Charger des données d’organisation (chargement ultérieur)
Si les données organisationnelles ont déjà été chargées dans l’application Advanced Insights, vous pouvez, en tant qu’administrateur, utiliser les informations de cet article pour :
- Modifier les données existantes.
- Remplacez les données existantes.
- Supprimer les attributs organisationnels des données existantes.
Effectuez ces étapes après avoir préparé les données, comme décrit dans Préparer les données organisationnelles.
Importante
Suivez ces étapes uniquement si ce n’est pas la première fois que vous avez chargé des données organisationnelles. S’il s’agit de votre premier chargement, suivez les étapes décrites dans Charger des données organisationnelles (premier chargement).
Pour les clients qui proviennent de notre application héritée :
Si vous effectuez une migration à partir de l’application Insights avancées héritée, les données que vous avez chargées dans l’application héritée sont automatiquement disponibles dans la nouvelle application. Une fois que vous avez commencé à utiliser la nouvelle application pour charger vos données, effectuez tous les chargements suivants ici. Continuer à utiliser la nouvelle application empêche l’incohérence des données.
Flux de travail
Après avoir préparé les données sources, le processus de chargement suit ces étapes, qui sont décrites dans les sections suivantes :
- Vous chargez le fichier .csv.
- Vous mappez des champs.
- L’application valide vos données. (Si la validation échoue, vous pouvez choisir parmi quelques options décrites dans Échec de la validation.)
- L’application traite vos données. (Si le traitement échoue, vous pouvez choisir parmi quelques options décrites dans Échec du traitement.)
Une fois les données validées et les processus réussis, la tâche globale de chargement des données est terminée.
Pour mettre à jour, remplacer ou supprimer des données
Les trois actions partagent les deux mêmes premières étapes :
- Sélectionnez le bouton Démarrer sous l’onglet Hub de données ou le bouton Modifier ou démarrer un nouveau chargement sous l’onglet Connexions de données .
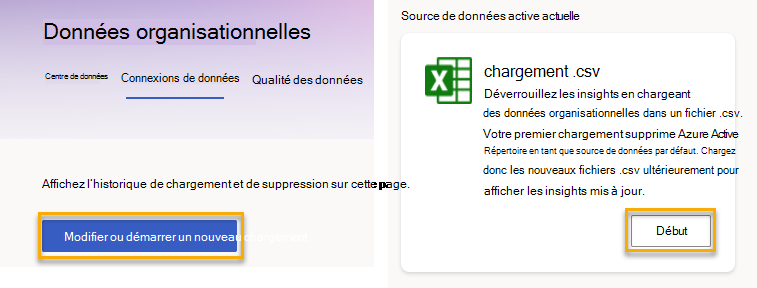
La page qui en résulte répertorie trois options :
- Ajouter ou modifier des données
- Supprimer des champs facultatifs
- Remplacer toutes les données
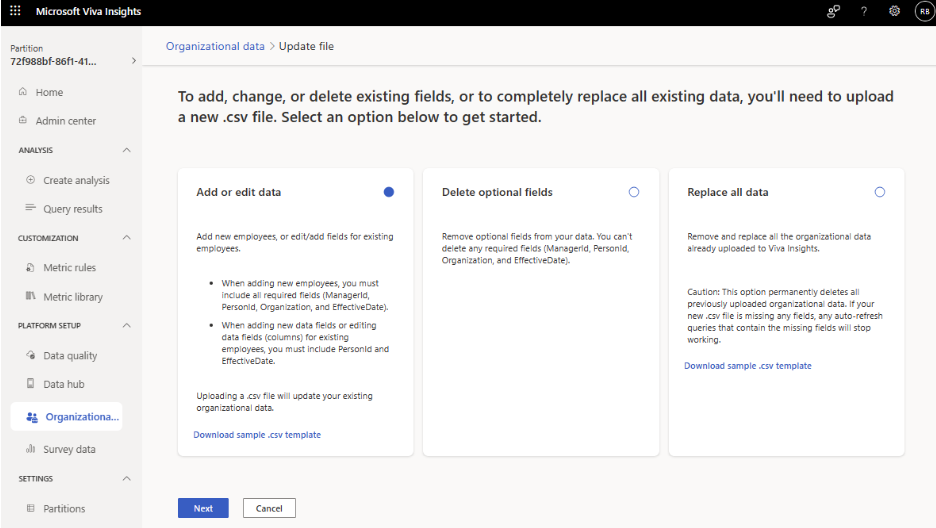
Effectuez votre sélection en fonction de ce que vous souhaitez faire, puis accédez à la section correspondante ci-dessous pour l’étape 3.
Action Section Commentaires Ajouter de nouveaux employés (lignes) Mettre à jour les données organisationnelles existantes Votre fichier doit inclure tous les champs obligatoires (PersonId, ManagerId et Organisation) et d’autres champs facultatifs. Ajouter de nouveaux champs (colonnes) Mettre à jour les données organisationnelles existantes Votre fichier doit inclure PersonId et d’autres champs facultatifs. Modifier les champs (colonnes) Mettre à jour les données organisationnelles existantes Votre fichier doit inclure PersonId et d’autres champs facultatifs. Supprimer des attributs Supprimer des champs facultatifs des données organisationnelles existantes Vous pouvez uniquement supprimer des attributs facultatifs. Si vous supprimez des champs utilisés dans les requêtes de mise en mémoire automatique, ces requêtes sont désactivées. Remplacer toutes les données organisationnelles existantes Remplacer des données existantes Cette option supprime définitivement toutes les données organisationnelles que vous avez chargées dans le passé. S’il manque des champs dans votre fichier, les requêtes de récupération automatique qui utilisent ces champs sont désactivées.

Mettre à jour et remplacer des données existantes
Mettre à jour les données existantes
File upload
- Sous Charger le fichier, sélectionnez le fichier que vous souhaitez charger, puis sélectionnez Suivant.
Vous êtes maintenant prêt à mapper des champs. Pour les étapes suivantes, accédez à Mappage de champs.
Exemple : ajout d’une nouvelle colonne de données
Supposons que vous souhaitiez charger une nouvelle valeur de score d’engagement pour chaque employé. Vous avez déjà chargé les 13 mois recommandés ou plus de données instantané, qui incluaient les colonnes requises pour tous les employés. Vous souhaitez maintenant appliquer la valeur du score d’engagement à toutes ces données historiques. Vous devez choisir l’option Mettre à jour les données organisationnelles existantes . Pour charger votre nouvelle colonne de données EngagementScore , vous devez charger le fichier qui la contient.
Étapes importantes pour la modification des attributs d’organisation
Si vous souhaitez modifier les attributs passés, votre fichier .csv doit inclure des valeurs mises à jour avec les effectiveDates correctes, pour vous assurer que les valeurs mises à jour s’appliquent sur la période appropriée.
Par exemple, considérez cet état initial des données d’organisation dans Viva Insights :
| StartDate | EndDate | PersonId | ManagerId | BadgeData | Commentaires |
|---|---|---|---|---|---|
| 01/01/0001 | 09/01/2023 | W@contoso.com | R@contoso.com | - | Pendant cette période, BadgeData est : |
| 09/01/2023 | 09/08/2023 | W@contoso.com | R@contoso.com | 102 | Pendant cette période, BadgeData est 102 |
| 09/08/2023 | 12/31/9999 | W@contoso.com | R@contoso.com | 106 | Pendant cette période, BadgeData est 106 |
Dans ce scénario, si vous souhaitez modifier la valeur ManagerId à partir du 06/09/2023 et que vous souhaitez que la nouvelle valeur s’applique indéfiniment, vous devez mettre à jour le ManagerId pour chaque date EffectiveDate commençant le 09/06/2023 à partir de tous les chargements incrémentiels passés, même si le champ ManagerId ne faisait pas partie de ces chargements incrémentiels.
Votre nouveau chargement se présente donc comme suit :
| EffectiveDate | PersonId | ManagerId |
|---|---|---|
| 09/06/2023 | W@contoso.com | D@contoso.com |
| 09/08/2023 | W@contoso.com | D@contoso.com |
Avec ce chargement, les données de votre organisation ressemblent alors à ceci. Notez que pour le 06/09/2023 et le 08/09/2023, le ManagerId a été mis à jour vers « D ».
| StartDate | EndDate | PersonId | ManagerId | BadgeData | Commentaires |
|---|---|---|---|---|---|
| 01/01/0001 | 09/01/2023 | W@contoso.com | R@contoso.com | - | |
| 09/01/2023 | 09/06/2023 | W@contoso.com | R@contoso.com | 102 | |
| 09/06/2023 | 09/08/2023 | W@contoso.com | D@contoso.com | 102 | Cette ligne a été ajoutée, mais elle a la valeur EndDate du 08/09/2023, car nous avons une entrée future existante. |
| 09/08/2023 | 12/31/9999 | W@contoso.com | D@contoso.com | 106 |
Ou imaginons un autre scénario. Si vous souhaitez modifier managerId uniquement pour les dates comprises entre le 06/09/2023 et le 08/09/2023, il s’agit de votre chargement :
| EffectiveDate | PersonId | ManagerId |
|---|---|---|
| 09/06/2023 | W@contoso.com | D@contoso.com |
Après ce chargement, les données de votre organisation ressemblent à ceci. Notez qu’après le 08/09/2023, le ManagerId est toujours « R », car aucune modification n’a été apportée à l’entrée passée le 08/09/2023.
| StartDate | EndDate | PersonId | ManagerId | BadgeData | Commentaires |
|---|---|---|---|---|---|
| 01/01/0001 | 09/01/2023 | W@contoso.com | R@contoso.com | - | |
| 09/01/2023 | 09/06/2023 | W@contoso.com | R@contoso.com | 102 | |
| 09/06/2023 | 09/08/2023 | W@contoso.com | D@contoso.com | 102 | Cette ligne a été ajoutée, mais elle a la valeur EndDate du 08/09/2023, car nous avons une entrée future existante. |
| 09/08/2023 | 12/31/9999 | W@contoso.com | R@contoso.com | 106 |
Enfin, si vous ne vous souvenez pas des valeurs précédentes du champ EffectiveDate, vous devez supprimer les colonnes qui doivent être modifiées et charger à nouveau les colonnes avec les valeurs mises à jour. Ou, si plusieurs colonnes doivent être modifiées, vous pouvez également remplacer toutes les données passées par un nouveau chargement avec les valeurs mises à jour.
Remplacer des données existantes
File upload
Remplacez les données existantes :
- Entrez un nom de chargement.
- Sous Charger un fichier, sélectionnez le fichier .csv que vous souhaitez charger.
Vérifiez que le fichier .csv est :
- Encodé en UTF-8
- Ne pas ouvrir dans un autre programme lorsque vous commencez le processus de chargement
- Pas plus de 1 Go
Remarque
Pour afficher la structure et les instructions relatives aux fichiers .csv et éviter les problèmes courants lors du chargement, vous pouvez télécharger un modèle via le lien Télécharger le modèle .csv .
- Chargez votre fichier en sélectionnant Suivant. Si vous devez annuler le chargement, sélectionnez Annuler.
Vous êtes maintenant prêt à mapper des champs. Pour les étapes suivantes, accédez à Mappage de champs.
Supprimer des champs facultatifs des données organisationnelles existantes
- Supprimer les champs :
- Nommez votre action de suppression afin de pouvoir y faire référence ultérieurement.
- Identifiez l’attribut à supprimer, puis case activée la zone correspondante.
- L’écran qui en résulte répertorie les attributs qui ont été supprimés. Sélectionnez Retour pour revenir au hub de données.
Le processus de suppression est maintenant terminé.
Importante
Les sections suivantes s’appliquent uniquement aux actions de chargement et de remplacement .
Mappage de champs
Une fois que vous avez chargé votre fichier, la page de mappage de champs s’affiche. Pour afficher des insights à partir de vos données, vous devez mapper des champs (colonnes) de votre fichier .csv aux noms de champs que l’application reconnaît.
Il existe deux types de champs : Système par défaut et Personnalisé.
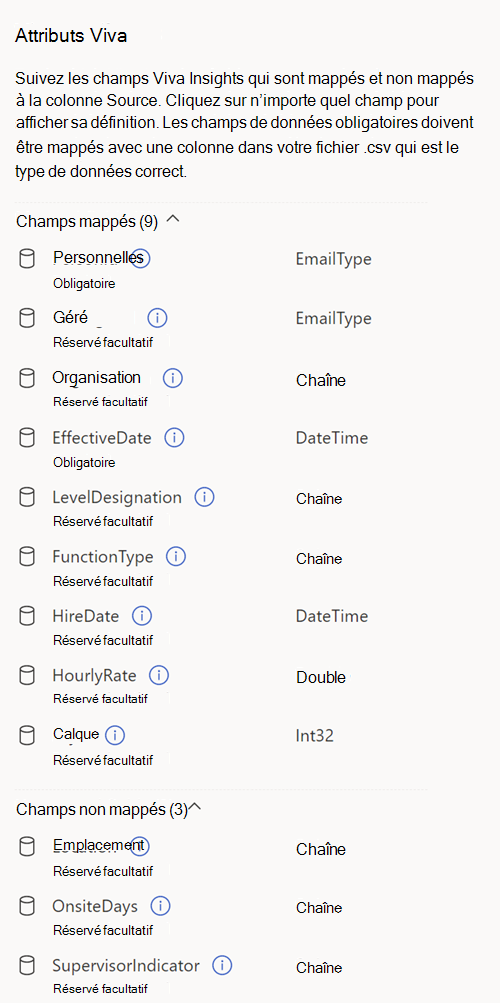
Système par défaut (obligatoire ou facultatif)
Les champs système par défaut peuvent être obligatoires ( PersonId, ManagerId et Organisation) ou facultatifs. Ces champs obligatoires et facultatifs représentent des attributs que Viva Insights connaît et utilise dans des calculs spécifiques au-delà du regroupement et du filtrage.
Importante
Chaque champ requis doit avoir une valeur valide et non null dans chaque ligne. Vous devez mapper toutes les valeurs Viva Insights requises, même si les en-têtes de colonne dans vos fichiers .csv ne correspondent pas exactement au nom de la valeur Viva Insights.
Les champs facultatifs sont des champs système couramment rencontrés que l’application suggère d’utiliser. Vous n’avez pas besoin de mapper des champs facultatifs si votre organization n’a pas de données pour eux.
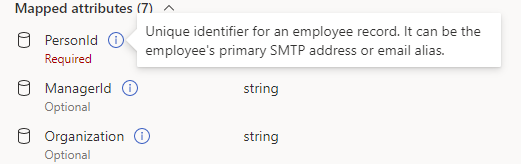
Pour savoir si un champ est obligatoire ou facultatif, reportez-vous à la section attributs Viva à droite de la liste de mappage. Les attributs obligatoires ont une étiquette « Obligatoire » et les attributs facultatifs ont une étiquette « Facultatif ».
Personnalisé
Les champs personnalisés sont des attributs facultatifs que vous pouvez créer. La section suivante, étape 5a, explique comment mapper et nommer un attribut personnalisé.
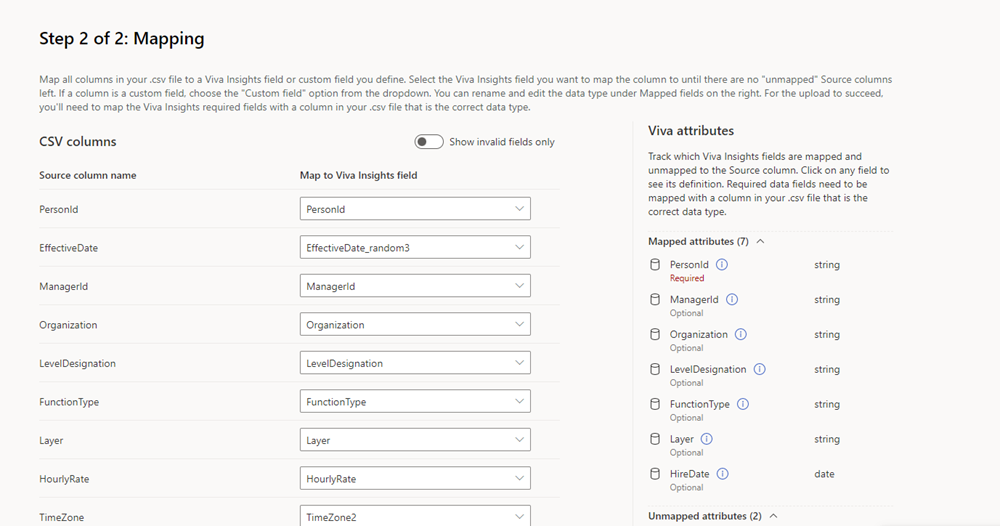
Pour mapper des champs
Suivez les étapes ci-dessous pour mapper vos données .csv aux attributs Viva Insights.
Importante
Tous les champs d’en-tête .csv, qui apparaissent sous Nom de la colonne source, doivent être mappés avant de pouvoir passer à la partie suivante du processus de chargement.
Pour chaque champ de Viva Insights obligatoire :
- Recherchez l’en-tête de colonne correspondant sous Nom de la colonne source. Pour éviter une erreur de validation ultérieurement, vérifiez que cette colonne est le type de données approprié.
- Sous la colonne Mapper à Viva Insights champ, ouvrez la liste déroulante et sélectionnez l’attribut Viva Insights qui correspond à l’en-tête de colonne que vous avez identifié à l’étape a.
Conseil
Pointez sur un nom d’attribut pour lire sa description.
Si vous mettez à jour des données, vous pouvez choisir de voir uniquement les nouvelles colonnes que vous avez ajoutées ou les en-têtes de colonne que vous avez modifiés. Pour ce faire, sélectionnez le bouton bascule Afficher uniquement les champs non valides .
Répétez les étapes 4a et 4b pour les champs personnalisés et facultatifs.
- Pour ajouter un champ personnalisé, incluez-le simplement en tant que colonne dans votre fichier de données. L’application lui attribue automatiquement un nom et le mappe. Pour cette version de Viva Insights, tous les attributs personnalisés se voient attribuer un nom par défaut et peuvent uniquement être classés en tant que types de données String.
Importante
Ne chargez pas TimeZone en tant que colonne. Vous obtiendrez une erreur.
- Pour ajouter un champ personnalisé, incluez-le simplement en tant que colonne dans votre fichier de données. L’application lui attribue automatiquement un nom et le mappe. Pour cette version de Viva Insights, tous les attributs personnalisés se voient attribuer un nom par défaut et peuvent uniquement être classés en tant que types de données String.

Une fois les champs mappés, l’application valide et traite vos données comme décrit dans les sections suivantes. Si la validation et le traitement réussissent, votre entrée dans le processus de chargement est terminée.
Si les colonnes attendues sont manquantes ou exclues
Pour qu’une requête s’exécute correctement, des attributs particuliers (colonnes) doivent être présents dans les données organisationnelles. Cette exigence est également vraie pour les requêtes avec l’option d’actualisation automatique activée. Si les attributs (colonnes) qu’une requête utilise sont manquants dans un chargement de données, l’application vous avertit. Vous verrez une table qui répertorie les champs d’attribut et les requêtes dans lesquelles ces champs sont utilisés, ainsi qu’un message d’avertissement : « La poursuite désactive ces requêtes. Si une requête d’actualisation automatique contenant ces champs est créée pendant que la fonction est en cours, elle est également désactivée. »
Après avoir examiné les attributs manquants :
- Si vous décidez de ne pas poursuivre le chargement ou le remplacement des données, sélectionnez Annuler. Ce bouton vous renvoie à la page de mappage de champs.
- Si vous décidez de poursuivre le chargement des données même s’il manque des attributs, sélectionnez Suivant. Notez que ce choix désactive l’actualisation automatique pour les requêtes répertoriées ci-dessus. Vous pouvez toujours accéder aux résultats des dernières exécutions de ces requêtes.
Validation
Une fois que vous avez mappé les attributs, l’application commence à valider vos données.
Dans la plupart des cas, la validation des fichiers doit se terminer rapidement. Si votre fichier de données d’organisation est volumineux, la validation peut prendre jusqu’à une ou deux minutes.
Une fois cette phase terminée, la validation a réussi ou échoué.
Pour plus d’informations sur ce qui se passe ensuite, accédez à la section appropriée :
La validation réussit
Une fois la validation réussie, Viva Insights commence à traiter vos nouvelles données. Le traitement peut prendre entre quelques heures et environ un jour. Pendant le traitement, vous verrez un status « Traitement » dans la table Connexions de données > Charger ou supprimer en cours.
Une fois le traitement terminé, il a réussi ou échoué. Selon le résultat, vous recevrez une notification de réussite ou une notification d’échec dans le coin supérieur droit de l’écran Connexions de données .
Le traitement réussit
Lorsque le traitement réussit, un status « Réussite » s’affiche dans la table Historique de chargement ou de suppression. À ce stade, le processus de chargement est terminé.

Une fois que vous avez reçu le status « Réussite », vous pouvez :
- Sélectionnez l’icône d’affichage (œil) pour afficher un résumé des résultats de validation.

- Sélectionnez l’icône de mappage pour afficher les paramètres de mappage du flux de travail.
Remarque
Chaque locataire ne peut avoir qu’un seul chargement en cours à la fois. Vous devez terminer le flux de travail d’un fichier de données, ce qui signifie que vous le guidez vers une validation et un traitement réussis ou que vous l’abandonnez avant de commencer le flux de travail du fichier de données suivant. La status ou l’étape du flux de travail de chargement s’affiche sous l’onglet Connexions de données.
Échec du traitement
Si le traitement échoue, vous verrez un status ayant échoué dans la table Charger ou supprimer en cours. La sélection du lien dans le status vous permet d’obtenir une explication de l’échec.
Sélectionnez Modifier ou démarrer un nouveau chargement. Ce bouton vous permet d’effectuer les opérations suivantes pour le fichier de données que vous avez chargé précédemment :
- Modifier pour ajouter de nouvelles lignes ou colonnes.
- Supprimer les attributs.
- Remplacez le fichier existant par un nouveau fichier.
Remarque
Les échecs de traitement sont généralement dus à des erreurs back-end. Si vous constatez des échecs de traitement persistants et que vous avez corrigé les données dans votre fichier chargé, créez un ticket de support avec nous.
Échec de la validation
Si la validation des données échoue, vous verrez un nouvel écran avec une erreur « Échec de la validation » et des informations sur l’échec. Vous pouvez sélectionner le bouton Annuler le chargement si vous ne souhaitez pas poursuivre le processus de chargement.
Avant d’apporter des modifications au fichier source et de réessayer le chargement, vous pouvez sélectionner Télécharger les problèmes. Ce fichier journal décrit les problèmes dans vos données qui peuvent avoir provoqué les erreurs de validation. Utilisez ces informations pour décider de la procédure suivante : corriger les données sources ou modifier vos paramètres de mappage.
Instructions pour corriger les erreurs dans les données
Quand une ligne ou une colonne de données a une valeur non valide pour un attribut, le chargement entier échoue tant que vous n’avez pas corrigé le fichier source (ou que vous n’avez pas corrigé le mappage d’attributs).
Pour en savoir plus sur la mise en forme de votre fichier afin d’éviter les erreurs, consultez Règles de fichier et erreurs de validation.
Rubrique connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour