Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Espaces de stockage peut fournir une tolérance de panne pour les données à l’aide de deux techniques fondamentales : miroir et parité. Dans Espaces de stockage direct, ReFS introduit la parité accélérée en miroir, ce qui vous permet de créer des volumes qui utilisent à la fois des résiliences de miroir et de parité. La parité accélérée par miroir offre un stockage peu coûteux et peu encombrant sans sacrifier les performances.
Background
Les schémas de résilience de miroir et de parité ont des caractéristiques de stockage et de performances fondamentalement différentes :
- La résilience miroir permet aux utilisateurs d’atteindre des performances d’écriture rapides, mais la réplication des données pour chaque copie n’est pas efficace en espace.
- La parité, d’autre part, doit ré-calculer la parité pour chaque écriture, ce qui entraîne une détérioration des performances d’écriture aléatoire. Toutefois, la parité permet aux utilisateurs de stocker leurs données avec une plus grande efficacité d’espace. Pour plus d’informations, consultez Espaces de stockage tolérance de panne.
Ainsi, le miroir est prédisposé à fournir un stockage sensible aux performances, tandis que la parité offre une utilisation améliorée de la capacité de stockage. Dans la parité avec accélération miroir, ReFS tire parti des avantages de chaque type de résilience pour fournir un stockage à la fois efficace en capacité et sensible aux performances en combinant les deux schémas de résilience au sein d’un seul volume.
Rotation des données sur la parité avec accélération miroir
ReFS effectue une rotation active des données entre le miroir et la parité, en temps réel. Cela permet aux écritures entrantes d’être rapidement écrites dans la mise en miroir, puis d’effectuer une rotation vers la parité pour être stockées efficacement. Ce faisant, les E/S entrantes sont rapidement effectuées en miroir, tandis que les données froides sont stockées efficacement en parité, offrant des performances optimales et un stockage à coût perdu dans le même volume.
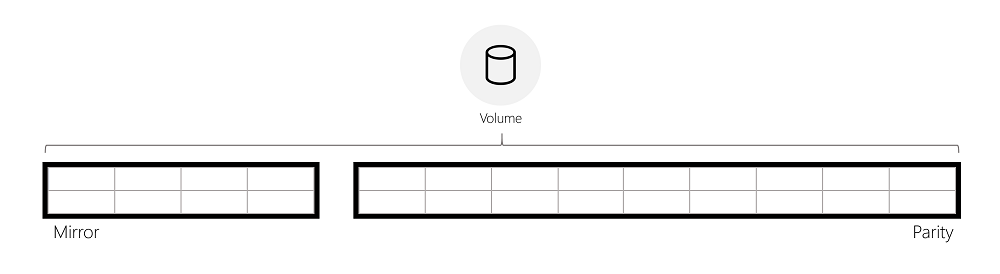
Pour faire pivoter les données entre le miroir et la parité, ReFS divise logiquement le volume en régions de 64 Mio, qui sont l’unité de rotation. L’image ci-dessous illustre un volume de parité accéléré en miroir divisé en régions.
ReFS commence à faire pivoter les régions complètes du miroir vers la parité une fois que le niveau miroir a atteint un niveau de capacité spécifié. Au lieu de déplacer immédiatement les données du miroir vers la parité, ReFS attend et conserve les données en miroir aussi longtemps que possible, ce qui permet à ReFS de continuer à fournir des performances optimales pour les données (voir « Performances d’E/S » ci-dessous).
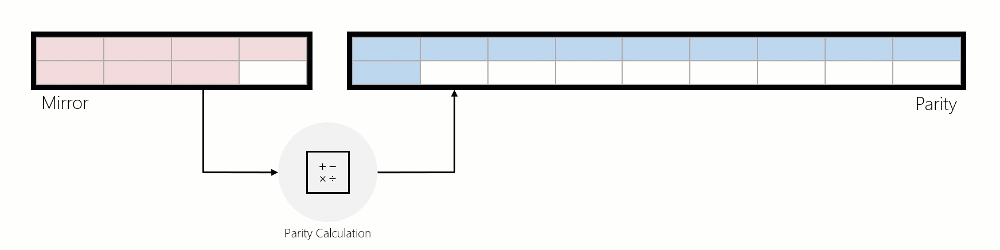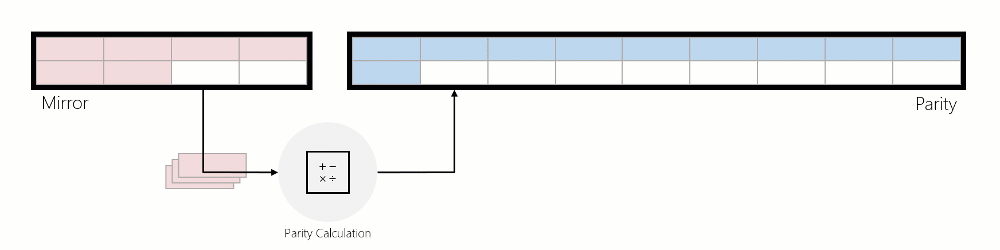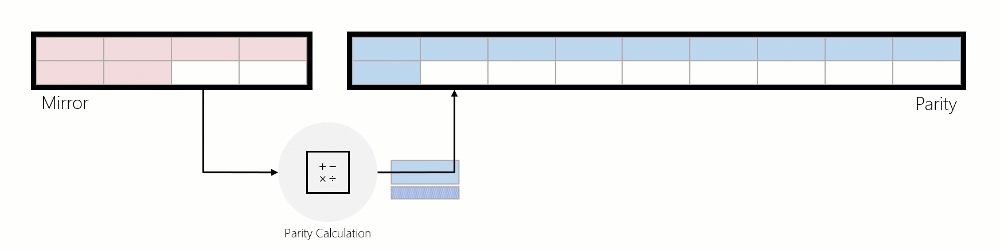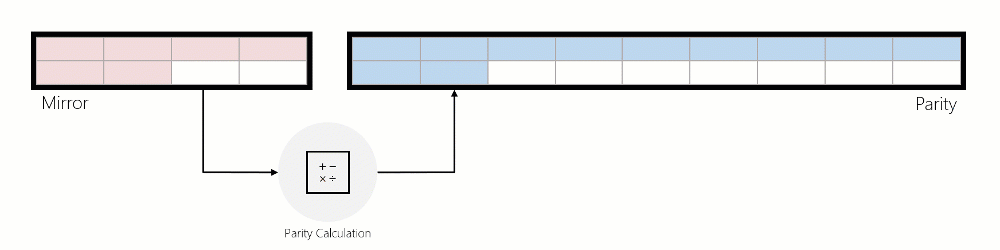
Lorsque les données sont déplacées du miroir vers la parité, les données sont lues, les encodages de parité sont calculés, puis ces données sont écrites en parité. L’animation ci-dessous illustre cela à l’aide d’une région mise en miroir à trois sens qui est convertie en une région codée d’effacement pendant la rotation :
E/S sur la parité avec accélération miroir
IO behavior
Writes: ReFS services incoming writes in three distinct ways:
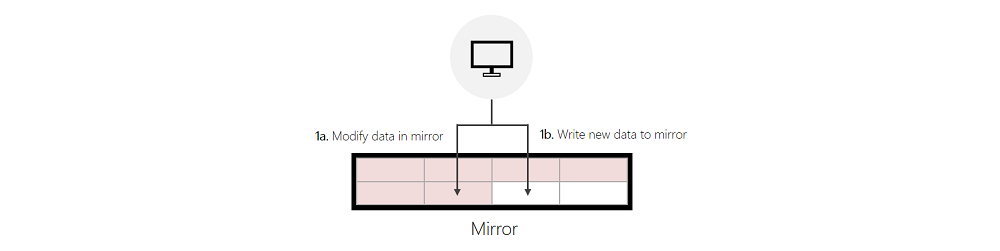
Écrit dans le miroir :
- 1a. Si l’écriture entrante modifie les données existantes en miroir, ReFS modifie les données en place.
- 1b. Si l’écriture entrante est une nouvelle écriture et que ReFS peut trouver suffisamment d’espace libre dans le miroir pour traiter cette écriture, ReFS écrit dans la mise en miroir.
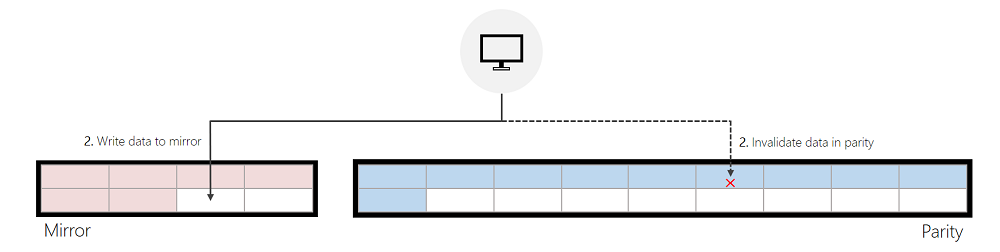
Écrit dans le miroir, réalloué à partir de Parité :
Si l’écriture entrante modifie les données en parité et que ReFS peut trouver suffisamment d’espace libre dans le miroir pour traiter l’écriture entrante, ReFS invalide d’abord les données précédentes en parité, puis écrit dans la mise en miroir. Cette invalidation est une opération de métadonnées rapide et peu coûteuse qui permet d’améliorer significativement les performances d’écriture par rapport à la parité.
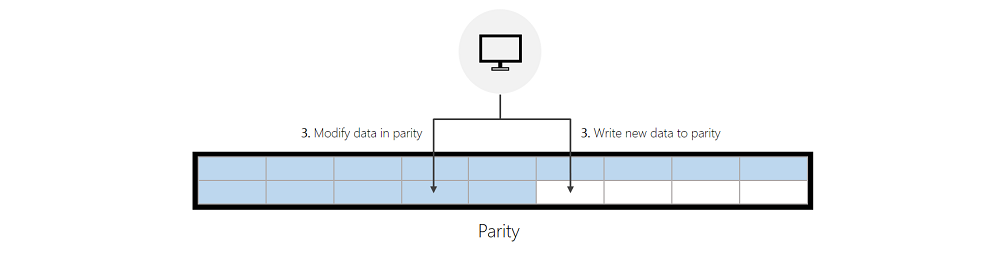
Écrit dans Parité :
Si ReFS ne parvient pas à trouver suffisamment d’espace libre dans le miroir, ReFS écrit de nouvelles données dans la parité ou modifie directement les données existantes en parité. La section « Optimisations des performances » ci-dessous fournit des conseils qui permettent de réduire les écritures sur la parité.
Reads: ReFS will read directly from the tier containing the relevant data. Si la parité est construite avec des disques durs, le cache dans espaces de stockage direct met en cache ces données pour accélérer les lectures futures.
Note
Les lectures n’obligent jamais ReFS à faire pivoter les données dans le niveau miroir.
IO performance
Writes: Each type of write described above has its own performance characteristics. En gros, les écritures dans le niveau miroir sont beaucoup plus rapides que les écritures réallouées, et les écritures réaffectées sont considérablement plus rapides que les écritures effectuées directement au niveau de parité. Cette relation est illustrée par l’inégalité ci-dessous :
- Niveau de parité d’écritures > réalloués de niveau >> miroir
Reads: There is no meaningful, negative performance impact when reading from parity:
- Si le miroir et la parité sont construits avec le même type de média, les performances de lecture sont équivalentes.
- Si le miroir et la parité sont construits avec différents types de supports (disques SSD mis en miroir, disques durs par parité, par exemple), le cache dans espaces de stockage direct permet de mettre en cache les données chaudes pour accélérer les lectures à partir de la parité.
ReFS compaction
Le compactage pour ReFS est disponible avec Windows Server 2019 et versions ultérieures, ce qui améliore considérablement les performances pour les volumes de parité accélérés en miroir qui sont complets à plus de 90 %.
Background: Previously, as mirror-accelerated parity volumes became full, the performance of these volumes could degrade. Les performances se dégradent, car les données chaudes et froides sont mélangées tout au long du volume en temps supplémentaire. Cela signifie que moins de données chaudes peuvent être stockées dans un miroir, car les données froides occupent de l’espace dans le miroir qui pourrait autrement être utilisé par les données chaudes. Le stockage de données chaudes dans le miroir est essentiel pour maintenir des performances élevées, car les écritures directes dans le miroir sont beaucoup plus rapides que les écritures réallouées et les ordres de grandeur sont plus rapides que les écritures directement sur la parité. Par conséquent, le fait d’avoir des données froides en miroir est mauvais pour les performances, car cela réduit la probabilité que ReFS puisse effectuer des écritures directement dans la mise en miroir.
Le compactage ReFS résout ces problèmes de performances en libérant de l’espace dans le miroir pour les données à chaud. Le compactage regroupe d’abord toutes les données, du miroir et de la parité, à la parité. Cela réduit la fragmentation au sein du volume et augmente la quantité d’espace adressable dans le miroir. Plus important encore, ce processus permet à ReFS de consolider les données chaudes dans le miroir :
- Lorsque de nouvelles écritures arrivent, elles sont mises en miroir. Ainsi, les données à chaud nouvellement écrites résident dans le miroir.
- Lorsqu’une écriture de modification est effectuée sur des données en parité, ReFS effectue une écriture réaffectée, de sorte que cette écriture est également mise en miroir. Par conséquent, les données à chaud qui ont été déplacées vers la parité pendant le compactage seront réaffectées en miroir.
Performance optimizations
Important
Nous vous recommandons de placer des disques durs virtuels lourds en écriture dans différents sous-répertoires. Cela est dû au fait que ReFS écrit des modifications de métadonnées au niveau d’un répertoire et de ses fichiers. Par conséquent, si vous distribuez des fichiers lourds en écriture entre les répertoires, les opérations de métadonnées sont plus petites et s’exécutent en parallèle, ce qui réduit la latence pour les applications.
Performance counters
ReFS gère les compteurs de performances pour aider à évaluer les performances de la parité avec accélération miroir.
Comme décrit ci-dessus dans la section Écrire en parité, ReFS écrit directement dans la parité lorsqu’il ne trouve pas d’espace libre dans le miroir. En règle générale, cela se produit lorsque le niveau mis en miroir se remplit plus rapidement que ReFS peut faire pivoter les données vers la parité. En d’autres termes, la rotation ReFS n’est pas en mesure de suivre le taux d’ingestion. Les compteurs de performances ci-dessous identifient quand ReFS écrit directement dans la parité :
# Windows Server 2016 ReFS\Data allocations slow tier/sec ReFS\Metadata allocations slow tier/sec # Windows Server 2019 ReFS\Allocation of Data Clusters on Slow Tier/sec ReFS\Allocation of Metadata Clusters on Slow Tier/secSi ces compteurs ne sont pas nuls, cela indique que ReFS ne fait pas pivoter les données assez rapidement hors du miroir. Pour atténuer ce problème, vous pouvez modifier l’agressivité de la rotation ou augmenter la taille du niveau mis en miroir.
Rotation aggressiveness
ReFS commence la rotation des données une fois que le miroir a atteint un seuil de capacité spécifié.
- Les valeurs plus élevées de ce seuil de rotation permettent à ReFS de conserver les données dans le niveau miroir plus longtemps. Laisser des données à chaud au niveau miroir est optimal pour les performances, mais ReFS ne pourra pas traiter efficacement de grandes quantités d’E/S entrantes.
- Des valeurs inférieures permettent à ReFS de démonter de manière proactive les données et de mieux ingérer les E/S entrantes. Cela s’applique aux charges de travail ingérées, telles que le stockage d’archivage. Toutefois, des valeurs inférieures peuvent dégrader les performances des charges de travail à usage général. La rotation inutile des données hors du niveau miroir entraîne une pénalité de performances.
ReFS introduit un paramètre paramétrable pour ajuster ce seuil, qui est configurable à l’aide d’une clé de Registre. Cette clé de registre doit être configurée sur chaque nœud d’un déploiement Espaces de stockage direct, et un redémarrage est nécessaire pour que les modifications prennent effet.
- Key: HKEY_LOCAL_MACHINE\System\CurrentControlSet\Policies
- ValueName (DWORD): DataDestageSsdFillRatioThreshold
- ValueType: Percentage
Si cette clé de Registre n’est pas définie, ReFS utilise une valeur par défaut de 85 %. Cette valeur par défaut est recommandée pour la plupart des déploiements et les valeurs inférieures à 50 % ne sont pas recommandées. La commande PowerShell ci-dessous montre comment définir cette clé de Registre avec une valeur de 75 % :
Set-ItemProperty -Path HKLM:\SYSTEM\CurrentControlSet\Policies -Name DataDestageSsdFillRatioThreshold -Value 75
Pour configurer cette clé de registre sur chaque nœud d’un déploiement espaces de stockage direct, vous pouvez utiliser la commande PowerShell ci-dessous :
$Nodes = 'S2D-01', 'S2D-02', 'S2D-03', 'S2D-04'
Invoke-Command $Nodes {Set-ItemProperty -Path HKLM:\SYSTEM\CurrentControlSet\Policies -Name DataDestageSsdFillRatioThreshold -Value 75}
Augmentation de la taille du niveau mis en miroir
L’augmentation de la taille du niveau mis en miroir permet à ReFS de conserver une plus grande partie du jeu de travail dans la mise en miroir. Cela améliore la probabilité que ReFS puisse écrire directement dans la mise en miroir, ce qui permet d’obtenir de meilleures performances. Les applets de commande PowerShell ci-dessous montrent comment augmenter la taille du niveau mis en miroir :
Resize-StorageTier -FriendlyName "Performance" -Size 20GB
Resize-StorageTier -InputObject (Get-StorageTier -FriendlyName "Performance") -Size 20GB
Tip
Make sure to resize the Partition and Volume after you resize the StorageTier. Pour plus d’informations et d’exemples, consultez Étendre un volume de base.
Créer un volume paritaire avec accélération par miroir
L’applet de commande PowerShell ci-dessous crée un volume de parité accéléré en miroir avec un ratio Miroir:Parité de 20:80, qui est la configuration recommandée pour la plupart des charges de travail. Pour plus d’informations et d’exemples, consultez Création de volumes dans Espaces de stockage direct.
New-Volume -FriendlyName "TestVolume" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName "StoragePoolName" -StorageTierFriendlyNames Performance, Capacity -StorageTierSizes 200GB, 800GB