Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : .NET Core 2.1, .NET Core 3.1, .NET 5
Cet article vous aide à analyser les problèmes de performances et explique comment utiliser createdump et ProcDump pour capturer manuellement les fichiers de vidage de mémoire .NET Core dans Linux.
Prerequisites
Les conditions minimales requises pour suivre ces laboratoires de résolution des problèmes sont les suivantes :
- Une application ASP.NET Core pour illustrer les problèmes de faible niveau de processeur et de performances de l’UC et les problèmes d’incident.
- Débogueur lldb, installé et configuré pour charger l’extension SOS lorsqu’un vidage principal est ouvert.
Si vous avez suivi les parties précédentes de cette série, vous devez disposer de la configuration suivante prête à être effectuée :
- Nginx est configuré pour héberger deux sites web :
- Le premier écoute les requêtes en utilisant l’en-tête de l’hôte myfirstwebsite (
http://myfirstwebsite) et les demandes de routage vers l’application de démonstration ASP.NET Core qui écoute sur le port 5000. - La deuxième écoute les requêtes à l’aide de l’en-tête de l’hôte buggyamb (
http://buggyamb) et du routage des requêtes vers la deuxième application d’exemple de bogue ASP.NET core qui écoute sur le port 5001.
- Le premier écoute les requêtes en utilisant l’en-tête de l’hôte myfirstwebsite (
- Les deux applications ASP.NET Core doivent s’exécuter en tant que services qui redémarrent automatiquement lorsque le serveur est redémarré ou que l’application cesse de répondre.
- Le pare-feu local Linux est activé et configuré pour autoriser le trafic SSH et HTTP.
Note
Si votre configuration n’est pas prête, accédez à « Partie 2 Créer et exécuter des applications ASP.NET Core ».
Objectif de ce labo
Jusqu’à présent dans cette série de résolution des problèmes, vous avez analysé un problème d’incident. Dans ce labo, vous aurez la chance d’analyser un problème de performances et d’apprendre à utiliser createump et ProcDump pour capturer manuellement les fichiers de vidage de mémoire.
Reproduire le problème
Dans une partie précédente, vous avez testé le premier scénario « lent » en sélectionnant le lien Lent . Lorsque vous effectuez cette opération, la page se charge correctement, mais beaucoup plus lentement que prévu. Dans cette partie, vous allez utiliser la fonctionnalité Générateur de charge BuggyAmb pour résoudre ce problème de performances. Il s’agit d’une fonctionnalité « expérimentale » qui envoie jusqu’à six requêtes simultanées à toute ressource problématique. Il est limité à six, car il utilise des appels jQuery et Ajax pour émettre les requêtes. Les navigateurs web définissent une limite sur la plupart des requêtes Ajax sur six requêtes simultanées à une URL donnée. Si vous souhaitez apprendre à utiliser le générateur de charge pour reproduire différents scénarios, consultez « Générateur de charge » expérimental.
Pour reproduire le problème, ouvrez pages de problèmes, sélectionnez Générateur de charge, puis envoyez six requêtes dans le scénario lent .
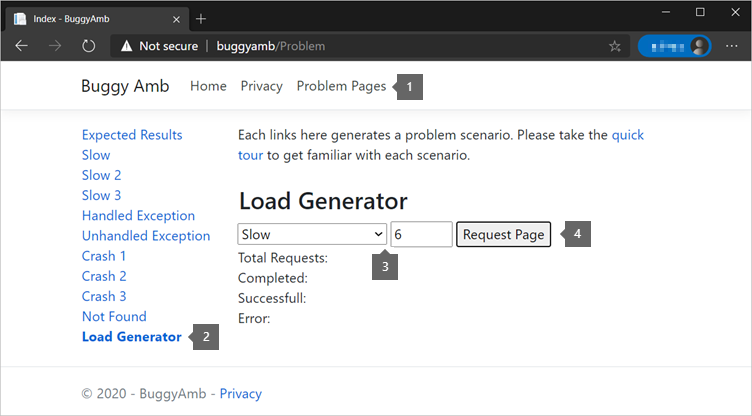
La liste suivante montre ce que vous devez, éventuellement, voir dans votre navigateur. Les temps de réponse affichés sont élevés. Le temps de réponse attendu est inférieur à une seconde. C’est ce que vous pouvez vous attendre à voir quand vous sélectionnez le lien Résultats attendus dans la page d’accueil de l’application.
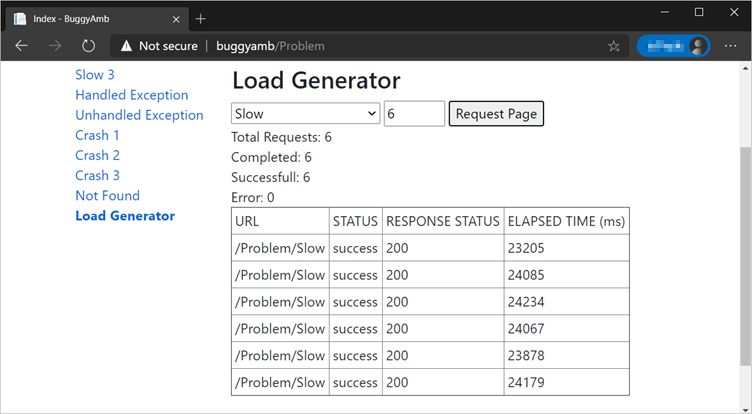
Il s’agit du problème que vous allez résoudre.
Surveiller les symptômes
N’oubliez pas qu’une bonne session de résolution des problèmes commence par définir le problème et comprendre les symptômes. Vous allez utiliser htop pour surveiller l’utilisation de la mémoire du processus et du processeur pour le processus qui héberge l’application ASP.NET Core lorsque vous essayez de reproduire le problème en générant la charge. Si vous ne vous souvenez pas de ce qui htop est, vérifiez les parties de la série précédente.
Avant d’essayer de reproduire le problème, commencez par définir une ligne de base pour la façon dont l’application doit effectuer. Sélectionnez Résultats attendus ou envoyez plusieurs requêtes au scénario Résultats attendus à l’aide de la fonctionnalité Générateur de charge. Vérifiez ensuite à quoi ressemble l’utilisation de l’UC et de la mémoire lorsque le problème ne se manifeste pas. Vous allez utiliser htop pour vérifier l’utilisation du processeur et de la mémoire.
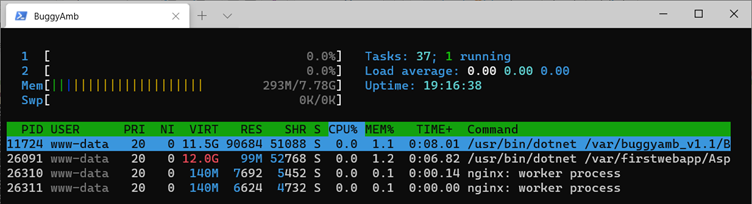
Exécutez et filtrez-le htoppour afficher uniquement les processus qui appartiennent à l’utilisateur sous lequel l’application buggy est exécutée. L’utilisateur de l’application cible ASP.NET Core dans ce cas est www-data. Appuyez sur la touche U pour sélectionner cet utilisateur www-data dans la liste. Appuyez également sur Maj+H pour masquer les threads. Comme vous pouvez le constater, il existe quatre processus s’exécutant dans le contexte de www-data, et deux d’entre eux sont les processus Nginx. Les autres concernent l’application buggy et l’application de démonstration que vous avez créée lors de la configuration de l’environnement.
Comme vous n’avez pas encore reproduit le problème de performances, notez que toutes les statistiques d’utilisation du processeur et de la mémoire sont actuellement faibles.
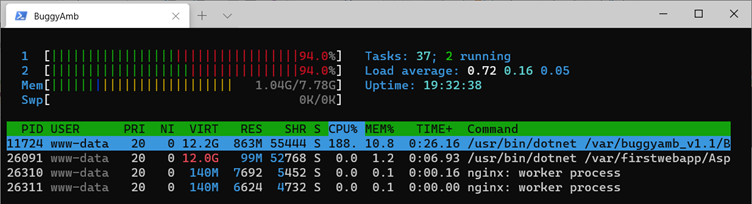
À présent, revenez à votre navigateur client et envoyez six requêtes au scénario lent à l’aide du générateur de charge. Ensuite, revenez rapidement à votre appareil Linux et observez la consommation des ressources de processus dans htop. Vous devriez voir que l’utilisation du processeur de l’application buggy a augmenté considérablement, et l’utilisation de la mémoire varie en hausse et en baisse.
Note
Étant donné que cette sortie est extraite d’une machine virtuelle dotée de deux PROCESSEURs logiques, htop affiche plus de 100 % d’utilisation du processeur.
Une fois toutes les requêtes traitées, l’utilisation du processeur et de la mémoire diminue. Les tendances d’utilisation du processeur et de la mémoire doivent vous faire croire qu’il peut y avoir une utilisation intensive du GC (Garbage Collector) dans l’application pendant le traitement des demandes.
Collecter les fichiers de vidage de base
Lorsque vous résolvez un problème de performances, les fichiers de vidage de mémoire consécutifs sont capturés et analysés. L’idée derrière la capture de plusieurs fichiers de vidage est simple : un vidage de processus est un instantané de la mémoire du processus. Il ne contient aucune information passée. Pour résoudre les problèmes de performances, vous devez capturer plusieurs fichiers de vidage de mémoire manuelle ou fichiers de vidage de base afin de pouvoir comparer les threads et les tas, et ainsi de suite.
Utilisez les options recommandées suivantes pour capturer les fichiers de vidage de mémoire manuelle à la demande :
- Createdump
- Procdump
- Dotnet-dump
Createdump
Createdump est inclus avec le runtime .NET Core. Il se trouve dans le répertoire d’exécution. Vous pouvez trouver vos chemins d’accès au répertoire d’exécution à l’aide de la dotnet --list-runtimes commande.

Étant donné que l’application buggy est une application .NET Core 3.1, le chemin complet de createdump est /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.10/createdump.
La forme la plus simple de cette commande est createdump <PID>. Cela écrit un vidage de base pour le processus cible. Vous pouvez indiquer l’outil où créer les fichiers de vidage en ajoutant le -f commutateur : createdump <PID> -f <filepath>. Pour cet exercice, créez les fichiers de vidage dans le ~/dumps/ répertoire.
Vous allez capturer deux fichiers de vidage de mémoire consécutifs du processus BuggyAmb 10 secondes à part. Vous devez capturer les fichiers de vidage pendant que vous reproduisez le problème de « réponse lente aux demandes ». Pour commencer, vous devez d’abord trouver le PID du processus. Utilisez la ou systemctl status buggyamb.service la htop commande. Dans les listes suivantes, le PID de processus est 11724.
Pour créer les fichiers de vidage, procédez comme suit :
- Créez le premier fichier :
sudo /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.10/createdump 11724 -f ~/dumps/coredump.manual.1.%d. - Attendez 10 secondes après l’écriture du premier fichier de vidage.
- Créez le deuxième fichier :
sudo /usr/share/dotnet/shared/Microsoft.NETCore.App/3.1.10/createdump 11724 -f ~/dumps/coredump.manual.2.%d
À la fin, vous devez avoir deux fichiers de vidage de mémoire. Notez la taille de chaque fichier de vidage.

Analyser les fichiers de vidage dans lldb
Vous devez déjà savoir comment ouvrir des fichiers de vidage dans lldb. Ouvrez les deux fichiers dans lldb dans deux sessions SSH différentes.
Votre objectif est de développer une théorie sur ce qui pourrait causer le problème de performance. Vous savez déjà que l’utilisation du processeur et de la mémoire est élevée lorsque le problème se produit. Pour vérifier la mémoire managée, vous pouvez utiliser la dumpheap -stat commande. Avant de commencer, examinez rapidement le premier fichier de vidage.
Exécutez la clrthreads commande pour obtenir la liste des threads managés.
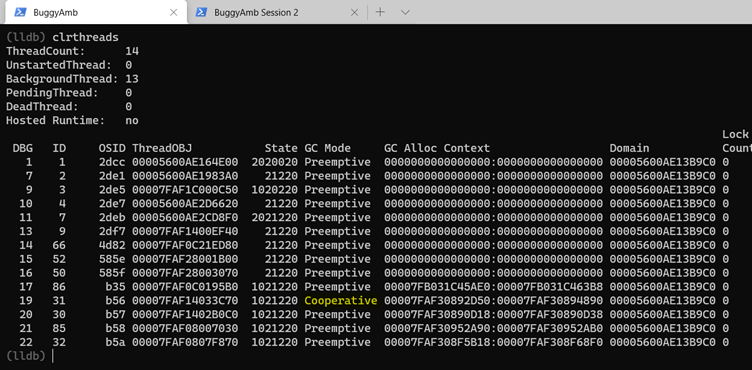
Note
L’un des threads a le mode GC défini sur Coopérative, et les autres sont définis sur Préemptive.
Si le mode GC d’un thread est défini sur Préemptive, cela signifie que le GC peut suspendre ce thread à tout moment. En revanche, le mode coopérative signifie que le GC doit attendre que le thread bascule vers le mode préemptif avant de le suspendre. Lorsque le thread exécute du code managé, il est en mode coopérative.
Commencez par examiner le thread en mode coopérative. L’ID de thread du débogueur pour le thread coopératif est 19 dans l’exemple de liste. L’ID diffère lorsque vous répétez l’exercice. Basculez vers le thread en cours d’exécution thread select 19, puis exécutez pour répertorier clrstack la pile des appels managés. La page « lente » de l’application buggy effectue une opération de chaîne concat.
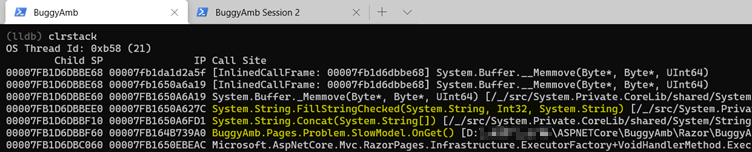
Cela doit vous rendre suspect, car vous devez savoir que les opérations concat de chaîne sont coûteuses. Cela est dû au fait que les objets de chaîne dans .NET sont immuables, ce qui signifie que leurs valeurs ne peuvent pas être modifiées après leur affectation. Considérez cet extrait de code pseudo :
string myText = "Debugging";
myText = myText + " .NET Core";
myText = myText + " is awesome";
Ce code crée plusieurs chaînes en mémoire : Debugging, Debugging .NET Coreet Debugging .NET Core is awesome. Trois objets de chaîne différents doivent être créés pour générer (concaténer) une chaîne finale. Si cela se produit assez fréquemment, il peut créer une pression de mémoire afin que le GC puisse être déclenché.
Cette théorie semble prometteuse. Toutefois, vous devez essayer de vérifier qu’il est correct. Avant d’examiner le tas managé, et pendant que vous êtes déjà positionné sur le contexte de thread, inspectez les objets référencés à partir de ce thread pour essayer de déterminer les valeurs de chaîne et string[] d’objets. Exécutez et concentrez-vous dsosur des tableaux de chaînes et de chaînes.
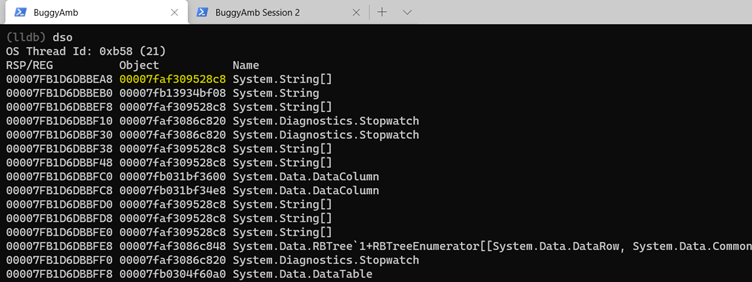
Essayez d’inspecter le tableau de chaînes. Exécutez à dumpobj l’aide de l’adresse de l’objet. Toutefois, sachez que cela montre uniquement que l’objet en question est un tableau. SOS fournit une dumparray commande pour examiner les tableaux. Exécutez dumparray 00007faf309528c8 pour obtenir la liste des éléments du tableau. (N’oubliez pas que l’adresse de l’objet tableau sera différente dans le fichier de vidage que vous examinez.)
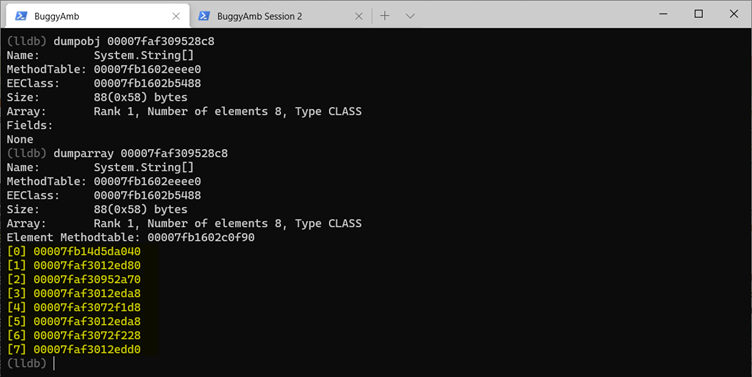
Réexécutez la dumpobj commande à l’aide des adresses de chaîne résultantes contenues dans le tableau. Choisissez certaines des adresses et examinez-les.
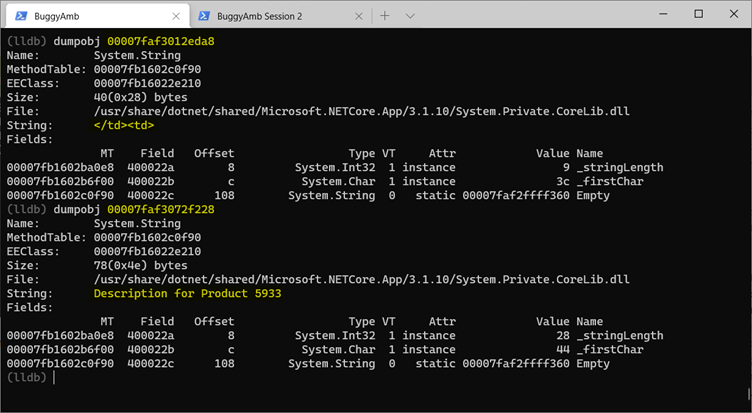
Ces chaînes ressemblent aux chaînes qui se trouvent dans la table de produits affichées par la page.
Notez que lldb (ou SOS) peut ne pas afficher la valeur de chaîne si les chaînes sont volumineuses. Dans ce cas, l’une de vos options consiste à utiliser les commandes natives de lldb pour examiner l’adresse mémoire native. Cela est similaire à l’utilisation d* des commandes (par exemple) dcdans WinDbg.
La commande suivante lit la mémoire native à l’emplacement de mémoire donné et affiche les 384 premiers octets. La liste utilise l’une des adresses de chaîne pour l’illustrer. La commande en cours d’exécution est memory read -c 384 00007fb14d5da040.
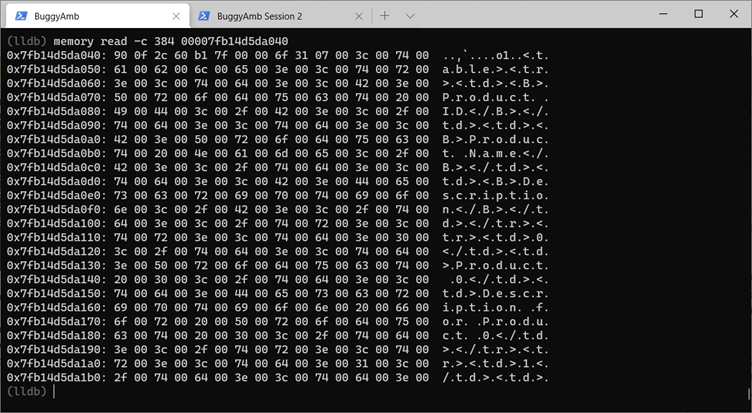
Le nombre de chaînes référencées par la pile du thread semble confirmer la théorie selon laquelle le problème de chaîne est à l’origine du problème de performances.
Toutefois, l’enquête n’est pas encore terminée. Vous avez deux fichiers de vidage de mémoire. Par conséquent, vous allez comparer le tas de mémoire managée et vérifier la façon dont le tas a changé dans le temps.
Exécutez la dumpheap -stat commande dans chaque fichier de vidage. Voici ce qui suit à partir du premier fichier. Dans la liste ci-dessous, il existe 105 401 objets de chaîne et la taille totale des objets de chaîne est d’environ 480 Mo. Notez également que la mémoire est éventuellement fragmentée et que la raison de la fragmentation semble être liée aux objets et System.Data.DataRow objets de tableau de chaînes.
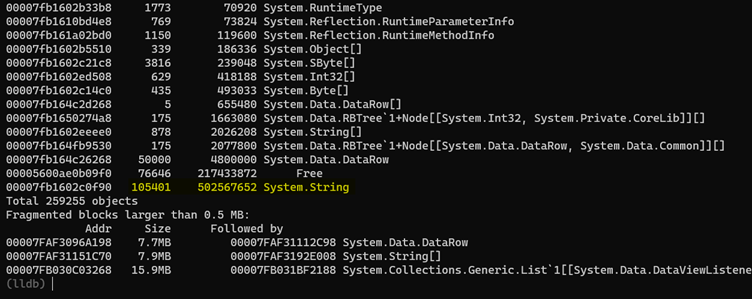
Continuez en exécutant la même dumpheap -stat commande dans le deuxième fichier de vidage. Vous devriez voir un changement dans les statistiques de fragmentation, mais ce n’est pas important dans le contexte de cette enquête. La partie importante est le nombre d’objets de chaîne et l’augmentation significative de la taille de ces objets.
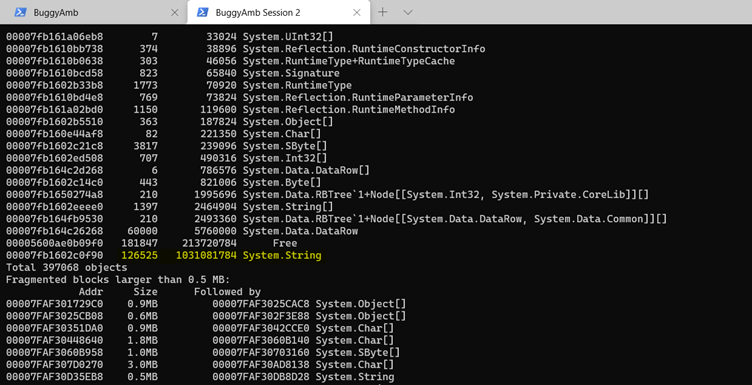
En même temps, le nombre d’objets System.Data.DataRow augmente également.
Vous pouvez soupçonner qu’il y a un problème qui implique un tas d’objets volumineux (LOH). Par conséquent, vous souhaiterez peut-être examiner les objets LOH. Dans ce cas, vous devez exécuter les dumpheap -stat -min 85000 commandes. La liste suivante contient les statistiques de LOH pour le premier vidage de mémoire.
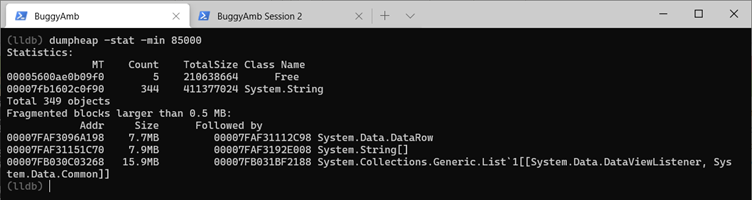
Et voici les statistiques de LOH pour le second vidage de mémoire.
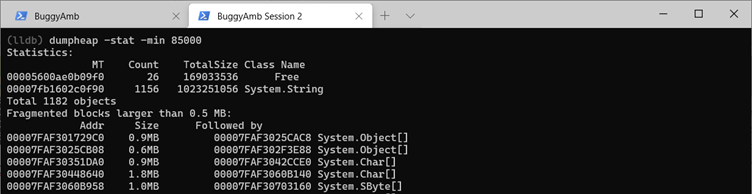
Cela montre également clairement l’augmentation du tas. Tout cela semble être lié aux string objets.
Enfin, que se passe-t-il si vous deviez choisir un objet « live » de LOH pour trouver sa racine ? « Live », dans ce cas, signifie que l’objet est rooté quelque part et, par conséquent, est utilisé activement par l’application afin que le processus GC ne le supprime pas.
La gestion de cette situation est facile. Exécutez dumpheap -stat -min 85000 -live. Cette commande affiche uniquement les objets qui sont enracinés quelque part. Dans cet exemple, il n’existe que des instances appropriées d’objets string vivant dans le LOH.
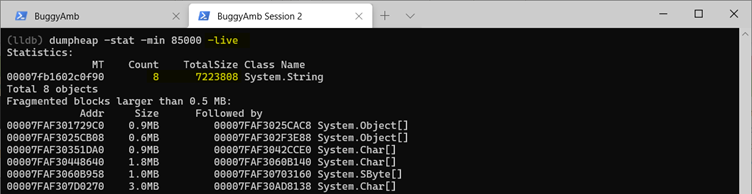
Utilisez l’adresse MT de l’objet string pour obtenir la liste des adresses de ces objets actifs. Exécutez dumpheap -mt 00007fb1602c0f90 -min 85000 -live.
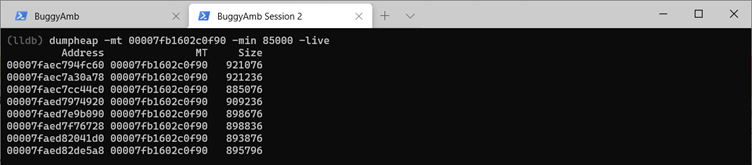
À présent, choisissez une adresse de façon aléatoire dans la liste résultante. Dans la capture d’écran suivante, la troisième adresse de la liste s’affiche. Vous pouvez essayer d’examiner l’adresse choisie en exécutant dumpobj. Toutefois, étant donné qu’il s’agit d’un objet volumineux, le débogueur n’affiche pas la valeur. Par conséquent, inspectez l’adresse mémoire native une fois de plus, et vous verrez qu’il s’agit d’un string objet qui ressemble à ce que vous pouvez trouver dans la liste de la table de produits sur la page qui répond lentement.
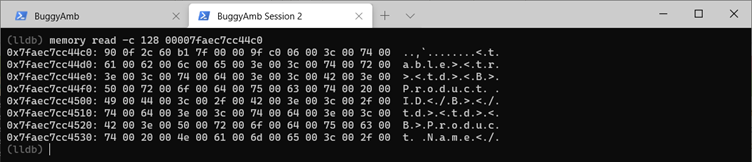
Examinez la racine de l’objet que vous avez répertorié. Pour ce faire, utilisez la commande SOS gcroot . Cette commande prend simplement l’adresse de l’objet en tant que paramètre sous sa forme la plus simple. Comme vous pouvez le voir, cela string est rooté au thread où la page « lente » est exécutée. Vous devez même voir le nom du fichier source et les informations de numéro de ligne.
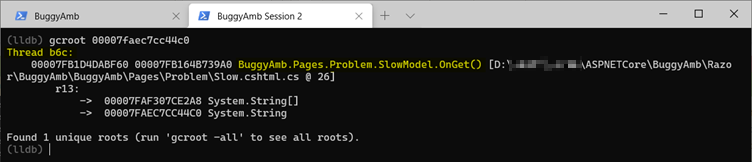
Note
L’affichage du nom de fichier source et des informations de numéro de ligne dépend de l’emplacement où vous résolvez les problèmes et si vos symboles sont correctement définis. Dans le pire des cas, vous pouvez au moins récupérer l’ID de thread. Dans la liste suivante, b6c est un ID de thread managé. Si vous exécutez clrthreads, vous trouverez l’ID de thread correspondant.
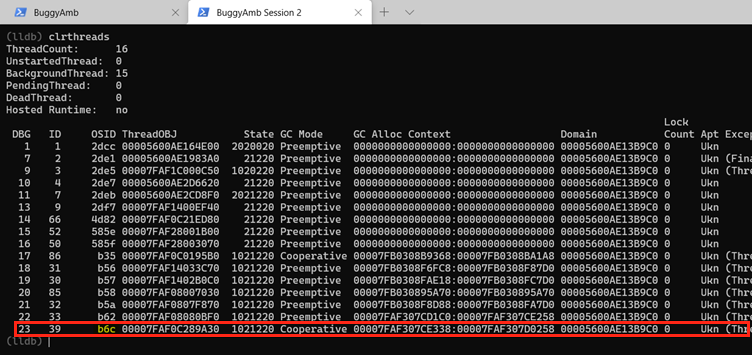
Comme illustré dans la capture d’écran ci-dessus, l’ID de thread du débogueur pour l’ID de thread managé b6c est 23. Basculez vers le thread 23 et vérifiez la pile des appels managés. Comme vous l’avez vu précédemment, ce thread doit également effectuer des opérations concat de chaîne.
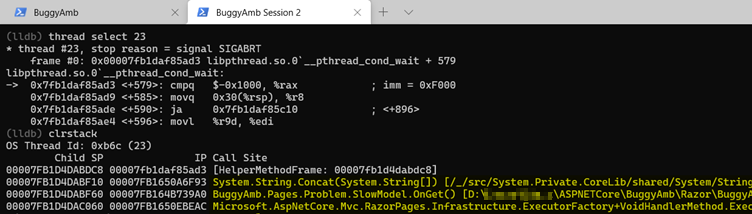
Et si vous examinez la pile des appels natifs à l’aide de la bt commande, vous remarquerez peut-être que le GC alloue de la mémoire pour ce thread.
Cette preuve confirme la théorie selon laquelle le problème est lié à un grand nombre d’opérations de concaténation de chaînes qui créent des chaînes toujours plus grandes qui sont déclenchées pendant le traitement d’une page « lente ».
La solution à ce problème n’est pas dans l’étendue de cette série. Toutefois, sachez que la solution est facile à implémenter à l’aide d’une StringBuilder instance de classe au lieu d’opérations concat de chaîne.
Prochaines étapes
Lab 2.2 Capturez des fichiers de vidage à l’aide de ProcDump