Résolution des problèmes de file d’attente de récupération dans un groupe de disponibilité Always On
Cet article fournit des solutions aux problèmes liés à la mise en file d’attente de récupération.
Qu’est-ce que la file d’attente de récupération ?
Les modifications apportées au réplica principal dans une base de données de groupe de disponibilité sont envoyées à tous les réplicas secondaires définis dans le même groupe de disponibilité. Une fois ces modifications arrivées aux réplicas secondaires, elles sont d’abord écrites dans le fichier journal des transactions de la base de données du groupe de disponibilité. Microsoft SQL Server ensuite utiliser l’opération de récupération ou de restauration pour mettre à jour les fichiers de base de données.
Si les modifications apportées à un groupe de disponibilité arrivent et renforcent le fichier journal des transactions de base de données plus rapidement qu’elles ne peuvent être récupérées, une file d’attente de récupération est formée. Cette file d’attente est composée de transactions du journal des transactions renforcées qui n’ont pas été récupérées et restaurées dans la base de données.
Symptômes et effet de la récupération (restauration) en file d’attente
L’interrogation des réplicas principaux et secondaires retourne des résultats différents
Les charges de travail en lecture seule qui interrogent des réplicas secondaires peuvent interroger des données obsolètes. Si une file d’attente de récupération se produit, les modifications apportées aux données sur la base de données réplica primaire risquent de ne pas être répercutées dans la base de données secondaire lorsque vous interrogez les mêmes données.
Bien que les modifications arrivent à la base de données secondaire et soient écrites dans le fichier journal de base de données, les modifications ne seront pas interrogées tant qu’elles ne seront pas récupérées et restaurées dans les fichiers de base de données. L’opération de récupération est ce qui rend ces modifications lisibles.
Pour plus d’informations, consultez la section Latence des données sur le réplica secondaire de « Différences entre les modes de disponibilité pour un groupe de disponibilité Always On ».
Le temps de basculement est plus long ou le RTO est dépassé
L’objectif de temps de récupération (RTO) est le temps d’arrêt maximal de la base de données qu’un organization peut gérer. Le RTO décrit également la vitesse à laquelle le organization peut récupérer l’accès à la base de données après une panne. Si une file d’attente de récupération importante est présente sur un réplica secondaire lorsqu’un basculement se produit, la récupération peut prendre plus de temps. Après la récupération, la base de données passe au rôle principal et représente l’état de la base de données qui existait avant le basculement. Un temps de récupération plus long peut retarder la reprise rapide de la production après un basculement.
Diverses fonctionnalités de diagnostic signalent la mise en file d’attente de récupération de groupe de disponibilité
Dans le cas d’une file d’attente de récupération, le tableau de bord Always On dans SQL Server Management Studio (SSMS) peut signaler un groupe de disponibilité non sain.
Guide pratique pour case activée pour la récupération (restauration) en file d’attente
La file d’attente de récupération est une mesure par base de données qui peut être vérifiée à l’aide du tableau de bord Always On sur le réplica principal ou à l’aide de la vue de gestion dynamique (DMV) sys.dm_hadr_database_replica_states sur le réplica principal ou secondaire. Analyseur de performances compteurs case activée la mise en file d’attente de récupération et le taux de récupération. Ces compteurs doivent être vérifiés par rapport au réplica secondaire.
Les sections suivantes fournissent des méthodes pour surveiller activement la file d’attente de récupération de votre base de données de groupe de disponibilité.
Sys.dm_hadr_database_replica_states de requête
La sys.dm_hadr_database_replica_states DMV signale une ligne pour chaque base de données de groupe de disponibilité. L’une des colonnes du rapport est redo_queue_size. Cette valeur correspond à la taille de la file d’attente de récupération mesurée en kilo-octets. Vous pouvez configurer une requête qui ressemble à la requête suivante pour surveiller toutes les tendances de la taille de la file d’attente de récupération toutes les 30 secondes. La requête est exécutée sur le réplica principal. Il utilise le is_local=0 prédicat pour signaler les données de l’réplica secondaire, où redo_queue_size et redo_rate sont pertinents.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Voici à quoi ressemble la sortie.

Passer en revue la file d’attente de récupération dans Always On tableau de bord
Pour passer en revue la file d’attente de récupération, procédez comme suit :
Ouvrez le tableau de bord Always On dans SSMS en cliquant avec le bouton droit sur un groupe de disponibilité dans SSMS Explorateur d'objets.
Sélectionnez Afficher le tableau de bord.
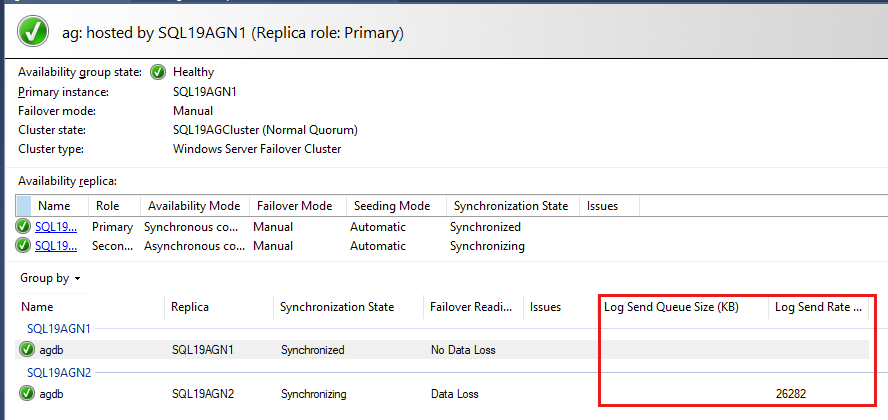
Les bases de données du groupe de disponibilité sont répertoriées en dernier, et certaines données sont signalées sur les bases de données. Bien que la taille de la file d’attente de restauration par progression (Ko) et le taux de restauration par progression (Ko/s) ne soient pas répertoriés par défaut, vous pouvez les ajouter à cette vue, comme illustré dans la capture d’écran de l’étape suivante.
Pour ajouter ces compteurs, cliquez avec le bouton droit sur l’en-tête au-dessus des rapports de base de données, puis sélectionnez dans la liste des colonnes disponibles.
Pour ajouter la taille de la file d’attente de restauration par progression (Ko) et le taux de restauration par progression (Ko/s), cliquez avec le bouton droit sur l’en-tête mis en évidence en rouge dans la capture d’écran suivante.
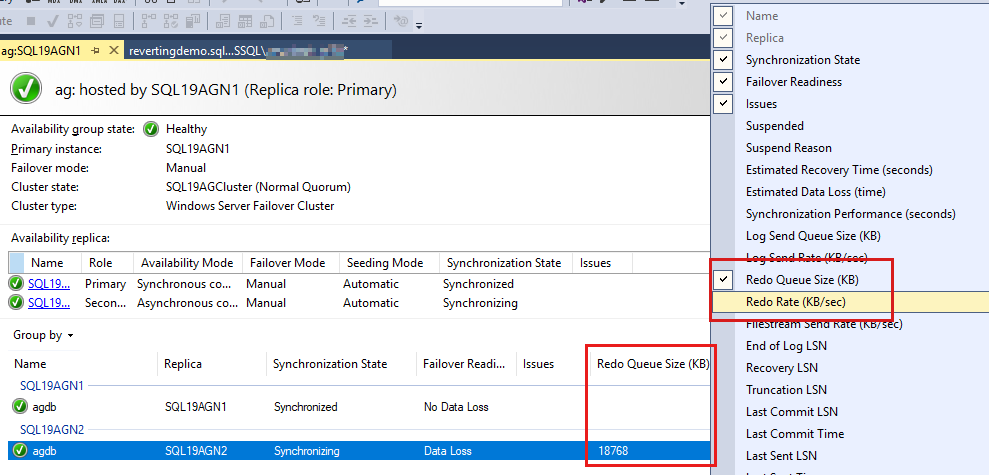
Par défaut, le tableau de bord Always On actualise automatiquement la taille de la file d’attente de restauration par progression (Ko) et le taux de restauration par progression (Ko/s) toutes les 60 secondes.


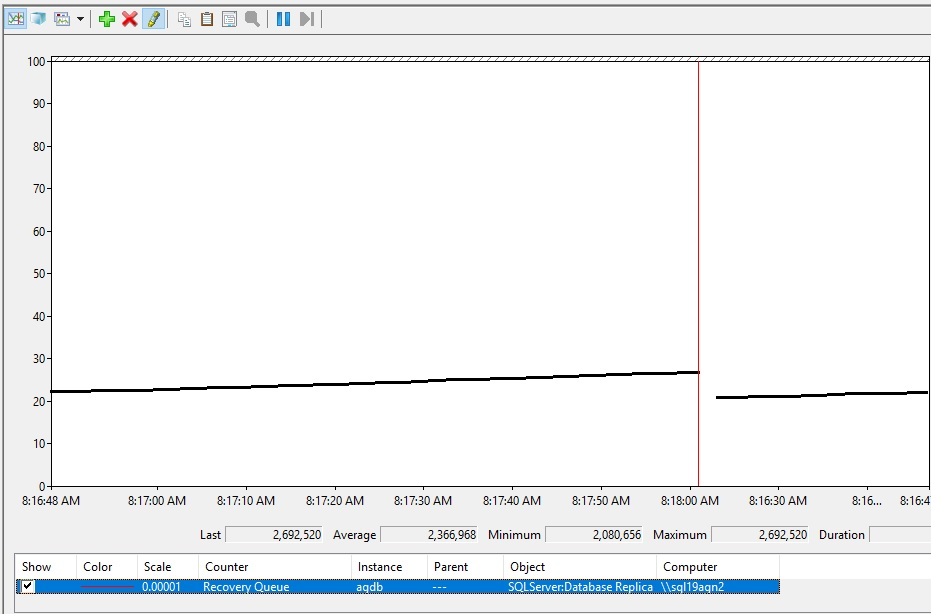
Passer en revue la file d’attente de récupération dans Analyseur de performances
La taille de la file d’attente de récupération est propre à chaque base de données et réplica secondaire. Par conséquent, pour passer en revue la file d’attente de récupération d’une base de données de groupe de disponibilité, procédez comme suit :
Ouvrez Analyseur de performances sur le réplica secondaire.
Sélectionnez le bouton Ajouter (compteur).
Sous Compteurs disponibles, sélectionnez SQLServer :Réplica de base de données, puis sélectionnez File d’attente de récupération et Compteurs d’octets restaurés/s .
Dans la zone de liste Instance , sélectionnez la base de données de groupe de disponibilité que vous souhaitez surveiller pour la mise en file d’attente de récupération.
Sélectionnez Ajouter>OK.
Voici à quoi peut ressembler l’augmentation de la file d’attente de récupération.

Interprétation des valeurs de file d’attente de récupération
Cette section explique comment interpréter les valeurs liées à la mise en file d’attente de récupération que vous avez déterminée dans la section précédente.
Quand la mise en file d’attente de récupération est-elle un problème ? Quelle quantité de files d’attente de récupération devez-vous tolérer ?
Vous pouvez supposer que si la file d’attente de récupération signale une valeur de 0, cela signifie qu’aucune file d’attente de récupération ne se produit au moment de ce rapport. Toutefois, lorsque votre environnement de production est occupé, vous devez vous attendre à observer que la file d’attente de récupération signale fréquemment une valeur différente de zéro, même dans un environnement AlwaysOn sain. Pendant la production classique, vous devez vous attendre à ce que cette valeur fluctue entre 0 et une valeur différente de zéro.
Si vous constatez une augmentation de la file d’attente de récupération au fil du temps, un examen plus approfondi est justifié. Cette activité supplémentaire indique que quelque chose a changé. Si vous observez une croissance soudaine de la file d’attente de récupération, les mesures suivantes sont utiles pour résoudre les problèmes :
- Taux de restauration par progression des journaux (Ko/s) (tableau de bord AlwaysOn)
- Redo_rate dans le sys.dm_hadr_database_replica_states DMV
Obtenir les taux de référence pour le taux de restauration par progression
Pendant les performances AlwaysOn saines, surveillez le taux de restauration par progression sur vos bases de données de groupe de disponibilité occupées. À quoi ressemblent-ils pendant les heures d’ouverture généralement occupées ? Quels sont ces taux pendant les périodes de maintenance, lorsque les transactions volumineuses (reconstructions d’index, processus ETL) entraînent un débit de transaction plus élevé sur le système ? Vous pouvez comparer ces valeurs lorsque vous observez la croissance de la file d’attente de récupération pour déterminer ce qui a changé. La charge de travail peut être supérieure à la normale. Si le taux de restauration par progression est inférieur, un examen approfondi peut être nécessaire pour déterminer pourquoi.
Les volumes de charge de travail sont importants
Lorsque vous avez des charges de travail volumineuses (par exemple, une instruction UPDATE sur un million de lignes, une reconstruction d’index sur une table de 1 téraoctet ou même un lot ETL qui insère des millions de lignes), vous devez vous attendre à voir une croissance de la file d’attente de récupération, immédiatement ou au fil du temps. Cela est attendu lorsqu’un grand nombre de modifications sont apportées soudainement dans la base de données du groupe de disponibilité.
Guide pratique pour diagnostiquer la récupération (restauration) en file d’attente
Après avoir identifié la file d’attente de récupération pour une base de données de groupe de disponibilité réplica secondaire spécifique, connectez-vous à la réplica secondaire, puis interrogez sys.dm_exec_requests pour déterminer les wait_type threads de récupération et wait_time . Voici une requête qui peut s’exécuter dans une boucle. Vous recherchez une fréquence élevée d’un ou de plusieurs types d’attente et même des temps d’attente pour ces types d’attente. Voici un exemple de requête qui s’exécute toutes les secondes et signale les types d’attente et les temps d’attente pour le groupe de disponibilité, « agdb » :
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Importante
Pour une sortie de type d’attente significative, la mise en file d’attente de récupération doit être observée comme augmentant lorsque vous utilisez l’une des méthodes décrites précédemment pour surveiller cette condition.
Dans cet exemple, certains types d’attente liés aux E/S sont signalés (PAGEIOLATCH_UP, PAGEIOATCH_EX). Surveillez pour case activée si ces types d’attente continuent d’avoir les valeurs les plus élevéeswait_times, comme indiqué dans la colonne suivante.

SQL Server types d’attente de restauration par progression
Lorsqu’un type d’attente est identifié, consultez l’article suivant SQL Server 2016/2017 : Modèle et performances de restauration par progression du groupe de disponibilité réplica - Microsoft Tech Community comme référence croisée pour les types d’attente courants qui entraînent une file d’attente de récupération et pour obtenir de l’aide pour résoudre le problème.
Threads de restauration par progression bloqués sur les serveurs de rapports secondaires
Si votre solution dirige la création de rapports (interrogations) sur des bases de données de groupe de disponibilité sur le réplica secondaire, ces requêtes en lecture seule acquièrent des verrous de stabilité de schéma (Sch-S). Ces verrous Sch-S peuvent empêcher les threads de restauration par progression d’acquérir des verrous de modification de schéma (Sch-M) (également appelés « verrous de modification de schéma » ou LCK_M_SCH_M) pour apporter des modifications en langage de définition de données (DDL), telles que ALTER TABLE ou ALTER INDEX. Un thread de restauration par progression bloqué ne peut pas appliquer d’enregistrements de journal tant qu’il n’est pas débloqué. Cela peut entraîner la mise en file d’attente de récupération.
Pour case activée la preuve historique d’un rétablissement bloqué, ouvrez les fichiers de trace Xevent AlwaysOn_health sur le réplica secondaire à l’aide de SSMS. Recherchez lock_redo_blocked les événements.

Utilisez Analyseur de performances pour surveiller activement l’impact des restaurations bloquées dans la file d’attente de récupération. Ajoutez les compteurs SQL Server ::D atabase Replica ::Redo blocked/sec et SQL Server ::D atabase Replica ::Recovery Queue. La capture d’écran suivante montre une ALTER TABLE ALTER COLUMN commande exécutée sur le réplica principal tandis qu’une requête longue est exécutée sur la même table sur le réplica secondaire. Le compteur Rétablir bloqué/s indique que la ALTER TABLE ALTER COLUMN commande est exécutée. Pendant que la requête de longue durée s’exécute sur la même table sur le réplica secondaire, toute modification ultérieure sur le serveur principal entraîne une augmentation de la file d’attente de récupération.

Surveillez le type d’attente de verrou de modification de schéma que le thread de restauration par progression tente d’acquérir. Pour ce faire, utilisez la requête décrite précédemment pour case activée les types d’attente signalés pour les opérations de restauration par progression sur sys.dm_exec_requests. Vous pouvez observer l’augmentation du temps d’attente pour le LCK_M_SCH_M dans le blocage de restauration par progression en cours.

Rétablissement monothread
SQL Server introduit la récupération parallèle pour les bases de données réplica secondaires dans Microsoft SQL Server 2016. Si vous rencontrez une file d’attente de récupération lorsque vous exécutez SQL Microsoft Server 2012 ou Microsoft SQL Server 2014, vous pouvez effectuer une mise à niveau vers une version ultérieure du programme pour améliorer les performances de restauration dans votre environnement de production.
Un rétablissement à thread unique peut se produire dans des versions SQL Server plus avancées dans lesquelles une architecture de récupération parallèle est utilisée. Dans ces versions, un SQL Server instance peut utiliser jusqu’à 100 threads pour une restauration par progression parallèle. Selon le nombre de processeurs et de bases de données de groupe de disponibilité, les threads de restauration par progression parallèles sont alloués jusqu’à un maximum de 100 threads au total. Si la limite de restauration par progression de 100 threads est atteinte, un seul thread de restauration par progression est affecté à certaines bases de données du groupe de disponibilité.
Pour déterminer si votre base de données de groupe de disponibilité utilise la récupération parallèle, connectez-vous à la réplica secondaire et utilisez la requête suivante pour déterminer le nombre de lignes (threads) qui appliquent la récupération pour la base de données du groupe de disponibilité. Dans l’exemple suivant, si la base de données « agdb » est un thread unique et que sa commande est DB STARTUP, la charge de travail de récupération peut tirer parti d’une récupération parallèle.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Si vous vérifiez que votre base de données utilise un rétablissement à thread unique, passez en revue l’algorithme décrit précédemment pour déterminer si SQL Server dépasse le nombre de 100 threads de travail dédiés à la récupération parallèle. Une telle condition peut être la raison pour laquelle la base de données « agdb » utilise un seul thread pour la récupération.
SQL Server 2022 utilise désormais un nouvel algorithme de récupération parallèle afin que les threads de travail soient affectés à la récupération parallèle en fonction de la charge de travail. Cela élimine le risque qu’une base de données occupée reste dans une récupération monothread. Pour plus d’informations, consultez la section Utilisation des threads par groupes de disponibilité de « Prérequis, restrictions et recommandations pour les groupes de disponibilité Always On ».