Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit des recommandations pour la planification de la capacité pour les services de domaine Active Directory (AD DS).
Objectifs de la planification de capacité
La planification de la capacité n’est pas la même chose que le dépannage des incidents de performance. Les objectifs de la planification de capacité sont les suivants :
- Implémentez et exploitez correctement un environnement.
- Minimisez le temps passé à résoudre les problèmes de performance.
Dans la planification de la capacité, une organisation peut avoir un objectif de base de 40 % d’utilisation du processeur pendant les périodes de pointe pour répondre aux exigences de performance des clients et laisser suffisamment de temps pour mettre à niveau le matériel dans le centre de données. Pendant ce temps, ils fixent leur seuil d’alerte de surveillance pour les problèmes de performance à 90 % sur un intervalle de cinq minutes.
Lorsque vous dépassez continuellement le seuil de gestion de la capacité, ajouter davantage de processeurs ou des processeurs plus rapides pour augmenter la capacité ou répartir le service sur plusieurs serveurs pourrait être une solution. Les seuils d’alerte de performance vous informent lorsque vous devez agir immédiatement lorsque les problèmes de performance affectent négativement l’expérience client. En revanche, une solution de dépannage se concentrerait davantage sur la résolution d’événements ponctuels.
La gestion de la capacité est comme les mesures préventives que vous prendriez pour éviter un accident de voiture, telles que la conduite défensive, s’assurer que les freins fonctionnent correctement, et ainsi de suite. Le dépannage de la performance ressemble davantage à l’intervention de la police, des pompiers et des professionnels de l’urgence lors d’un accident.
Au cours des dernières années, les conseils en matière de planification de capacité pour les systèmes de scale-up ont considérablement changé. Les changements suivants dans les architectures système remettent en question les hypothèses fondamentales concernant la conception et l’échelle d’un service :
- Plateformes de serveur 64 bits
- Virtualisation
- Attention accrue à la consommation d’énergie
- Stockage SSD
- Scénarios cloud
L’approche de la planification de la capacité passe également des exercices de planification basés sur le serveur à ceux basés sur le service. Les services de domaine Active Directory (AD DS), un service distribué mature utilisé par de nombreux produits Microsoft et tiers en tant que backend, est désormais l’un des produits les plus critiques pour garantir que vos autres applications disposent de la capacité nécessaire pour fonctionner.
Informations importantes à considérer avant de commencer la planification
Pour tirer le meilleur parti de cet article, vous devez faire les choses suivantes :
- Assurez-vous d’avoir lu et compris les Directives de réglage des performances pour Windows Server 2012 R2.
- Comprenez que la plate-forme Windows Server est une architecture basée sur x64. De plus, vous devez comprendre que les directives de cet article s’appliquent toujours même si votre environnement Active Directory est installé sur Windows Server 2003 x86 (désormais au-delà de la fin du cycle de support) et dispose d’un arbre d’informations de répertoire (DIT) de moins de 1,5 Go et peut facilement être stocké en mémoire.
- Comprenez que la planification de la capacité est un processus continu, vous devez donc régulièrement examiner dans quelle mesure l’environnement que vous avez construit répond à vos attentes.
- Comprenez que l’optimisation se produit sur plusieurs cycles de vie du matériel à mesure que les coûts du matériel évoluent. Par exemple, si la mémoire devient moins chère, le coût par cœur diminue, ou si le prix des différentes options de stockage change.
- Planifiez la période de pointe de chaque jour. Nous vous recommandons de faire vos plans sur la base d’intervalles de 30 minutes ou d’une heure. Des intervalles supérieurs à une heure peuvent masquer le moment où votre service atteint réellement sa capacité maximale, et des intervalles inférieurs à 30 minutes peuvent vous fournir des informations inexactes qui rendent les augmentations transitoires plus importantes qu’elles ne le sont réellement.
- Planifiez la croissance tout au long du cycle de vie du matériel pour l’entreprise. Cette planification peut inclure des stratégies de mise à niveau ou d’ajout de matériel de manière échelonnée, ou un renouvellement complet tous les trois à cinq ans. Chaque plan de croissance nécessite d’estimer dans quelle mesure la charge sur Active Directory augmentera. Les données historiques peuvent vous aider à faire une évaluation plus précise.
- Planifiez la tolérance de panne. Une fois que vous avez dérivé l’estimation N, planifiez des scénarios qui incluent N - 1, N - 2, et N - x.
En fonction de votre plan de croissance, ajoutez des serveurs supplémentaires en fonction des besoins de l’organisation pour vous assurer que la perte d’un ou plusieurs serveurs ne provoque pas le dépassement des estimations de capacité maximale de pointe du système.
N’oubliez pas non plus que vous devez intégrer vos plans de croissance et de tolérance aux pannes. Par exemple, si vous savez que votre déploiement nécessite actuellement un contrôleur de domaine (DC) pour supporter la charge, mais que votre estimation indique que la charge doublera l’année prochaine et nécessitera deux DCs, alors votre système n’a pas suffisamment de capacité pour supporter la tolérance aux pannes. Pour éviter ce manque de capacité, vous devriez plutôt prévoir de commencer avec trois DCs. Si votre budget ne permet pas trois DCs, vous pouvez également commencer avec deux DCs, puis planifier d’ajouter un troisième après trois ou six mois.
Remarque
L’ajout d’applications prenant en charge Active Directory peut avoir un impact notable sur la charge du contrôleur de domaine, que la charge provienne des serveurs d’applications ou des clients.
Le cycle de planification de la capacité en trois parties
Avant de commencer votre cycle de planification, vous devez décider de la qualité de service dont votre organisation a besoin. Toutes les recommandations et directives de cet article concernent les environnements de performance optimale. Cependant, vous pouvez les relâcher sélectivement dans les cas où vous n’avez pas besoin d’optimisation. Par exemple, si votre organisation a besoin d’un niveau plus élevé de simultanéité et d’une expérience utilisateur plus cohérente, vous devriez envisager de mettre en place un centre de données. Les centres de données vous permettent de prêter une plus grande attention à la redondance et de minimiser les goulots d’étranglement du système et de l’infrastructure. En revanche, si vous prévoyez un déploiement pour un bureau satellite avec seulement quelques utilisateurs, vous n’avez pas besoin de vous soucier autant de l’optimisation du matériel et de l’infrastructure, ce qui vous permet de choisir des options moins coûteuses.
Ensuite, vous devez décider si vous optez pour des machines virtuelles ou physiques. Du point de vue de la planification de la capacité, il n’y a pas de bonne ou de mauvaise réponse. Cependant, vous devez garder à l’esprit que chaque scénario vous donne un ensemble différent de variables avec lesquelles travailler.
Les scénarios de virtualisation vous donnent deux options :
- Mapping direct, où vous avez un seul invité par hôte.
- Scénarios d’hôte partagé, où vous avez plusieurs invités par hôte.
Vous pouvez traiter les scénarios de mapping direct de manière identique aux hôtes physiques. Si vous choisissez un scénario d’hôte partagé, cela introduit d’autres variables que vous devez prendre en compte dans les sections ultérieures. Les hôtes partagés se disputent également les ressources avec les services de domaine Active Directory (AD DS), ce qui peut affecter la performance du système et l’expérience utilisateur.
Maintenant que nous avons répondu à ces questions, examinons le cycle de planification de la capacité lui-même. Chaque cycle de planification de la capacité implique un processus en trois étapes :
- Mesurez l’environnement existant, déterminez où se trouvent actuellement les goulots d’étranglement du système et obtenez les bases environnementales nécessaires pour planifier la quantité de capacité dont votre déploiement a besoin.
- Déterminez le matériel dont vous avez besoin en fonction de vos besoins en capacité.
- Surveillez et validez que l’infrastructure que vous avez mise en place fonctionne conformément aux spécifications. Les données que vous collectez à cette étape deviennent la référence pour le prochain cycle de planification de la capacité.
Application du processus
Pour optimiser la performance, assurez-vous que les composants majeurs suivants sont correctement sélectionnés et ajustés aux charges d’application :
- Mémoire
- Réseau
- Stockage
- Processeur
- Netlogon
Les exigences de stockage de base pour AD DS et le comportement général des logiciels clients compatibles permettent aux environnements avec jusqu’à 10 000 à 20 000 utilisateurs d’ignorer la planification de la capacité pour le matériel physique, car la plupart des systèmes de classe serveur modernes peuvent déjà supporter une charge de cette taille. Cependant, les tableaux dans Tableaux récapitulatifs de la collecte des données expliquent comment évaluer votre environnement existant pour sélectionner le bon matériel. Les sections qui suivent celle-ci entrent plus en détail sur les recommandations de base et les principes spécifiques à l’environnement pour le matériel afin d’aider les administrateurs AD DS à évaluer leur infrastructure.
Autres informations à garder à l’esprit lors de la planification :
- Toute taille basée sur les données actuelles est uniquement précise pour l’environnement actuel.
- Lors de la réalisation d’estimations, attendez-vous à ce que la demande augmente au cours du cycle de vie du matériel.
- Accommodez la croissance future en déterminant s’il faut surdimensionner votre environnement aujourd’hui ou ajouter progressivement de la capacité au cours du cycle de vie.
- Tous les principes et méthodologies de planification de la capacité que vous appliqueriez à un déploiement physique s’appliquent également à un déploiement virtualisé. Cependant, lors de la planification d’un environnement virtualisé, vous devez vous rappeler d’ajouter la surcharge de virtualisation à toute planification ou estimation liée au domaine.
- La planification de la capacité est une prédiction, pas une valeur parfaitement correcte, alors ne vous attendez pas à ce qu’elle soit parfaitement précise. N’oubliez jamais d’ajuster la capacité selon les besoins et de valider constamment que votre environnement fonctionne comme prévu.
Tables récapitulatives de la collecte de données
Les tableaux suivants listent et expliquent les critères pour déterminer vos estimations matérielles.
Environnement de travail
| Composant | Estimations |
|---|---|
| Taille de la base de données/du stockage | 40 Ko à 60 Ko pour chaque utilisateur |
| Mémoire vive (RAM) | Taille de la base de données Recommandations de système d’exploitation de base Applications tierces |
| Réseau | 1 Go |
| UC | 1 000 utilisateurs simultanés pour chaque cœur |
Critères d’évaluation généraux
| Composant | Critères d’évaluation | Considérations relatives à la planification |
|---|---|---|
| Taille de la base de données/du stockage | Défragmentation hors connexion | |
| Performance du stockage/base de données |
|
|
| Mémoire vive (RAM) |
|
|
| Réseau |
|
|
| UC |
|
|
| Accès réseau (Netlogon) |
|
|
Planification
Pendant longtemps, la recommandation habituelle pour la dimensionnement de AD DS était de mettre autant de RAM que la taille de la base de données. Maintenant que les environnements AD DS et l’écosystème qui les consomme sont devenus beaucoup plus grands, les choses ont changé. Bien que l’augmentation de la puissance de calcul et le passage de l’architecture x86 à x64 aient rendu les aspects plus subtils du dimensionnement pour la performance sans importance pour les clients exécutant AD DS sur des machines physiques, la virtualisation a rendu les ajustements beaucoup plus préoccupants.
Pour répondre à ces préoccupations, les sections suivantes décrivent comment déterminer et planifier les besoins d’Active Directory en tant que service. Vous pouvez appliquer ces directives à n’importe quel environnement, que votre environnement soit physique, virtualisé ou mixte. Pour maximiser vos performances, votre objectif doit être d’amener votre environnement AD DS aussi près que possible de la limite du processeur.
Mémoire vive (RAM)
Plus vous pouvez mettre de stockage en cache dans la RAM, moins il sera nécessaire d’accéder au disque. Pour maximiser l’évolutivité du serveur, la quantité minimale de RAM que vous utilisez doit être égale à la somme de la taille actuelle de la base de données, de la taille totale de la valeur système, de la quantité recommandée pour votre système d’exploitation et des recommandations du fournisseur pour les agents (programmes antivirus, surveillance, sauvegarde, etc.). Vous devez également inclure de la RAM supplémentaire pour prévoir la croissance future pendant la durée de vie du serveur. Cette estimation changera en fonction de la croissance de la base de données et des changements environnementaux.
Pour les environnements où maximiser la RAM n’est pas rentable ou réalisable, tels que les sites satellites ou lorsque l’arborescence des informations d’annuaire (DIT) est trop grande, passez directement à Stockage pour vous assurer que votre stockage est correctement configuré.
Un autre point important à considérer pour la dimensionnement de la mémoire est la dimensionnement du fichier d’échange. En dimensionnement de disque, comme pour tout ce qui concerne la mémoire, l’objectif est de minimiser l’utilisation du disque. En particulier, combien de RAM faut-il pour minimiser le pagination? Les sections suivantes devraient vous fournir les informations nécessaires pour répondre à cette question. D’autres considérations pour la taille du fichier d’échange qui n’affectent pas nécessairement les performances de AD DS sont les recommandations du système d’exploitation (OS) et la configuration de votre système pour les vidages de mémoire.
Déterminer la quantité de RAM dont un contrôleur de domaine (DC) a besoin peut être difficile en raison de nombreux facteurs complexes :
- Les systèmes existants ne sont pas toujours des indicateurs fiables des besoins en RAM car le service Local Security Authority Subsystem Service (LSSAS) réduit la RAM sous pression mémoire, diminuant artificiellement les besoins.
- Les DC individuels n’ont besoin de mettre en cache que les données qui intéressent leurs clients. Cela signifie que les données mises en cache dans différents environnements changeront en fonction des types de clients qu’ils contiennent. Par exemple, un DC dans un environnement avec un serveur Exchange collectera des données différentes d’un DC qui n’authentifie que des utilisateurs.
- La quantité d’effort nécessaire pour évaluer la RAM pour chaque DC au cas par cas est souvent excessive et change au fur et à mesure que l’environnement évolue.
Les critères derrière les recommandations peuvent vous aider à prendre des décisions plus éclairées :
- Plus vous mettez en cache dans la RAM, moins vous devez accéder au disque.
- Le stockage est le composant le plus lent d’un ordinateur. L’accès aux données sur des supports de stockage à base de disques et SSD est un million de fois plus lent que l’accès aux données dans la RAM.
Éléments à prendre en compte en matière de virtualisation pour la RAM
Votre objectif pour l’optimisation de la RAM est de minimiser le temps passé à accéder au disque. Vous devez également éviter la sur-allocation de mémoire sur l’hôte. Dans les scénarios de virtualisation, la sur-allocation de mémoire se produit lorsque le système alloue plus de RAM aux invités que ce qui existe réellement sur la machine physique. Bien que la sur-allocation ne soit pas un problème en soi, lorsque la mémoire totale utilisée par tous les invités dépasse la capacité de la RAM de l’hôte, cela provoque la pagination de l’hôte. La pagination rend la performance dépendante du disque dans les cas où le DC accède à NTDS.nit ou au fichier d’échange pour obtenir des données, ou lorsque l’hôte accède au disque pour essayer d’accéder aux données en RAM. En conséquence, ce processus réduit considérablement les performances et l’expérience utilisateur globale.
Exemple de résumé de calcul
| Composant | Mémoire estimée (exemple) |
|---|---|
| RAM recommandée pour le système d’exploitation de base (Windows Server 2008) | 2 Go |
| Tâches internes LSASS | 200 Mo |
| Agent de monitoring | 100 Mo |
| Logiciel antivirus | 100 Mo |
| Base de données (catalogue global) | 8,5 Go |
| Tampon pour que la sauvegarde s’exécute, les administrateurs se connectent sans impact | 1 Go |
| Somme | 12 Go |
Recommandé : 16 Go
Au fil du temps, plus de données sont ajoutées à la base de données, et la durée de vie moyenne d’un serveur est d’environ trois à cinq ans. Sur la base d’une estimation de croissance de 333%, 16 Go est une quantité raisonnable de RAM à installer dans un serveur physique.
Réseau
Cette section concerne l’évaluation de la quantité totale de bande passante et de capacité réseau dont votre déploiement a besoin, y compris les requêtes client, les paramètres de stratégie de groupe, etc. Vous pouvez collecter des données pour faire votre estimation en utilisant les Network Interface(*)\Bytes Received/sec et Network Interface(*)\Bytes Sent/sec compteurs de performance. Les intervalles d’échantillonnage pour les compteurs d’interface réseau doivent être de 15, 30 ou 60 minutes. Toute durée inférieure sera trop volatile pour obtenir de bonnes mesures, et toute durée supérieure lissera excessivement les pics quotidiens.
Remarque
En règle générale, la majorité du trafic réseau sur un contrôleur de domaine est sortant, car le contrôleur de domaine répond aux requêtes du client. En conséquence, cette section se concentre principalement sur le trafic sortant. Cependant, nous vous recommandons également d’évaluer chaque environnement pour le trafic entrant. Vous pouvez utiliser les directives de cet article pour évaluer également les besoins en trafic réseau entrant. Pour plus d’informations, veuillez consulter la section 929851 : La plage de ports dynamiques par défaut pour TCP/IP a changé dans Windows Vista et Windows Server 2008.
Besoins de bande passante
La planification de la scalabilité du réseau couvre deux catégories distinctes : la quantité de trafic et la charge processeur à partir du trafic réseau.
Il y a deux éléments à prendre en compte lors de la planification de la capacité pour le support du trafic. Tout d’abord, vous devez savoir combien de trafic de réplication Active Directory circule entre vos DC. Deuxièmement, vous devez évaluer le trafic client-serveur intra-site. Le trafic intra-site reçoit principalement de petites requêtes des clients par rapport aux grandes quantités de données qu’il renvoie aux clients. 100 Mo suffisent généralement pour les environnements avec jusqu’à 5 000 utilisateurs par serveur. Pour les environnements de plus de 5 000 utilisateurs, nous vous recommandons d’utiliser un adaptateur réseau de 1 Go et la prise en charge de Receive Side Scaling (RSS).
Pour évaluer la capacité de trafic intra-site, en particulier dans les scénarios de consolidation de serveurs, vous devez examiner le compteur de performance Network Interface(*)\Bytes/sec sur tous les DC d’un site, les additionner, puis diviser la somme par le nombre cible de DC. Une façon simple de calculer ce nombre est d’ouvrir le moniteur de fiabilité et de performance Windows et de regarder l’affichage en aires empilées. Assurez-vous que tous les compteurs sont à la même échelle.
Voyons un exemple d’une méthode plus complexe pour valider que cette règle générale s’applique à un environnement spécifique. Dans cet exemple, nous faisons les hypothèses suivantes :
- L’objectif est de réduire l’empreinte au nombre le plus petit possible de serveurs. Idéalement, un serveur supporte la charge, puis vous déployez un serveur supplémentaire pour la redondance (scénario n + 1).
- Dans ce scénario, l’adaptateur réseau actuel ne prend en charge que 100 Mo et se trouve dans un environnement commuté.
- L’utilisation maximale cible de la bande passante réseau est de 60% dans un scénario n (perte d’un DC).
- Chaque serveur a environ 10 000 clients connectés.
Maintenant, examinons ce que le graphique dans le compteur Network Interface(*)\Bytes Sent/sec dit de cet exemple de scénario :
- La journée de travail commence à s’intensifier vers 5h30 et se termine à 19h00.
- La période la plus occupée se situe entre 8h00 et 8h15, avec plus de 25 octets envoyés par seconde sur le DC le plus occupé.
Remarque
Toutes les données de performance sont historiques, donc le point de données de pointe à 8h15 indique la charge de 8h00 à 8h15.
- Il y a des pics avant 4h00, avec plus de 20 octets envoyés par seconde sur le DC le plus occupé, ce qui pourrait indiquer soit une charge provenant de différents fuseaux horaires, soit une activité d’infrastructure en arrière-plan, telle que des sauvegardes. Étant donné que le pic de 8h00 dépasse cette activité, il n’est pas pertinent.
- Il y a cinq DC dans le site.
- La charge maximale est d’environ 5,5 Mo/s par DC, ce qui représente 44% de la connexion 100 Mo. Les compteurs d’envoi/réception d’interface réseau sont en octets, mais la bande passante réseau est mesurée en bits.
Remarque
Par conséquent, pour calculer la bande passante totale, il faudrait faire 100 Mo ÷ 8 = 12,5 Mo et 1 Go ÷ 8 = 128 Mo. Par conséquent, pour calculer la bande passante totale, il faudrait faire 100 Mo ÷ 8 = 12,5 Mo et 1 Go ÷ 8 = 128 Mo.
Maintenant que nous avons examiné les données, quelles conclusions pouvons-nous en tirer ?
- L’environnement actuel respecte le niveau de tolérance aux pannes n + 1 avec une utilisation cible de 60%. La mise hors ligne d’un système déplacera la bande passante par serveur d’environ 5,5 Mo/s (44%) à environ 7 Mo/s (56%).
- Sur la base de l’objectif précédemment énoncé de consolidation en un seul serveur, ce changement dépasse l’utilisation cible maximale et l’utilisation possible d’une connexion 100 Mo.
- Avec une connexion 1 Go, cette valeur représente 22% de la capacité totale.
- Dans des conditions de fonctionnement normales dans le scénario n + 1, la charge client est relativement bien répartie à environ 14 Mo/s par serveur ou 11% de la capacité totale.
- Pour vous assurer d’avoir suffisamment de capacité lorsqu’un DC est indisponible, les cibles d’exploitation normales par serveur seraient d’environ 30% d’utilisation du réseau ou 38 Mo/s par serveur. Les cibles de basculement seraient de 60% d’utilisation du réseau ou 72 Mo/s par serveur.
Le déploiement final du système doit avoir un adaptateur réseau de 1 Go et une connexion à une infrastructure réseau qui supportera cette charge. En raison de la quantité de trafic réseau, la charge du processeur due aux communications réseau peut potentiellement limiter l’évolutivité maximale de AD DS. Vous pouvez utiliser ce même processus pour estimer les communications entrantes vers le DC. Cependant, dans la plupart des scénarios, vous n’aurez pas besoin de calculer le trafic entrant car il est plus petit que le trafic sortant.
Il est important de s’assurer que votre matériel prend en charge le RSS dans les environnements avec plus de 5 000 utilisateurs par serveur. Pour les scénarios à trafic réseau élevé, l’équilibrage de la charge d’interruption peut constituer un goulot d’étranglement. Vous pouvez détecter les goulots d’étranglement potentiels en vérifiant le compteur Processor(*)\% Interrupt Time pour voir si le temps d’interruption est réparti de manière inégale entre les processeurs. Les contrôleurs d’interface réseau (NIC) compatibles RSS peuvent atténuer ces limitations et augmenter l’évolutivité.
Remarque
Vous pouvez adopter une approche similaire pour estimer si vous avez besoin de plus de capacité lors de la consolidation de centres de données ou de la mise hors service d’un DC dans un site satellite. Pour estimer la capacité requise, examinez simplement les données relatives au trafic sortant et entrant vers les clients. Le résultat est la quantité de trafic présent dans les liaisons WAN (réseau étendu).
Dans certains cas, vous risquez de rencontrer plus de trafic que prévu, car le trafic est plus lent, notamment quand la vérification des certificats ne parvient pas à respecter des délais d’expiration agressifs sur le WAN. C’est pourquoi le dimensionnement et l’utilisation du WAN doivent être un processus itératif et continu.
Éléments à prendre en compte en matière de virtualisation pour la bande passante réseau
Les recommandations typiques pour un serveur physique sont de 1 Go pour les serveurs prenant en charge plus de 5 000 utilisateurs. Une fois que plusieurs invités commencent à partager une infrastructure de commutateur virtuel sous-jacente, vous devez prêter une attention particulière à la question de savoir si l’hôte dispose d’une bande passante réseau adéquate pour prendre en charge tous les invités du système. Vous devez prendre en compte la bande passante, que le réseau inclue le DC fonctionnant en tant que VM sur un hôte avec du trafic réseau passant par un commutateur virtuel ou directement connecté à un commutateur physique. Les commutateurs virtuels sont des composants où la liaison montante doit prendre en charge la quantité de données que la connexion transmet, ce qui signifie que l’adaptateur réseau physique de l’hôte lié au commutateur doit pouvoir prendre en charge la charge du DC plus tous les autres invités partageant le commutateur virtuel connecté à l’adaptateur réseau physique.
Exemple de résumé du calcul du réseau
Le tableau suivant contient des valeurs provenant d’un scénario exemple que nous pouvons utiliser pour calculer la capacité réseau :
| Système | Bande passante maximale |
|---|---|
| Contrôleur de domaine 1 | 6.5 Mbits/s |
| Contrôleur de domaine 2 | 6.25 Mbits/s |
| Contrôleur de domaine 3 | 6.25 Mbits/s |
| Contrôleur de domaine 4 | 5.75 Mbits/s |
| Contrôleur de domaine 5 | 4.75 Mbits/s |
| Somme | 28.5 Mbits/s |
Sur la base de ce tableau, la bande passante recommandée serait de 72 Mbits/s (28,5 Mbits/s ÷ 40 %).
| Nombre cible de systèmes | Bande passante totale (comme ci-dessus) |
|---|---|
| 2 | 28.5 Mbits/s |
| Comportement normal obtenu | 28,5 ÷ 2 = 14,25 Mbits/s |
Comme toujours, vous devez supposer que la charge client augmentera avec le temps, alors vous devez planifier cette croissance le plus tôt possible. Nous vous recommandons de prévoir une augmentation d’au moins 50 % du trafic réseau estimé.
Stockage
Il y a deux choses que vous devez considérer lors de la planification de la capacité de stockage :
- Capacité ou taille de stockage
- Performances
Bien que la capacité soit importante, il est essentiel de ne pas négliger les performances. Avec les coûts matériels actuels, la plupart des environnements ne sont pas suffisamment grands pour que l’un ou l’autre facteur soit une préoccupation majeure. Par conséquent, la recommandation habituelle est simplement d’ajouter autant de RAM que la taille de la base de données. Cependant, cette recommandation pourrait être excessive pour les sites satellites dans des environnements plus vastes.
Dimensionnement
Évaluation du stockage
Comparé à l’époque où Active Directory est apparu, alors que les disques de 4 Go et 9 Go étaient les tailles de disques les plus courantes, la dimensionnement pour Active Directory n’est même plus une considération, sauf pour les plus grands environnements. Avec les plus petites tailles de disque dur disponibles dans la gamme des 180 Go, l’ensemble du système d’exploitation, SYSVOL et NTDS.dit peuvent facilement tenir sur un seul lecteur. En conséquence, nous vous recommandons d’éviter d’investir trop lourdement dans ce domaine.
Notre seule recommandation est de vous assurer que 110 % de la taille du NTDS.dit est disponible pour que vous puissiez défragmenter votre stockage. Au-delà de cela, vous devriez prendre les considérations habituelles pour anticiper la croissance future.
Si vous allez évaluer votre stockage, vous devez d’abord évaluer la taille nécessaire du NTDS.dit et du SYSVOL. Ces mesures vous aideront à dimensionner à la fois le disque fixe et les allocations de RAM. Étant donné que les composants sont relativement peu coûteux, vous n’avez pas besoin d’être très précis dans vos calculs. Pour plus d’informations sur l’évaluation du stockage, veuillez consulter la section Limites de stockage et Estimations de croissance pour les utilisateurs et unités d’organisation d’Active Directory.
Remarque
Les articles liés dans le paragraphe précédent sont basés sur des estimations de taille de données faites lors de la sortie d’Active Directory sous Windows 2000. Lors de votre propre estimation, utilisez des tailles d’objets qui reflètent la taille réelle des objets dans votre environnement.
Lorsque vous examinez des environnements existants avec plusieurs domaines, vous pouvez remarquer des variations dans les tailles de base de données. Lorsque vous repérez ces variations, utilisez les plus petites tailles de catalogue global (GC) et non-GC.
Les tailles de base de données peuvent varier entre les versions du système d’exploitation. Les DC exécutant des versions antérieures du système d’exploitation, comme Windows Server 2003, ont des tailles de base de données plus petites que celles exécutant une version plus récente comme Windows Server 2008 R2. Le DC disposant de fonctionnalités telles que la corbeille Active Directory ou l’itinérance des informations d’identification activée peut également affecter la taille de la base de données.
Remarque
- Pour les nouveaux environnements, rappelez-vous que 100 000 utilisateurs dans le même domaine consomment environ 450 Mo d’espace. Les attributs que vous remplissez peuvent avoir un impact énorme sur la quantité totale d’espace consommé. Les attributs sont remplis par de nombreux objets provenant de produits tiers et de produits Microsoft, y compris Microsoft Exchange Server et Lync. En conséquence, nous vous recommandons d’évaluer en fonction du portefeuille de produits de l’environnement. Cependant, vous devez également garder à l’esprit que faire des calculs et des tests pour obtenir des estimations précises, sauf pour les plus grands environnements, peut ne pas valoir un temps ou un effort considérable.
- Assurez-vous que l’espace libre dont vous disposez est de 110 % de la taille du NTDS.dit pour permettre une défragmentation hors ligne. Cet espace libre vous permet également de planifier la croissance sur la durée de vie matérielle de trois à cinq ans du serveur. Si vous disposez du stockage nécessaire, allouer suffisamment d’espace libre pour correspondre à 300 % du DIT pour le stockage est un moyen sûr de s’adapter à la croissance et à la défragmentation.
Éléments à prendre en compte en matière de virtualisation pour le stockage
Dans les scénarios où vous allouez plusieurs fichiers de disque dur virtuel (VHD) à un seul volume, vous devez utiliser un disque d’état fixe d’au moins 210 % de la taille du DIT (100 % du DIT + 110 % d’espace libre) pour garantir que vous disposez de suffisamment d’espace réservé pour vos besoins.
Exemple de résumé du calcul de stockage
Le tableau suivant répertorie les valeurs que vous utiliseriez pour estimer les besoins en espace pour un scénario de stockage hypothétique.
| Données collectées à partir de la phase d’évaluation | Taille |
|---|---|
| Taille de NTDS.dit | 35 Go |
| Modificateur pour autoriser la défragmentation hors connexion | 2,1 Go |
| Stockage total nécessaire | 73,5 Go |
Remarque
L’estimation du stockage devrait également inclure la quantité de stockage nécessaire pour SYSVOL, le système d’exploitation, le fichier d’échange, les fichiers temporaires, les données mises en cache localement telles que les fichiers d’installation et les applications.
Performances de stockage
En tant que composant le plus lent dans un ordinateur, le stockage peut avoir l’impact négatif le plus grand sur l’expérience client. Pour les environnements suffisamment grands pour que les recommandations de dimensionnement de la RAM dans cet article ne soient pas réalisables, les conséquences de négliger la planification de la capacité de stockage peuvent être dévastatrices pour les performances du système. Les complexités et les variétés de la technologie de stockage disponible augmentent encore le risque, car la recommandation typique de placer le système d’exploitation, les journaux et la base de données sur des disques physiques séparés ne s’applique pas universellement à tous les scénarios.
Les anciennes recommandations concernant les disques supposaient qu’un disque était une broche dédiée permettant une E/S isolée. Cette supposition n’est plus vraie en raison de l’introduction des types de stockage suivants :
- RAID
- Nouveaux types de stockage et scénarios de stockage virtualisé et partagé
- Broches partagées sur un réseau de zone de stockage (SAN)
- Fichier VHD sur un SAN ou un stockage attaché au réseau
- SSDs (Solid State Drive)
- Architectures de stockage hiérarchisé, telles que la mise en cache de stockage SSD sur un stockage plus grand basé sur des broches
Stockage partagé, tel que RAID, SAN, NAS, JBOD, Storage Spaces et VHD, qui peuvent être surchargés par d’autres charges de travail que vous placez sur le stockage back-end. Ces types de stockage présentent également un défi supplémentaire : des problèmes de SAN, de réseau ou de pilote entre le disque physique et l’application AD peuvent entraîner des ralentissements et des délais. Pour être clair, ces configurations ne sont pas mauvaises, mais elles sont plus complexes, ce qui signifie que vous devez porter une attention particulière pour vous assurer que chaque composant fonctionne comme prévu. Pour des explications plus détaillées, consultez la section Annexe C et Annexe D plus loin dans cet article. De plus, bien que les SSD ne soient pas limités par les disques durs qui ne peuvent traiter qu’une E/S à la fois, ils ont toujours des limitations d’E/S qui peuvent être surchargées.
En résumé, l’objectif de toute planification de performance de stockage, quelle que soit l’architecture de stockage, est de garantir que le nombre nécessaire d’I/O est toujours disponible et qu’il se produit dans un délai acceptable. Pour les scénarios avec stockage localement attaché, consultez la section Annexe C pour plus d’informations sur la conception et la planification. Vous pouvez appliquer les principes de l’annexe à des scénarios de stockage plus complexes, ainsi qu’à des conversations avec les fournisseurs soutenant vos solutions de stockage back-end.
En raison du nombre d’options de stockage disponibles aujourd’hui, nous vous recommandons de consulter vos équipes de support matériel ou vos fournisseurs lors de la planification pour vous assurer que la solution répond aux besoins de votre déploiement AD DS. Lors de ces conversations, vous pourriez trouver les compteurs de performance suivants utiles, en particulier lorsque votre base de données est trop grande pour votre RAM :
-
LogicalDisk(*)\Avg Disk sec/Read(par exemple, si NTDS.dit est stocké sur le lecteur D, le chemin complet seraitLogicalDisk(D:)\Avg Disk sec/Read) LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
Lorsque vous fournissez les données, vous devez vous assurer qu’elles sont échantillonnées à des intervalles de 15, 30 ou 60 minutes pour donner l’image la plus précise possible de votre environnement actuel.
Évaluation des résultats
Cette section se concentre sur les lectures à partir de la base de données, car la base de données est généralement le composant le plus exigeant. Vous pouvez appliquer la même logique aux écritures dans le fichier journal en substituant <NTDS Log>)\Avg Disk sec/Write et LogicalDisk(<NTDS Log>)\Writes/sec).
Le compteur LogicalDisk(<NTDS>)\Avg Disk sec/Read montre si le stockage actuel est correctement dimensionné. Si la valeur est approximativement égale au temps d’accès disque attendu pour le type de disque, le compteur LogicalDisk(<NTDS>)\Reads/sec est une mesure valide. Si les résultats sont à peu près égaux au temps d’accès disque pour le type de disque, le compteur LogicalDisk(<NTDS>)\Reads/sec est une mesure valide. Bien que cela puisse changer en fonction des spécifications du fabricant de votre stockage back-end, les bonnes plages pour LogicalDisk(<NTDS>)\Avg Disk sec/Read seraient à peu près :
- 7200 tr/min : 9 à 12,5 millisecondes (ms)
- 10 000 tr/min : 6 à 10 ms
- 15 000 tr/min : 4 à 6 ms
- SSD – de 1 à 3 ms
Vous pourriez entendre d’autres sources dire que les performances de stockage sont dégradées à 15 ms à 20 ms. La différence entre ces valeurs et les valeurs de la liste précédente est que les valeurs de la liste montrent la plage de fonctionnement normale. Les autres valeurs sont destinées au dépannage, ce qui vous aide à identifier quand l’expérience client s’est suffisamment dégradée pour devenir perceptible. Pour plus d’informations, consultez la section Annexe C.
-
LogicalDisk(<NTDS>)\Reads/secest la quantité d’E/S que le système effectue actuellement.- Si
LogicalDisk(<NTDS>)\Avg Disk sec/Readse situe dans la plage optimale pour le stockage back-end, vous pouvez utiliser directementLogicalDisk(<NTDS>)\Reads/secpour dimensionner le stockage. - Si
LogicalDisk(<NTDS>)\Avg Disk sec/Readne se situe pas dans la plage optimale pour le stockage back-end, un E/S supplémentaire est nécessaire selon la formule suivante :LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ Temps d’accès au disque sur support physique ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Si
Lorsque vous effectuez ces calculs, voici quelques éléments à prendre en compte :
- Si le serveur a une quantité sous-optimale de RAM, les valeurs résultantes seront trop élevées et ne seront pas assez précises pour être utiles à la planification. Cependant, vous pouvez toujours les utiliser pour prédire les scénarios les plus défavorables.
- Si vous ajoutez ou optimisez la RAM, vous diminuez également la quantité de lecture d’E/S
LogicalDisk(<NTDS>)\Reads/Sec. Cette diminution peut faire en sorte que la solution de stockage ne soit pas aussi robuste que les calculs initiaux le supposaient. Malheureusement, nous ne pouvons pas donner plus de détails sur ce que cela signifie, car les calculs varient largement en fonction des environnements individuels, en particulier de la charge client. Cependant, nous vous recommandons d’ajuster le dimensionnement du stockage après avoir optimisé la RAM.
Éléments à prendre en compte en matière de virtualisation pour les performances
Comme pour les sections précédentes, notre objectif ici est de s’assurer que l’infrastructure partagée peut supporter la charge totale de tous les consommateurs. Vous devez garder cet objectif à l’esprit lors de la planification des scénarios suivants :
- Un CD physique partageant le même média sur une infrastructure SAN, NAS ou iSCSI que d’autres serveurs ou applications.
- Un utilisateur utilisant un accès pass-through à une infrastructure SAN, NAS ou iSCSI qui partage le média.
- Un utilisateur utilisant un fichier VHD sur un média partagé localement ou une infrastructure SAN, NAS ou iSCSI.
Du point de vue d’un utilisateur invité, devoir passer par un hôte pour accéder à tout stockage a un impact sur les performances, car l’utilisateur doit parcourir des chemins de code supplémentaires pour accéder. Les tests de performance indiquent que la virtualisation impacte le débit en fonction de la quantité de processeur utilisée par le système hôte. L’utilisation du processeur est également influencée par la quantité de ressources que l’utilisateur invité demande à l’hôte. Cette demande contribue aux Considérations de virtualisation pour le traitement que vous devriez prendre en compte pour les besoins de traitement dans les scénarios virtualisés. Pour plus d’informations, consultez la section Annexe A.
La situation se complique encore avec le nombre d’options de stockage actuellement disponibles, chacune ayant des impacts sur les performances très différents. Ces options incluent le stockage pass-through, les adaptateurs SCSI et IDE. Lors de la migration d’un environnement physique vers un environnement virtuel, vous devriez ajuster les différentes options de stockage pour les utilisateurs invités virtualisés en utilisant un multiplicateur de 1,10. Cependant, vous n’avez pas besoin de considérer des ajustements lors du transfert entre différents scénarios de stockage, car le fait que le stockage soit local, SAN, NAS ou iSCSI est plus important.
Exemple de calcul de virtualisation
Détermination de la quantité d’E/S nécessaires pour un système sain dans des conditions de fonctionnement normales :
- LogicalDisk(
<NTDS Database Drive>) ÷ Transferts par seconde pendant la période de pointe de 15 minutes - Pour déterminer la quantité d’E/S nécessaires pour le stockage quand la capacité du stockage sous-jacent est dépassée :
IOPS nécessaire = (LogicalDisk(
<NTDS Database Drive>)) ÷ Moyenne Disque Lecture/sec ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Lecture/sec
| Compteur | Valeur |
|---|---|
LogicalDisk réel(<NTDS Database Drive>)\Moyenne Disque sec/Transfert |
0,02 secondes (20 millisecondes) |
LogicalDisk cible(<NTDS Database Drive>)\Moyenne Disque sec/Transfert |
0,01 secondes |
| Multiplicateur pour changement d’E/S disponible | 0,02 ÷ 0,01 = 2 |
| Nom de la valeur | Valeur |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transferts/sec |
400 |
| Multiplicateur pour changement d’E/S disponible | 2 |
| Nombre total d’IOPS nécessaires pendant la période de pointe | 800 |
Pour déterminer le taux auquel vous devez réchauffer le cache :
- Déterminez le temps maximum que vous jugez acceptable de consacrer au réchauffement du cache. Dans les scénarios typiques, un délai acceptable correspondrait au temps nécessaire pour charger l’intégralité de la base de données à partir d’un disque. Dans les scénarios où la RAM ne peut pas charger l’intégralité de la base de données, utilisez le temps qu’il faudrait pour remplir toute la RAM.
- Déterminez la taille de la base de données, en excluant l’espace que vous ne prévoyez pas d’utiliser. Pour plus d’informations, consultez Évaluation du stockage.
- Divisez la taille de la base de données par 8 Ko pour obtenir le nombre total d’E/S nécessaires pour charger la base de données.
- Divisez le nombre total d’E/S par le nombre de secondes dans la période de temps définie.
Le nombre que vous calculez est principalement précis, mais peut ne pas être exact, car vous n’avez pas configuré (Extensible Storage Engine) ESE pour avoir une taille de cache fixe, alors AD DS éjectera les pages précédemment chargées car il utilise une taille de cache variable par défaut.
| Points de données à collecter | Valeurs |
|---|---|
| Délai maximal acceptable de réchauffement | 10 minutes (600 secondes) |
| Taille de la base de données | 2 Go |
| Étape de calcul | Formule | Résultat |
|---|---|---|
| Calculer la taille de la base de données en pages | (2 Go × 1024 × 1024) = Taille de la base de données en Ko | 2 097 152 Ko |
| Calculer le nombre de pages dans la base de données | 2 097 152 Ko ÷ 8 Ko = Nombre de pages | 262 144 pages |
| Calculer les IOPS nécessaires pour réchauffer entièrement le cache | 262 144 pages ÷ 600 secondes = IOPS nécessaires | 437 IOPS |
Traitement en cours
Évaluation de l’utilisation du processeur Active Directory
Dans la plupart des environnements, la gestion de la capacité de traitement est le composant qui mérite le plus d’attention. Lorsque vous évaluez la capacité CPU dont votre déploiement a besoin, vous devez prendre en compte les deux points suivants :
- Les applications de votre environnement se comportent-elles comme prévu au sein d’une infrastructure de services partagés en fonction des critères décrits dans Suivi des recherches coûteuses et inefficaces ? Dans les environnements plus vastes, des applications mal codées peuvent rendre la charge CPU volatile, consommer un temps CPU excessif au détriment d’autres applications, augmenter les besoins en capacité et répartir la charge de manière inégale sur les DC.
- AD DS est un environnement distribué avec de nombreux clients potentiels dont les besoins en traitement varient largement. Les coûts estimés pour chaque client peuvent varier en fonction des modèles d’utilisation et du nombre d’applications utilisant AD DS. Tout comme dans Réseaux, vous devriez aborder l’estimation comme une évaluation de la capacité totale nécessaire dans l’environnement au lieu de considérer chaque client individuellement.
Vous ne devriez faire cette estimation qu’après avoir complété votre estimation de stockage, car vous ne pourrez pas faire une estimation précise sans données valides sur votre charge processeur. Il est également important de s’assurer que les goulets d’étranglement ne sont pas causés par le stockage avant de résoudre les problèmes de processeur. À mesure que vous éliminez les états d’attente du processeur, l’utilisation du CPU augmente car il n’a plus besoin d’attendre les données. Par conséquent, les compteurs de performance auxquels vous devez prêter le plus d’attention sont Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read et Process(lsass)\ Processor Time. Si le compteur Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read dépasse 10 ou 15 millisecondes, alors les données dans Process(lsass)\ Processor Time sont artificiellement basses et le problème est lié aux performances du stockage. Nous vous recommandons de définir des intervalles d’échantillonnage à 15, 30 ou 60 minutes pour obtenir les données les plus précises possibles.
Aperçu du traitement
Pour prévoir la planification de capacité des contrôleurs de domaine, la puissance de traitement nécessite le plus d’attention et de compréhension. Lors du dimensionnement des systèmes pour assurer des performances maximales, il y a toujours un composant qui est le goulet d’étranglement, et dans un contrôleur de domaine correctement dimensionné, ce composant est le processeur.
Comme dans la section sur la mise en réseau dans laquelle la demande de l’environnement est examinée site par site, il s’agit de faire de même pour la capacité de calcul exigée. Contrairement à la section sur la mise en réseau, dans laquelle les technologies de mise en réseau disponibles dépassent de loin la demande normale, faites plus attention au dimensionnement de la capacité du processeur. Comme n’importe quel environnement, même de taille modérée, tout ce qui dépasse quelques milliers d’utilisateurs simultanés peut entraîner une charge importante sur le processeur.
Malheureusement, en raison de l’énorme variabilité des applications clientes qui exploitent AD, une estimation générale des utilisateurs par processeur est inapplicable à tous les environnements. Plus précisément, les exigences de calcul sont soumises au comportement utilisateur et au profil des applications. Par conséquent, chaque environnement a besoin d’être dimensionné individuellement.
Profil de comportement de site cible
Lorsque vous planifiez la capacité pour un site entier, votre objectif devrait être une conception de capacité N + 1. Dans cette conception, même si un système tombe en panne pendant la période de pointe, le service peut toujours se poursuivre à des niveaux de qualité acceptables. Dans un scénario N, la charge sur tous les systèmes devrait être inférieure à 80%-100% pendant les périodes de pointe.
De plus, les applications et les clients du site utilisent la méthode recommandée DsGetDcName function pour localiser les DC, ils devraient déjà être répartis de manière uniforme avec seulement de légers pics transitoires.
Nous allons maintenant examiner deux exemples d’environnements qui sont dans les cibles et hors cible. Tout d’abord, nous allons examiner un exemple d’environnement qui fonctionne comme prévu et ne dépasse pas l’objectif de planification de capacité.
Pour le premier exemple, nous faisons les hypothèses suivantes :
- Chacun des cinq DC du site dispose de quatre CPU.
- L’utilisation totale du processeur cible pendant les heures de bureau s’élève à 40 % dans des conditions normales de fonctionnement (N + 1) et à 60 % sinon (N). Pendant les heures non ouvrées, la cible d’utilisation du CPU est de 80% car nous nous attendons à ce que le logiciel de sauvegarde et d’autres processus de maintenance consomment toutes les ressources disponibles.
Examinons maintenant le graphique (Processor Information(_Total)\% Processor Utility), pour chacun des DC, comme indiqué dans l’image suivante.
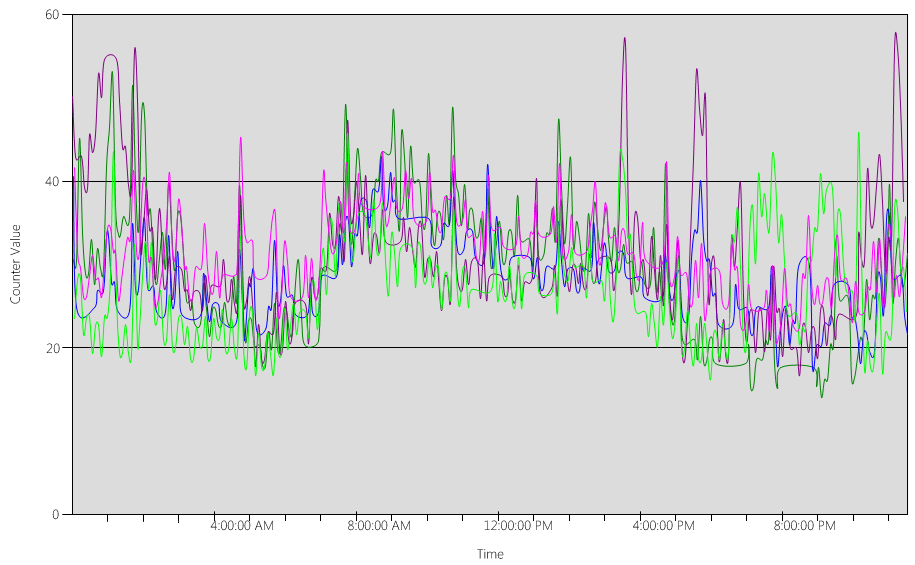
La charge est relativement bien répartie, ce à quoi nous nous attendrions lorsque les clients utilisent le localisateur DC et des recherches bien écrites.
À plusieurs intervalles de cinq minutes, il y a des pics à 10%, parfois même 20%. Cependant, à moins que ces pics ne fassent dépasser l’utilisation du CPU l’objectif de planification de capacité, vous n’avez pas besoin de les examiner.
La période de pointe pour tous les systèmes est entre 8h00 et 9h15. La journée de travail moyenne dure de 5h00 à 17h00. Par conséquent, les pics aléatoires de l’utilisation du CPU qui se produisent entre 17h00 et 4h00 du matin sont en dehors des heures ouvrées et ne nécessitent donc pas d’être inclus dans vos préoccupations de planification de capacité.
Remarque
Sur un système bien géré, les pics qui se produisent en dehors des heures de pointe sont généralement causés par des logiciels de sauvegarde, des analyses antivirus complètes, des inventaires matériels ou logiciels, des déploiements de logiciels ou de correctifs, etc. Comme ces pics se produisent en dehors des heures de bureau, ils ne comptent pas pour dépasser les objectifs de planification de capacité.
Étant donné que chaque système est à environ 40% et qu’ils ont tous le même nombre de CPU, si l’un d’entre eux se déconnecte, les systèmes restants fonctionnent à environ 53%. Le système D a une charge de 40% qui est répartie équitablement et ajoutée à la charge existante de 40% des systèmes A et C. Cette hypothèse linéaire n’est pas parfaitement exacte, mais elle est suffisamment précise pour évaluer la situation.
Ensuite, examinons un exemple d’environnement qui n’a pas une bonne utilisation du CPU et dépasse l’objectif de planification de capacité.
Dans cet exemple, nous avons deux DC fonctionnant à 40%. Un contrôleur de domaine se déconnecte, ce qui fait que l’utilisation estimée du CPU sur le DC restant atteint 80%. Ce niveau d’utilisation du CPU dépasse largement le seuil de la planification de capacité et commence à limiter la marge de manœuvre pour les 10% à 20% du profil de charge. En conséquence, chaque pic pourrait potentiellement pousser le DC à 90% ou même 100% pendant le scénario N, réduisant ainsi sa réactivité.
Calcul des demandes processeur
Le compteur de Process\% Processor Time performance suit le temps total que tous les threads d’application passent sur le CPU, puis divise cette somme par la durée totale du temps système écoulé. Une application multithread sur un système multi-CPU peut dépasser 100% de temps CPU, et vous interpréteriez ses données très différemment du compteur Processor Information\% Processor Utility. En pratique, le compteur Process(lsass)\% Processor Time suit combien de CPU fonctionnant à 100% le système nécessite pour répondre aux exigences d’un processus. Par exemple, si le compteur a une valeur de 200%, cela signifie que le système a besoin de deux CPU fonctionnant à 100% pour supporter toute la charge AD DS. Bien qu’un CPU fonctionnant à 100% de sa capacité soit le plus rentable en termes de consommation d’énergie et de puissance, pour les raisons décrites dans Annexe A, un système multithread est plus réactif lorsque son système ne fonctionne pas à 100%.
Pour accueillir les pics transitoires de la charge des clients, nous vous recommandons de cibler une période de pointe du CPU entre 40% et 60% de la capacité du système. Par exemple, dans le premier exemple de Profil de comportement cible du site, vous auriez besoin de 3,33 CPU (cible 60%) à 5 CPU (cible 40%) pour supporter la charge AD DS. Vous devriez ajouter une capacité supplémentaire en fonction des besoins de l’OS et de tout autre agent requis, tel que l’antivirus, la sauvegarde, la surveillance, etc. Bien que vous deviez évaluer l’impact des agents sur les agents CPU au cas par cas, généralement, vous pouvez allouer entre 5% et 10% pour les processus d’agents sur un seul CPU. Pour reprendre notre exemple, nous aurions besoin de 3,43 CPU (cible 60%) à 5,1 CPU (cible 40%) pour supporter la charge pendant les périodes de pointe.
Examinons maintenant un exemple de calcul pour un processus spécifique. Dans ce cas, nous examinons le processus LSASS.
Calcul de l’utilisation CPU pour le processus LSASS
Dans cet exemple, le système est dans un scénario N + 1 où un serveur supporte la charge AD DS tandis qu’un serveur supplémentaire est là pour la redondance.
Le graphique suivant montre le temps processeur pour le processus LSASS sur tous les processeurs pour cet exemple de scénario. Ces données ont été recueillies à partir du compteur de performance Process(lsass)\% Processor Time.
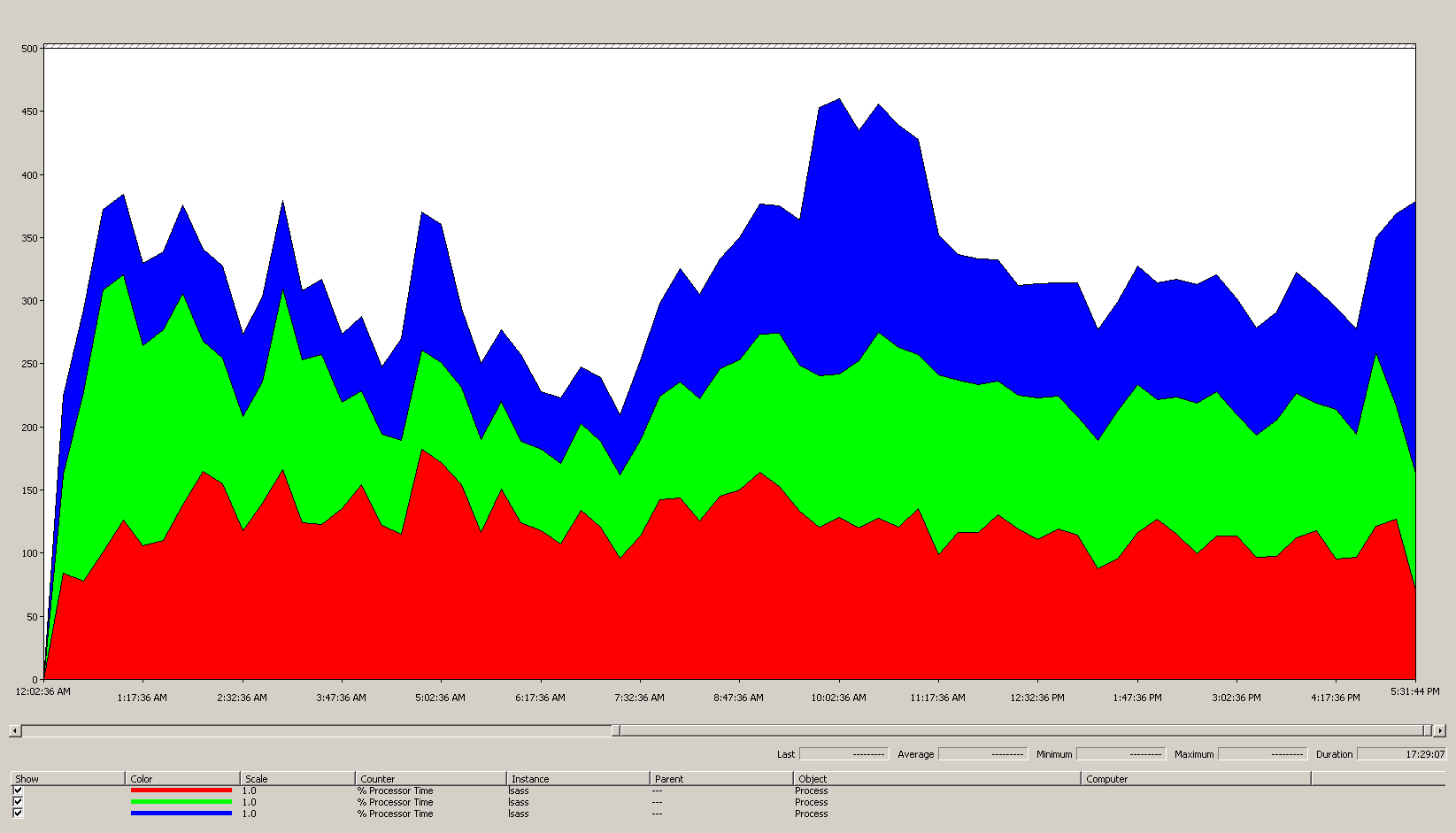
Voici ce que ce graphique nous apprend sur l’environnement de ce scénario :
- Le site comprend trois contrôleurs de domaine.
- La journée de travail commence à monter en puissance vers 7h00, puis redescend à 17h00.
- La période la plus chargée de la journée est de 9h30 à 11h00.
Remarque
Toutes les données de performances sont historiques. Le point de données de pointe à 9h15 indique la charge de 9h00 à 9h15.
- Les pics avant 7h00 pourraient indiquer une charge supplémentaire provenant de différents fuseaux horaires ou d’une activité d’infrastructure en arrière-plan, telle que des sauvegardes. Cependant, étant donné que ce pic est inférieur à l’activité de pointe à 9h30, il n’est pas préoccupant.
À charge maximale, le processus LSASS consomme environ 4,85 CPU fonctionnant à 100%, ce qui correspondrait à 485% sur un seul CPU. Ces résultats suggèrent que le site du scénario a besoin d’environ 12/25 CPU pour gérer AD DS. Lorsque vous ajoutez la capacité supplémentaire recommandée de 5% à 10% pour les processus en arrière-plan, le serveur a besoin de 12,30 à 12,25 CPU pour supporter sa charge actuelle. Les estimations anticipant une croissance future rendent ce nombre encore plus élevé.
Quand régler des pondérations LDAP
Il existe certains scénarios où vous devriez envisager d’ajuster LdapSrvWeight. Dans le contexte de la planification de la capacité, vous devriez l’ajuster lorsque vos applications, charges utilisateurs ou capacités système sous-jacentes ne sont pas équilibrées de manière homogène.
Les sections suivantes décrivent deux scénarios d’exemple où vous devriez ajuster les pondérations Lightweight Directory Access Protocol (LDAP).
Exemple 1 : Environnement émulateur PDC
Si vous utilisez un émulateur de contrôleur de domaine principal (PDC), un comportement utilisateur ou applicatif distribué de manière inégale peut affecter plusieurs environnements à la fois. Les ressources CPU sur l’émulateur PDC sont souvent plus sollicitées qu’ailleurs dans le déploiement car plusieurs outils et actions le ciblent, tels que les outils de gestion des stratégies de groupe, les tentatives d’authentification secondaire, l’établissement de confiance, etc.
- Vous devriez ajuster votre émulateur PDC uniquement s’il y a une différence notable dans l’utilisation du CPU. L’ajustement devrait réduire la charge sur l’émulateur PDC et augmenter la charge sur d’autres DC, permettant une répartition plus uniforme de la charge.
- Dans ces cas, définissez la valeur de
LDAPSrvWeightentre 50 et 75 pour l’émulateur PDC.Divisez le nombre total d’E/S par le nombre de secondes dans la plage horaire définie.
| Système | Utilisation du CPU avec les paramètres par défaut | Nouveau LdapSrvWeight | Nouvelle estimation de l’utilisation du CPU |
|---|---|---|---|
| Contrôleur de domaine 1 (émulateur de contrôleur de domaine principal) | 53 % | 57 | 40 % |
| Contrôleur de domaine 2 | 33 % | 100 | 40 % |
| Contrôleur de domaine 3 | 33 % | 100 | 40 % |
Le problème est que si le rôle d’émulateur PDC est transféré ou saisi, en particulier par un autre contrôleur de domaine dans le site, l’utilisation du CPU augmente considérablement sur le nouvel émulateur PDC.
Dans cet exemple de scénario, nous supposons, en nous basant sur le profil de comportement du site cible, que les trois contrôleurs de domaine dans ce site disposent chacun de quatre CPU. Dans des conditions normales, que se passerait-il si l’un de ces DC avait huit CPU ? Il y aurait deux DC avec une utilisation de 40 % et un avec une utilisation de 20 %. Bien que cette configuration ne soit pas nécessairement mauvaise, il existe ici une opportunité pour vous d’utiliser le réglage du poids LDAP pour mieux équilibrer la charge.
Exemple 2 : environnement avec différents nombres de CPU
Lorsque vous avez des serveurs avec différents nombres de CPU et vitesses dans le même site, vous devez vous assurer qu’ils sont répartis équitablement. Par exemple, si votre site possède deux serveurs à huit cœurs et un serveur à quatre cœurs, le serveur à quatre cœurs ne dispose que de la moitié de la puissance de traitement des deux autres serveurs. Si la charge client est répartie de manière égale, cela signifie que le serveur à quatre cœurs doit travailler deux fois plus que les deux serveurs à huit cœurs pour gérer sa charge CPU. En plus de cela, si l’un des serveurs à huit cœurs tombe en panne, le serveur à quatre cœurs est surchargé.
| Système | Informations processeur\% de rendement du processeur(_Total) Utilisation du CPU avec les paramètres par défaut |
Nouveau LdapSrvWeight | Nouvelle estimation de l’utilisation du CPU |
|---|---|---|---|
| Contrôleur de domaine 1 à 4 processeurs | 40 | 100 | 30 % |
| Contrôleur de domaine 2 à 4 processeurs | 40 | 100 | 30 % |
| Contrôleur de domaine 3 à 8 processeurs | 20 | 200 | 30 % |
Il est d’une importance capitale de planifier un scénario « N + 1 ». L’impact de la mise hors connexion d’un seul contrôleur de domaine doit être calculé pour chaque scénario. Dans le scénario immédiatement précédent où la répartition de la charge est équilibrée, afin d’assurer une charge de 60 % lors d’un scénario « N », avec la charge répartie de manière égale entre tous les serveurs, la distribution est correcte car les ratios restent cohérents. Lorsque vous examinez le scénario de réglage de l’émulateur PDC, ou tout scénario général où la charge des utilisateurs ou des applications est déséquilibrée, l’effet est très différent :
| Système | Utilisation ajustée | Nouveau LdapSrvWeight | Nouvelle utilisation estimée |
|---|---|---|---|
| Contrôleur de domaine 1 (émulateur de contrôleur de domaine principal) | 40 % | 85 % | 47 % |
| Contrôleur de domaine 2 | 40 % | 100 | 53 % |
| Contrôleur de domaine 3 | 40 % | 100 | 53 % |
Éléments à prendre en compte en matière de virtualisation pour le traitement
Lorsque vous planifiez la capacité pour un environnement virtualisé, il y a deux niveaux que vous devez prendre en compte : le niveau hôte et le niveau invité. Au niveau hôte, vous devez identifier les périodes de pointe de votre cycle d’activité. Comme la planification des threads invités sur le CPU pour une machine virtuelle est similaire à celle des threads AD DS sur le CPU pour une machine physique, nous vous recommandons toujours d’utiliser 40 % à 60 % de l’hôte sous-jacent. Au niveau invité, comme les principes de planification des threads sous-jacents ne changent pas, nous vous recommandons également de maintenir l’utilisation du CPU dans la plage de 40 % à 60 %.
Dans un scénario à correspondance directe avec un invité par hôte, vous devez intégrer toutes les estimations de planification de capacité que vous avez effectuées dans les sections précédentes afin de faire votre estimation. Pour un scénario d’hôte partagé, il y a environ 10 % d’impact sur l’efficacité des processeurs sous-jacents, ce qui signifie que si un site nécessite 10 CPU à un objectif de 40 %, le nombre recommandé de CPU virtuels que vous devez allouer à l’ensemble des N invités serait de 11. Dans les sites avec des distributions mixtes de serveurs physiques et virtuels, ce modificateur ne s’applique qu’aux machines virtuelles (VM). Par exemple, dans un scénario N + 1, un serveur physique ou à correspondance directe avec 10 CPU est presque équivalent à un invité avec 11 CPU sur un hôte avec 11 CPU supplémentaires réservés pour le DC.
Pendant que vous analysez et calculez le nombre de CPU nécessaires pour prendre en charge la charge AD DS, gardez à l’esprit que si vous prévoyez d’acheter du matériel physique, les types de matériel disponibles sur le marché peuvent ne pas correspondre exactement à vos estimations. Cependant, vous n’avez pas ce problème lorsque vous utilisez la virtualisation. L’utilisation de VM réduit l’effort nécessaire pour ajouter de la capacité de calcul à un site, car vous pouvez ajouter autant de CPU avec les spécifications exactes que vous souhaitez à une VM. Cependant, la virtualisation ne supprime pas votre responsabilité d’évaluer précisément la quantité de puissance de calcul dont vous avez besoin pour garantir que votre matériel sous-jacent est disponible lorsque les invités ont besoin de plus de CPU. Comme toujours, n’oubliez pas de planifier la croissance à l’avance.
Exemple de résumé des calculs de virtualisation
| Système | Processeur de pointe |
|---|---|
| Contrôleur de domaine 1 | 120 % |
| Contrôleur de domaine 2 | 147 % |
| Contrôleur de domaine 3 | 218 % |
| Utilisation totale du CPU | 485 % |
| Nombre de systèmes cibles | Bande passante totale (comme ci-dessus) |
|---|---|
| Processeurs nécessaires à une cible de 40 % | 4,85 ÷ 0,4 = 12,125 |
En prévoyant la croissance dans ce scénario, si vous supposez que la demande augmentera de 50 % au cours des trois prochaines années, vous devez vous assurer qu’il dispose de 18,375 CPU (12,25 × 1,5) d’ici là. Sinon, vous pouvez revoir la demande après la première année, puis ajouter de la capacité supplémentaire en fonction des résultats.
Charge d’authentification du client avec approbation croisée pour NTLM
Évaluation de la charge d’authentification du client avec approbation croisée
De nombreux environnements peuvent avoir un ou plusieurs domaines connectés par une approbation. Les demandes d’authentification pour des identités dans d’autres domaines qui n’utilisent pas Kerberos doivent traverser une relation d’approbation en utilisant un canal sécurisé entre deux contrôleurs de domaine. Le contrôleur de domaine que l’utilisateur essaie d’accéder dans le site se connecte à un autre contrôleur de domaine qui est situé soit dans le domaine de destination, soit quelque part plus haut sur le chemin vers le domaine de destination. Le nombre d’appels que le DC peut passer à l’autre DC dans le domaine approuvé est contrôlé par le paramètre *MaxConcurrentAPI*. Pour garantir que le canal sécurisé puisse gérer la charge nécessaire pour que les DC communiquent entre eux, vous pouvez soit régler MaxConcurrentAPI, soit, si vous êtes dans une forêt, créer des approbations de raccourci. Pour en savoir plus sur la manière de déterminer le volume de trafic à travers les approbations, consultez Comment effectuer un réglage des performances pour l’authentification NTLM en utilisant le paramètre MaxConcurrentApi.
Comme pour les scénarios précédents, vous devez collecter des données pendant les périodes de pointe de la journée pour qu’elles soient utiles.
Remarque
Les scénarios intra-forêt et inter-forêts peuvent amener l’authentification à traverser plusieurs approbations, ce qui signifie que vous devez régler chaque étape du processus.
Planification de la virtualisation
Il y a quelques éléments à garder à l’esprit lors de la planification de la capacité pour la virtualisation :
- De nombreuses applications utilisent l’authentification Network Level Trust Manager (NTLM) par défaut ou dans certaines configurations.
- À mesure que le nombre de clients actifs augmente, il en va de même pour le besoin des serveurs d’applications d’avoir plus de capacité.
- Les clients gardent parfois les sessions ouvertes pendant une durée limitée et se reconnectent régulièrement pour des services comme la synchronisation des courriers électroniques.
- Les serveurs proxy Web qui nécessitent une authentification pour accéder à Internet peuvent entraîner une charge élevée NTLM.
Ces applications peuvent créer une charge importante pour l’authentification NTLM, ce qui met une pression significative sur les DC, en particulier lorsque les utilisateurs et les ressources se trouvent dans des domaines différents.
Il existe de nombreuses approches que vous pouvez adopter pour gérer la charge d’approbation croisée, que vous pouvez souvent et devriez utiliser simultanément :
- Réduisez l’authentification client croisée en localisant les services qu’un utilisateur consomme dans le domaine où il se trouve.
- Augmentez le nombre de canaux sécurisés disponibles. Ces canaux sont appelés approbations de raccourci et sont pertinents pour le trafic intra-forêt et inter-forêts.
- Réglez les paramètres par défaut pour MaxConcurrentAPI.
Pour régler MaxConcurrentAPI sur un serveur existant, utilisez l’équation suivante :
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
Pour plus d’informations, consultez l’article de la base de connaissances 2688798 : Guide pratique pour effectuer un réglage des performances de l’authentification NTLM à l’aide du paramètre MaxConcurrentApi.
Éléments à prendre en compte en matière de virtualisation
Il n’y a pas de considérations particulières à prendre en compte, car la virtualisation est un paramètre de réglage du système d’exploitation.
Exemple de calcul de réglage de la virtualisation
| Type de données | Valeur |
|---|---|
| Acquisitions de sémaphore (minimum) | 6 161 |
| Acquisitions de sémaphore (maximum) | 6 762 |
| Expirations de sémaphore | 0 |
| Temps moyen de conservation de sémaphore | 0,012 |
| Durée de la collecte (secondes) | 1 minute 11 secondes (71 secondes) |
| Formule (extraite de la base de connaissances 2688798) | ((6762 - 6161) + 0) × 0,012 / |
| Valeur minimale de MaxConcurrentAPI | ((6762 - 6161) + 0) × 0,012 ÷ 71 = 0,101 |
Pour ce système, les valeurs par défaut sont acceptables pendant cette période.
Monitoring de la conformité avec des objectifs de planification de capacité
Tout au long de cet article, nous avons discuté de la manière dont la planification et la mise à l’échelle contribuent aux objectifs d’utilisation. Le tableau suivant résume les seuils recommandés que vous devez surveiller pour vous assurer que les systèmes fonctionnent comme prévu. Gardez à l’esprit qu’il ne s’agit pas de seuils de performance, mais de seuils de planification de capacité. Un serveur fonctionnant au-delà de ces seuils continuera de fonctionner, mais vous devez vérifier que vos applications fonctionnent comme prévu avant de commencer à observer des problèmes de performance à mesure que la demande des utilisateurs augmente. Si les applications fonctionnent correctement, vous devez alors commencer à évaluer les mises à niveau matérielles ou d’autres modifications de configuration.
| Catégorie | Compteur de performances | Intervalle/Échantillonnage | Cible | Avertissement |
|---|---|---|---|---|
| Processeur | Processor Information(_Total)\% Processor Utility |
60 min | 40 % | 60 % |
| RAM (Windows Server 2008 R2 ou version antérieure) | Mémoire\Mo disponibles | < 100 Mo | N/A | < 100 Mo |
| RAM (Windows Server 2012) | Mémoire\Durée(s) de vie moyenne(s) du cache de secours à long terme | 30 min | À tester | À tester |
| Réseau | Interface réseau(*)\Octets envoyés/s Interface réseau(*)\Octets reçus/s |
30 min | 40 % | 60 % |
| Stockage | LogicalDisk((<NTDS Database Drive>))\Temps moyen du disque sec/LectureLogicalDisk(( |
60 min | 10 ms | 15 ms |
| Services AD | Netlogon(*)\Temps moyen de conservation de sémaphore | 60 min | 0 | 1 seconde |
Annexe A : Critères de dimensionnement des processeurs
Cette annexe aborde des termes et concepts utiles qui peuvent vous aider à estimer les besoins en dimensionnement du CPU de votre environnement.
Définitions : dimensionnement du CPU
Un processeur (microprocesseur) est un composant qui lit et exécute les instructions d’un programme.
Un processeur multicœur possède plusieurs CPU sur le même circuit intégré.
Un système multi-CPU possède plusieurs CPU qui ne sont pas sur le même circuit intégré.
Un processeur logique est un processeur qui n’a qu’un seul moteur de calcul logique du point de vue du système d’exploitation.
Ces définitions incluent l’hyper-threading, un cœur sur un processeur multicœur, ou un processeur monocœur.
Comme les systèmes de serveurs modernes possèdent plusieurs processeurs, plusieurs processeurs multicœurs et de l’hyper-threading, ces définitions sont généralisées pour couvrir les deux scénarios. Nous utilisons le terme processeur logique car il représente la perspective du système d’exploitation et des applications des moteurs de calcul disponibles.
Parallélisme au niveau des threads
Chaque thread est une tâche indépendante, car il possède sa propre pile et ses propres instructions. AD DS est multithread et vous pouvez régler le nombre de threads disponibles en suivant les instructions de Comment afficher et définir la stratégie LDAP dans Active Directory en utilisant Ntdsutil.exe, il s’adapte bien à plusieurs processeurs logiques.
Parallélisme au niveau des données
Le parallélisme au niveau des données est lorsque qu’un service partage des données entre plusieurs threads pour le même processus et partage de nombreux threads entre plusieurs processus. Le processus AD DS à lui seul compterait comme un service partageant des données entre plusieurs threads pour un seul processus. Toute modification des données est reflétée dans tous les threads en cours d’exécution à tous les niveaux du cache, chaque cœur, et toute mise à jour de la mémoire partagée. Les performances peuvent se dégrader lors des opérations d’écriture car toutes les emplacements mémoire s’ajustent aux modifications avant que le traitement des instructions puisse continuer.
Vitesse du CPU par rapport aux considérations multicœurs
En général, des processeurs logiques plus rapides réduisent le temps nécessaire pour traiter une série d’instructions. Plus de processeurs logiques signifient que vous pouvez exécuter plus de tâches en même temps. Cependant, ces règles ne s’appliquent pas dans des scénarios plus complexes, tels que la récupération de données à partir de la mémoire partagée, l’attente du parallélisme au niveau des données, et la surcharge de la gestion de plusieurs threads à la fois. En conséquence, l’évolutivité dans les systèmes multicœurs n’est pas linéaire.
Pour comprendre pourquoi ce changement se produit, il est utile de penser à ces scénarios comme à une autoroute. Chaque thread est une voiture individuelle, chaque voie est un cœur, et la limitation de vitesse est la vitesse d’horloge.
S’il n’y a qu’une seule voiture sur l’autoroute, peu importe s’il y a deux ou douze voies. Cette voiture va seulement aussi vite que la limitation de vitesse le permet.
Si les données dont le thread a besoin ne sont pas immédiatement disponibles, alors le thread ne peut pas traiter les instructions jusqu’à ce qu’il récupère les données pertinentes de la mémoire. C’est comme si un segment de l’autoroute était fermé. Même s’il n’y a qu’une seule voiture sur l’autoroute, la limitation de vitesse n’affectera pas sa capacité à circuler, car elle ne peut aller nulle part tant que la route n’est pas rouverte.
À mesure que le nombre de voitures augmente, les frais généraux nécessaires pour gérer le nombre de voitures augmentent également. Les conducteurs doivent se concentrer davantage lorsqu’ils conduisent sur l’autoroute pendant les heures de pointe par rapport à la fin de soirée, lorsque la route est principalement vide. De plus, conduire sur une autoroute à deux voies, où vous n’avez à vous soucier que d’une autre voie, nécessite moins de concentration que de conduire sur une autoroute à six voies où vous devez faire attention à cinq autres voies de circulation.
En résumé, les questions de savoir s’il faut ajouter davantage de processeurs ou des processeurs plus rapides deviennent très subjectives et doivent être examinées au cas par cas. Pour AD DS en particulier, ses besoins en traitement dépendent des facteurs environnementaux et peuvent varier d’un serveur à l’autre au sein d’un même environnement. Par conséquent, les sections précédentes de cet article n’ont pas beaucoup investi dans des calculs super précis. Lorsque vous prenez des décisions d’achat basées sur le budget, nous vous recommandons d’optimiser d’abord l’utilisation du processeur à 40 % ou au chiffre requis par votre environnement spécifique. Si votre système n’est pas optimisé, alors vous ne bénéficierez pas autant de l’achat de processeurs supplémentaires.
Remarque
La loi d’Amdahl et de Gustafson sont les concepts pertinents ici.
Temps de réponse et impact des niveaux d’activité du système sur les performances
La théorie des files d’attente est l’étude mathématique des files d’attente, ou queues. En théorie des files d’attente pour l’informatique, la loi d’utilisation est représentée par l’équation suivante :
U k = B ÷ T
Où U k est le pourcentage d’utilisation, B est le temps passé à être occupé, et T est le temps total passé à observer le système. Dans un contexte Microsoft, cela signifie le nombre de threads d’intervalle de 100 nanosecondes (ns) qui sont en état de fonctionnement divisé par le nombre d’intervalles de 100 ns disponibles dans l’intervalle de temps donné. C’est la même formule qui calcule le pourcentage d’utilisation du processeur affiché dans l’objet Processeur et PERF_100NSEC_TIMER_INV.
La théorie des files d’attente fournit également la formule suivante : N = U k ÷ (1 - U k) pour estimer le nombre d’éléments en attente en fonction de l’utilisation, où N est la longueur de la queue. La représentation graphique de cette équation sur tous les intervalles d’utilisation fournit les estimations suivantes du temps d’attente dans la queue pour accéder au processeur à une charge CPU donnée.
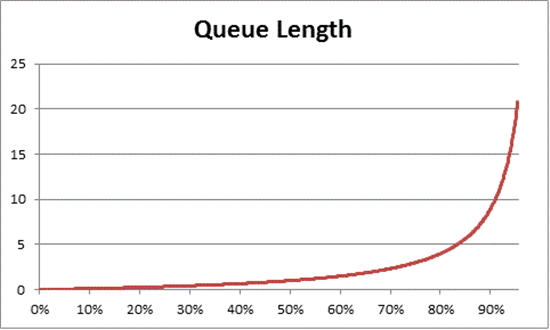
Sur la base de cette estimation, nous pouvons observer qu’après 50 % de charge CPU, l’attente moyenne comprend généralement un autre élément dans la queue, et augmente rapidement jusqu’à 70 % d’utilisation CPU.
Pour comprendre comment la théorie des files d’attente s’applique à votre déploiement AD DS, revenons à la métaphore de l’autoroute que nous avons utilisée dans la vitesse du CPU par rapport aux considérations sur les cœurs multiples.
Les périodes plus chargées en milieu d’après-midi se situeraient quelque part dans la plage de capacité de 40 % à 70 %. Il y a suffisamment de trafic pour que votre capacité à choisir une voie pour conduire ne soit pas sévèrement restreinte. Bien que la probabilité qu’un autre conducteur se mette en travers de votre chemin soit élevée, cela ne nécessite pas le même niveau d’effort que vous auriez besoin pour trouver un espace sûr entre les autres voitures dans la voie pendant les heures de pointe.
À l’approche des heures de pointe, le système routier approche de 100 % de sa capacité. Changer de voie pendant les heures de pointe devient très difficile car les voitures sont si proches les unes des autres que vous n’avez pas autant de marge de manœuvre pour changer de voie.
C’est pourquoi estimer les moyennes à long terme pour une capacité de 40 % permet de laisser plus de marge pour les pics de charge anormaux, qu’ils soient transitoires, comme avec des requêtes mal codées qui mettent du temps à s’exécuter, ou des pics de charge anormaux en général, comme l’augmentation de l’activité le matin après un week-end prolongé.
La déclaration précédente considère le pourcentage de temps de processeur calculé comme étant identique à l’équation de la loi d’utilisation. Cette version simplifiée est destinée à introduire le concept aux nouveaux utilisateurs. Cependant, pour des calculs mathématiques plus avancés, vous pouvez utiliser les références suivantes comme guide :
- Traduction de PERF_100NSEC_TIMER_INV
- B = Le nombre d’intervalles de 100 ns que le thread Idle passe sur le processeur logique. Modification de la variable X dans le calcul de PERF_100NSEC_TIMER_INV.
- T = Nombre total d’intervalles de 100 ns dans un intervalle de temps donné. Modification de la variable Y dans le calcul de PERF_100NSEC_TIMER_INV.
- U k = Pourcentage d’utilisation du processeur logique par thread inactif ou % de temps d’inactivité.
- Description du calcul :
- U k = 1 – % temps processeur
- % temps processeur = 1 – U k
- % temps processeur = 1 – B / T
- % temps processeur = 1 – X1 – X0 / Y1 – Y0
Application de ces concepts à la planification de la capacité
Les calculs mathématiques de la section précédente rendent probablement la détermination du nombre de processeurs logiques nécessaires dans un système très complexe. Par conséquent, votre approche de la dimension du système doit se concentrer sur la détermination de l’utilisation cible maximale en fonction de la charge actuelle, puis sur le calcul du nombre de processeurs logiques nécessaires pour atteindre cet objectif. De plus, votre estimation n’a pas besoin d’être parfaitement exacte. Bien que les vitesses des processeurs logiques aient un impact significatif sur la synchronisation, les performances peuvent également être affectées par d’autres domaines :
- Efficacité du cache
- Exigences de cohérence de la mémoire
- Planification et synchronisation des threads
- Charges clientes imparfaitement équilibrées
Puisque la puissance de calcul est relativement peu coûteuse, il ne vaut pas la peine de consacrer trop de temps à calculer le nombre de CPU exactement parfait dont vous avez besoin.
Il est également important de se rappeler que la recommandation de 40 % dans ce cas n’est pas une exigence obligatoire. Nous l’utilisons comme un point de départ raisonnable pour effectuer des calculs. Différents types d’utilisateurs d’AD ont besoin de différents niveaux de réactivité. Il peut même y avoir des scénarios où des environnements peuvent fonctionner à 80 % voire 90 % d’utilisation soutenue en moyenne sans que les temps d’attente pour l’accès au processeur n’affectent sensiblement les performances des clients.
Il existe également d’autres domaines dans le système qui sont beaucoup plus lents que le processeur logique que vous devez également optimiser, y compris l’accès à la RAM, l’accès au disque et la transmission des réponses sur le réseau. Par exemple :
Si vous ajoutez des processeurs à un système fonctionnant à 90 % d’utilisation qui est limité par le disque, cela n’améliorera probablement pas de manière significative les performances. Si vous examinez de plus près le système, il y a beaucoup de threads qui n’accèdent même pas au processeur car ils attendent que les opérations d’E/S soient terminées.
Résoudre les problèmes liés aux limitations du disque peut signifier que les threads précédemment bloqués en attente cessent d’être bloqués, créant ainsi plus de concurrence pour le temps du processeur. En conséquence, l’utilisation de 90 % passera à 100 %. Vous devez ajuster les deux composants pour ramener l’utilisation à des niveaux gérables.
Remarque
Le compteur
Processor Information(*)\% Processor Utilitypeut dépasser les 100 % avec des systèmes qui ont un mode Turbo. Le mode Turbo permet au CPU de dépasser la vitesse nominale du processeur pendant de courtes périodes. Si vous avez besoin de plus d’informations, consultez la documentation du fabricant du CPU et les descriptions des compteurs.
La discussion sur les considérations d’utilisation de l’ensemble du système implique également les contrôleurs de domaine en tant qu’invités virtualisés. Temps de réponse et impact des niveaux d’activité du système sur les performances s’appliquent à la fois à l’hôte et à l’invité dans un scénario virtualisé. Dans un hôte avec un seul invité, un DC ou un système a presque les mêmes performances que sur un matériel physique. Ajouter plus d’invités aux hôtes augmente l’utilisation de l’hôte sous-jacent, augmentant également les temps d’attente pour accéder aux processeurs. Par conséquent, vous devez gérer l’utilisation des processeurs logiques au niveau de l’hôte et de l’invité.
Revenons à la métaphore de l’autoroute des sections précédentes, sauf que cette fois, nous imaginons l’invité VM comme un bus express. Les bus express, contrairement aux transports publics ou aux bus scolaires, vont directement à la destination du passager sans faire d’arrêts.
Maintenant, imaginons quatre scénarios :
- Les heures creuses d’un système sont comme monter dans un bus express tard le soir. Lorsque le passager monte, il n’y a presque aucun autre passager et la route est presque vide. Parce qu’il n’y a pas de trafic avec lequel le bus doit composer, le trajet est facile et tout aussi rapide que si le passager avait conduit lui-même. Cependant, le temps de trajet du passager est également limité par la limitation de vitesse locale.
- Les heures creuses où l’utilisation du CPU d’un système est trop élevée sont comme un trajet tard le soir lorsque la plupart des voies sur l’autoroute sont fermées. Même si le bus lui-même est principalement vide, la route est encore congestionnée par le trafic restant qui doit composer avec les voies restreintes. Bien que le passager soit libre de s’asseoir où il veut, son temps de trajet réel est déterminé par le trafic extérieur au bus.
- Un système avec une utilisation CPU élevée pendant les heures de pointe est comme un bus bondé pendant l’heure de pointe. Non seulement le trajet est plus long, mais monter et descendre du bus est plus difficile car le bus est plein d’autres passagers. Ajouter plus de processeurs logiques au système invité pour essayer de réduire les temps d’attente reviendrait à essayer de résoudre le problème de circulation en ajoutant plus de bus. Le problème n’est pas le nombre de bus, mais le temps que prend le trajet.
- Un système avec une utilisation CPU élevée pendant les heures creuses est comme ce même bus bondé sur une route quasiment déserte la nuit. Bien que les passagers puissent avoir du mal à trouver des places ou à monter et descendre du bus, le trajet est assez fluide une fois que le bus a pris tous ses passagers. Ce scénario est le seul où les performances s’amélioreraient en ajoutant plus de bus.
D’après les exemples précédents, vous pouvez voir qu’il existe de nombreux scénarios entre 0 % et 100 % d’utilisation qui ont des degrés d’impact variables sur les performances. De plus, ajouter plus de processeurs logiques n’améliore pas nécessairement les performances en dehors de scénarios très spécifiques. Il devrait être assez simple d’appliquer ces principes à l’objectif recommandé de 40 % d’utilisation du CPU pour les hôtes et les invités.
Annexe B : Considérations concernant les différentes vitesses de processeur
Dans Traitement, nous avons supposé que le processeur fonctionnait à 100 % de la vitesse d’horloge pendant que vous collectiez des données, et que tous les systèmes de remplacement avaient la même vitesse de traitement. Bien que ces hypothèses ne soient pas précises, surtout pour Windows Server 2008 R2 et versions ultérieures, où le plan d’alimentation par défaut est Équilibré, ces hypothèses fonctionnent toujours pour des estimations conservatrices. Bien que les erreurs potentielles puissent augmenter, elles n’augmentent que la marge de sécurité à mesure que la vitesse des processeurs augmente.
- Par exemple, dans un scénario nécessitant 11,25 CPU, si les processeurs fonctionnaient à mi-vitesse lorsque vous avez collecté vos données, l’estimation plus précise de leur demande serait de 5,125 ÷ 2.
- Il est impossible de garantir que doubler la vitesse d’horloge double la quantité de traitement effectuée pendant la période de temps enregistrée. Le temps que les processeurs passent à attendre la RAM ou d’autres composants reste à peu près le même. Par conséquent, les processeurs plus rapides pourraient passer un pourcentage plus élevé de temps en veille en attendant que le système récupère des données. Nous vous recommandons de vous en tenir au dénominateur commun le plus bas, de garder vos estimations prudentes et d’éviter de supposer une comparaison linéaire entre les vitesses des processeurs qui pourrait rendre vos résultats inexacts.
Si les vitesses des processeurs de votre matériel de remplacement sont inférieures à celles de votre matériel actuel, vous devez augmenter proportionnellement l’estimation du nombre de processeurs dont vous avez besoin. Par exemple, examinons un scénario où vous calculez qu’il vous faut 10 processeurs pour supporter la charge de votre site. Les processeurs actuels fonctionnent à 3,3 GHz, et les processeurs que vous envisagez de les remplacer fonctionnent à 2,6 GHz. Remplacer uniquement les 10 processeurs d’origine vous donnerait une diminution de vitesse de 21 %. Pour augmenter la vitesse, vous devez obtenir au moins 12 processeurs au lieu de 10.
Cependant, cette variabilité ne change pas les objectifs de gestion de la capacité d’utilisation des processeurs. Les vitesses d’horloge des processeurs s’ajustent dynamiquement en fonction de la demande de charge, donc faire fonctionner le système sous des charges plus élevées amène le CPU à passer plus de temps dans un état de vitesse d’horloge plus élevée. L’objectif ultime est d’avoir le processeur à 40 % d’utilisation dans un état de vitesse d’horloge à 100 % pendant les heures de pointe. Tout ce qui est en dessous générera des économies d’énergie en réduisant la vitesse du processeur lors des scénarios hors pointe.
Remarque
Vous pouvez désactiver la gestion de l’alimentation sur les processeurs pendant la collecte de données en définissant le plan d’alimentation sur Performances élevées. Désactiver la gestion de l’alimentation vous donne des lectures plus précises de la consommation du processeur sur le serveur cible.
Pour ajuster les estimations pour différents processeurs, nous vous recommandons d’utiliser le benchmark SPECint_rate2006 de la Standard Performance Evaluation Corporation. Pour utiliser ce benchmark :
Rendez-vous sur le site web de la Standard Performance Evaluation Corporation (SPEC).
Sélectionnez Résultats.
Entrez CPU2006 et sélectionnez Rechercher.
Dans le menu déroulant pour Configurations disponibles, sélectionnez Tous les SPEC CPU2006.
Dans le champ Demande de formulaire de recherche, sélectionnez Simple, puis sélectionnez Allez-y !.
Sous Demande simple, entrez les critères de recherche pour votre processeur cible. Par exemple, si vous recherchez un processeur ES-2630, dans le menu déroulant, sélectionnez Processeur, puis entrez le nom du processeur dans le champ de recherche. Une fois terminé, sélectionnez Exécuter la récupération simple.
Recherchez la configuration de votre serveur et de votre processeur dans les résultats de recherche. Si le moteur de recherche ne retourne pas de correspondance exacte, recherchez la correspondance la plus proche possible.
Enregistrez les valeurs dans les colonnes Résultat et # Cores.
Déterminez le modificateur en utilisant cette équation :
((Valeur du score par cœur de la plateforme cible) × (MHz par cœur de la plateforme de référence)) ÷ ((Valeur du score par cœur de référence) × (MHz par cœur de la plateforme cible))
Par exemple, voici comment vous trouveriez le modificateur pour un processeur ES-2630 :
(35,83 × 2000) ÷ (33,75 × 2300) = 0,92
Multipliez le nombre de processeurs que vous estimez nécessaires par ce modificateur.
Pour l’exemple du processeur ES-2630, 0,92 × 10,3 = 10,35 processeurs.
Annexe C : Comment le système d’exploitation interagit avec le stockage
Les concepts de la théorie des files d’attente que nous avons abordés dans Temps de réponse et impact des niveaux d’activité du système sur les performances s’appliquent également au stockage. Vous devez être familier avec la façon dont votre système d’exploitation gère les E/S afin d’appliquer efficacement ces concepts. Dans les systèmes d’exploitation Windows, le système d’exploitation crée une file d’attente qui contient les demandes d’E/S pour chaque disque physique. Cependant, un disque physique n’est pas nécessairement un seul disque. Le système d’exploitation peut également enregistrer une agrégation de broches sur un contrôleur de baie ou SAN en tant que disque physique. Les contrôleurs de baie et les SAN peuvent également agréger plusieurs disques en un seul ensemble de baies, le diviser en plusieurs partitions, puis utiliser chaque partition comme un disque physique, comme illustré dans l’image suivante.
Dans cette illustration, les deux broches sont en miroir et divisées en zones logiques pour le stockage des données, étiquetées Données 1 et Données 2. Le système d’exploitation enregistre chacune de ces zones logiques comme des disques physiques distincts.
Maintenant que nous avons clarifié ce qui définit un disque physique, vous devriez également vous familiariser avec les termes suivants pour mieux comprendre les informations de cette annexe.
- Une broche est le dispositif physiquement installé dans le serveur.
- Un ensemble de baies est une collection de broches agrégées par le contrôleur.
- Une partition de baie est une partition de l’ensemble de baies agrégé.
- Un Numéro d’Unité Logique (LUN) est un ensemble de dispositifs SCSI connectés à un ordinateur. Cet article utilise ces termes lorsqu’il parle de SAN.
- Un disque comprend toute broche ou partition que le système d’exploitation enregistre comme un seul disque physique.
- Une partition est une partition logique de ce que le système d’exploitation enregistre comme un disque physique.
Considérations liées à l’architecture du système d’exploitation
Le système d’exploitation crée une file d’attente E/S Première Entrée, Première Sortie (FIFO) pour chaque disque qu’il enregistre. Ces disques peuvent être des broches, des ensembles de baies ou des partitions de baies. En ce qui concerne la gestion des E/S par le système d’exploitation, plus il y a de files d’attente actives, mieux c’est. Lorsque le système d’exploitation sérialise la file d’attente FIFO, il doit traiter toutes les demandes E/S FIFO envoyées au sous-système de stockage dans l’ordre d’arrivée. Lorsque le système d’exploitation corrèle chaque disque avec une broche ou un ensemble de baies, il maintient une file d’attente E/S pour chaque ensemble unique de disques, éliminant la concurrence pour des ressources E/S rares à travers les disques et isolant la demande d’E/S à un seul disque. Cependant, Windows Server 2008 a introduit une exception sous la forme de la priorisation des E/S. Les applications conçues pour utiliser des E/S de faible priorité sont déplacées à la fin de la file d’attente, quel que soit le moment où le système d’exploitation les a reçues. Les applications non spécifiquement codées pour utiliser le paramètre de faible priorité sont par défaut à une priorité normale à la place.
Présentation des sous-systèmes de stockage simples
Dans cette section, nous parlons de sous-systèmes de stockage simples. Commençons par un exemple : un seul disque dur à l’intérieur d’un ordinateur. Si nous décomposons ce système en ses principaux composants de sous-système de stockage, voici ce que nous obtenons :
- Un disque dur SCSI Ultra Rapide de 10 000 tr/min (SCSI Ultra Rapide a un débit de transfert de 20 Mbits/s)
- Un bus SCSI (le câble)
- Un adaptateur SCSI Ultra Rapide
- Un bus PCI 32 bits à 33 MHz
Remarque
Cet exemple ne reflète pas le cache disque où le système conserve généralement les données d’un cylindre. Dans ce cas, la première E/S nécessite 10 ms et le disque lit le cylindre entier. Toutes les autres E/S séquentielles sont satisfaites par le cache. Par conséquent, les caches sur disque peuvent améliorer les performances des E/S séquentielles.
Une fois que vous avez identifié les composants, vous pouvez commencer à vous faire une idée de la quantité de données que le système peut transmettre et de la quantité d’E/S qu’il peut gérer. La quantité d’E/S et la quantité de données pouvant transiter par le système sont liées entre elles, mais ne sont pas les mêmes valeurs. Cette corrélation dépend de la taille des blocs et si les E/S du disque sont aléatoires ou séquentielles. Le système écrit toutes les données sur le disque sous forme de bloc, mais différentes applications peuvent utiliser des tailles de bloc différentes.
Ensuite, analysons ces éléments composant par composant.
Temps d’accès au disque dur
Le disque dur moyen à 10 000 tr/min a un temps de recherche de 7 ms et un temps d’accès de 3 ms. Le temps de recherche est le temps moyen nécessaire pour que la tête de lecture ou d’écriture se déplace vers un emplacement sur le plateau. Le temps d’accès est le temps moyen nécessaire pour que la tête lise ou écrive les données sur le disque une fois qu’elle est à l’emplacement correct. Par conséquent, le temps moyen pour lire un bloc de données unique dans un disque dur à 10 000 tr/min inclut à la fois les temps de recherche et d’accès pour un total d’environ 10 ms, soit 0,010 secondes par bloc de données.
Lorsque chaque accès disque nécessite que la tête se déplace vers un nouvel emplacement sur le disque, le comportement de lecture ou d’écriture est appelé aléatoire. Lorsque toutes les E/S sont aléatoires, un disque dur à 10 000 tr/min peut gérer environ 100 E/S par seconde (IOPS).
Lorsque toutes les E/S proviennent de secteurs adjacents sur le disque dur, on parle d’E/S séquentielles. Les E/S séquentielles n’ont pas de temps de recherche car, après la première E/S terminée, la tête de lecture ou d’écriture est à l’endroit où le disque dur stocke le bloc de données suivant. Par exemple, un disque dur à 10 000 tr/min est capable de gérer environ 333 E/S par seconde, sur la base de l’équation suivante :
1000 ms par seconde ÷ 3 ms par E/S
Jusqu’à présent, le taux de transfert du disque dur n’a pas été pertinent pour notre exemple. Quelle que soit la taille du disque dur, la quantité réelle d’IOPS qu’un disque dur à 10 000 tr/min peut gérer est toujours d’environ 100 E/S aléatoires ou 300 E/S séquentielles. À mesure que les tailles de bloc changent en fonction de l’application qui écrit sur le disque, la quantité de données extraites par E/S change également. Par exemple, si la taille de bloc est de 8 Ko, 100 opérations d’E/S lisent ou écrivent sur le disque dur un total de 800 Ko. Cependant, si la taille du bloc est de 32 Ko, 100 E/S liront ou écriront 3 200 Ko (3,2 Mo) sur le disque dur. Si le taux de transfert SCSI dépasse la quantité totale de données transférées, alors obtenir un taux de transfert plus rapide ne change rien. Pour plus d’informations, consultez les tableaux suivants :
| Descriptif | 7200 tr/min 9 ms de recherche, 4 ms d’accès | 10 000 tr/min 7 ms de recherche, 3 ms d’accès | 15,000 tr/min 4 ms de recherche, 2 ms d’accès |
|---|---|---|---|
| E/S aléatoires | 80 | 100 | 150 |
| E/S séquentielles | 250 | 300 | 500 |
| Lecteur à 10 000 tours/min | Taille de bloc de 8 Ko (Active Directory Jet) |
|---|---|
| E/S aléatoires | 800 Ko/s |
| E/S séquentielles | 2 400 Ko/s |
Le backplane SCSI
La manière dont le backplane SCSI, qui dans cet exemple de scénario est le câble ruban, affecte le débit du sous-système de stockage dépend de la taille du bloc. Quelle quantité d’E/S le bus peut-il gérer si les E/S sont en blocs de 8 Ko ? Dans ce scénario, le bus SCSI est de 20 Mbits/s, soit 20 480 Ko/s. 20 480 Ko/s divisés par des blocs de 8 Ko donnent un maximum d’environ 2500 IOPS prises en charge par le bus SCSI.
Remarque
Les chiffres dans le tableau suivant représentent un exemple de scénario. La plupart des périphériques de stockage attachés utilisent actuellement PCI Express, qui offre un débit beaucoup plus élevé.
| E/S prises en charge par le bus SCSI par taille de bloc | Taille de bloc de 2 Ko | Taille de bloc de 8 Ko (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 Mbits/s | 10 000 | 2 500 |
| 40 Mbits/s | 20 000 | 5 000 |
| 128 Mbits/s | 65 536 | 16 384 |
| 320 Mbits/s | 160 000 | 40 000 |
Comme le montre le tableau précédent, dans notre exemple de scénario, le bus n’est jamais un goulet d’étranglement car le maximum de broches est de 100 E/S, bien en dessous de tous les seuils répertoriés.
Remarque
Dans ce scénario, nous supposons que le bus SCSI est efficace à 100 %.
L’adaptateur SCSI
Pour déterminer la quantité d’E/S que le système peut gérer, vous devez vérifier les spécifications du fabricant. Diriger les demandes d’E/S vers le périphérique approprié nécessite de la puissance de traitement, donc la quantité d’E/S que le système peut gérer dépend de l’adaptateur SCSI ou du processeur du contrôleur de baie.
Dans cet exemple de scénario, nous supposons que le système peut gérer 1 000 E/S.
Bus PCI
Le bus PCI est un composant souvent négligé. Dans cet exemple de scénario, le bus PCI n’est pas un goulet d’étranglement. Cependant, à mesure que les systèmes évoluent, il peut potentiellement devenir un goulot d’étranglement à l’avenir.
Nous pouvons voir combien un bus PCI peut transférer de données dans notre exemple de scénario en utilisant cette équation :
32 bits ÷ 8 bits par octet × 33 MHz = 133 Mbits/s
Par conséquent, nous pouvons supposer qu’un bus PCI 32 bits fonctionnant à 33 MHz peut transférer 133 Mbits/s de données.
Remarque
Le résultat de cette équation représente la limite théorique des données transférées. En réalité, la plupart des systèmes n’atteignent que 50 % du maximum. Dans certains scénarios de rafale, le système peut atteindre 75 % de la limite pendant de courtes périodes.
Un bus PCI 64 bits 66 MHz peut supporter un maximum théorique de 528 Mbits/s sur la base de cette équation :
64 bits ÷ 8 bits par octet × 66 MHz = 528 Mbits/s
Lorsque vous ajoutez un autre périphérique, tel qu’un adaptateur réseau ou un deuxième contrôleur SCSI, cela réduit la bande passante disponible pour le système, car tous les périphériques partagent la bande passante et peuvent entrer en concurrence les uns avec les autres pour des ressources de traitement limitées.
Analyse des sous-systèmes de stockage pour trouver des goulots d’étranglement
Dans ce scénario, la broche est le facteur limitant la quantité d’E/S que vous pouvez demander. En conséquence, ce goulet d’étranglement limite également la quantité de données que le système peut transmettre. Comme notre exemple est un scénario AD DS, la quantité de données transmissibles est de 100 E/S aléatoires par seconde en incréments de 8 Ko, pour un total de 800 Ko par seconde lors de l’accès à la base de données Jet. En revanche, le débit maximal pour une broche que vous configurez pour allouer exclusivement aux fichiers journaux serait limité à 300 E/S séquentielles par seconde par tranches de 8 Ko, soit un total de 2 400 Ko ou 2,4 Mo par seconde.
Maintenant que nous avons analysé les composants de notre configuration d’exemple, examinons un tableau qui montre où des goulets d’étranglement peuvent se produire à mesure que nous ajoutons et modifions des composants dans le sous-système de stockage.
| Remarques | Analyse des goulots d’étranglement | Disque | Autobus | Adaptateur | Bus PCI |
|---|---|---|---|---|---|
| Il s’agit de la configuration du contrôleur de domaine après l’ajout d’un deuxième disque. La configuration du disque représente le goulot d’étranglement à 800 Ko/s. | Ajouter 1 disque (Total = 2) E/S aléatoires Taille de bloc de 4 Ko Disque dur à 10 000 tours/min |
Total de 200 E/S Total de 800 Ko/s |
|||
| Après avoir ajouté 7 disques, la configuration de disque représente toujours le goulot d’étranglement à 3 200 Ko/s. | Ajouter 7 disques (Total = 8) E/S aléatoires Taille de bloc de 4 Ko Disque dur à 10 000 tours/min |
Total de 800 E/S Total de 3 200 Ko/s |
|||
| Après avoir modifié l’E/S en séquentielle, l’adaptateur réseau devient le goulet d’étranglement car il est limité à 1000 IOPS. | Ajouter 7 disques (Total = 8) E/S séquentielles Taille de bloc de 4 Ko Disque dur à 10 000 tours/min |
2 400 E/S peuvent être lues/écrites sur le disque, le contrôleur est limité à 1 000 IOPS | |||
| Après avoir remplacé la carte réseau par une carte SCSI prenant en charge 10 000 E/S par seconde, le goulot d’étranglement revient à la configuration de disque. | Ajouter 7 disques (Total = 8) E/S aléatoires Taille de bloc de 4 Ko Disque dur à 10 000 tours/min Mettre à niveau la carte SCSI (elle prend désormais en charge 10 000 E/S) |
Total de 800 E/S Total de 3 200 Ko/s |
|||
| Après avoir augmenté la taille de bloc à 32 Ko, le bus devient le goulet d’étranglement car il ne supporte que 20 Mbits/s. | Ajouter 7 disques (Total = 8) E/S aléatoires Taille de bloc de 32 Ko Disque dur à 10 000 tours/min |
Total de 800 E/S 25 600 Ko/s (25 Mbits/s) peuvent être lus/écrits sur le disque. Le bus ne supporte que 20 Mbits/s |
|||
| Après la mise à niveau du bus et l’ajout de disques supplémentaires, le disque reste le goulot d’étranglement. | Ajouter 13 disques (Total = 14) Ajouter une deuxième carte SCSI avec 14 disques E/S aléatoires Taille de bloc de 4 Ko Disque dur à 10 000 tours/min Mise à niveau vers un bus SCSI de 320 Mbits/s |
2 800 E/S 11 200 Ko/s (10,9 Mbits/s) |
|||
| Après le passage à des E/S séquentielles, le disque reste le goulot d’étranglement. | Ajouter 13 disques (Total = 14) Ajouter une deuxième carte SCSI avec 14 disques E/S séquentielles Taille de bloc de 4 Ko Disque dur à 10 000 tours/min Mise à niveau vers un bus SCSI de 320 Mbits/s |
8 400 E/S 33 600 Ko/s (32,8 Mo/s) |
|||
| Après avoir ajouté des disques durs plus rapides, le disque reste le goulot d’étranglement. | Ajouter 13 disques (Total = 14) Ajouter une deuxième carte SCSI avec 14 disques E/S séquentielles Taille de bloc de 4 Ko Disque dur à 15 000 tours/min Mise à niveau vers un bus SCSI de 320 Mbits/s |
14 000 E/S 56 000 Ko/s (54,7 Mbits/s) |
|||
| Après avoir augmenté la taille de bloc à 32 Ko, le bus PCI devient le goulot d’étranglement. | Ajouter 13 disques (Total = 14) Ajouter une deuxième carte SCSI avec 14 disques E/S séquentielles Taille de bloc de 32 Ko Disque dur à 15 000 tours/min Mise à niveau vers un bus SCSI de 320 Mbits/s |
14 000 E/S 448 000 Ko/s (437 Mbits/s) est la limite de lecture/écriture du disque. Le bus PCI supporte un maximum théorique de 133 Mbits/s (75 % d’efficacité au mieux). |
Présentation de RAID
Lorsque vous introduisez un contrôleur de baie dans votre sous-système de stockage, cela ne change pas radicalement sa nature. Le contrôleur de baie remplace simplement l’adaptateur SCSI dans les calculs. Cependant, le coût de lecture et d’écriture des données sur le disque lorsque vous utilisez les différents niveaux de baie change.
En RAID 0, l’écriture de données les répartit en bandes sur tous les disques du set RAID. Lors d’une opération de lecture ou d’écriture, le système extrait ou pousse les données sur chaque disque, augmentant ainsi la quantité de données que le système peut transmettre pendant cette période donnée. Ainsi, dans cet exemple où nous utilisons des disques à 10 000 tr/min, l’utilisation du RAID 0 vous permettrait d’effectuer 100 opérations d’E/S. La quantité totale d’E/S que le système supporte est N disques multipliée par 100 E/S par seconde par disque, soit N disques × 100 E/S par seconde par disque.

En RAID 1, le système reflète, ou duplique, les données sur une paire de disques pour assurer la redondance. Lorsque le système effectue une opération de lecture d’E/S, il peut lire les données sur les deux disques du set. Ce mirroring rend la capacité d’E/S des deux disques disponible pendant une opération de lecture. Cependant, le RAID 1 n’offre aucun avantage de performance pour les opérations d’écriture, car le système doit également refléter les données écrites sur la paire de disques. Bien que le mirroring n’allonge pas les temps d’écriture, il empêche le système d’effectuer plus d’une opération de lecture à la fois. Ainsi, chaque opération d’écriture d’E/S coûte deux opérations de lecture d’E/S.
L’équation suivante permet de calculer le nombre d’opérations d’E/S qui se produisent dans ce scénario :
E/S de lecture + 2 × E/S d’écriture = Total des E/S disque disponibles consommées
Lorsque vous connaissez le ratio de lectures par rapport aux écritures et le nombre de disques dans votre déploiement, vous pouvez utiliser cette équation pour calculer la quantité d’E/S que votre baie peut supporter :
IOPS maximum par disque × 2 disques × [(% lectures + % écritures) ÷ (% lectures + 2 × % écritures)] = Total IOPS
Un scénario utilisant à la fois le RAID 1 et le RAID 0 se comporte exactement comme le RAID 1 en ce qui concerne le coût des opérations de lecture et d’écriture. Toutefois, les E/S sont désormais réparties sur chaque jeu mis en miroir. Cela signifie que l’équation changera ainsi :
IOPS maximum par disque × 2 disques × [(% lectures + % écritures) ÷ (% lectures + 2 × % écritures)] = Total E/S
Dans un set RAID 1, lorsque vous répartissez N nombre de sets RAID 1, le total d’E/S que votre baie peut traiter devient N × E/S par set RAID 1 :
N × {IOPS maximum par disque × 2 disques × [(% lectures + % écritures) ÷ (% lectures + 2 × % écritures)]} = Total IOPS
Nous appelons parfois le RAID 5 N + 1 RAID car le système répartit les données sur N disques et écrit les informations de parité sur le + 1 disque. Cependant, le RAID 5 utilise plus de ressources lors d’une écriture d’E/S que le RAID 1 ou le RAID 1 + 0. Le RAID 5 effectue le processus suivant chaque fois que le système d’exploitation soumet une écriture d’E/S à la baie :
- Lire les anciennes données.
- Lire l’ancienne parité.
- Écrire les nouvelles données.
- Écrire la nouvelle parité.
Chaque requête d’écriture d’E/S que le système d’exploitation envoie au contrôleur de baie nécessite quatre opérations d’E/S pour se terminer. Ainsi, les requêtes d’écriture RAID N + 1 prennent quatre fois plus de temps qu’une lecture d’E/S pour se terminer. En d’autres termes, pour déterminer combien de requêtes d’E/S provenant du système d’exploitation se traduisent par combien de requêtes que les disques reçoivent, vous utilisez cette équation :
E/S de lecture + 4 × E/S d’écriture = Nombre total d’E/S
De même, dans un set RAID 1 où vous connaissez le ratio de lectures par rapport aux écritures et le nombre de disques, vous pouvez utiliser cette équation pour identifier la quantité d’E/S que votre baie peut supporter :
IOPS par disque × (disques – 1) × [(% lectures + % écritures) ÷ (% lectures + 4 × % écritures)] = Total IOPS
Remarque
Le résultat de l’équation précédente ne comprend pas le disque perdu pour la parité.
Présentation des SAN
Lorsque vous introduisez un réseau de stockage (SAN) dans votre environnement, cela n’affecte pas les principes de planification que nous avons décrits dans les sections précédentes. Cependant, vous devez tenir compte du fait que le SAN peut modifier le comportement d’E/S pour tous les systèmes qui y sont connectés. L’un des principaux avantages de l’utilisation d’un SAN est qu’il vous offre plus de redondance que le stockage attaché en interne ou en externe, mais cela signifie également que votre planification de capacité doit prendre en compte les besoins en tolérance aux pannes. De plus, à mesure que vous ajoutez des composants à votre système, vous devez également intégrer ces nouvelles pièces dans vos calculs.
Voyons maintenant comment décomposer un SAN en ses composants :
- Le disque dur SCSI ou Fibre Channel
- Le fond de panier du canal de l’unité de stockage
- Les unités de stockage elles-mêmes
- Le module de contrôleur de stockage
- Un ou plusieurs commutateurs SAN
- Une ou plusieurs cartes hôtes (HBA)
- Le bus PCI (Interconnexion de composants périphériques)
Lorsque vous concevez un système pour la redondance, vous devez inclure des composants supplémentaires pour garantir que votre système continue de fonctionner dans un scénario de crise où un ou plusieurs des composants d’origine cessent de fonctionner. Cependant, lorsque vous planifiez la capacité, vous devez exclure les composants redondants des ressources disponibles pour obtenir une estimation précise de la capacité de base de votre système, car ces composants ne sont généralement activés qu’en cas d’urgence. Par exemple, si votre SAN dispose de deux modules de contrôleur, vous n’avez besoin d’en utiliser qu’un seul lors du calcul du débit total d’E/S disponible, car l’autre ne s’activera que si le module d’origine cesse de fonctionner. Vous ne devez pas non plus inclure le commutateur SAN redondant, l’unité de stockage ou les disques dans les calculs d’E/S.
De plus, parce que votre planification de capacité ne considère que les périodes de pointe, vous ne devez pas inclure les composants redondants dans vos ressources disponibles. L’utilisation maximale ne doit pas dépasser 80 % de saturation du système afin de pouvoir accueillir les pics ou autres comportements inhabituels du système.
Lorsque vous analysez le comportement du disque dur SCSI ou Fibre Channel, vous devez l’analyser selon les principes que nous avons décrits dans les sections précédentes. Bien que chaque protocole ait ses propres avantages et inconvénients, la principale chose qui limite les performances sur une base par disque est les limites mécaniques du disque dur.
Lorsque vous analysez le canal de l’unité de stockage, vous devez adopter la même approche que lorsque vous calculiez le nombre de ressources disponibles sur le bus SCSI : divisez la bande passante par la taille de bloc. Par exemple, si votre unité de stockage dispose de six canaux supportant chacun un débit maximum de 20 Mbits/s, votre quantité totale d’E/S et de transfert de données disponible est de 100 Mbits/s. La raison pour laquelle le total est de 100 Mbits/s au lieu de 120 Mbits/s est que le débit total du canal de stockage ne doit pas dépasser la quantité de débit qu’il utiliserait si l’un des canaux s’arrêtait soudainement, ne laissant que cinq canaux fonctionnels. Bien sûr, cet exemple suppose également que le système répartit la charge et la tolérance aux pannes de manière uniforme sur tous les canaux.
La possibilité de transformer l’exemple précédent en un profil d’E/S dépend du comportement de l’application. Pour l’E/S Active Directory Jet, la valeur maximale serait d’environ 12 500 E/S par seconde, soit 100 Mbits/s ÷ 8 Ko par E/S.
Pour comprendre le débit que vos modules de contrôleur supportent, vous devez également obtenir leurs spécifications auprès du fabricant. Dans cet exemple, le SAN a deux modules de contrôleur qui prennent en charge 7 500 E/S chacun. Si vous n’utilisez pas la redondance, le débit total du système serait de 15 000 IOPS. Cependant, dans un scénario où la redondance est requise, vous calculeriez le débit maximum en fonction des limites d’un seul des contrôleurs, soit 7 500 IOPS. En supposant que la taille de bloc soit de 4 Ko, ce seuil est bien en dessous du maximum de 12 500 IOPS que les canaux de stockage peuvent supporter, et constitue donc le goulet d’étranglement dans votre analyse. Cependant, à des fins de planification, le maximum d’E/S souhaité que vous devriez prévoir est de 10 400 E/S.
Lorsque les données quittent le module de contrôleur, elles transitent par une connexion Fibre Channel avec un débit de 1 Go/s, soit 128 Mbits/s. Comme cette quantité dépasse la bande passante totale de 100 Mbits/s sur tous les canaux de l’unité de stockage, elle ne constituera pas un goulot d’étranglement pour le système. De plus, étant donné que cette transmission ne se fait que sur l’un des deux canaux Fibre Channel en raison de la redondance, si une connexion Fibre Channel cesse de fonctionner, la connexion restante aura toujours suffisamment de capacité pour gérer la demande de transfert de données.
Les données transitent ensuite par un commutateur SAN en direction du serveur. Le commutateur limite la quantité d’E/S qu’il peut gérer car il doit traiter la demande entrante puis la transmettre au port approprié. Cependant, vous ne pouvez connaître la limite du commutateur qu’en consultant les spécifications du fabricant. Par exemple, si votre système dispose de deux commutateurs et que chaque commutateur peut gérer 10 000 IOPS, le débit total sera de 20 000 IOPS. Selon les règles de tolérance aux pannes, si un commutateur cesse de fonctionner, le débit total du système sera de 10 000 IOPS. Par conséquent, dans des conditions normales, vous ne devriez pas utiliser plus de 80 % de la capacité, soit 8 000 E/S.
Enfin, le HBA que vous installez dans le serveur limite également la quantité d’E/S qu’il peut gérer. En général, vous installez un deuxième HBA pour la redondance, mais comme pour le commutateur SAN, lorsque vous calculez la quantité d’E/S que le système peut gérer, le débit total sera N - 1 HBA.
Considérations relatives à la mise en cache
Les caches sont l’un des composants qui peuvent avoir un impact significatif sur les performances globales à n’importe quel endroit du système de stockage. Cependant, une analyse détaillée des algorithmes de mise en cache dépasse le cadre de cet article. Nous vous donnerons plutôt une liste rapide des éléments que vous devez connaître sur la mise en cache des sous-systèmes de disque.
- La mise en cache améliore les E/S en écriture séquentielle soutenue car elle met en mémoire tampon de nombreuses petites opérations d’écriture en blocs d’E/S plus importants. Elle déstabilise également les opérations vers le stockage en quelques gros blocs au lieu de nombreux petits. Cette optimisation réduit le nombre total d’opérations d’E/S aléatoires et séquentielles, libérant ainsi davantage de ressources pour d’autres opérations d’E/S.
- La mise en cache n’améliore pas le débit d’E/S en écriture soutenue sur le sous-système de stockage car elle ne met en mémoire tampon les écritures que jusqu’à ce que les disques soient disponibles pour valider les données. Lorsque toutes les E/S disponibles des disques sont saturées par les données pendant de longues périodes, le cache finit par se remplir. Pour vider le cache, vous devez fournir suffisamment d’E/S pour permettre au cache de se vider en fournissant des disques supplémentaires ou en laissant suffisamment de temps entre les pics pour que le système puisse rattraper son retard.
- Les caches plus grands permettent de mettre en mémoire tampon davantage de données, ce qui signifie que le cache peut gérer des périodes de saturation plus longues.
- Dans les sous-systèmes de stockage typiques, l’OS bénéficie d’une amélioration des performances d’écriture grâce aux caches, car le système n’a besoin d’écrire les données que dans le cache. Cependant, une fois que le support sous-jacent est saturé par les opérations d’E/S, le cache se remplit et les performances d’écriture reviennent à la vitesse normale du disque.
- Lorsque vous mettez en cache les E/S en lecture, le cache est le plus utile lorsque vous stockez les données de manière séquentielle sur le disque et que vous permettez au cache de lire en avance. La lecture en avance se produit lorsque le cache peut immédiatement passer au secteur suivant comme si celui-ci contenait les données que le système demandera ensuite.
- Lorsque les E/S en lecture sont aléatoires, la mise en cache au niveau du contrôleur de disque n’augmente pas la quantité de données que le disque peut lire. Si la taille du cache au niveau de l’OS ou de l’application est plus grande que celle du cache matériel, toute tentative d’améliorer la vitesse de lecture du disque ne change rien.
- Dans Active Directory, le cache n’est limité que par la quantité de RAM que le système possède.
Considérations relatives aux disques SSD
Les disques à état solide (SSD) sont fondamentalement différents des disques durs à plateaux. Les SSD peuvent gérer des volumes plus élevés d’E/S avec une latence plus faible. Bien que les SSD puissent être coûteux en termes de coût par gigaoctet, ils sont très bon marché en termes de coût par E/S. Cependant, la planification de la capacité avec les SSD implique de se poser les mêmes questions que pour les disques à plateaux : combien d’IOPS peuvent-ils gérer et quelle est la latence de ces IOPS ?
Voici quelques éléments à prendre en compte lors de la planification des SSD :
- Les IOPS et la latence dépendent des conceptions des fabricants. Dans certains cas, certaines conceptions de SSD peuvent avoir des performances inférieures à celles des technologies à plateaux. Lorsque vous essayez de décider si vous devez utiliser des SSD ou des disques à plateaux, vous devez examiner et valider les spécifications des fabricants pour chaque disque au lieu de supposer que toutes les technologies fonctionnent de la même manière.
- Les types d’IOPS peuvent avoir des valeurs différentes selon qu’il s’agit de lectures ou d’écritures. Les services AD DS sont principalement basés sur la lecture, et sont donc moins affectés par la technologie d’écriture que vous utilisez par rapport à d’autres scénarios d’application.
- L’endurance en écriture est l’hypothèse selon laquelle les cellules des SSD ont une durée de vie limitée et finiront par s’user après de nombreuses utilisations. Pour les disques de base de données, un profil d’E/S principalement en lecture prolonge l’endurance en écriture des cellules au point où vous n’avez pas à vous soucier autant de l’endurance en écriture.
Résumé
Imaginez le stockage comme étant la plomberie intérieure d’une maison. Les IOPS du support dans lequel vous stockez vos données sont comme le drain principal de la maison. Lorsque le drain principal est bouché ou limité par la taille ou l’effondrement du tuyau, les drains se bouchent et ne fonctionnent pas correctement lorsque la maison utilise beaucoup d’eau. Ce scénario est similaire à celui où un environnement partagé a un ou plusieurs systèmes utilisant un stockage partagé sur le même SAN, NAS ou iSCSI avec le même support sous-jacent. Parce que la demande des utilisateurs dépasse la capacité du système à suivre, les performances en souffrent.
De même, dans notre scénario de plomberie imaginaire, vous pouvez adopter différentes approches pour résoudre les obstructions et autres problèmes de performance :
- Pour résoudre un tuyau de drainage effondré ou un drain trop petit, vous devez remplacer les tuyaux par des tuyaux fonctionnels et de la bonne taille. En termes de stockage partagé, cela revient à ajouter du nouveau matériel ou à redistribuer l’utilisation des systèmes partagés dans toute l’infrastructure.
- Déboucher un drain nécessite d’identifier les problèmes sous-jacents et leur emplacement, puis de les supprimer avec l’outil approprié. Par exemple, un bouchon relativement simple dans un drain d’évier de cuisine ne nécessite qu’un plongeur ou un déboucheur pour l’enlever, tandis que des obstructions plus complexes impliquant un objet piégé peuvent nécessiter un furet de plomberie. De même, dans un système de stockage partagé, identifier la cause des problèmes de performance vous aide à déterminer si vous devez créer une sauvegarde au niveau du système, synchroniser les analyses antivirus sur tous les serveurs, ou synchroniser le logiciel de défragmentation que vous exécutez pendant les périodes de pointe.
Dans la plupart des conceptions de plomberie, plusieurs drains alimentent le drain principal. Lorsqu’un drain se bouche, l’eau ne se retrouve piégée que derrière l’endroit où se trouve le bouchon. Si une jonction est bouchée, alors tous les drains situés derrière ce point de jonction cessent de drainer. Dans un scénario de stockage, une jonction bouchée est similaire à un commutateur surchargé, un problème de compatibilité de pilote ou des tâches logicielles non synchronisées. Vous devez mesurer les IOPS et la taille des E/S pour déterminer si votre système de stockage peut supporter la charge, puis ajuster le système si nécessaire.
Appendice D : dépannage du stockage dans des environnements où plus de RAM n’est pas une option
De nombreuses recommandations de stockage avant le stockage virtualisé avaient deux objectifs :
- Isoler les E/S pour éviter que les problèmes de performance sur le disque de l’OS n’affectent les performances de la base de données et les profils d’E/S.
- Tirer parti de l’augmentation des performances que les disques durs à plateaux et les caches peuvent apporter à votre système lorsqu’ils sont utilisés avec les E/S séquentielles des fichiers journaux AD DS. Isoler les E/S séquentielles sur un disque physique séparé peut également augmenter le débit.
Avec les nouvelles options de stockage, de nombreuses hypothèses fondamentales derrière les recommandations de stockage antérieures ne sont plus valables. Les scénarios de stockage virtualisé, tels que iSCSI, SAN, NAS et les fichiers d’image de disque virtuel, partagent souvent le support de stockage sous-jacent entre plusieurs hôtes. Cette différence annule les hypothèses selon lesquelles vous devez isoler les E/S et optimiser les E/S séquentielles. Désormais, d’autres hôtes qui accèdent au support partagé peuvent réduire la réactivité du contrôleur de domaine.
Lorsque vous planifiez la capacité pour les performances du stockage, vous devez tenir compte de trois éléments :
- État du cache froid
- État de cache chaud
- Sauvegarde et restauration
L’état de cache froid se produit lorsque vous redémarrez initialement le contrôleur de domaine ou redémarrez le service Active Directory, donc aucune donnée Active Directory n’est présente dans la RAM. Un état de cache chaud est lorsque le contrôleur de domaine fonctionne en régime stable et a mis en cache la base de données. En termes de conception de performance, réchauffer un cache froid est comme un sprint, tandis que faire fonctionner un serveur avec un cache entièrement réchauffé est comme un marathon. Définir ces états et les différents profils de performance qu’ils induisent est important, car vous devez les prendre en compte tous les deux lors de l’estimation de la capacité. Par exemple, le fait d’avoir suffisamment de RAM pour mettre en cache toute la base de données pendant un état de cache chaud ne vous aide pas à optimiser les performances pendant un état de cache froid.
Pour les deux scénarios de cache, la chose la plus importante est la rapidité avec laquelle le stockage peut déplacer les données du disque vers la mémoire. Lorsque vous réchauffez le cache, au fil du temps, les performances s’améliorent à mesure que les requêtes réutilisent les données, que le taux de succès de cache augmente et que la fréquence d’accès au disque pour récupérer des données diminue. En conséquence, les impacts négatifs sur les performances dus à l’accès au disque diminuent également. Toute dégradation des performances est temporaire et disparaît généralement lorsque le cache atteint son état chaud et la taille maximale que le système permet.
Vous pouvez mesurer la rapidité avec laquelle le système peut obtenir des données du disque en mesurant les IOPS disponibles dans Active Directory. Le nombre d’IOPS disponibles dépend également du nombre d’IOPS disponibles dans le stockage sous-jacent. D’un point de vue planification, étant donné que le réchauffement du cache et les états de sauvegarde ou de restauration sont des événements exceptionnels qui surviennent généralement en dehors des heures de pointe et sont soumis à la charge du contrôleur de domaine, nous ne pouvons pas donner de recommandations générales au-delà de ne passer à ces états qu’en dehors des heures de pointe.
Dans la plupart des scénarios, AD DS est principalement composé de E/S de lecture avec un ratio de 90 % de lecture et 10 % d’écriture. Les E/S de lecture sont le goulot d’étranglement typique pour l’expérience utilisateur, tandis que les E/S d’écriture sont le goulot d’étranglement qui dégrade les performances d’écriture. Les caches tendent à offrir peu d’avantages pour les E/S de lecture car les opérations d’E/S pour le fichier NTDS.dit sont principalement aléatoires. Par conséquent, votre priorité principale est de vous assurer que vous configurez correctement le stockage pour le profil d’E/S de lecture.
Dans des conditions de fonctionnement normales, votre objectif de planification du stockage est de minimiser les temps d’attente pour que le système renvoie les demandes d’AD DS au disque. Le nombre d’opérations d’E/S en attente et en cours doit être inférieur ou égal au nombre de chemins d’accès dans le disque. Pour les scénarios de surveillance des performances, nous recommandons généralement que le compteur LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read soit inférieur à 20 ms. Vous devriez définir le seuil d’exploitation beaucoup plus bas, aussi proche que possible de la vitesse du stockage, dans une plage de deux à six millisecondes selon le type de stockage.
Le graphique linéaire suivant montre la mesure de la latence du disque dans un système de stockage.
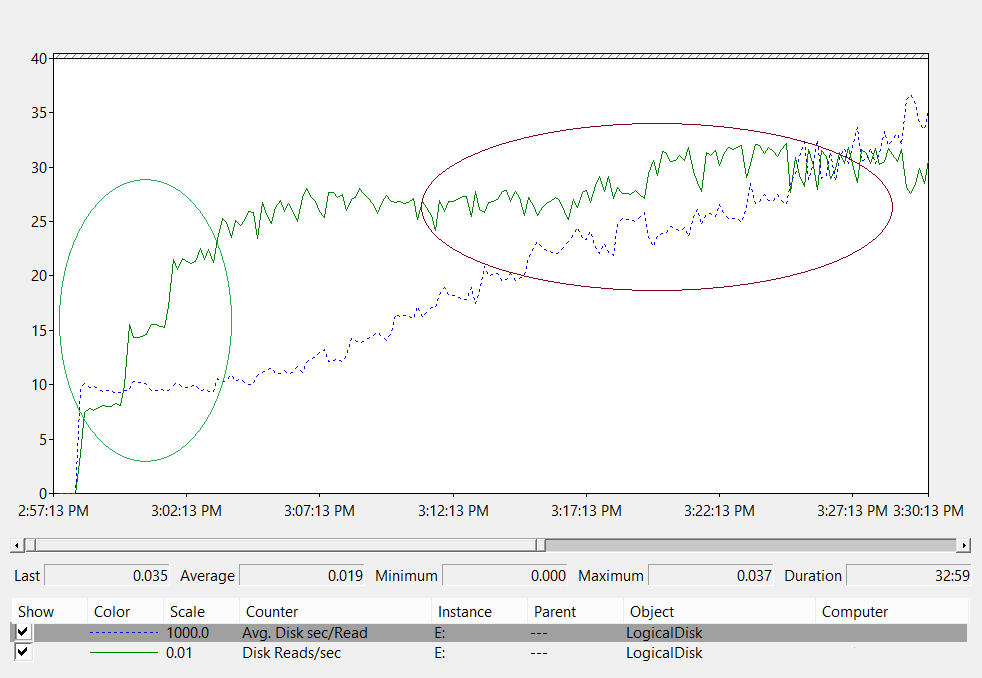
Analysons cette courbe :
- La zone à gauche du graphique entourée en vert montre que la latence est constante à 10 ms lorsque la charge augmente de 800 IOPS à 2 400 IOPS. Cette zone est la référence pour la rapidité avec laquelle le stockage sous-jacent peut traiter une demande d’E/S. Cependant, cette référence est affectée par le type de solution de stockage que vous utilisez.
- La zone sur le côté droit du graphique entourée en marron montre le débit du système entre la référence et la fin de la collecte des données. Le débit lui-même ne change pas, mais la latence augmente. Cette zone démontre comment les demandes passent plus de temps en attente dans la file d’attente pour être envoyées au sous-système de stockage lorsque les volumes de demande dépassent les limites physiques du stockage sous-jacent.
Réfléchissons maintenant à ce que ces données nous disent.
Tout d’abord, supposons qu’un utilisateur qui interroge l’appartenance à un grand groupe exige que le système lise 1 Mo de données du disque. Vous pouvez évaluer la quantité d’E/S requise et la durée des opérations avec ces valeurs :
- La taille de chaque page de base de données Active Directory est de 8 Ko.
- Le nombre minimum de pages que le système doit lire est de 128.
- Par conséquent, dans la zone de référence du diagramme, le système devrait prendre au moins 1,28 seconde pour charger les données du disque et les renvoyer au client. À la marque des 20 ms, où le débit dépasse largement le maximum recommandé, le processus prend 2,5 secondes.
Sur la base de ces chiffres, vous pouvez calculer la rapidité avec laquelle le cache se réchauffera en utilisant cette équation :
2 400 IOPS × 8 Ko par E/S
Après avoir effectué ce calcul, nous pouvons dire que la vitesse de réchauffement du cache dans ce scénario est de 20 Mbits/s. En d’autres termes, le système charge environ 1 Go de base de données dans la RAM toutes les 53 secondes.
Remarque
Il est normal que la latence augmente pendant de courtes périodes lorsque les composants lisent ou écrivent de manière intensive sur le disque. Par exemple, la latence augmente lorsque le système effectue une sauvegarde ou qu’AD DS exécute une collecte des objets inutilisés. Vous devriez prévoir une marge supplémentaire pour ces événements périodiques en plus de vos estimations d’utilisation initiales. Votre objectif est de fournir un débit suffisant pour accommoder ces pics sans affecter le fonctionnement global.
Il existe une limite physique à la vitesse à laquelle le cache se réchauffe en fonction de la façon dont vous concevez le système de stockage. La seule chose qui peut réchauffer le cache à la vitesse que le stockage sous-jacent peut supporter sont les requêtes des clients entrants. Exécuter des scripts pour tenter de préchauffer le cache pendant les heures de pointe entre en concurrence avec les demandes réelles des clients, augmente la charge globale, charge des données non pertinentes pour les demandes des clients et dégrade les performances. Nous vous recommandons d’éviter d’utiliser des mesures artificielles pour réchauffer le cache.