Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez apprendre à conserver des données dans une application conteneur. Lorsque vous l’exécutez ou que vous la mettez à jour, les données sont toujours disponibles. Il existe deux types principaux de volumes utilisés pour conserver des données. Ce tutoriel se concentre sur les volumes nommés .
Vous découvrirez également les montages de liaison, qui contrôlent le point de montage exact sur l’hôte. Vous pouvez utiliser des montages de liaison pour rendre les données persistantes, mais ils peuvent également ajouter des données dans des conteneurs. Lorsque vous travaillez sur une application, vous pouvez utiliser un montage de liaison pour monter le code source dans le conteneur pour lui permettre de voir les modifications de code, de répondre et de vous permettre de voir les modifications immédiatement.
Ce didacticiel présente également la couche d’images, la mise en cache de couches et les builds à plusieurs étapes.
Dans ce tutoriel, vous allez apprendre à :
- Comprendre les données entre les conteneurs.
- Conserver les données à l’aide de volumes nommés.
- Utilisation de montages de liaisons.
- Afficher les couches d’images.
- Dépendances de cache.
- Comprendre les builds à plusieurs étapes.
Conditions préalables
Ce tutoriel poursuit le didacticiel précédent, Créer et partager une application conteneur avec Visual Studio Code. Commencez par celui-ci, qui inclut les conditions préalables.
Comprendre les données entre les conteneurs
Dans cette section, vous allez démarrer deux conteneurs et créer un fichier dans chacun d’eux. Les fichiers créés dans un conteneur ne sont pas disponibles dans un autre.
Démarrez un conteneur
ubuntuà l’aide de cette commande :docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Cette commande démarre appelle deux commandes à l’aide de
&&. La première partie choisit un nombre aléatoire unique et l’écrit dans/data.txt. La deuxième commande surveille un fichier pour maintenir le conteneur en cours d’exécution.Dans VS Code, dans l’Explorateur de conteneurs, cliquez avec le bouton droit sur le conteneur Ubuntu, puis sélectionnez Attacher Shell.
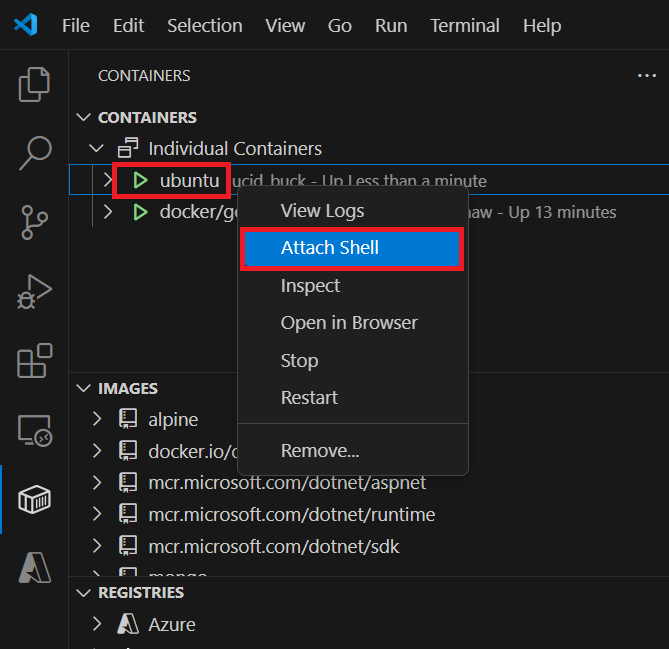
Un terminal s’ouvre qui exécute un interpréteur de commandes dans le conteneur Ubuntu.
Exécutez la commande suivante pour afficher le contenu du fichier
/data.txt.cat /data.txtLe terminal affiche un nombre compris entre 1 et 1 0000.
Pour utiliser la ligne de commande pour afficher ce résultat, obtenez l’ID de conteneur à l’aide de la commande
docker ps, puis exécutez la commande suivante.docker exec <container-id> cat /data.txtDémarrez un autre conteneur
ubuntu.docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Utilisez cette commande pour examiner le contenu du dossier.
docker run -it ubuntu ls /Il ne devrait y avoir aucun fichier
data.txt, car il a été écrit dans l’espace temporaire uniquement pour le premier conteneur.Sélectionnez ces deux conteneurs Ubuntu. Cliquez avec le bouton droit et sélectionnez Supprimer. À partir de la ligne de commande, vous pouvez les supprimer à l’aide de la commande
docker rm -f.
Conserver vos données todo à l’aide de volumes nommés
Par défaut, l’application todo stocke ses données dans une base de données SQLite dans /etc/todos/todo.db.
SQLite Database est une base de données relationnelle qui stocke les données dans un seul fichier.
Cette approche fonctionne pour les petits projets.
Vous pouvez conserver le fichier unique sur l’hôte. Lorsque vous la mettez à la disposition du conteneur suivant, l’application peut récupérer là où elle s’est arrêtée. En créant un volume et en l’attachant ou en le montant au dossier dans lequel les données sont stockées, vous pouvez conserver les données. Le conteneur écrit dans le fichier todo.db, et ces données sont conservées dans l’hôte dans le volume.
Pour cette section, utilisez un volume nommé. Docker conserve l’emplacement physique du volume sur le disque. Référez-vous au nom du volume, et Docker fournit les données appropriées.
Créez un volume à l’aide de la commande
docker volume create.docker volume create todo-dbSous CONTAINERS, sélectionnez Bien démarrer et cliquez avec le bouton droit. Sélectionnez Arrêter pour arrêter le conteneur de l'application.
Pour arrêter le conteneur à partir de la ligne de commande, utilisez la commande
docker stop.Démarrez le conteneur getting-started à l’aide de la commande suivante.
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedLe paramètre de volume spécifie le volume à monter et l’emplacement,
/etc/todos.Actualisez votre navigateur pour recharger l’application. Si vous avez fermé la fenêtre du navigateur, accédez à
http://localhost:3000/. Ajoutez des éléments à votre liste de tâches.
Supprimez le conteneur getting-started de l’application todo. Cliquez avec le bouton droit sur le conteneur dans l'Explorateur de conteneurs et sélectionnez Supprimer ou utilisez les commandes
docker stopetdocker rm.Démarrez un nouveau conteneur à l’aide de la même commande :
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedCette commande monte le même lecteur qu’auparavant. Actualisez votre navigateur. Les éléments que vous avez ajoutés sont toujours dans votre liste.
Supprimez à nouveau le conteneur getting-started.
Les volumes nommés et les montages de liaison, décrits ci-dessous, sont les principaux types de volumes pris en charge par une installation par défaut du moteur Docker.
| Propriété | Volumes nommés | Lier des montages |
|---|---|---|
| Emplacement de l’hôte | Docker choisit | Vous contrôlez |
Exemple de montage (à l’aide de -v) |
my-volume :/usr/local/data | /path/to/data :/usr/local/data |
| Remplit un nouveau volume avec le contenu du conteneur | Oui | Non |
| Prend en charge les pilotes de volume | Oui | Non |
De nombreux plug-ins de pilotes de volume sont disponibles pour prendre en charge NFS, SFTP, NetApp, etc. Ces plug-ins sont particulièrement importants pour exécuter des conteneurs sur plusieurs hôtes dans un environnement cluster tel que Swarm ou Kubernetes.
Si vous vous demandez où Docker réellement stocke vos données, exécutez la commande suivante.
docker volume inspect todo-db
Examinez la sortie, semblable à ce résultat.
[
{
"CreatedAt": "2019-09-26T02:18:36Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/todo-db/_data",
"Name": "todo-db",
"Options": {},
"Scope": "local"
}
]
Le Mountpoint est l’emplacement réel où les données sont stockées.
Sur la plupart des ordinateurs, vous avez besoin d’un accès racine pour accéder à ce répertoire à partir de l’hôte.
Utilisation de montages de liaisons
Avec les montages de liaison, vous contrôlez le point de montage exact sur l’hôte. Cette approche conserve les données, mais est souvent utilisée pour fournir davantage de données dans des conteneurs. Vous pouvez utiliser un montage de liaison pour monter le code source dans le conteneur afin qu'il puisse détecter les modifications de code, réagir et vous permettre de voir les changements immédiatement.
Pour exécuter votre conteneur pour prendre en charge un flux de travail de développement, procédez comme suit :
Supprimez les conteneurs
getting-started.Dans le dossier
app, exécutez la commande suivante.docker run -dp 3000:3000 -w /app -v ${PWD}:/app node:lts-alpine sh -c "yarn install && yarn run dev"Cette commande contient les paramètres suivants.
-
-dp 3000:3000Identique à ce qui précède. Exécutez en mode détaché et créez un mappage de port. -
-w /apprépertoire de travail à l’intérieur du conteneur. -
-v ${PWD}:/app"Liez le répertoire actif à partir de l’hôte dans le conteneur dans le répertoire/app. -
node:lts-alpinel’image à utiliser. Cette image est l’image de base de votre application à partir du Dockerfile. -
sh -c "yarn install && yarn run dev"Une commande. Il démarre un shell en utilisantshet exécuteyarn installpour installer toutes les dépendances. Ensuite, elle exécuteyarn run dev. Si vous regardez dans lepackage.json, le scriptdevdémarrenodemon.
-
Vous pouvez regarder les logs à l’aide de
docker logs.docker logs -f <container-id>$ nodemon src/index.js [nodemon] 2.0.20 [nodemon] to restart at any time, enter `rs` [nodemon] watching path(s): *.* [nodemon] watching extensions: js,mjs,json [nodemon] starting `node src/index.js` Using sqlite database at /etc/todos/todo.db Listening on port 3000Lorsque vous voyez l’entrée finale dans cette liste, l’application est en cours d’exécution.
Lorsque vous avez terminé de regarder les journaux, sélectionnez n’importe quelle touche dans la fenêtre de terminal ou appuyez sur Ctrl+C dans une fenêtre externe.
Dans VS Code, ouvrez src/static/js/app.js. Modifiez le texte du bouton Ajouter un élément à la ligne 109.
- {submitting ? 'Adding...' : 'Add Item'} + {submitting ? 'Adding...' : 'Add'}Enregistrez votre modification.
Actualisez votre navigateur. Vous devriez voir la modification.

Supprimez le
node:lts-alpineconteneur.Dans le
appdossier, exécutez la commande suivante pour supprimer lenode_modulesdossier créé aux étapes précédentes.rm -r node_modules
Afficher les couches d’image
Vous pouvez examiner les couches qui composent une image.
Exécutez la commande docker image history pour afficher la commande utilisée pour créer chaque couche dans une image.
Utilisez
docker image historypour afficher les couches de l’image getting-started que vous avez créée précédemment dans le tutoriel.docker image history getting-startedVotre résultat devrait ressembler à ce résultat.
IMAGE CREATED CREATED BY SIZE COMMENT a78a40cbf866 18 seconds ago /bin/sh -c #(nop) CMD ["node" "/app/src/ind… 0B f1d1808565d6 19 seconds ago /bin/sh -c yarn install --production 85.4MB a2c054d14948 36 seconds ago /bin/sh -c #(nop) COPY dir:5dc710ad87c789593… 198kB 9577ae713121 37 seconds ago /bin/sh -c #(nop) WORKDIR /app 0B b95baba1cfdb 13 days ago /bin/sh -c #(nop) CMD ["node"] 0B <missing> 13 days ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B <missing> 13 days ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B <missing> 13 days ago /bin/sh -c apk add --no-cache --virtual .bui… 5.35MB <missing> 13 days ago /bin/sh -c #(nop) ENV YARN_VERSION=1.21.1 0B <missing> 13 days ago /bin/sh -c addgroup -g 1000 node && addu… 74.3MB <missing> 13 days ago /bin/sh -c #(nop) ENV NODE_VERSION=12.14.1 0B <missing> 13 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B <missing> 13 days ago /bin/sh -c #(nop) ADD file:e69d441d729412d24… 5.59MBChacune des lignes représente une couche dans l’image. La sortie affiche la base en bas avec la couche la plus récente en haut. À l’aide de ces informations, vous pouvez voir la taille de chaque couche, ce qui vous permet de diagnostiquer des images volumineuses.
Plusieurs lignes sont tronquées. Si vous ajoutez le paramètre
--no-trunc, vous obtenez la sortie complète.docker image history --no-trunc getting-started
Dépendances de cache
Une fois qu’une couche change, toutes les couches en aval doivent également être recréées. Voici à nouveau le fichier Dockerfile :
FROM node:lts-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "/app/src/index.js"]
Chaque commande du fichier Dockerfile devient une nouvelle couche dans l’image.
Pour réduire le nombre de couches, vous pouvez restructurer votre Dockerfile pour prendre en charge la mise en cache des dépendances.
Pour les applications basées sur des nœuds, ces dépendances sont définies dans le fichier package.json.
L’approche consiste à copier uniquement ce fichier en premier, installer les dépendances et puis copier tout le reste.
Le processus recrée les dépendances yarn uniquement en cas de modification de package.json.
Mettez à jour le Dockerfile pour copier dans le
package.jsond’abord, installer les dépendances, puis copier tout le reste. Voici le nouveau fichier :FROM node:lts-alpine WORKDIR /app COPY package.json yarn.lock ./ RUN yarn install --production COPY . . CMD ["node", "/app/src/index.js"]Générez une nouvelle image à l’aide de
docker build.docker build -t getting-started .Vous devriez voir une sortie semblable aux résultats suivants :
Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:lts-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Running in d53a06c9e4c2 yarn install v1.17.3 [1/4] Resolving packages... [2/4] Fetching packages... info fsevents@1.2.9: The platform "linux" is incompatible with this module. info "fsevents@1.2.9" is an optional dependency and failed compatibility check. Excluding it from installation. [3/4] Linking dependencies... [4/4] Building fresh packages... Done in 10.89s. Removing intermediate container d53a06c9e4c2 ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> a239a11f68d8 Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 49999f68df8f Removing intermediate container 49999f68df8f ---> e709c03bc597 Successfully built e709c03bc597 Successfully tagged getting-started:latestToutes les couches ont été reconstruites. Ce résultat est attendu, car vous avez modifié le Dockerfile.
Apportez une modification au src/static/index.html. Par exemple, modifiez le titre pour dire « The Awesome Todo App ».
À l'aide de
docker build, construisez l'image Docker encore une fois. Cette fois, votre sortie doit être un peu différente.Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:lts-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> Using cache ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Using cache ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> cccde25a3d9a Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 2be75662c150 Removing intermediate container 2be75662c150 ---> 458e5c6f080c Successfully built 458e5c6f080c Successfully tagged getting-started:latestÉtant donné que vous utilisez le cache de build, il devrait aller beaucoup plus vite.
Constructions en plusieurs étapes
Les builds à plusieurs étapes sont un outil incroyablement puissant pour vous aider à utiliser plusieurs étapes pour créer une image. Il existe plusieurs avantages pour eux :
- Séparer les dépendances de compilation des dépendances d’exécution
- Réduire la taille globale de l’image en expédiant uniquement ce que votre application doit exécuter
Cette section fournit de brefs exemples.
Exemple Maven/Tomcat
Lorsque vous générez des applications Java, un JDK est nécessaire pour compiler le code source en bytecode Java. Ce JDK n’est pas nécessaire en production. Vous pouvez utiliser des outils tels que Maven ou Gradle pour vous aider à créer l’application. Ces outils ne sont pas nécessaires dans votre image finale.
FROM maven AS build
WORKDIR /app
COPY . .
RUN mvn package
FROM tomcat
COPY --from=build /app/target/file.war /usr/local/tomcat/webapps
Cet exemple utilise une étape, build, pour effectuer la build Java réelle à l’aide de Maven.
La deuxième étape, à partir de « FROM tomcat », copie les fichiers de l’étape build.
L’image finale est uniquement la dernière étape créée, qui peut être remplacée à l’aide du paramètre --target.
Exemple React
Lors de la génération d’applications React, vous avez besoin d’un environnement Node pour compiler le code JavaScript, les feuilles de style Sass, et bien plus encore en HTML statique, JavaScript et CSS. Si vous n’effectuez pas de rendu côté serveur, vous n’avez même pas besoin d’un environnement Node pour la build de production.
FROM node:lts-alpine AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run build
FROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html
Cet exemple utilise une image node:lts-alpine pour effectuer la génération, ce qui optimise la mise en cache de couche, puis copie la sortie dans un conteneur nginx.
Nettoyer les ressources
Gardez tout ce que vous avez fait jusqu’à présent pour poursuivre cette série de tutoriels.
Étapes suivantes
Vous avez découvert les options permettant de conserver des données pour les applications conteneur.
Que voulez-vous faire ensuite ?
Utilisez plusieurs conteneurs à l’aide de Docker Compose :
Créer des applications à plusieurs conteneurs avec MySQL et Docker Compose
Déployer sur Azure Container Apps :
Déployer sur Azure App Service