Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article vous aide à diagnostiquer et à résoudre l’ID d’événement 1135 qui peut être consigné lors du démarrage du service de cluster dans un environnement de clustering de basculement.
S’applique à : Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, versions 21H2 et 20H2
Essayez notre agent virtuel : il peut vous aider à identifier et à résoudre rapidement les problèmes courants liés à la réplication Active Directory.
Page de démarrage
L’ID d’événement 1135 indique qu’un ou plusieurs nœuds de cluster ont été supprimés de l’appartenance active au cluster de basculement. Il peut s’accompagner des symptômes suivants :
Basculement du cluster\nœuds supprimés de l’appartenance active au cluster de basculement :
Problème lié à la suppression de nœuds de l’appartenance active à un cluster de basculement
ID d’événement 1069 :
ID d’événement 1069 - Disponibilité du service ou de l’application en cluster
ID d’événement 1177 pour perte de quorum :
ID d’événement 1177 - Quorum et connectivité nécessaires pour le quorum
ID d’événement 1006 pour le service de cluster arrêté :
Une validation et des tests du réseau sont recommandés pour commencer la résolution des problèmes afin de s’assurer qu’il n’existe aucun problème de configuration pouvant être à l’origine de problèmes.
Vérifiez si les correctifs recommandés sont installés
Le service de cluster est le composant logiciel principal permettant de contrôler l’ensemble des aspects du fonctionnement du cluster de basculement et de gérer la base de données de configuration du cluster. Si vous voyez l’ID d’événement 1135, nous vous recommandons d’installer les correctifs mentionnés dans les articles suivants et de redémarrer tous les nœuds du cluster, puis d’observer si le problème se produit.
- Correctifs logiciels et mises à jour recommandés pour les clusters de basculement basés sur Windows Server 2012 R2
- Correctifs logiciels et mises à jour recommandés pour les clusters de basculement basés sur Windows Server 2012
- Correctifs logiciels et mises à jour recommandés pour les clusters de basculement Windows Server 2008 R2 SP1
Vérifiez si le service de cluster s’exécute sur tous les nœuds
Suivez la commande suivante selon votre système d’exploitation Windows pour vérifier que le service de cluster est en cours d’exécution et disponible en continu.
Pour le cluster Windows Server 2008 R2
À partir d’une invite de commandes avec élévation de privilèges, exécutez cluster.exe node /stat.
Pour les clusters Windows Server 2012 et Windows Server 2012 R2
Exécutez l’applet de commande PowerShell suivante : Get-ClusterResource
Le service de cluster est en cours d’exécution et disponible sur tous les nœuds ?
Plusieurs scénarios de l’ID d’événement 1135
Vous devez examiner de plus près les journaux des événements système sur tous les nœuds de votre cluster. Passez en revue l’ID d’événement 1135 que vous voyez sur les nœuds et copiez toutes les instances de cet événement. Vous pouvez ainsi les examiner et les évaluer facilement.
Event ID 1135
Cluster node ' **NODE A** ' was removed from the active failover cluster membership. The Cluster service on this node may have stopped.
This could also be due to the node having lost communication with other active nodes in the failover cluster.
Run the Validate a Configuration wizard to check your network configuration.
If the condition persists, check for hardware or software errors related to the network adapters on this node.
Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Il existe trois scénarios classiques :
Scénario A
Vous examinez tous les événements et tous les nœuds du cluster indiquent que NODE A avait perdu la communication.
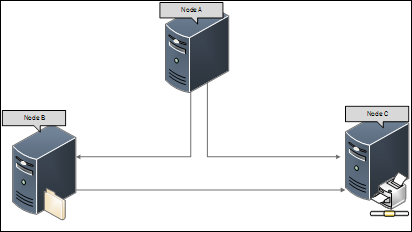

Il peut être possible que lorsque vous voyez les journaux système sur NODE A, il comporte des événements pour tous les nœuds restants du cluster.
Solution
Cela suggère qu’au moment du problème, la communication avec le NŒUD A a été perdue en raison d’une congestion du réseau ou pour une autre raison.
Vous devez passer en revue et valider les problèmes de configuration et de communication réseau. N’oubliez pas de rechercher les problèmes liés au nœud A.
Scénario B
Vous examinez les événements sur les nœuds et supposons que votre cluster est dispersé sur deux sites. NODE A, NODE B et NODE C sur le site 1 et NODE D &NODE E sur le site 2.
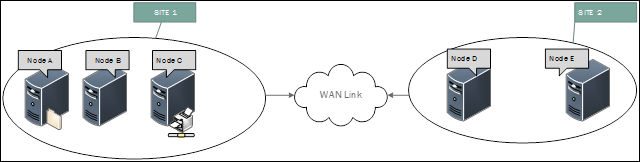
Sur les nœuds A, B et C, vous voyez que les événements enregistrés sont destinés à la connectivité aux nœuds D &E. De même, lorsque vous voyez les événements sur les nœuds D &E, les événements suggèrent que nous avons perdu la communication avec A, B et C.
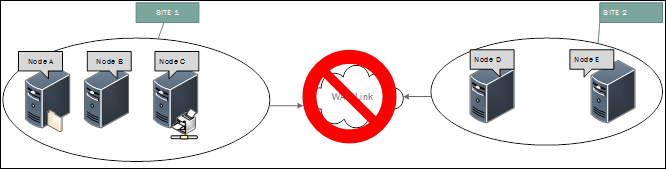
Solution
Si vous constatez une activité similaire, cela indique un échec de communication via la liaison qui connecte ces sites. Nous vous recommandons de passer en revue la connexion entre les sites. S’il s’agit d’une connexion WAN, nous vous conseillons de vérifier la connectivité auprès de votre fournisseur de services Internet.
Scénario C
Vous examinez les événements sur les nœuds et vous voyez que les noms des nœuds n’ont pas de modèle particulier. Imaginons que votre cluster s’étend sur deux sites. NODE A, NODE B et NODE C sur le site 1 et NODE D &NODE E sur le site 2.
- Sur le nœud A : des événements s’affichent pour les nœuds B, D, E.
- Sur le nœud B : des événements s’affichent pour les nœuds C, D, E.
- Sur le nœud C : des événements s’affichent pour les nœuds A, B, E.
- Sur le nœud D : des événements s’affichent pour les nœuds A, C, E.
- Sur le nœud E : des événements s’affichent pour les nœuds B, C, D.
- Ou toute autre combinaison.
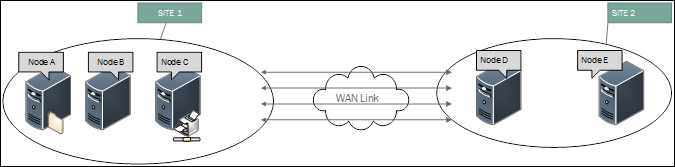
Solution
Ces événements sont possibles en cas de goulots d’étranglement sur les canaux réseau entre les nœuds et quand les messages de communication du cluster n’arrivent pas en temps voulu. Ainsi, le cluster a l’impression que la communication entre les nœuds est perdue, ce qui entraîne la suppression des nœuds de l’appartenance au cluster.
Passer en revue les réseaux en cluster
Nous vous recommandons de passer en revue vos réseaux en cluster en vérifiant les trois options suivantes une par une afin de poursuivre ce guide de résolution des problèmes.
Vérification de l’exclusion de l’antivirus
Excluez les emplacements de système de fichiers suivants de l’analyse antivirus sur un serveur qui exécute les services de cluster :
- Chemin d’accès du témoin FileShare
- Dossier %Systemroot%\Cluster
Configurez le composant d’analyse en temps réel dans votre logiciel antivirus pour exclure les répertoires et les fichiers suivants :
Répertoire de configuration de machine virtuelle par défaut (C :\ProgramData\Microsoft\Windows\Hyper-V)
Répertoires de configuration de la machine virtuelles personnalisés
Répertoire de disque dur virtuel par défaut (C :\Users\Public\Documents\Hyper-V\Virtual Hard Disks)
Répertoires de disques durs virtuels personnalisés
Répertoires de données de réplication personnalisés, si vous utilisez le réplica Hyper-V
Répertoires d’instantanés
mms.exe
Notes
Il est possible que ce fichier doive être configuré en tant qu’exclusion du processus dans le logiciel antivirus.
Vmwp.exe
Notes
Il est possible que ce fichier doive être configuré en tant qu’exclusion du processus dans le logiciel antivirus.
En outre, quand vous utilisez la Migration dynamique avec des Volumes partagés de cluster, excluez le chemin CSV C:\Clusterstorage et tous ses sous-répertoires. Si vous résolvez des problèmes de basculement ou des problèmes généraux avec les services de cluster et les logiciels antivirus sont installés, désinstallez temporairement le logiciel antivirus ou vérifiez auprès du fabricant du logiciel pour déterminer si le logiciel antivirus fonctionne avec les services de cluster. Dans la plupart des cas, il ne suffit pas de désactiver le logiciel antivirus. Même si vous désactivez le logiciel antivirus, le pilote de filtre est toujours chargé quand vous redémarrez l’ordinateur.
Rechercher la configuration du port réseau dans le pare-feu
Le service de cluster contrôle les opérations de cluster de serveurs et gère la base de données du cluster. Un cluster est une collection d’ordinateurs indépendants qui agissent comme un ordinateur unique. Les responsables, les programmeurs et les utilisateurs voient le cluster comme un système unique. Le logiciel distribue les données aux différents nœuds du cluster. En cas d’échec d’un nœud, les autres nœuds fournissent les services et les données qui étaient précédemment fournies par le nœud manquant. Quand un nœud est ajouté ou réparé, le logiciel du cluster migre certaines données vers ce nœud.
Nom du service système : ClusSvc
| Application | Protocol | Ports |
|---|---|---|
| Service de cluster | UDP | 3343 |
| Service de cluster | TCP | 3343 (ce port est nécessaire lors d’une opération de jointure de nœud.) |
| RPC | TCP | 135 |
| Administration du cluster | UDP | 137 |
| Kerberos | UDP/TCP | 464* |
| SMB | TCP | 445 |
| Ports UDP élevés alloués de manière aléatoire** | UDP | Numéro de port aléatoire compris entre 1024 et 65535 Numéro de port aléatoire compris entre 49152 et 65535*** |
Notes
En outre, pour une validation réussie sur les clusters de basculement Windows sur Windows Server 2008 et versions ultérieures, autorisez le trafic entrant et sortant pour ICMP4, ICMP6.
- Pour plus d’informations, consultez Création d’un cluster de basculement Windows Server 2012 Échec avec l’erreur 0xc000005e.
- Pour plus d’informations sur la personnalisation de ces ports, consultez la section « Références » dans la vue d’ensemble du service et la configuration requise pour les ports réseau pour Windows.
Il s’agit de la plage dans Windows Server 2012, Windows 8, Windows Server 2008 R2, Windows 7, Windows Server 2008 et Windows Vista.
En outre, exécutez la commande suivante pour rechercher la configuration du port réseau dans le pare-feu. Par exemple, cette commande permet de déterminer le port 3343 disponible\ouvert utilisé pour le cluster de basculement :
netsh advfirewall firewall show rule name="Failover Clusters (UDP-In)" verbose
Exécuter le rapport de validation du cluster pour toute erreur ou avertissement
L’outil de validation du cluster exécute une suite de tests pour vérifier que votre matériel et vos paramètres sont compatibles avec le clustering de basculement.
Suivez ces instructions :
Exécutez le rapport de validation du cluster en vue de détecter toute erreur ou tout avertissement. Pour plus d’informations, consultez Présentation des tests de validation des clusters : réseau
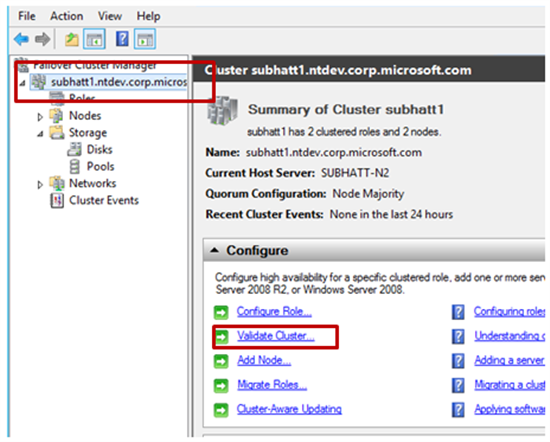
Vérifiez s’il existe des avertissements et des erreurs pour les réseaux. Pour plus d’informations, consultez Présentation des tests de validation des clusters : réseau.
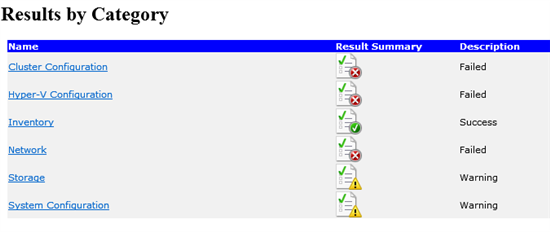
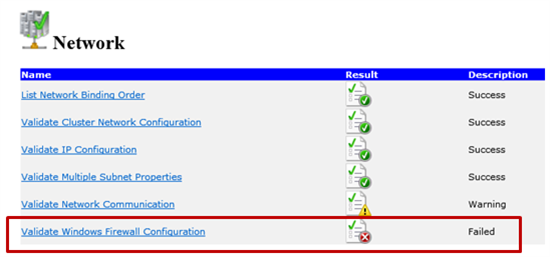
Consulter la liste de l’ordre de liaison réseau
Ce test indique l’ordre dans lequel les réseaux sont liés aux cartes sur chaque nœud.
L’onglet Adaptateurs et liaisons répertorie les connexions dans l’ordre dans lequel les connexions sont accessibles par les services réseau. L’ordre de ces connexions reflète l’ordre dans lequel les appels/paquets TCP/IP génériques sont envoyés sur le réseau.
Pour modifier l’ordre de liaison des cartes réseau, procédez comme suit :
- Sélectionnez Démarrer, sélectionnez Exécuter, tapez ncpa.cpl, puis sélectionnez OK. Les connexions disponibles sont affichées dans la section Réseau local et Internet haut débit de la fenêtre Connexions réseau.
- Dans le menu Avancé , sélectionnez Paramètres avancés, puis sélectionnez l’onglet Adaptateurs et liaisons .
- Dans la zone Connexions, sélectionnez la connexion que vous souhaitez faire monter dans la liste. Utilisez les flèches pour déplacer la connexion. En règle générale, la carte qui communique avec le réseau (connectivité de domaine, routage vers d’autres réseaux, etc. doit être la première carte liée (en haut de la liste).
Les nœuds de cluster sont des systèmes multirésidents. La priorité réseau affecte le client DNS pour la connectivité réseau sortante. Les cartes réseau utilisées pour la communication client doivent se trouver en haut sur la liste de l’ordre de liaison. Les réseaux non routés peuvent être placés à un niveau de priorité inférieur. Dans Windows Server 2012 et Windows Server 2012 R2, l’adaptateur de pilote réseau de cluster (NETFT.SYS) est automatiquement placé en bas dans la liste des commandes de liaison.
Vérifier Valider la communication réseau
La latence sur votre réseau peut également être à l’origine de ce problème. Il est possible que les paquets ne soient pas perdus entre les nœuds, mais qu’ils n’atteignent pas assez rapidement les nœuds avant l’expiration du délai.
Ce test vérifie que les serveurs testés peuvent communiquer avec une latence acceptable sur tous les réseaux.
Par exemple, sous Valider la communication réseau, les messages suivants peuvent s’afficher concernant des problèmes de latence réseau :
Succeeded in pinging network interface node003.contoso.com IP Address 192.168.0.2 from network interface node004.contoso.com IP Address 192.168.0.3 with maximum delay 500 after 1 attempt(s).
Either address 10.0.0.96 is not reachable from 192.168.0.2 or **the ping latency is greater than the maximum allowed 2000 ms**
This may be expected, since network interfaces node003.contoso.com - Heartbeat Network and node004.contoso.com - Production Network are on different cluster networks
Either address 192.168.0.2 is not reachable from 10.0.0.96 or **the ping latency is greater than the maximum allowed 2000 ms**
This may be expected, since network interfaces node004.contoso.com - Production Network and node003.contoso.com - Heartbeat Network for MSCS are on different cluster networks
Pour le cluster multisite, vous pouvez augmenter les valeurs de délai d’expiration. Pour plus d’informations, consultez Configurer les paramètres de pulsation et DNS dans un cluster de basculement multisite.
Vérifiez auprès du fournisseur de services Internet s’il existe des problèmes de connectivité WAN.
Vérifiez si vous rencontrez l’un des problèmes suivants.
Perte de paquets réseau entre les nœuds
Vérifier si des paquets sont perdus à l’aide des performances
Si le paquet est perdu sur le réseau entre des nœuds, les pulsations échouent. Nous pouvons facilement déterminer s’il s’agit du problème à l’aide de l’Analyseur de performances en examinant le compteur « Interface réseau\Paquets reçus ignorés ». Une fois que vous avez ajouté ce compteur, examinez les nombres Moyen, Minimum et Maximum. Si l’une des valeurs est supérieure à zéro, la mémoire tampon de réception doit être ajustée à la hausse pour l’adaptateur.
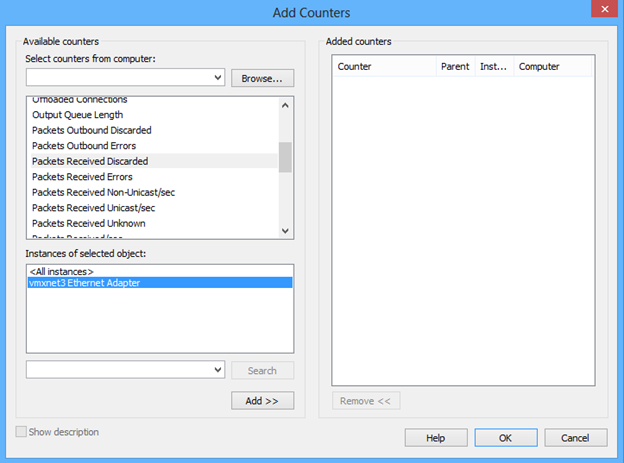
Si vous rencontrez des paquets réseau perdus sur la plateforme de virtualisation VMware, consultez la section « Cluster installé dans la plateforme de virtualisation VMware ».
Mettre à niveau les pilotes de carte réseau
Ce problème peut être dû à des pilotes de carte réseau\Composants d’intégration (IC)\VmTools obsolètes ou à des cartes réseau défectueuses. Si des paquets réseau sont perdus entre les nœuds sur des machines physiques, effectuez des mises à jour de votre pilote de carte réseau. Pilotes de carte réseau et/ou microprogrammes anciens ou obsolètes. Parfois, une simple configuration incorrecte du commutateur ou de la carte réseau peut également entraîner la perte de pulsations.
Cluster installé sur la plateforme de virtualisation VMware
Vérifiez les problèmes de carte VMware s’il s’agit d’un environnement VMware.
Ce problème peut survenir si les paquets sont supprimés lors de pics de trafic élevés en rafale. Assurez-vous que le trafic n’est pas filtré (par exemple via un filtre de messagerie). Après avoir éliminé cette possibilité, augmentez progressivement le nombre de mémoires tampons dans le système d’exploitation invité et effectuez une vérification.
Pour réduire les chutes de trafic en rafale, procédez comme suit :
- Sélectionnez Démarrer, sélectionnez Exécuter, tapez
devmgmt.mscet appuyez sur Entrée. - Développez les cartes réseau, cliquez avec le bouton droit sur vmxnet3 et sélectionnez Propriétés.
- Sélectionnez l'onglet Avancé.
- Sélectionnez Petites mémoires tampons Rx et augmentez la valeur. La valeur par défaut est 512 et la valeur maximum est 8192.
- Sélectionnez Rx Ring #1 Taille et augmentez la valeur. La valeur par défaut est 1024 et la valeur maximum est 4096.
Consultez les articles suivants pour vérifier les problèmes d’adaptateur VMware en cas d’environnement VMware :
- Nœuds supprimés de l’appartenance au cluster de basculement sur VMware ESX ?.
- Perte de paquets importante au niveau du système d’exploitation invité sur la carte réseau virtuelle VMXNET3 dans ESXi
Notez toute congestion du réseau
La congestion du réseau peut également entraîner des problèmes de connectivité réseau.
Vérifiez que votre réseau est configuré conformément aux recommandations de Microsoft et du fournisseur. Consultez Configuration des réseaux en cluster de basculement Windows.
Vérifier la configuration réseau
S’il ne fonctionne toujours pas, vérifiez si vous avez vu le réseau partitionné dans l’interface graphique utilisateur du cluster ou si l’association de cartes réseau est activée sur la carte réseau de pulsations.
Si un réseau partitionné est visible dans l’interface graphique du cluster, consultez Réseaux de cluster « partitionnés » pour résoudre le problème.
Si l’Association de cartes réseau est activée sur la carte réseau de pulsation, vérifiez la fonctionnalité logicielle d’association conformément à la recommandation du fournisseur d’association.
Mettre à niveau les pilotes de carte réseau
Ce problème peut être dû à des pilotes de carte réseau obsolètes ou à des cartes réseau défectueuses.
Si des paquets réseau sont perdus entre les nœuds sur des machines physiques, effectuez des mises à jour de votre pilote de carte réseau. Pilotes de carte réseau et/ou microprogrammes anciens ou obsolètes.
Parfois, une simple configuration incorrecte du commutateur ou de la carte réseau peut également entraîner la perte de pulsations.
Vérifier la configuration réseau
S’il ne fonctionne toujours pas, vérifiez si vous avez vu le réseau partitionné dans l’interface graphique utilisateur du cluster ou si l’association de cartes réseau est activée sur la carte réseau de pulsations.