme.
Vous pouvez vérifier l’utilisation globale du THP sur le système en examinant le /proc/meminfo fichier. Vérifiez le AnonHugePages champ pour déterminer la quantité de mémoire qui utilise THP. Ce fichier fournit uniquement des statistiques à l’échelle du système.
Pour savoir si un processus utilise THP, vous devez inspecter le smaps fichier dans le /proc répertoire du processus en question. Par exemple, dans /proc/2275/smaps, recherchez une ligne qui contient le mot heap (illustré ici à l’extrême droite).
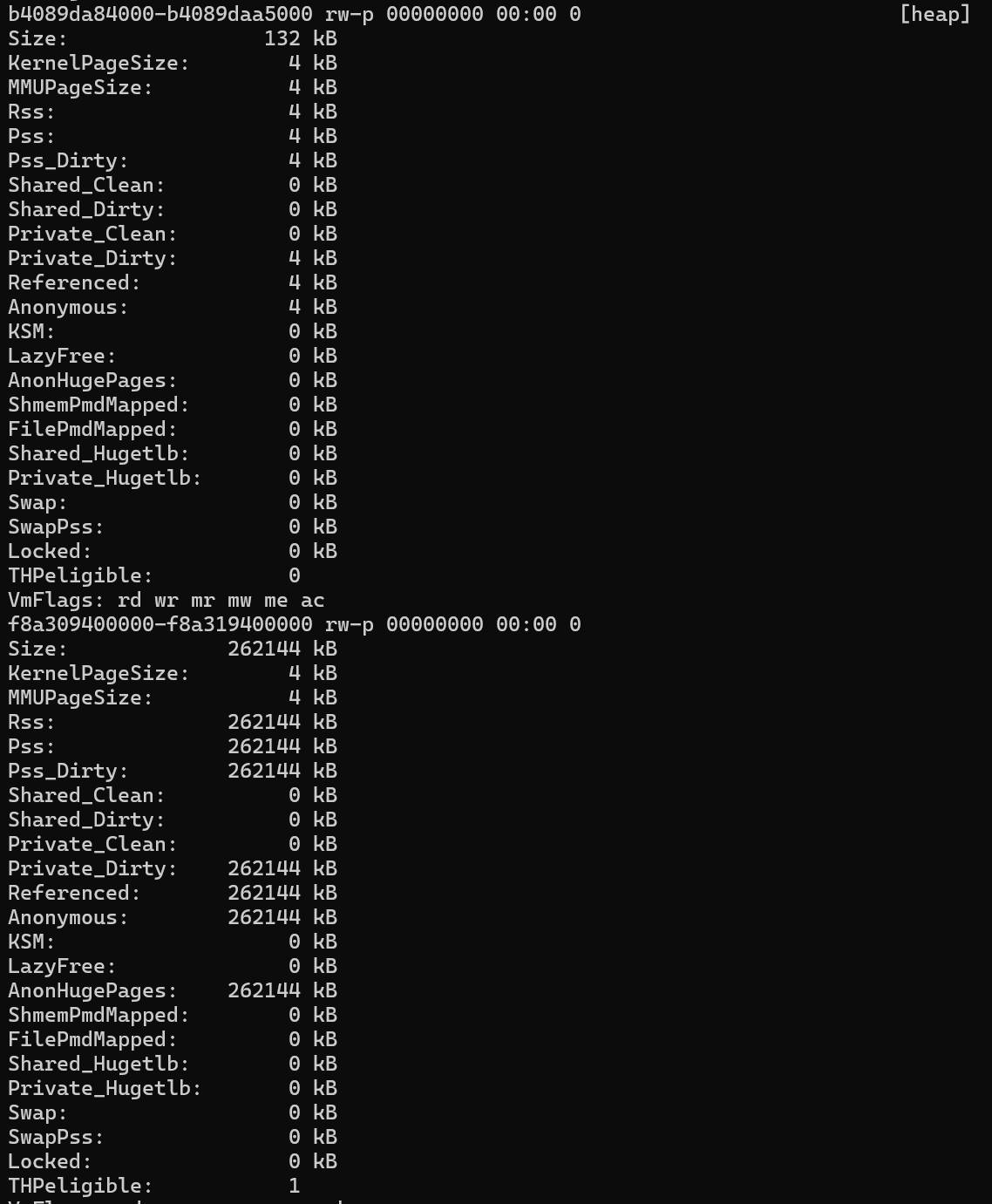
Cet exemple montre qu’un segment de mémoire volumineux a été alloué et marqué comme THPeligible(THP sont en cours d’utilisation). En utilisant madvice syscall, l’allocation de ce bloc de mémoire est beaucoup plus efficace. Vous pouvez obtenir la même efficacité à l’aide d’Huge Pages. En fonction de la taille de l’allocation, le noyau peut affecter des pages standard de 4 Ko ou des blocs contigus plus grands. Cette optimisation peut améliorer les performances des applications gourmandes en mémoire.
Pour plus d’informations, consultez Transparent Hugepage Support.
NUMA
Si les applications s’exécutent sur un système NUMA qui a plusieurs nœuds, il est important de connaître la capacité de mémoire de chaque nœud. Tous les nœuds peuvent accéder à la mémoire totale du système. Toutefois, vous obtenez des performances optimales si les processus qui s’exécutent sur un nœud NUMA particulier fonctionnent sur la mémoire sous contrôle direct de ce nœud. Si le nœud local ne peut pas répondre à une demande de mémoire, le système alloue de la mémoire à partir d’un autre nœud. Toutefois, l’accès à la mémoire entre les nœuds introduit une latence et peut entraîner des pénalités de performances. Par conséquent, vous devez surveiller la localité de la mémoire pour vous assurer que les charges de travail sont alignées avec les ressources mémoire de leurs nœuds NUMA affectés.
La capture d’écran suivante montre un exemple de configuration NUMA du système.
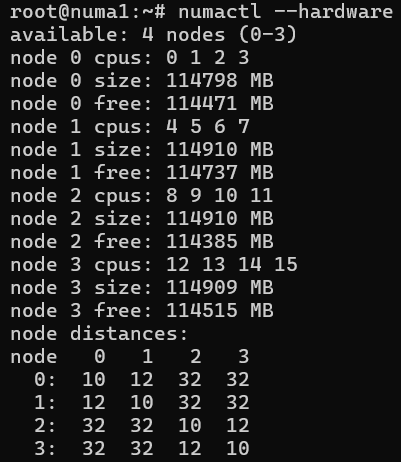
Cette configuration montre que l’accès à la mémoire au sein du même nœud a un niveau de distance de 10. Si vous souhaitez accéder à la mémoire à Node 1 partir de Node 0, ce processus a une valeur de distance élevée de 12, mais est toujours gérable. Toutefois, si vous souhaitez accéder à la mémoire sur NODE 3 depuis NODE 0, le niveau de distance devient 32. Ce processus est toujours faisable, mais il est également trois fois plus lent. Il est utile de prendre en compte ces différences lorsque vous diagnostiquez des problèmes de performances ou optimisez les charges de travail liées à la mémoire. Pour plus d’informations, consultez cet article sur le noyau Linux. Pour obtenir une description de l’outil numactl , consultez numactl(8).
Pour déterminer si un réacheminement des processus existe et qu’un nœud différent serait nécessaire, utilisez l’outil numastat . La documentation de cet outil est disponible sur numastat(8). L’outil migratepagesmigratepages(8) peut vous aider à déplacer les pages de mémoire vers le nœud approprié.
Surcommitment et OOM killer (tueur du Out-Of-Memory)
Le surcommitment est un choix de conception important qui peut affecter sérieusement les performances et la stabilité du système. Le noyau Linux prend en charge trois modes :
- 'Heuristique'
- Toujours s'engager au-delà de ses limites
- Ne vous engagez pas trop
Par défaut, le système utilise le Heuristic schéma. Ce mode offre un compromis équilibré entre permettre constamment la surcharge mémoire et la refuser strictement. Pour plus d’informations, consultez la documentation du noyau.
Un paramètre de surcommitment incorrect peut empêcher les pages de mémoire d’allouer de la mémoire. Potentiellement, cette condition peut entraver la création de nouveaux processus ou empêcher les structures de noyau internes d’acquérir suffisamment de mémoire.
Si vous vérifiez que le problème est lié à l’allocation de mémoire, la cause la plus probable de ce problème est des ressources insuffisantes restantes pour le noyau. Dans ce genre de situation, le tueur OOM (Out-Of-Memory) peut être appelé. Son travail consiste à libérer certaines pages de mémoire à utiliser par des tâches de noyau ou d’autres applications. En appelant le tueur OOM, le système vous avertit qu’il a atteint ses limites de ressources. Si vous pouvez éliminer la possibilité d’une fuite de mémoire, la cause de cette condition peut être que trop de processus sont en cours d’exécution ou que les processus qui consomment beaucoup de mémoire. Pour résoudre le problème, envisagez d’augmenter la taille de machine virtuelle ou de déplacer certaines applications vers un autre serveur.
Journaux système générés pendant les événements OOM
Cette section présente une technique permettant d’identifier le moment où le tueur OOM est déclenché et d’apprendre quelles informations sont enregistrées par le système.
Le programme C simple suivant teste la quantité de mémoire allouée dynamiquement sur un système avant d’échouer.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ONEGB (1 << 30)
int main() {
int count = 0;
while (1) {
int *p = malloc(ONEGB);
if (p == NULL) {
printf("malloc refused after %d GB\n", count);
return 0;
}
memset(p,1,ONEGB);
printf("got %d GB\n", ++count);
}
}
Ce programme indique que l’allocation de mémoire échoue après environ 3 Go.

Lorsque le système manque de mémoire, le tueur OOM est appelé. Vous pouvez afficher les journaux associés à l’aide de la commande dmesg. Les entrées de journal commencent généralement comme indiqué dans la capture d’écran suivante.

Les entrées se terminent généralement par un résumé de l’état de mémoire.

Entre ces entrées, vous trouverez des informations détaillées sur l’utilisation de la mémoire et le processus sélectionné pour l’arrêt.
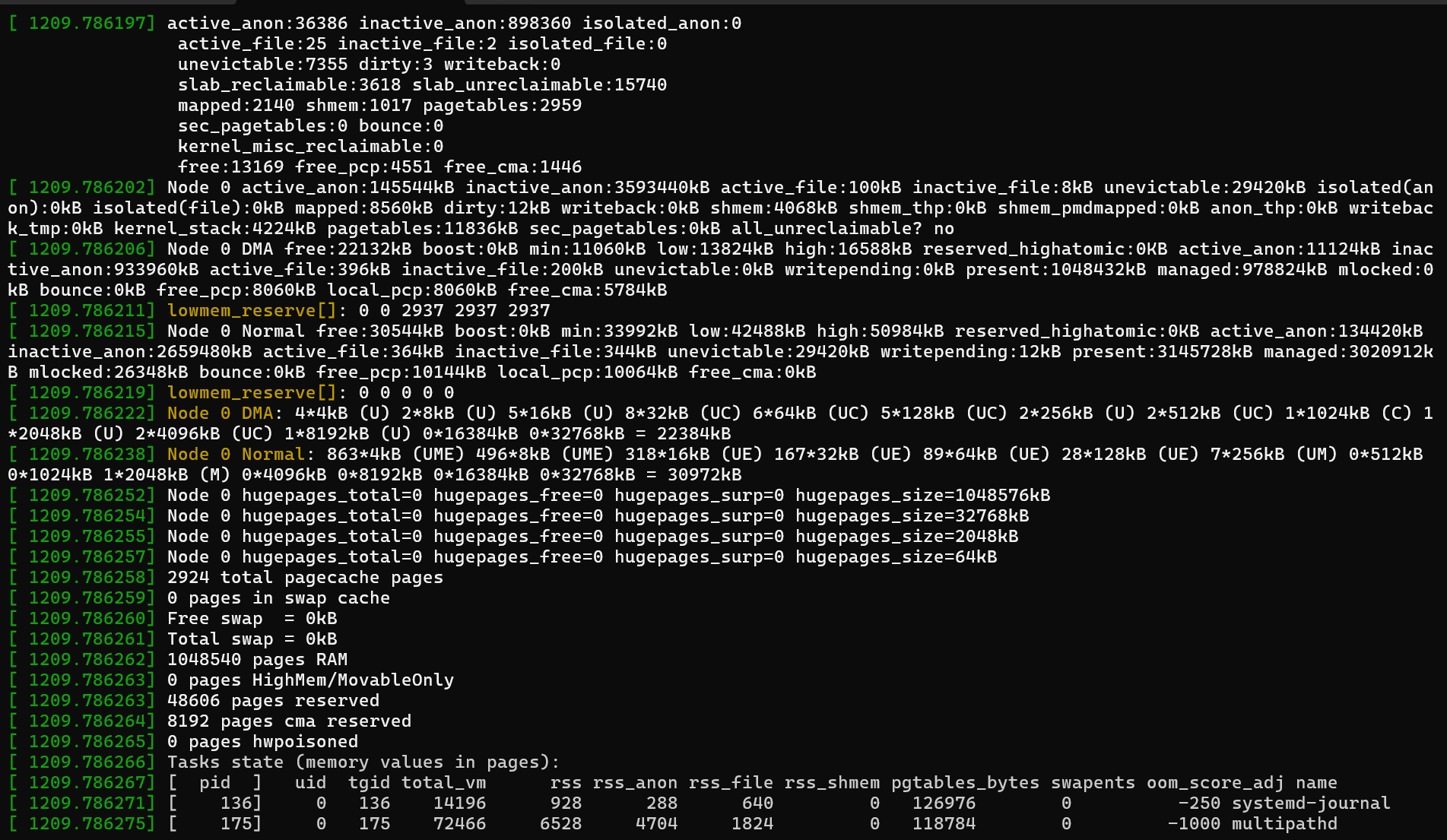
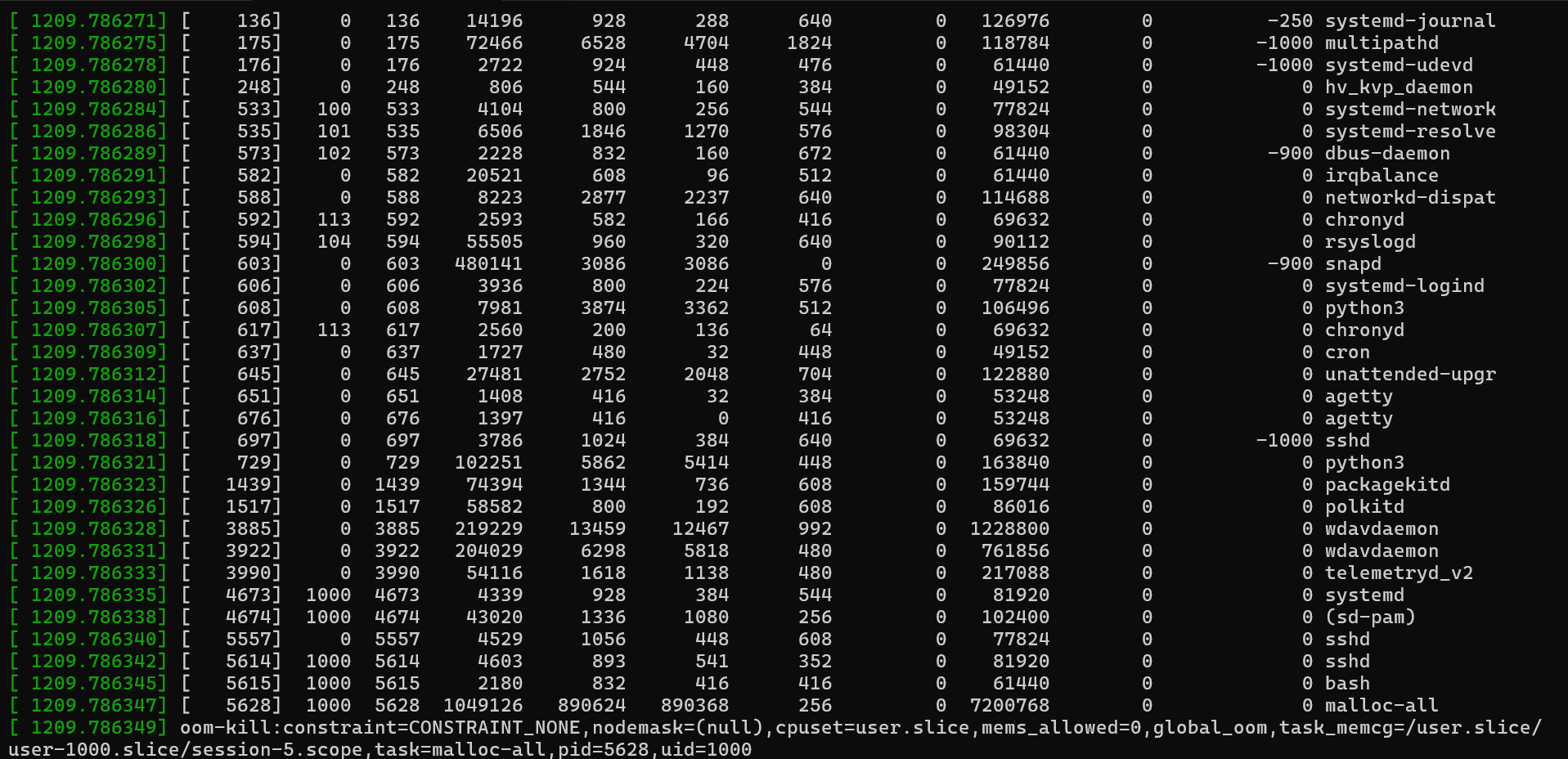
À partir de ces informations, vous pouvez extraire les insights suivants :
4194160 kBytes physical memory
No swap space
3829648 kBytes are in use
Dans l’exemple de journal suivant, le processus malloc a demandé une page de 4 Ko (order=0). Bien que la page 4 Ko soit petite, le système était déjà sous pression. Le journal indique que la mémoire a été allouée à partir de la « zone normale ».

La mémoire disponible (free) est de 29 500 Ko. Toutefois, le filigrane minimal (min) est de 34 628 Ko. Étant donné que le système est inférieur à ce seuil, seul le noyau peut utiliser la mémoire restante et les applications d’espace utilisateur sont refusées. Le tueur OOM est appelé à ce stade. Il sélectionne le processus ayant la plus grande oom_score et la plus grande utilisation de mémoire ('RSS'). Dans cet exemple, le processus malloc avait une oom_score valeur de 0, mais a également le plus élevé RSS (917760). Par conséquent, il est sélectionné comme cible pour la terminaison.
Surveiller la croissance progressive de la mémoire
Les événements OOM sont faciles à détecter, car les messages associés sont enregistrés dans la console et les journaux système. Toutefois, les augmentations progressives de l’utilisation de la mémoire qui ne provoquent pas d’événement OOM peuvent être plus difficiles à détecter.
Pour surveiller l’utilisation de la mémoire au fil du temps, utilisez l’outil sar à partir du sysstat package. Pour vous concentrer sur les détails de la mémoire, utilisez l’option « r » (par exemple, « sar -r »).
Exemple de sortie
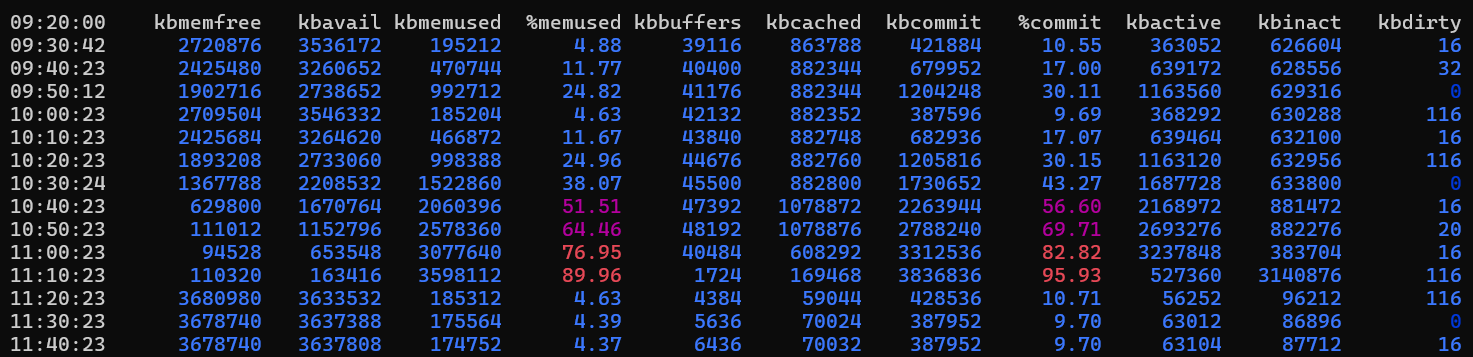
Dans ce cas, l’utilisation de la mémoire augmente pendant environ deux heures. Ensuite, il revient à quatre pour cent. Ce comportement peut être attendu, par exemple pendant les heures de connexion maximales ou les tâches de création de rapports nécessitant beaucoup de ressources. Pour déterminer si ce comportement est normal, vous devrez peut-être surveiller l’utilisation pendant plusieurs jours, puis la mettre en corrélation avec l’activité de l’application. L’utilisation élevée de la mémoire n’est pas nécessairement un problème. Cela dépend de la charge de travail et de la façon dont les applications sont conçues pour utiliser la mémoire.
Pour rechercher les processus qui consomment le plus de mémoire, utilisez pidstat.
Exemple de sortie
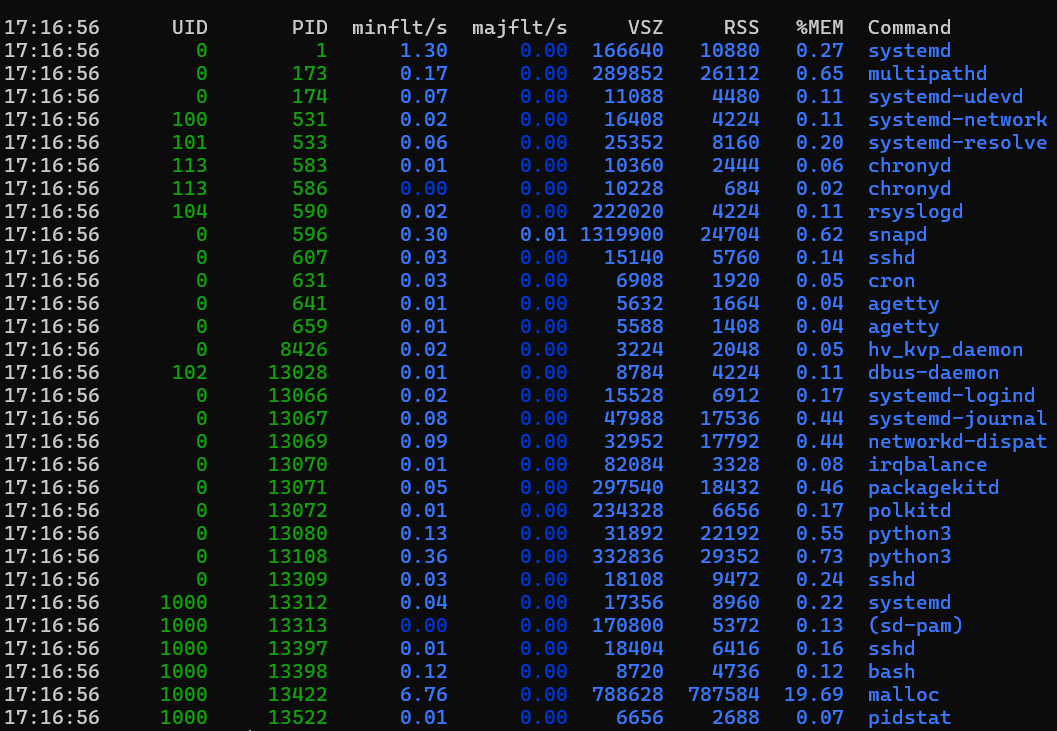
Cette sortie affiche tous les processus en cours d’exécution et leurs statistiques. Une autre approche consiste à utiliser l’outil « ps » pour obtenir des résultats similaires : ps aux --sort=-rss | head -n 10
Exemple de sortie

Pourquoi trier par RSS ?
La taille d’ensemble résidente (RSS) est la partie de la mémoire de processus conservée dans la RAM (mémoire physique non permutée). En revanche, Virtual Set Size (VSZ) représente la quantité totale de mémoire que le processus réserve, y compris la mémoire qui n'est pas allouée.
Committed memory fait référence aux pages réellement écrites en mémoire physique. Si vous essayez d’identifier les processus qui utilisent la mémoire physique la plus élevée (y compris l’échange), concentrez-vous sur la RSS colonne. Dans l’exemple de sortie, le snapd processus semble utiliser beaucoup de mémoire, mais sa RSS valeur est faible. Le malloc processus a des valeurs VSZ similaires et RSS qui indiquent qu’il utilise activement plus de 1,3 gigaoctets de mémoire.
Exclusion de responsabilité pour contact avec des tiers
Microsoft fournit des informations de contacts externes afin de vous aider à obtenir un support technique sur ce sujet. Ces informations de contact peuvent changer sans préavis. Microsoft ne garantit pas l’exactitude des informations concernant les sociétés externes.
Contactez-nous pour obtenir de l’aide
Si vous avez des questions ou avez besoin d’aide, créez une demande de support ou demandez le support de la communauté Azure. Vous pouvez également soumettre des commentaires sur les produits à la communauté de commentaires Azure.