Structure DML_MULTIHEAD_ATTENTION_OPERATOR_DESC (directml.h)
Effectue une opération d’attention multi-tête (pour plus d’informations, voir Attention is all you need). Exactement un tenseur de Requête, un tenseur de Clé et un tenseur de Valeur doivent être présents, qu’ils soient empilés ou non. Par exemple, si StackedQueryKey est fourni, les tenseurs Requête et Clé doivent être nuls, car ils sont déjà fournis dans une disposition de pile. Il en va de même pour StackedKeyValue et StackedQueryKeyValue. Les tenseurs empilés ont toujours cinq dimensions et sont toujours empilés sur la quatrième dimension.
Logiquement, l’algorithme peut être décomposé dans les opérations suivantes (les opérations entre crochets sont facultatives) :
[Add Bias to query/key/value] -> GEMM(Query, Transposed(Key)) * Scale -> [Add RelativePositionBias] -> [Add Mask] -> Softmax -> GEMM(SoftmaxResult, Value);
Important
Cette API est disponible dans le cadre du package redistribuable autonome DirectML (voir Microsoft.AI.DirectML version 1.12 et ultérieures). Consultez également l’historique des versions DirectML.
Syntaxe
struct DML_MULTIHEAD_ATTENTION_OPERATOR_DESC
{
_Maybenull_ const DML_TENSOR_DESC* QueryTensor;
_Maybenull_ const DML_TENSOR_DESC* KeyTensor;
_Maybenull_ const DML_TENSOR_DESC* ValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* BiasTensor;
_Maybenull_ const DML_TENSOR_DESC* MaskTensor;
_Maybenull_ const DML_TENSOR_DESC* RelativePositionBiasTensor;
_Maybenull_ const DML_TENSOR_DESC* PastKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* PastValueTensor;
const DML_TENSOR_DESC* OutputTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentValueTensor;
FLOAT Scale;
FLOAT MaskFilterValue;
UINT HeadCount;
DML_MULTIHEAD_ATTENTION_MASK_TYPE MaskType;
};
Membres
QueryTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Interroger avec la forme [batchSize, sequenceLength, hiddenSize], où hiddenSize = headCount * headSize. Ce tenseur est mutuellement exclusif avec StackedQueryKeyTensor et StackedQueryKeyValueTensor. Le tenseur peut également avoir 4 ou 5 dimensions, tant que les dimensions de début sont des 1.
KeyTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Clé avec forme [batchSize, keyValueSequenceLength, hiddenSize], où hiddenSize = headCount * headSize. Ce tenseur est mutuellement exclusif avec StackedQueryKeyTensor, StackedQueryKeyValueTensor et StackedQueryKeyValueTensor. Le tenseur peut également avoir 4 ou 5 dimensions, tant que les dimensions de début sont des 1.
ValueTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Valeur avec forme [batchSize, keyValueSequenceLength, valueHiddenSize], où valueHiddenSize = headCount * valueHeadSize. Ce tenseur est mutuellement exclusif avec StackedKeyValueTensor et StackedQueryKeyValueTensor. Le tenseur peut également avoir 4 ou 5 dimensions, tant que les dimensions de début sont des 1.
StackedQueryKeyTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Requête et clé empilées avec forme [batchSize, sequenceLength, headCount, 2, headSize]. Ce tenseur est mutuellement exclusif avec QueryTensor, KeyTensor, StackedKeyValueTensor et StackedQueryKeyValueTensor.
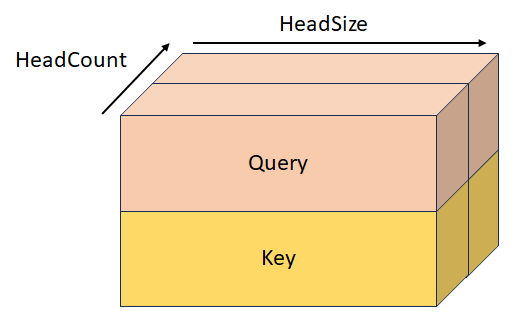
StackedKeyValueTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Clé empilée et valeur avec la forme [batchSize, keyValueSequenceLength, headCount, 2, headSize]. Ce tenseur est mutuellement exclusif avec KeyTensor, ValueTensor, StackedQueryKeyTensor et StackedQueryKeyValueTensor.
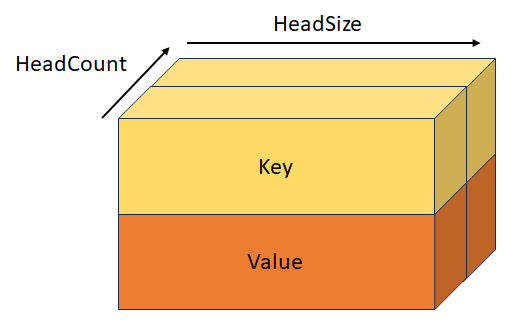
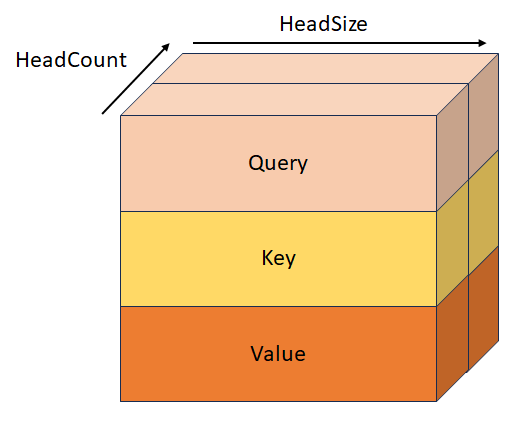
StackedQueryKeyValueTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Requête, clé et valeur empilées avec la forme [batchSize, sequenceLength, headCount, 3, headSize]. Ce tenseur est mutuellement exclusif avec QueryTensor, KeyTensor, ValueTensor, StackedQueryKeyTensor et StackedKeyValueTensor.
BiasTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Il s’agit du biais, de forme [hiddenSize + hiddenSize + valueHiddenSize], qui est ajouté à Query/Key/Value avant la première opération GEMM. Ce tenseur peut également avoir 2, 3, 4 ou 5 dimensions, tant que les dimensions de début sont des 1.
MaskTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Il s’agit du masque qui détermine quels éléments voient leur valeur définie sur MaskFilterValue après l’opération GEMM QxK. Le comportement de ce masque dépend de la valeur de MaskType et est appliqué après RelativePositionBiasTensor ou après la première opération GEMM si RelativePositionBiasTensor est nul. Voir la définition de MaskType pour plus d’informations.
RelativePositionBiasTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Il s’agit du biais qui est ajouté au résultat de la première opération GEMM.
PastKeyTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Tenseur de clé de l’itération précédente avec la forme [batchSize, headCount, pastSequenceLength, headSize]. Quand ce tenseur n’est pas nul, il est concaténé avec le tenseur de clé, ce qui entraîne un tenseur de forme [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
PastValueTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
Tenseur de valeur de l’itération précédente avec la forme [batchSize, headCount, pastSequenceLength, headSize]. Quand ce tenseur n’est pas nul, il est concaténé avec ValueDesc, ce qui entraîne un tenseur de forme [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
OutputTensor
Type : const DML_TENSOR_DESC*
Sortie, de forme [batchSize, sequenceLength, valueHiddenSize].
OutputPresentKeyTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
État présent pour la clé cross attention, avec la forme [batchSize, headCount, keyValueSequenceLength, headSize] ou état présent pour la self-attention avec la forme [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Il contient le contenu du tenseur de clé ou le contenu du tenseur concaténé PastKey + Key à passer à l’itération suivante.
OutputPresentValueTensor
Type : _Maybenull_ const DML_TENSOR_DESC*
État présent pour la valeur de la cross attention, avec la forme [batchSize, headCount, keyValueSequenceLength, headSize] ou état présent pour la self-attention avec la forme [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Il contient le contenu du tenseur de clé ou le contenu du tenseur concaténé PastValue + Value à passer à l’itération suivante.
Scale
Type : FLOAT
Effectuez une mise à l’échelle pour multiplier le résultat de l’opération GEMM QxK, mais effectuez-la avant l’opération Softmax. Cette valeur est généralement de 1/sqrt(headSize).
MaskFilterValue
Type : FLOAT
Valeur ajoutée au résultat de l’opération GEMM QxK aux positions définies par le masque en tant qu’éléments de remplissage. Cette valeur doit être un très grand nombre négatif (généralement -10000.0f).
HeadCount
Type : UINT
Nombre de têtes d’attention.
MaskType
Type : DML_MULTIHEAD_ATTENTION_MASK_TYPE
Décrit le comportement de MaskTensor.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_BOOLEAN. Lorsque le masque contient une valeur de 0, MaskFilterValue est ajouté. Cependant, lorsqu’il contient une valeur de 1, rien n’est ajouté.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_LENGTH. Le masque, de la forme [1, batchSize], contient les longueurs de séquence de la zone non remplie pour chaque lot. Tous les éléments après la longueur de séquence voient leur valeur définie sur MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_END_START. Le masque, de la forme [2, batchSize], contient les index de fin (exclus) et de début (inclus) de la zone non remplie. Tous les éléments en dehors de la zone voient leur valeur définie sur MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_QUERY_SEQUENCE_LENGTH_START_END. Le masque, de forme [batchSize * 3 + 2], contient les valeurs suivantes : [keyLength[0], ..., keyLength[batchSize - 1], queryStart[0], ..., queryStart[batchSize - 1], queryEnd[batchSize - 1], keyStart[0], ..., keyStart[batchSize - 1], keyEnd[batchSize - 1]].
Disponibilité
Cet opérateur a été introduit dans DML_FEATURE_LEVEL_6_1.
Contraintes de tenseur
BiasTensor, KeyTensor, OutputPresentKeyTensor, OutputPresentValueTensor, OutputTensor, PastKeyTensor, PastValueTensor, QueryTensor, RelativePositionBiasTensor, StackedKeyValueTensor, StackedQueryKeyTensor, StackedQueryKeyValueTensor et ValueTensor doivent avoir le même DataType.
Prise en charge des tenseurs
| Tenseur | Genre | Nombre de dimensions pris en charge | Types de données pris en charge |
|---|---|---|---|
| QueryTensor | Entrée facultative | De 3 à 5 | FLOAT32, FLOAT16 |
| KeyTensor | Entrée facultative | De 3 à 5 | FLOAT32, FLOAT16 |
| ValueTensor | Entrée facultative | De 3 à 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyTensor | Entrée facultative | 5 | FLOAT32, FLOAT16 |
| StackedKeyValueTensor | Entrée facultative | 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyValueTensor | Entrée facultative | 5 | FLOAT32, FLOAT16 |
| BiasTensor | Entrée facultative | 1 à 5 | FLOAT32, FLOAT16 |
| MaskTensor | Entrée facultative | 1 à 5 | INT32 |
| RelativePositionBiasTensor | Entrée facultative | 4 à 5 | FLOAT32, FLOAT16 |
| PastKeyTensor | Entrée facultative | 4 à 5 | FLOAT32, FLOAT16 |
| PastValueTensor | Entrée facultative | 4 à 5 | FLOAT32, FLOAT16 |
| OutputTensor | Sortie | De 3 à 5 | FLOAT32, FLOAT16 |
| OutputPresentKeyTensor | Sortie facultative | 4 à 5 | FLOAT32, FLOAT16 |
| OutputPresentValueTensor | Sortie facultative | 4 à 5 | FLOAT32, FLOAT16 |
Spécifications
| En-tête | directml.h |
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour