Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit la conception fonctionnelle de la migration dynamique d'appareils de calcul hétérogènes (GPU, NPU, etc.) virtualisés via le partitionnement SR-IOV (virtualisation d'E/S d'une racine unique). Les appareils qui prennent en charge le partitionnement via les modèles de pilotes WDDM et MCDM font désormais partie intégrante de nos offres de virtualisation. Par conséquent, il est important de prendre en charge la migration dynamique et d'aider nos abstractions de virtualisation à maximiser leur fiabilité pour limiter l'impact sur les clients en cas de modification de l'affectation des ressources. Cet article décrit également la migration rapide de ces appareils.
La migration dynamique est prise en charge à partir de Windows 11, version 24H2 (WDDM 3.2). Il s'agit plus généralement d'une extension des DDI de paravirtualisation GPU (GPU-P) pour les pilotes qui affichent la capacité. En option, les pilotes MCDM qui implémentent les interfaces de virtualisation GPU-P peuvent implémenter également ces interfaces de migration dynamique, y compris leur extension avec des événements de triage.
Dans cet article, « GPU » fait simplement référence à des appareils qui implémentent l'infrastructure de virtualisation GPU-P, qu'il s'agisse de WDDM ou MCDM, et qu'il s'agisse de GPU, NPU ou tout autre appareil de calcul hétérogène.
Genres de migration de ressources et objectifs
La migration des ressources est la possibilité de déplacer une virtualisation vers de nouvelles ressources physiques. Parmi les différentes façons de déplacer une exécution virtualisée figurent les suivantes :
Mise hors tension brusque. La carte mère virtuelle peut être mise hors tension directement, stoppant ainsi l'exécution des ressources virtuelles. Toutes les applications qui ne sont pas tolérantes aux coupures de courant perdent les données sur lesquelles elles travaillaient et tous les états de l'appareil sont réinitialisés. Le disque dur virtuel (VHD) peut ensuite être virtualisé sur un autre ordinateur hôte, ce qui entraîne un démarrage à froid.
Mise hors tension progressive Cette mise hors tension diffère de la précédente en ce qu'elle envoie simplement la demande de mise sous tension au SE invité. Le SE invité distribue ensuite le mécanisme de mise hors tension aux applications pour que leur arrêt s'effectue normalement. Les applications peuvent utiliser cette notification pour stocker toutes les données en toute sécurité et les enregistrer pour reprendre le fonctionnement au démarrage, bien que cela dépende de la programmation de chaque application. Une mise hors tension progressive nécessite un SE invité prenant en charge ce mécanisme d'arrêt normal et les services appropriés pour stocker l'état actuel et reprendre le fonctionnement au redémarrage.
Mise en veille prolongée. Cette autre technologie provenant de l'invité permet à celui-ci de se placer en état de veille à démarrage rapide, dans lequel tous les processus d'application sont gelés, l'état de l'appareil est purgé dans la mémoire du processeur et toute la mémoire est ensuite envoyée au stockage pour permettre la mise hors tension du matériel. Le disque dur virtuel de stockage de machine virtuelle peut ensuite être redémarré sur un autre ordinateur, avec la mémoire chargée, l'état de l'appareil restauré et les processus réactivés. La mise en veille prolongée n'est disponible que sur les SE invités qui la prennent en charge. Il s'agit d'un processus assez invasif qui dépend de la stabilité de l'invité, mais qui fournit un mécanisme capable de restaurer les processus d'application en l'état, ce que les mécanismes de mise hors tension ne permettent pas.
Migration rapide (également appelée Enregistrement et restauration de machine virtuelle). Avec cette technologie, la machine virtuelle est en pause (les processeurs virtuels arrêtent la planification) et tous les états nécessaires pour restaurer l'état sur les nouvelles ressources physiques sont rassemblés dans le système d'exploitation hôte, y compris la mémoire de la machine virtuelle et l'état de tous les appareils. Cet état est ensuite transféré vers le nouvel hôte qui crée une machine virtuelle avec tous les contextes de processeur virtuel chargés, mappe la mémoire à l'espace de la machine virtuelle et restaure les états de l'appareil. Un PowerOnRestore redémarre ensuite l'exécution des processeurs virtuels. Cette technologie est indépendante du SE invité et ne dépend pas d'une exécution dans l'environnement invité. Il s'agit donc d'un moyen plus fiable de maintenir le processus et l'état de l'appareil que la mise en veille prolongée. L'utilisateur de virtualisation peut remarquer un temps d'arrêt significatif, car la mémoire de la machine virtuelle peut s'élever à plusieurs Go, ce qui entraîne des temps de transfert parfois importants.
Live Migration. Si nous avons la possibilité de transférer du contenu pendant que les ressources virtualisées sont toujours actives et que nous pouvons suivre le contenu qui est compromis, nous pouvons transférer du contenu significatif tout en laissant la virtualisation active. Ensuite, lorsque la machine virtuelle est en pause, il est nécessaire de transférer beaucoup moins de contenu et nous pouvons réduire le temps pendant lequel la virtualisation ne s'exécute pas. Le résultat réduit l'impact pour l'utilisateur final, dans la mesure où toutes les opérations qui ont lieu pendant la migration se poursuivent sans entrave et autant que possible, l'impact sur la consommation des ressources en est réduit. En particulier, les délais d'indisponibilité (contraintes de temps externes à l'indisponibilité de virtualisation, comme les délais d'expiration du protocole TCP ou d'autres protocoles avec des points de terminaison externes) peuvent être réduits, voire supprimés.
Chaque progression réduit ou supprime une partie de la prise de conscience (souvent importante) par le client de la modification de l'affectation physique d'une virtualisation, ce qui rend cette dernière de plus en plus complète et transparente pour l'utilisateur. En combinaison avec d'autres technologies (comme l'isolation en cas de plantage de l'hôte) qui réduisent les dépendances du client à l'égard de l'infrastructure, notre solution de virtualisation se rapproche de l'idéal défini par une indépendance d'affectation et un calcul véritablement éphémère.
Conception à grande échelle
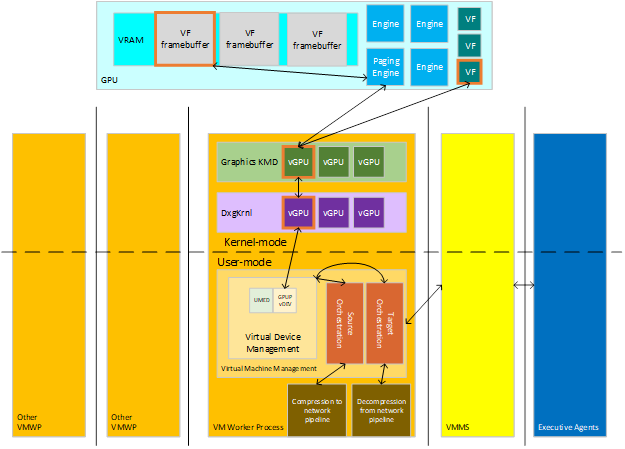
La migration dynamique transfère le contenu de virtualisation d'un hôte source vers un hôte cible. La virtualisation consiste en plusieurs appareils avec leurs états, qui peuvent être caractérisés par une capacité de mémoire, de calcul et de stockage, chacun comportant des données qui doivent être transférées entre les appareils de la source et les appareils de la cible. Les agents exécutifs qui gèrent les virtualisations entre les clusters communiquent avec les hôtes pour leur faire savoir qu'ils doivent configurer l'orchestration de la migration source d'une machine virtuelle existante (lorsque le contenu quitte l'hôte) ou la migration cible vers une nouvelle machine virtuelle (pour recevoir le contenu). Les principaux acteurs de cette interaction sont représentés sur le diagramme suivant.
:
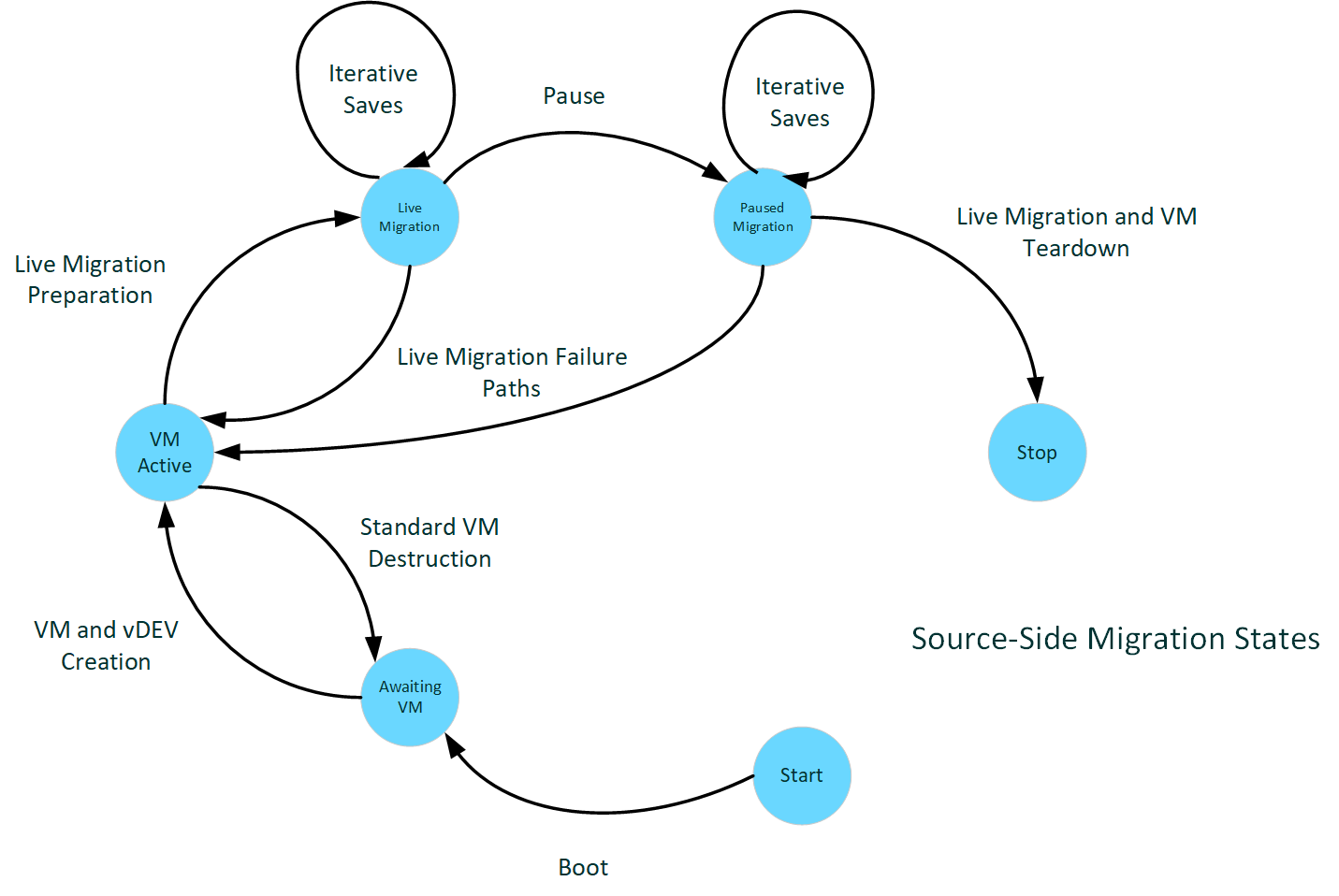
Époques de l'hôte source
Le diagramme suivant illustre les états de migration du côté source.
:
Démarrage du côté source
En règle générale, lorsqu'un hôte démarre, le KMD signale les fonctionnalités de l'appareil au noyau à travers plusieurs appels d'initialisation.
Lorsque le KMD reçoit l'appel DxgkDdiQueryAdapterInfo pour les données DXGKQAITYPE_GPUPCAPS, il peut définir le bit de capacité LiveMigration ajouté à DXGK_GPUPCAPS. Lorsque le KMD définit ce bit, il indique que le pilote prend en charge la migration dynamique.
Une condition préalable à la prise en charge de la migration dynamique est la prise en charge du suivi des pages VRAM modifiées sur tous les segments de mémoire locale GPU, comme décrit dans Suivi des bits d'intégrité. Cette prise en charge est signalée par d'autres appels DxgkDdiQueryAdapterInfo correspondant à d'autres types d'informations. Un pilote qui signale la prise en charge de la migration dynamique doit également signaler la prise en charge du suivi des bits d'intégrité. Une configuration dans laquelle la prise en charge de la migration dynamique n'est pas associée à celle du suivi des bits d'intégrité est non valide, et DxgUnekrnl ne peut pas démarrer l'adaptateur.
Machines virtuelles en ligne
Une fois que l'hôte démarre et que les piles de gestion sont en ligne, l'activité des machines virtuelles commence à entrer en ligne. Les demandes de démarrage et d'arrêt des machines virtuelles commencent à arriver, et nous commençons à voir les vGPU GPU-P projetés dans ces virtualisations.
En supposant que la capacité du plan de bits d'intégrité est performante, Dxgkrnl appelle DxgkDdiStartDirtyTracking après avoir réservé les ressources VRAM à une VF (fonction virtuelle), ce qui permet au système de suivre l'intégrité de la VRAM dans le cas où le VF participe ultérieurement à un scénario de migration.
Ce démarrage de machine virtuelle commence par l'interception de l'accès à la table des interruptions pour virtualiser la prise en charge des interruptions, qui se poursuit pendant toute la durée de vie de la machine virtuelle.
Préparation de l'envoi de migration dynamique
La pile de gestion envoie l'événement pour démarrer la migration dynamique lorsque ses contrôles l'indiquent, et la gestion de l'ordinateur d'état de migration rassemble tous les états de la machine virtuelle qui sont immuables pendant la durée de vie de la virtualisation (métriques de configuration de partition du vGPU) afin de reconstruire le vGPU sur la cible. Une fois prêt, le processus de préparation des mémoires tampons de transport et d'initialisation de la pile de transport démarre.
Cette époque génère un appel au DDI DxgkDdiPrepareLiveMigration introduit. Le KMD doit établir les stratégies de planification PF/VF qui donnent à la migration dynamique la capacité de diffuser du continu incohérent depuis la VRAM de l'hôte tout en préservant les performances de la VF. Si le suivi des bits d'intégrité est signalé comme étant non performant, c'est également à ce point que que celui-ci démarre.
Envoi de migration dynamique
:
Nous entrons alors dans la phase active du transfert de VRAM incohérente. Cette phase implique d'effectuer des appels à travers le DDI de suivi des bits d'intégrité pour obtenir des instantanés du framebuffer de la VF, puis d'effectuer la pagination de ces pages du GPU vers les mémoires tampons de processeur préparées précédemment.
Il y a ensuite une étape dans ce transfert où la machine virtuelle et tous ses appareils virtuels sont mis en pause. La VF peut cesser d'être planifiée pour l'invité et, à ce stade, tout intervalle de temps supplémentaire pouvant être donné à la PF pour terminer la pagination du contenu doit l'être. Étant donné que la VF et le processeur virtuel sont mis en pause dans la machine virtuelle, il ne doit y avoir aucune autre modification du contenu migré (processeur ou mémoire locale de l'appareil) après ce point.
Envoi de migration en pause
Les dernières itérations des pages incohérentes sont transférées tandis qu'elles sont en pause. À ce stade, un appel est effectué pour collecter les tout derniers éléments de l'état de l'appareil et du pilote qui étaient mutables pendant qu'ils étaient actifs et qui n'ont pas pu être transférés dans la préparation précédente. Cet état peut être n'importe quelle reconstruction d'état nécessaire côté cible, des structures de suivi ou en règle générale des informations nécessaires pour compléter la restauration de l'état de la VF côté cible.
Désactivation de migration dynamique
Enfin, une fois que la machine virtuelle et tous ses appareils virtuels ont transféré leur état dans leurs nouvelles réalisations physiques, le côté source peut supprimer les éléments restants de la machine virtuelle. Les mémoires tampons et autres états de migration sont effacés et le vGPU est détruit.
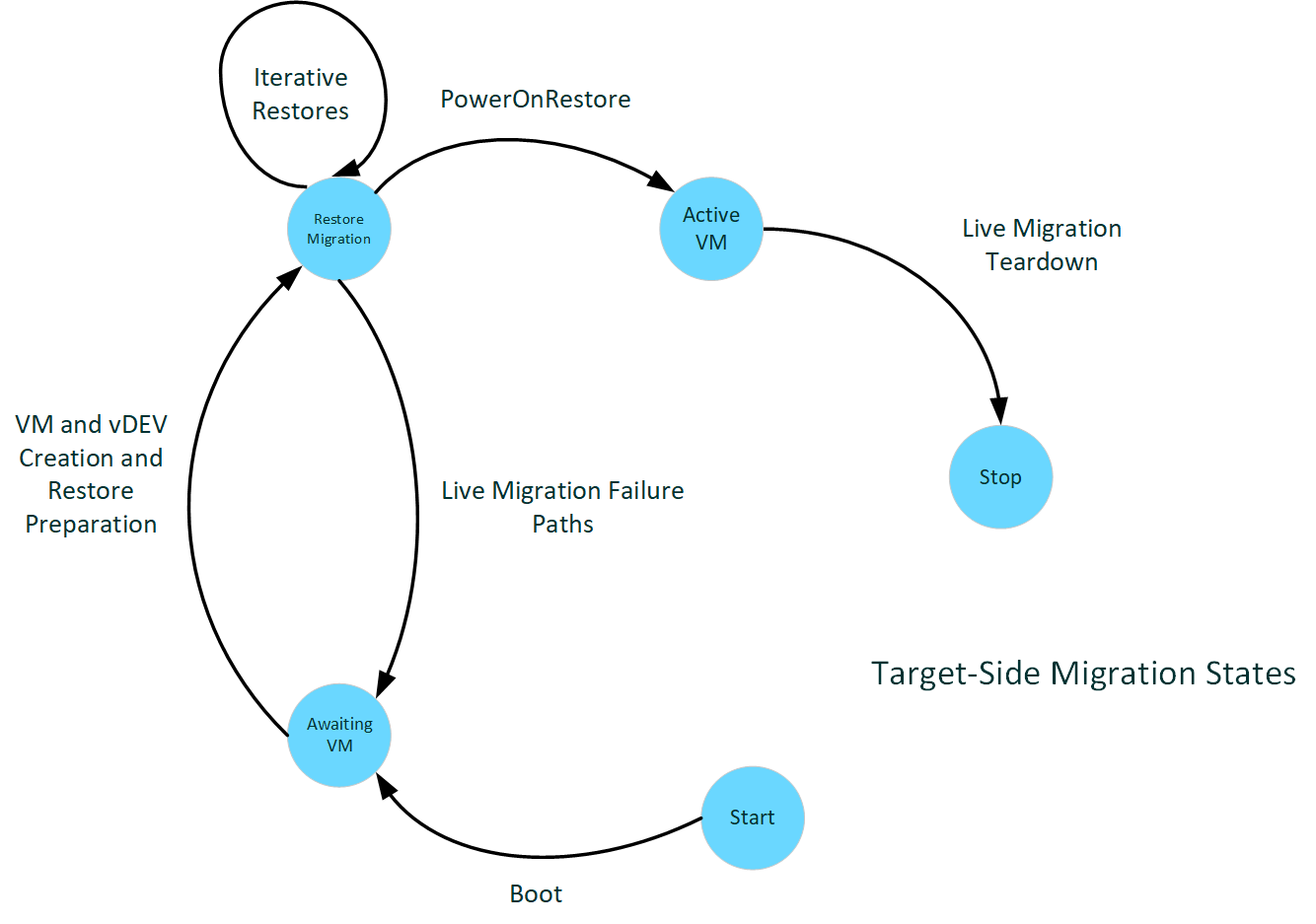
Époques de l'hôte cible
Le diagramme suivant illustre les états de migration du côté cible.
:
Démarrage du côté cible
Le démarrage du côté cible est similaire à celui du côté source. Le démarrage s'effectuer sur l'ensemble du système, qui peut être une source et une cible sur différentes VF tout au long de son cycle de vie. Le pilote doit simplement spécifier la prise en charge de la migration dynamique pour pouvoir participer.
Préparation de la réception de migration dynamique
Côté cible, la machine virtuelle est construite comme s'il s'agissait d'une nouvelle machine virtuelle. La machine virtuelle et les appareils virtuels sont créés. Ce processus de création inclut le GPU virtuel, créé avec les mêmes paramètres que ceux utilisés dans sa création côté source. Après la création, les données de validation sont reçues et transmises au pilote afin de s'assurer que le côté cible est compatible avec la source pour restaurer la machine virtuelle. À ce stade, il s'agit de s'assurer que rien ne peut compromettre cette compatibilité, notamment la version du pilote, la ou les versions du microprogramme et tout autre état ambiant du système cible et du pilote. Le pilote se configure pour permettre l'accès de la PF à tous les intervalles de temps de pagination qui devraient normalement être attribués à la VF, pendant que celle-ci n'est pas encore active.
Réception de migration dynamique
:
La réception de données de pages incohérentes est similaire à l'étape de la source, exception faite que le sens de pagination va des mémoires tampons du processeur vers la VRAM. Tous les transferts sont effectués pendant que la VF est mise en pause, de sorte que l'intégralité du transfert peut être effectuée dans le budget de la VF.
Démarrage et désactivation de la machine virtuelle
Une fois la migration VRAM terminée, le vGPU a la possibilité de configurer tout état supplémentaire devant être transféré (données d'enregistrement mutables finales). Nous démarrons ensuite la machine virtuelle côté cible et désactivons l'état de migration, y compris les mémoires tampons utilisées pour le transfert.
Objectifs de performance
Une partie importante de la migration dynamique est sa réactivité. En particulier, elle réduit le temps d'arrêt de la virtualisation lorsqu'elle n'a pas à répondre au niveau externe (soit à l'utilisateur de la virtualisation, soit à tout point de terminaison auquel celui-ci peut être connecté). De nombreux protocoles de pile réseau ont des délais d'expiration à travers les ordinateurs distants qui sont assez brefs avant que la nouvelle tentative ou le rétablissement n'échoue, et peuvent donc être perturbants pour l'utilisateur lorsqu'ils sont supprimés. L'objectif fixe commun est un temps de pause total pour le transfert et le démarrage inférieur à trois quarts de seconde (750 ms), ce qui situe la durée hors contact à une valeur inférieure aux délais d'expiration de piles les plus courants.
De plus, dans la mesure du possible, les modifications de performances apportées au système actif ne doivent pas déclencher d'autres interruptions pour l'utilisateur final. Sur les appareils utilisant ces DDI, le système ne doit pas augmenter de façon significative la valeur des TDR en ralentissant l'intervalle de temps planifié. À présent, nous prévoyons que la plupart des TDR ne sont pas de longs paquets, mais des appareils en suspension, et le fait de doubler ou tripler le temps d'exécution d'un paquet ne devrait pas mener la plupart des paquets à dépasser les délais d'expiration qui sont de plusieurs secondes. Nous devons cependant veiller à ne pas trop augmenter nos délais d'expiration pour garantir l'ensemble des performances.
Interfaces de pilotes d'appareils
En règle générale, les DDI de migration dynamique reprennent les concepts généraux des DDI de WDDM et MCDM, et tout particulièrement des DDI de virtualisation de GPU-P.
hAdapter fait généralement référence au jeton de handle qui représente un appareil spécifique géré par ce pilote. Les systèmes équipés de plusieurs appareils physiques énumérés par le système peuvent avoir un pilote gérant plusieurs hAdapters. Par conséquent, hAdapter localise l'appareil spécifique.
vfIndex identifie la fonction virtuelle / vDEV qui est référencée. Il localise l'appareil virtuel spécifique. Il est parfois également appelé ID de partition.
DeviceLuid localise également l'appareil virtuel spécifique, mais dans le langage de l'interface UMED avec la gestion des appareils virtuels.
SegmentId identifie l'exposition d'un segment VidMm spécifique lors du référencement de contenu stocké sur l'appareil, comme la réserve VRAM.
Remarque sur les définitions d'interface
Cet article fait référence à des structures de taille dynamique. Ces structures sont implémentées à travers des tableaux de taille dynamique, que les pages de référence décrivent comme suit :
size_t ArraySize;
ElementType Array[ArraySize];
où l'interface transfère une taille de tableau auparavant dans la structure et l'analyse de l'objet d'interface effectue ensuite une itération sur ce nombre d'éléments lorsque le tableau est fourni. Ces déclarations ne sont pas valides en C/C++, car ces langages expriment des fragments de taille statique. Il faut tout d'abord lire la structure de taille statique, puis analyser le code de façon dynamique.
Rapports sur le démarrage et les capacités des appareils
Les capacités suivantes sont ajoutées à DXGK_GPUPCAPS :
- La capacité LiveMigration indique la prise en charge par le pilote de la fonctionnalité de migration dynamique (généralement, les DDI ajoutés qui sont mentionnés dans cet article, à l'exception de DxgkDdiSetVirtualGpuResources2).
- La capacité ScatterMapReserve indique la prise en charge par le pilote de DxgkDdiSetVirtualGpuResources2, qui sera ajoutée dans une future version.
Le KMD doit remplir ces capacités lorsque le système d'exploitation appelle DxgkDdiQueryAdapterInfo avec une requête DXGKQAITYPE_GPUPCAPS. Le système d'exploitation lance une requête de capacités au moment de l'initialisation de l'appareil après l'appel de DxgkDdiStartDevice et lorsque l'adaptateur prend en charge le partitionnement du GPU.
Si le pilote retourne la capacité ScatterMapReserve, il doit exposer le type DXGKQAITYPE_SCATTER_RESERVE ajouté avec les structures associées suivantes afin que le système d'exploitation puisse interroger les capacités de réserve de diffusion du pilote :
- DXGK_QUERYSCATTERRESERVEIN pour pInputData
- DXGK_QUERYSCATTERRESERVEOUT pour pOutputData
Prise en charge de la pagination de diffusion
Pour prendre en charge le transfert de pages incohérentes non contiguës vers et depuis le framebuffer, cette fonctionnalité est l'une des premières à exercer des mappages d'adresses virtuelles de GPU qui ne sont pas soutenues par des adresses physiques contiguës. Les interfaces de pagination actuelles n'ont pas besoin d'être mises à jour, car il s'agit toujours d'une possibilité générale prise en charge par les tables de pages. Toutefois, les détails d'implémentation latents qui ont fait des hypothèses sur la contiguïté sont susceptibles d'être exposés par cette modification. Il est donc important de comprendre ce mécanisme du système d'exploitation et la manière dont il exécute les interfaces de pagination virtuelle, et de s'assurer que la pagination est résistante à cette modification.
En particulier, l'interface TransferVirtual transfère désormais des plages d'adresses virtuelles qui ne sont pas mappées de façon contiguës dans le framebuffer.
Démarrage de la migration dynamique côté envoi
Lorsque le système démarre le composant dynamique de la migration, il doit appeler le DDI DxgkDdiPrepareLiveMigration ajouté. Cet appel signale au pilote que cette époque a démarré et lui permet de configurer la stratégie de planification VF pour la migration, qui devrait allouer une partie du budget des VF libres et en migration à la pagination PF.
Dxgkrnl appelle ensuite le DDI DxgkDdiSaveImmutableMigrationData du KMD pour collecter des informations sur l'appareil à restaurer côté cible.
Une fois que le système regroupe et envoie les données immuables et les données de validation, la boucle itérative principale d'envoi des données incohérentes commence.
Enregistrement/envoi itératif
Comme décrit dans la section de présentation, l'opération d'enregistrement itérée utilise DxgkDdiQueryDirtyBitData pour obtenir un instantané du plan de bits d'intégrité actuel pour la VF au début de chaque itération et utilise l'opération standard DXGK_OPERATION_VIRTUAL_TRANSFER pour paginer les pages incohérentes signalées. Si cette opération se produit sur un appareil ayant signalé dans ses capacités de suivi des bits d'intégrité que son impact n'est pas négligeable sur les performances, le contrôle d'itération du système active d'abord un suivi des bits d'intégrité, puis transfère l'intégralité du framebuffer avant le premier appel pour interroger le plan de bits d'intégrité.
Pour le transfert virtuel, le principal comportement mis à jour est que le mappage ne se fait pas de VA contiguës à PA contiguës. Il peut y avoir des pages PA déconnectées sous le mappage. Dans le cas contraire, le comportement est celui décrit dans la documentation originale sur la pagination et le suivi du plan de bits d'intégrité, et cette fonctionnalité n'y est pas ajoutée.
Fin de la migration dynamique côté envoi
À la fin de la migration, le système doit collecter l'état de tous les appareils et pilotes nécessaires pour terminer de reconstruire l'état et le suivi qui n'ont pas encore été transférés. Ces données n'ont pas pu être transférées, car elles ne correspondaient pas aux exigences d'immuabilité des données de migration antérieures et qu'il ne s'agissait pas de contenu incohérent de la VRAM. Pour ce faire, Dxgkrnl appelle le DDI DxgkDdiSaveMutableMigrationData ajouté. Cette utilisation du DDI est similaire à DxgkDdiSaveImmutableMigrationData.
Finalement, lorsqu'il n'est plus nécessaire de configurer la migration sur cette VF, DxgkDdiEndLiveMigration est appelé. L'ensemble de la planification et des états doit revenir à une configuration de non-migration.
Démarrage de migration dynamique côté réception
Lorsque les données immuables arrivent côté réception, le système les transfère directement au KMD via un appel à DxgkDdiRestoreImmutableMigrationData.
Ce DDI ne doit être appelé que pour les VF actuellement mises en pause.
Restauration/réception itérative
Là encore, la pagination de diffusion fonctionne de manière itérative, mais cette fois-ci, sans les appels pour inspecter le plan de bits d'intégrité associé au framebuffer réservé par la VF, car le plan de bits d'intégrité sur la cible est construit par la pagination. La direction de pagination est inversée. Le contenu des mémoires tampons reçues est transféré vers la VRAM, avec le positionnement des pages dicté.
Fin de la migration dynamique côté réception
Une fois la migration terminée, le système côté réception appelle la fonction DxgkDdiRestoreMutableMigrationData du pilote avec le package final d'état à restaurer. Ce package doit fournir tout le contenu à transférer qui avait été laissé au pilote pour la restauration de son état et de son suivi, et pour la restauration restante de l'état de la VF.
Ce DDI ne doit être appelé que pour les VF actuellement mises en pause.
Après cet appel, le système appelle la fonction DxgkDdiEndLiveMigration du KMD pour informer le côté cible de supprimer tout état autour de la migration dynamique, y compris la restauration de la planification VF normale.
Communications avec l'UMED
L'interface UMED (User-Mode Emulation DLL) est étendue avec l'interface IGPUPMigration pour exposer la possibilité d'enregistrer et de valider du contenu pendant une migration dynamique.
HRESULT SaveImmutableGpup(
[in] PLUID DeviceLuid,
[in,out] UINT64 * Length,
[in,out] BYTE * SaveBuffer
);
HRESULT RestoreImmutableGpup(
[in] PLUID DeviceLuid,
[in] UINT64 Length,
[in] BYTE * RestoreBuffer
);
Pendant les actions de préparation de la migration dynamique où le KMD est appelé de la même façon, l'UMED a la possibilité d'envoyer des informations qui peuvent être utiles pour préparer celle-ci à la migration ou confirmer que l'environnement prend en charge la migration au niveau de l'UMED. Il s'agit d'une interface facultative pour les UMED avec les contrats d'interface standard pour l'UMED (threading et contexte de processus, exposition limitée du système d'exploitation, etc.). Son modèle d'appel imite les DDI du KMD, avec l'enregistrement en deux phases. Il n'existe aucun indicateur d'état dans ces appels, à l'instar d'autres interfaces UMED d'enregistrement/restauration, car ceux-ci doivent être valides et constants tout au long de la durée de vie de l'appareil et de son LUID.
L'état modifiable de l'UMED est transféré dans l'interface d'enregistrement/restauration existante. Auparavant, cette interface était bloquée vis-à-vis de l'exécution avec des pilotes GPU-P, mais elle est débloquée lorsque les rapports du KMD prennent en charge LiveMigration. Cette liaison entre la fonction légende UMED et la capacité du KMD est intentionnelle. La migration dynamique est la façon pour le système d'implémenter une migration rapide pour la virtualisation de ces appareils. La séquence des tâches est la même, et vous pouvez concevoir la migration rapide (Enregistrer/Restaurer) comme un cas spécial de migration dynamique dans lequel il n'y a pas de transfert actif. Une UMED prenant en charge l'enregistrement/la restauration doit toujours avoir un KMD qui prend en charge les DDI de migration dynamique. De même, l'UMED doit avoir connaissance de l'interface IGPUPMigration et évaluer si celle-ci est nécessaire dans sa conception avant que le KMD ne puisse migrer de façon dynamique.
Virtualisation des interruptions
L'adressage physique de la gestion des interruptions de l'invité doit être virtualisé afin de traiter correctement l'accès à la table MSI-X lorsque le matériel sous-jacent change pendant la migration. L'UMED doit intercepter la table des interruptions MSI-X pour tous les pilotes qui prennent en charge la migration dynamique. Toutes les lectures ou écritures dans les champs Message Upper Address et et Message Address doivent être mappées aux valeurs réelles du matériel. Dxgkrnl maintient le mappage de l'adresse virtualisée (ou de l'invité) et effectue la substitution si nécessaire dans la pile des appels.
Le système d'exploitation gère la virtualisation/le mappage des adresses physiques de l'invité auxquelles les lectures ou les écritures de la table peuvent faire référence côté invité avec les adresses physiques de l'hôte nécessaires au traitement réel des interruptions. Ce processus commun ne requiert pas l'implantation séparée de l'UMED ou le transfert du noyau, et le système d'exploitation n'informe pas l'UMED lorsqu'il intercepte la table. La seule condition requise pour l'UMED est que les atténuations concernant l'appareil soient définies pour les pages BAR de la table.
Toutefois, dans le noyau, Dxgkrnl souhaite que le KMD traite les écritures réelles. Pour ce faire, le KMD implémente la fonction de rappel DxgkDdiWriteVirtualizedInterrupt ajoutée.
Il ne doit jamais y avoir besoin d'une lecture, car l'UMD effectue le suivi local des écritures (sous forme virtualisée/traduite par l'invité) afin qu'elles ne nécessitent pas le transfert mémoire du noyau, qui est coûteux. Ce suivi migre avec l'appareil virtuel.
Contextes de synchronisation et IRQL des DDI
| DDI | Niveau de synchronisation | IRQL |
|---|---|---|
| DxgkDdiPrepareLiveMigration | 0 | PASSIVE |
| DxgkDdiEndLiveMigration | 0 | PASSIVE |
| DxgkDdiSaveImmutableMigrationData | 0 | PASSIVE |
| DxgkDdiSaveMutableMigrationData | 0 | PASSIVE |
| DxgkDdiRestoreImmutableMigrationData | 0 | PASSIVE |
| DxgkDdiRestoreMutableMigrationData | 0 | PASSIVE |
| DxgkDdiWriteVirtualizedInterrupt | 0 | PASSIVE |
| DxgkDdiSetVirtualGpuResources2 | 0 | PASSIVE |
| DxgkDdiSetVirtualFunctionPauseState | 0 | PASSIVE |
| IGPUPMigration::SaveImmutableGpup | 0 | PASSIVE |
| IGPUPMigration::RestoreImmutableGpup | 0 | PASSIVE |
Considérations importantes relatives à la planification VF
L'efficacité du transfert est largement déterminée par la planification des transferts de pagination sur la PF. Plus l'accès aux moteurs de pagination de l'appareil que la PF peut utiliser pour saturer le bus et obtenir le meilleur débit, plus le transfert en général est performant, et tout particulièrement le transfert mis en pause. Le mieux est de capturer et d'envoyer le plus de contenu possible dans un laps de temps donné ; du moins, jusqu'à la saturation du réseau.
Il est préférable que la modification de la planification affecte uniquement le moteur de pagination, et aucune autre ressource des appareils, mais toutes les conceptions de planification VF ne le permettent pas. Au minimum, il est souhaitable que la planification :
- ne prélève du budget que sur la VF en cours de migration ou sur la planification VF non attribuée.
- ne dégrade pas les performances des autres virtualisations sur la machine.
Il convient de souligner que, côté cible, ces conditions peuvent être beaucoup plus facilement remplies, car la VF est mise en pause pendant l'intégralité du transfert et que l'ensemble du budget est disponible. Côté source, il est nécessaire de compter sur un équilibrage des besoins de migration et des besoins de la machine virtuelle, dans le but ultime de respecter les objectifs de transfert en matière de pause.