Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : .NET Core 2.1, .NET Core 3.1, .NET 5
Cet article vous aide à considérer le processus de résolution des problèmes dans son ensemble.
Prerequisites
Comme dans les parties précédentes, cette partie est structurée pour mettre davantage l’accent sur la théorie et les principaux à suivre lorsque vous commencez à résoudre les problèmes. Elle n’a aucun prérequis. Toutefois, vous devez avoir déjà configuré les éléments suivants si vous avez suivi toutes les étapes de cette formation jusqu’à présent :
- Nginx a deux sites web :
- Le premier site web écoute les requêtes à l’aide de l’en-tête de l’hôte myfirstwebsite (
http://myfirstwebsite) et route les requêtes vers l’application demo ASP.NET Core qui écoute sur le port 5000. - Le deuxième site web écoute les requêtes à l’aide de l’en-tête de l’hôte buggyamb (
http://buggyamb) et route les requêtes vers la deuxième application ASP.NET Core de bogues qui écoute sur le port 5001.
- Le premier site web écoute les requêtes à l’aide de l’en-tête de l’hôte myfirstwebsite (
- Les deux applications ASP.NET Core s’exécutent en tant que services qui redémarrent automatiquement lorsque le serveur est redémarré, ou les applications cesse de répondre ou échouent.
- Un pare-feu local Linux est activé et configuré pour autoriser le trafic SSH et HTTP.
Objectif de cette partie
Lorsque vous préparez à résoudre les problèmes que vous pouvez rencontrer si vous avez la configuration décrite précédemment, cette partie fournit des conseils pour obtenir des informations sur l’exécution des processus sur Linux.
Tout est-il dans Linux un fichier ?
Vous pouvez entendre l’expression « tout dans Linux est fichier ». Est-ce que cette expression est vraiment le cas ? Bien que cette série d’articles ne se concentre pas sur l’expertise Linux, le système d’exploitation Linux est fortement axé sur l’exposition de tout via le système de fichiers. Cette partie tentera d’approfondir la raison pour laquelle c’est.
Selon Wikipédia, Linux est basé sur un système de fichiers spécial nommé procfs.
Le système de fichiers proc (procfs) est un système de fichiers spécial dans des systèmes d’exploitation de type Unix qui présente des informations sur les processus et d’autres informations système dans une structure hiérarchique de type fichier. Cela fournit une méthode plus pratique et standardisée que les méthodes de traçage traditionnelles ou l’accès direct à la mémoire du noyau pour accéder dynamiquement aux données de traitement conservées dans le noyau. En règle générale, les données sont mappées à un point de montage nommé /proc au moment du démarrage. Le système de fichiers proc agit comme une interface pour les structures de données internes dans le noyau. Vous pouvez utiliser le fichier pour obtenir des informations sur le système et modifier certains paramètres du noyau au moment de l’exécution (sysctl).
Par conséquent, si vous êtes un superutilisateur sur un ordinateur Linux, vous pouvez accéder à des informations sur chacun des processus en cours d’exécution via un fichier de système de fichiers. Si tout dans Linux est un fichier, il s’agit donc d’un processus.
Vous pouvez vous rappeler que nous avons brièvement abordé cela dans les parties précédentes de cette série : un processus est considéré comme un fichier sous le répertoire /proc/ . Ce répertoire est défini comme un répertoire spécial ici :
« Ce répertoire spécial contient tous les détails sur votre système Linux, y compris son noyau, ses processus et ses paramètres de configuration. »
Si vous examinez ce répertoire à l’aide de la ll /proc/ commande, plusieurs « fichiers » et « dossiers » s’affichent. Par exemple, vous verrez un « fichier » nommé /proc/meminfo. cela, si vous exécutez la cat /proc/meminfo commande, génère les informations détaillées suivantes sur les statistiques d’utilisation de la mémoire du serveur :

De même, si vous exécutez la cat /proc/cpuinfo commande, ou verra les informations suivantes sur le processeur de serveur :

Si vous souhaitez obtenir des informations sur la version du système d’exploitation Linux, vous pouvez utiliser cat /proc/version des commandes :

Et ainsi de suite.
Un processus est-il vraiment un fichier ?
En ce qui concerne les processus, chaque processus en cours d’exécution sur votre système Linux s’affiche sous le sous-répertoire sous le /proc/ dossier, et chaque dossier est nommé en tant qu’ID de processus :
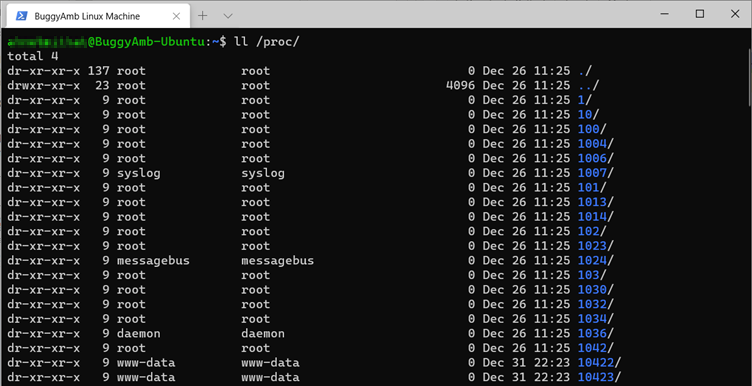
Si vous examinez l’un des répertoires d’ID de processus, vous verrez d’autres fichiers et dossiers. Vous devez préfixer la commande à l’aide de « sudo » pour obtenir certaines des informations suivantes :
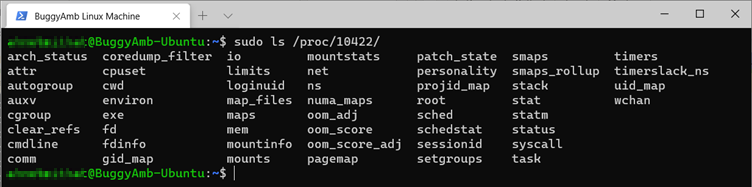
Examinez l’un cmdline des processus. Exécutez la commande sudo cat /proc/19933/cmdline. (Le PID du processus que vous choisissez sera différent). La sortie se présentera comme suit. (Il s’agit de l’application BuggyAmb qui a été installée et configurée dans la partie 2).

Enfin, examinons les variables d’environnement du processus BuggyAmb en exécutant la sudo cat /proc/19933/environ commande. Dans une partie précédente, vous avez été invité à utiliser la variable d’environnement ASPNETCORE_URLS . Cette opération a été créée pour indiquer à l’application web d’écouter sur le port 5001 :

En utilisant cette technique de système de fichiers, vous pouvez obtenir beaucoup d’informations sur un processus.
Commande ps
Cet article ne sera pas détaillé sur cette commande. Toutefois, la commande mérite d’être mentionnée ici dans la discussion des processus, car il s’agit de l’une des façons les plus simples de générer un instantané des processus actuels. Nous vous recommandons d’ouvrir la page « man » à l’aide de la man ps commande et de l’essayer pour vous-même.
Prochaines étapes
Partie 3.2 - Gestionnaires de tâches Linux, top et htop
La partie suivante examine certains outils et commandes importants que vous pouvez utiliser pour résoudre les problèmes.