Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : .NET sur Linux
Objectif de cette partie
Cette partie de la formation se concentre sur les répertoires spéciaux Linux, sur l’exécution de commandes en tant que superutilisateur (racine) et sur l’installation et la désinstallation d’applications à l’aide de gestionnaires de packages.
L’utilisation de gestionnaires de packages pour installer et supprimer des packages nécessite des privilèges racine. Par conséquent, vous devez d’abord comprendre comment exécuter des commandes en tant que superutilisateur.
Répertoires spéciaux Linux
Pour cette formation, il n’est pas nécessaire de plonger profondément dans la façon de gérer Linux. Toutefois, un résumé de certains répertoires spéciaux serait utile, car vous les utiliserez dans le reste de la formation.
| Répertoire | Description |
|---|---|
| / | Répertoire racine (dossier de niveau supérieur). |
| bin/ | Contient des fichiers binaires utilisateur, des fichiers exécutables. |
| /sbin | Contient des fichiers binaires utilisateur, des fichiers exécutables. |
| /etc | Contient les fichiers de configuration pour le système local et les applications. Par exemple, vous allez créer des fichiers de configuration dans le répertoire /etc/system pour permettre à l’application ASP.NET Core d’être démarrée automatiquement par le système. |
| /home | Contient le répertoire de base de chaque utilisateur. Par exemple, /home/<username>. |
| /tmp | Répertoire temporaire pour stocker des fichiers temporaires créés par le système et les applications. |
| /Usr | Stocke les fichiers partageables, notamment les exécutables, les bibliothèques et les documents. Par exemple, le runtime .NET et les kits sdk sont installés dans le répertoire /usr/share/dotnet/ . |
| /var | Stocke les fichiers de données variables. Par exemple, Apache stocke le contenu du site web racine dans le répertoire /var/www/html et les fichiers journaux dans le répertoire /var/log/apache2/ . Bien qu’il ne soit pas nécessaire, vous allez publier vos applications web dans ce répertoire. |
Note
Linux respecte la casse. Par conséquent, /home et /Home sont des répertoires différents, et le nom de fichier et le nom de fichier sont des fichiers différents.
Lorsque vous vous connectez pour la première fois à votre machine virtuelle Linux, vous commencerez à votre répertoire racine. Ce répertoire sera /home/<username>.
Le raccourci du répertoire racine est ~ (tilde). Vous pouvez utiliser la cd ~ commande à tout moment pour revenir au répertoire de base.
Passez en revue et essayez les commandes suivantes (illustrées dans la capture d’écran suivante) :
-
pwd(répertoire de travail d’impression) : imprime le répertoire actif et le répertoire /etc/systemd . -
echo: imprime la valeur du répertoire ~ (racine). -
cd ~: retourne le répertoire racine.
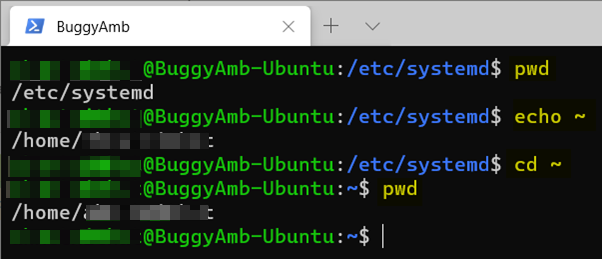
Cet exemple n’inclut pas la liste du contenu du répertoire. Toutefois, une étape ultérieure de cette formation couvre l’utilisation de fichiers et de dossiers. Certaines de ces tâches nécessitent des autorisations de superutilisateur. La section suivante explique comment vous élever à l’état superutilisateur.
Exécuter des commandes en tant que superutilisateur
Le superutilisateur est le compte d’utilisateur le plus privilégié. Il dispose d’un accès racine (illimité) à tous les fichiers et dossiers, et contrôle total sur l’opération de l’ordinateur. L’administrateur système utilise ce compte pour la maintenance du système.
Sur les systèmes de type UNIX, le nom conventionnel du superutilisateur est « root ». L’utilisateur racine peut effectuer des tâches qui sont autrement restreintes pour les utilisateurs standard, notamment les suivantes :
- Modification des répertoires système
- Modification des privilèges utilisateur
- Modification de la propriété du fichier
- Tâches liées au système, telles que les redémarrages
- Installation de certaines applications
Il existe plusieurs façons d’exécuter des commandes en tant qu’utilisateur de compte racine. L’une consiste à utiliser la sudo su commande. Dans cette commande, sudo est courte pour superuser do, et su est une abréviation de « changer d’utilisateur ». Vous pouvez également utiliser la su commande pour basculer entre les utilisateurs standard.
Important
Une fois que vous êtes devenu l’utilisateur du compte racine, tout ce que vous effectuez s’exécute dans le contexte racine. Par conséquent, vous devez agir attentivement, car le compte racine a accès à l’ensemble du système.
Pour illustrer un problème d’autorisations, créez un fichier texte dans un dossier spécial nommé /etc.
Le dossier /etc/ se trouve dans lequel se trouvent les fichiers de configuration système. Ce dossier protège son contenu contre la modification par un utilisateur standard.
Exécutez la commande suivante :
echo hello world > /etc/helloworld.txt
La echo commande écrit tout le texte qui le suit dans la sortie. Le crochet angle (>) indique au système d’envoyer la sortie au fichier /etc/helloworld.txt au lieu de la console. Ce comportement est similaire au fonctionnement de Windows.
Note
Linux respecte la casse : Helloworld.txt, helloworld.txt et helloworld. Txt sont des fichiers différents.
Vous n’avez pas besoin de fournir une extension de nom de fichier. Le nom « helloworld » lui-même est parfaitement valide. (L’extension « txt » est utilisée ici uniquement comme exemple.)
Lorsque vous exécutez cette commande, vous recevez un message d’erreur refusé par autorisation.

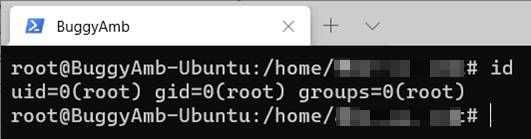
L’opération échoue, car le dossier /etc est un dossier spécial qu’un utilisateur standard ne peut pas modifier. Vérifiez l’utilisateur en exécutant la id commande.

Pour devenir l’utilisateur du compte racine, exécutez la sudo su commande.

Vous devez remarquer deux choses : lorsque vous devenez racine, le caractère de signe dollar ($) devient un caractère de signe de livre (#). En outre, le nom d’utilisateur est remplacé par la racine. Si vous réexécutez la même id commande, vous voyez que l’utilisateur et l’ID de groupe de la racine sont 0.
Important
Maintenant que vous vous êtes élevé au rôle « superutilisateur » dans votre session, vous avez un accès complet au système. Gardez à l’esprit qu’il s’agit d’une situation potentiellement dangereuse et que vous devez faire preuve de prudence au fur et à mesure que vous continuez.
À présent, exécutez la même commande une fois de plus :
echo hello world > /etc/helloworld.txt
Cette fois, vous ne recevez aucun message d’erreur. Pour vérifier si le fichier est créé, exécutez la commande suivante :
ll /etc/hello*
La ll commande répertorie les fichiers et sous-dossiers qui se trouvent dans un dossier spécifié. Dans cet exemple, la valeur du /etc/hello* paramètre limite la sortie de commande aux fichiers ou dossiers dont le nom commence .hello

La sortie indique que le fichier a été créé. Que se passe-t-il si nous voulons examiner le contenu du fichier ? La cat commande vous aide ici. Pour afficher le contenu, exécutez cat /etc/helloworld.txt.

La cat commande lit les fichiers de manière séquentielle et écrit leur contenu dans la sortie standard. Par conséquent, il écrit « hello world » dans la console.
Pour éviter les erreurs susceptibles d’endommager le système pendant que vous êtes élevé à l’état racine, il est recommandé de quitter la session racine et de revenir à votre session utilisateur standard pour éviter certaines opérations dangereuses. Pour cela, exécutez exit. Vous pouvez voir que le signe livre revient à un signe dollar et que le nom d’utilisateur s’affiche en tant qu’utilisateur standard.
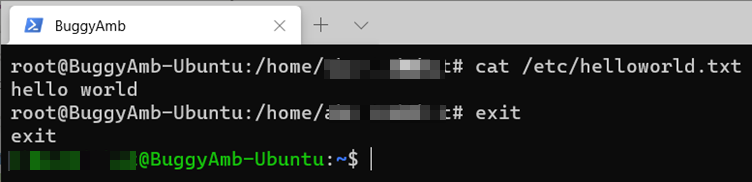
Pour une pratique supplémentaire, exécutez les mêmes ll commandes dans cat votre contexte utilisateur standard. Vous verrez que vous ne pouvez pas créer le fichier dans le dossier /etc/ , mais que vous pouvez répertorier le fichier et lire le contenu.
Exécuter des commandes à l’aide du préfixe « sudo »
Au lieu de devenir l’utilisateur du compte racine dans votre session, vous pouvez exécuter des commandes en tant que racine à l’aide du sudo <command> format. Cette approche est plus sûre, car elle exécute la commande donnée uniquement en tant que superutilisateur.
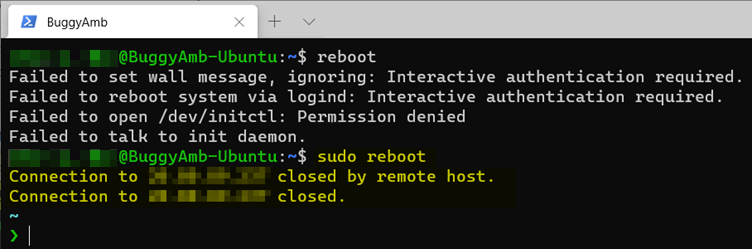
Par exemple, si vous exécutez restart pendant que vous n’êtes pas élevé à l’état superutilisateur, le résultat est le suivant.
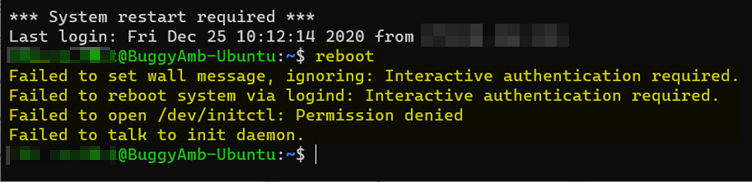
Pour exécuter cette commande en tant que superutilisateur à la place, vous pouvez modifier le contexte de session en racine (en exécutant sudo su) ou ajouter le sudo préfixe, comme suit :
sudo reboot
À présent, l’opération de redémarrage s’exécute comme prévu par la machine virtuelle.
Gestionnaires de package
Les gestionnaires de packages sont utilisés pour installer, mettre à niveau et supprimer des applications dans Linux. Il existe plusieurs gestionnaires de package différents, tels que DPKG (Système de gestion des packages Debian), RPM (Red Hat Gestionnaire de package) et Zypper pour les gestionnaires de package SUSE eux-mêmes sont de bas niveau. Par conséquent, il peut être difficile de gérer les logiciels directement à l’aide du gestionnaire de package. Heureusement, il existe des wrappers pour ces outils qui facilitent l’installation et la désinstallation de logiciels. Par exemple, yum est un wrapper autour de RPM (Red Hat Gestionnaire de package) et APT est un wrapper autour de DPKG (Debian Package Management System).
Ce tutoriel suppose que vous exécutez le système de gestion des packages Ubuntu. Ce système est dérivé du même système que celui utilisé par la distribution Debian GNU/Linux. Par conséquent, nous pouvons utiliser APT pour installer le logiciel.
Selon votre choix Linux, vous devrez peut-être utiliser d’autres outils. Par exemple, vous pouvez utiliser yum pour installer ou désinstaller des logiciels si vous exécutez Red Hat.
Mettre à niveau la base de données du gestionnaire de package
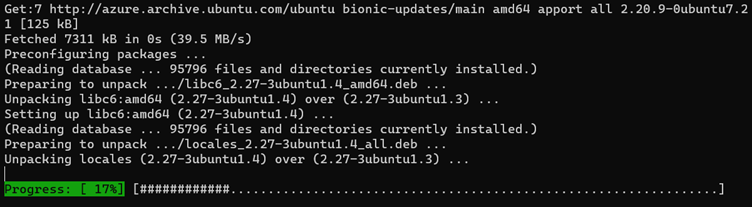
APT fonctionne sur une base de données de packages disponibles. Nous vous recommandons de mettre à jour les gestionnaires de packages, puis de mettre à niveau les packages après une nouvelle installation.
Pour mettre à jour la base de données de package sur Ubuntu, exécutez sudo apt update. Notez que le sudo préfixe est entré avant la apt commande. Pour ce faire, vous exécutez la apt commande en tant qu’utilisateur racine sans réellement modifier le contexte de session en celui de l’utilisateur racine.

La commande de mise à jour ne met pas à niveau les packages logiciels installés. Au lieu de cela, il met à jour la base de données du package. La mise à niveau réelle est effectuée par la sudo apt upgrade commande.

Après avoir tapé Y , puis appuyez sur Entrée, les packages sont mis à niveau.
Rechercher des packages à l’aide de gestionnaires de packages
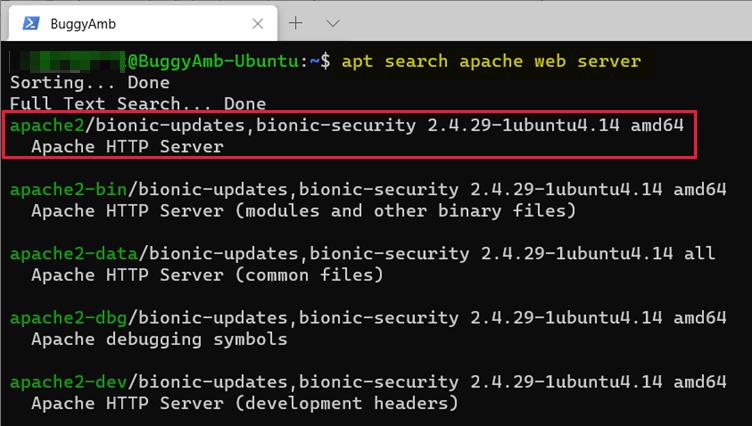
L’exemple suivant montre comment utiliser des gestionnaires de packages pour rechercher des packages, qui illustre l’installation et la désinstallation du serveur web Apache 2.
Commencez par rechercher sur « serveur web Apache » à l’aide de la apt search commande. APT effectue une recherche en texte intégral et affiche les résultats. Vous allez installer Apache HTTP Server à l’aide du nom du package de apache2.
Note
Utilisation de la commande. Le sudo préfixe n’est pas ajouté, car vous n’avez pas besoin d’être un utilisateur racine pour effectuer une recherche dans des packages.
Au lieu d’effectuer une recherche, vous pouvez effectuer une APT searchrecherche dans un navigateur web sur « comment installer Apache sur Ubuntu » pour rechercher le nom du package et la commande APT. Pour cet exemple, vous devez trouver ce document Ubuntu officiel qui explique clairement comment installer Apache 2 sur Ubuntu.
Afficher les détails du package
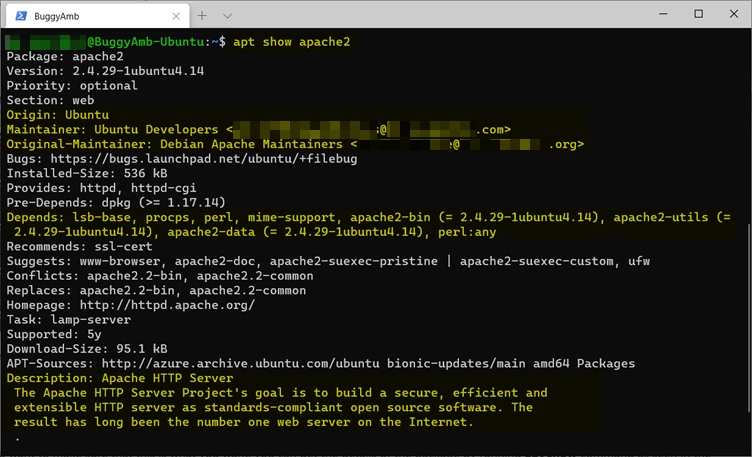
Pour vérifier que vous disposez du package approprié, exécutez apt show pour afficher les détails du package, comme illustré dans la capture d’écran suivante. Là encore, notez que le sudo préfixe n’est pas nécessaire ici.
Répertorier les packages installés et utiliser grep pour filtrer la liste
Après avoir déterminé que le package que vous avez trouvé est celui souhaité, vous devez vous assurer qu’il n’est pas déjà installé sur le serveur de destination.
Pour ce faire, utilisez la apt list --installed commande pour répertorier les applications installées sur la machine virtuelle. Vous pouvez également ajouter la commande grep pour filtrer les résultats pour afficher uniquement les applications qui contiennent apache2.
Note
La grep commande recherche un terme donné dans un fichier. Il s’agit d’un outil très puissant, car il fournit plusieurs options, telles que la recherche à l’aide d’une expression régulière ou d’une chaîne, l’invertissant les résultats de la recherche, ignorant la sensibilité de la casse, la recherche à l’aide de plusieurs termes de recherche et la prise en charge de la recherche récursive.
Lorsque vous exécutez apt list --installed | grep apache2, vous devez voir que le package n’est pas installé sur la machine virtuelle.

Installer le package
Maintenant que vous avez déterminé que vous avez trouvé le package souhaité et qu’il n’est pas déjà installé, vous pouvez poursuivre l’installation. Exécutez la commande suivante :
sudo apt install apache2
Note
Cette fois, nous faisons précéder la commande à l’aide sudo de cette commande, car cette commande modifie le système. Par conséquent, il doit s’agir du compte racine pour s’exécuter correctement. Le gestionnaire de package est assez gentil pour vous inviter à savoir si vous souhaitez vraiment installer l’application.
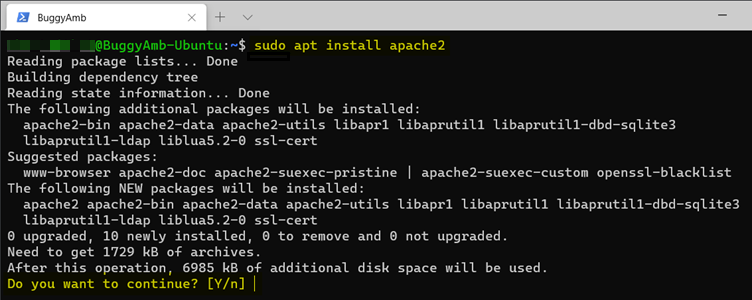
Tapez Y (oui), puis appuyez sur Entrée pour installer Apache2. Le gestionnaire de package affiche une barre de progression pour indiquer l’état de l’installation.

Si vous réexécutez la même apt list --installed | grep apache2 commande, vous voyez que le package Apache 2 est installé avec d’autres packages liés à Apache2 installés automatiquement.

Même si vous avez installé Apache 2, vous devez utiliser Nginx. Par conséquent, vous n’avez plus besoin d’Apache et vous pouvez supprimer ce package de la machine virtuelle.
Supprimer des packages
L’installation d’un package (dans ce cas, Apache 2) est réversible. Vous pouvez supprimer le package si vous déterminez que vous n’en avez pas besoin. Vous avez deux options de commande pour supprimer des packages :
apt remove: cette commande supprime les fichiers binaires, mais pas le fichier de configuration. Il est utile si vous envisagez de réinstaller le package et de conserver la même configuration.apt purge: cette commande supprime les fichiers binaires et le fichier de configuration.
Supprimez le package à l’aide apt remove d’un utilisateur racine pour voir le résultat. Pour ce faire, exécutez sudo apt remove apache2. Lorsque vous êtes invité à confirmer la suppression, tapez Y, puis appuyez sur Entrée.
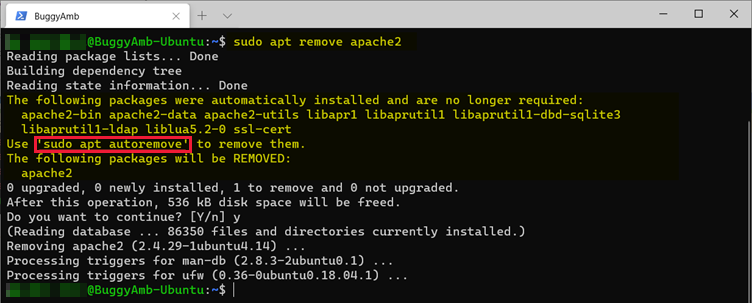
La sortie de commande vous indique les informations suivantes :
- APT a détecté qu’il existe des packages qui ont été installés automatiquement et ne seront plus nécessaires.
- APT a supprimé uniquement le
apache2package, et il vous recommande d’exécutersudo apt autoremovepour supprimer les packages associés.
Répertoriez à nouveau les packages installés. Vous voyez que le apache2 package est supprimé, mais que les packages installés automatiquement qui ont été fournis avec celui-ci restent installés.

Suivez la recommandation de réexécuter sudo apt autoremove pour supprimer les packages de gauche.
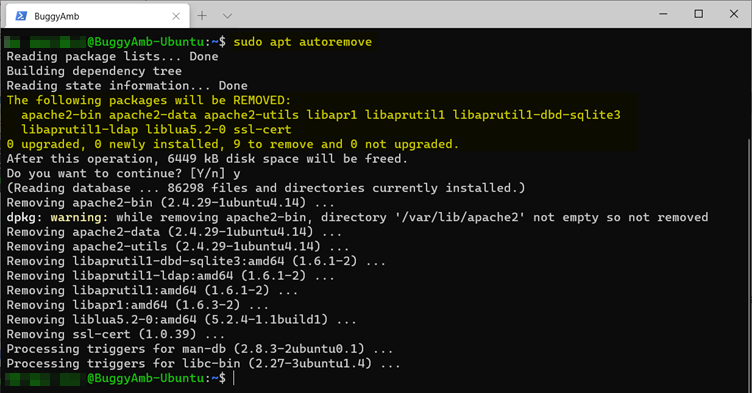
Répertoriez les packages installés une fois de plus. À présent, aucun package lié à Apache2 n’est installé.
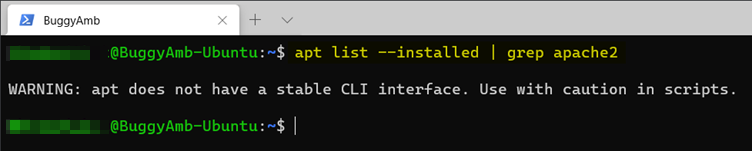
Cette procédure n’est pas terminée. N’oubliez pas que la différence entre apt remove le fichier de configuration et apt purge la suppression du fichier de configuration. Dans cet exercice, vous ne l’avez pas supprimé. Alors où est-ce ?
La recherche du fichier n’implique pas de gestionnaires de package. Au lieu de cela, vous allez exécuter une recherche standard des fichiers dans Linux. Plusieurs méthodes sont possibles. L’une des commandes de recherche les plus courantes est find. Toutefois, cette commande est également déroutante à utiliser, donc nous ne l’aborderons pas ici. Au lieu de cela, nous allons utiliser whereis.
Note
Linux est très bien documenté. Presque toutes les commandes ont une page d’aide utile disponible. Utilisez les commandes d’utilisateur et d’informations pour afficher les pages d’aide dans Linux. Par exemple, pour en savoir plus sur la find commande, exécutez man find ou info find.
Selon la page d’aide pour whereis, la définition est la suivante :
whereis recherche les fichiers binaires, sources et manuels pour les noms de commandes spécifiés.
Si vous exécutez whereis apache2, vous devez trouver l’installation de /etc/apache2 .
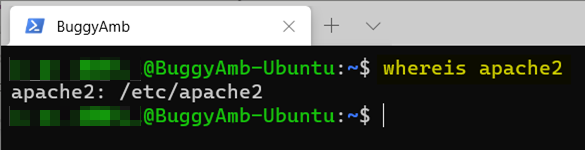
N’oubliez pas que le répertoire /etc/ est l’emplacement des fichiers de configuration système. Pour savoir si « apache2 » est un fichier ou un dossier, exécutez ll /etc/apache2. Comme vous pouvez le voir, il s’agit d’un dossier et contient les fichiers de configuration Apache2.
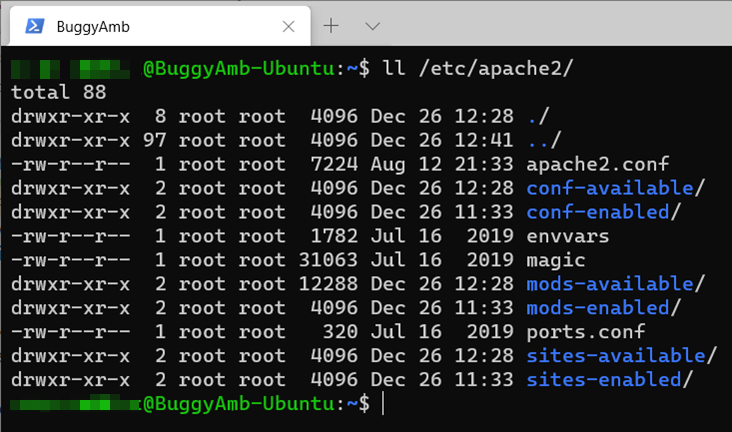
Vous prévoyez apache2 de contenir ces fichiers et dossiers, car vous avez utilisé la apt remove commande qui ne supprime pas les fichiers de configuration.
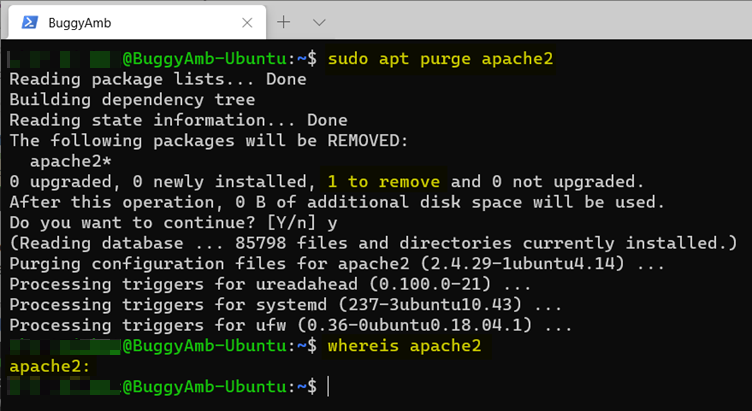
En guise d’étape finale, exécutez la apt purge commande pour voir son effet. Vous pouvez exécuter un vidage pour nettoyer le dossier d’installation même après avoir supprimé le package. La capture d’écran suivante montre que whereis rien n’a trouvé. Cela est dû au fait que la purge commande a supprimé les fichiers de configuration avec les fichiers binaires.
Prochaines étapes
Partie 1.3 - Installer .NET dans Linux
Exclusion de responsabilité de tiers
Les produits tiers mentionnés dans le présent article sont fabriqués par des sociétés indépendantes de Microsoft. Microsoft exclut toute garantie, implicite ou autre, concernant les performances ou la fiabilité de ces produits.