Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Utilisez la reconnaissance vocale pour fournir une entrée, spécifier une action ou une commande et accomplir des tâches.
APIs importantes : Windows.Media.SpeechRecognition
La reconnaissance vocale est constituée d’un runtime de reconnaissance vocale, d’API de reconnaissance pour la programmation du runtime, de grammaires prêtes à l’emploi pour la dictée et la recherche web, ainsi qu’une interface utilisateur système par défaut qui permet aux utilisateurs de découvrir et d’utiliser des fonctionnalités de reconnaissance vocale.
Configurer la reconnaissance vocale
Pour prendre en charge la reconnaissance vocale avec votre application, l’utilisateur doit se connecter et activer un microphone sur son appareil et accepter l’autorisation d’octroi de la politique de confidentialité Microsoft pour que votre application l’utilise.
Pour demander automatiquement à l'utilisateur l'autorisation d'accéder au flux audio du microphone par une boîte de dialogue système (par exemple, à partir de l'exemple reconnaissance vocale et synthèse vocale indiqué ci-dessous), il suffit de définir la fonctionnalité Microphonede l'appareil dans le manifeste du package App. Pour plus d’informations, consultez les déclarations de fonctionnalités d’application.

Si l’utilisateur clique sur Oui pour accorder l’accès au microphone, votre application est ajoutée à la liste des applications approuvées dans la page Paramètres -> Confidentialité -> Microphone. Toutefois, comme l’utilisateur peut choisir de désactiver ce paramètre à tout moment, vous devez confirmer que votre application a accès au microphone avant de tenter de l’utiliser.
Si vous souhaitez également prendre en charge la dictée, Cortana ou d’autres services de reconnaissance vocale (par exemple, une grammaire prédéfinie définie dans une contrainte de rubrique), vous devez également confirmer que la reconnaissance vocale en ligne (Paramètres -> Confidentialité -> Reconnaissance vocale) est activée.
Cet extrait de code montre comment votre application peut vérifier si un microphone est présent et s’il est autorisé à l’utiliser.
public class AudioCapturePermissions
{
// If no microphone is present, an exception is thrown with the following HResult value.
private static int NoCaptureDevicesHResult = -1072845856;
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
public async static Task<bool> RequestMicrophonePermission()
{
try
{
// Request access to the audio capture device.
MediaCaptureInitializationSettings settings = new MediaCaptureInitializationSettings();
settings.StreamingCaptureMode = StreamingCaptureMode.Audio;
settings.MediaCategory = MediaCategory.Speech;
MediaCapture capture = new MediaCapture();
await capture.InitializeAsync(settings);
}
catch (TypeLoadException)
{
// Thrown when a media player is not available.
var messageDialog = new Windows.UI.Popups.MessageDialog("Media player components are unavailable.");
await messageDialog.ShowAsync();
return false;
}
catch (UnauthorizedAccessException)
{
// Thrown when permission to use the audio capture device is denied.
// If this occurs, show an error or disable recognition functionality.
return false;
}
catch (Exception exception)
{
// Thrown when an audio capture device is not present.
if (exception.HResult == NoCaptureDevicesHResult)
{
var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system.");
await messageDialog.ShowAsync();
return false;
}
else
{
throw;
}
}
return true;
}
}
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
IAsyncOperation<bool>^ AudioCapturePermissions::RequestMicrophonePermissionAsync()
{
return create_async([]()
{
try
{
// Request access to the audio capture device.
MediaCaptureInitializationSettings^ settings = ref new MediaCaptureInitializationSettings();
settings->StreamingCaptureMode = StreamingCaptureMode::Audio;
settings->MediaCategory = MediaCategory::Speech;
MediaCapture^ capture = ref new MediaCapture();
return create_task(capture->InitializeAsync(settings))
.then([](task<void> previousTask) -> bool
{
try
{
previousTask.get();
}
catch (AccessDeniedException^)
{
// Thrown when permission to use the audio capture device is denied.
// If this occurs, show an error or disable recognition functionality.
return false;
}
catch (Exception^ exception)
{
// Thrown when an audio capture device is not present.
if (exception->HResult == AudioCapturePermissions::NoCaptureDevicesHResult)
{
auto messageDialog = ref new Windows::UI::Popups::MessageDialog("No Audio Capture devices are present on this system.");
create_task(messageDialog->ShowAsync());
return false;
}
throw;
}
return true;
});
}
catch (Platform::ClassNotRegisteredException^ ex)
{
// Thrown when a media player is not available.
auto messageDialog = ref new Windows::UI::Popups::MessageDialog("Media Player Components unavailable.");
create_task(messageDialog->ShowAsync());
return create_task([] {return false; });
}
});
}
var AudioCapturePermissions = WinJS.Class.define(
function () { }, {},
{
requestMicrophonePermission: function () {
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
return new WinJS.Promise(function (completed, error) {
try {
// Request access to the audio capture device.
var captureSettings = new Windows.Media.Capture.MediaCaptureInitializationSettings();
captureSettings.streamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.audio;
captureSettings.mediaCategory = Windows.Media.Capture.MediaCategory.speech;
var capture = new Windows.Media.Capture.MediaCapture();
capture.initializeAsync(captureSettings).then(function () {
completed(true);
},
function (error) {
// Audio Capture can fail to initialize if there's no audio devices on the system, or if
// the user has disabled permission to access the microphone in the Privacy settings.
if (error.number == -2147024891) { // Access denied (microphone disabled in settings)
completed(false);
} else if (error.number == -1072845856) { // No recording device present.
var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system.");
messageDialog.showAsync();
completed(false);
} else {
error(error);
}
});
} catch (exception) {
if (exception.number == -2147221164) { // REGDB_E_CLASSNOTREG
var messageDialog = new Windows.UI.Popups.MessageDialog("Media Player components not available on this system.");
messageDialog.showAsync();
return false;
}
}
});
}
})
Reconnaître l’entrée vocale
Une contrainte définit les mots et expressions (vocabulaire) qu’une application reconnaît dans l’entrée vocale. Les contraintes sont au cœur de la reconnaissance vocale et donnent à votre application un meilleur contrôle sur la précision de la reconnaissance vocale.
Vous pouvez utiliser les types de contraintes suivants pour reconnaître l’entrée vocale.
Grammaires prédéfinies
Les grammaires de dictée et de recherche web prédéfinies fournissent une reconnaissance vocale pour votre application sans avoir à créer une grammaire. Lorsque vous utilisez ces grammaires, la reconnaissance vocale est effectuée par un service web distant et les résultats sont retournés à l’appareil.
La grammaire de dictée de texte libre par défaut peut reconnaître la plupart des mots et expressions qu’un utilisateur peut dire dans une langue particulière et est optimisé pour reconnaître les phrases courtes. La grammaire de dictée prédéfinie est utilisée si vous ne spécifiez aucune contrainte pour votre objet SpeechRecognizer. La dictée en texte libre est utile lorsque vous ne souhaitez pas limiter les types de choses qu’un utilisateur peut dire. Les utilisations classiques incluent la création de notes ou la dictée du contenu d’un message.
La grammaire de recherche web, comme une grammaire de dictée, contient un grand nombre de mots et d’expressions qu’un utilisateur peut dire. Toutefois, il est optimisé pour reconnaître les termes que les utilisateurs utilisent généralement lors de la recherche sur le web.
Note
Étant donné que les grammaires de dictée et de recherche web prédéfinies peuvent être volumineuses et parce qu’elles sont en ligne (pas sur l’appareil), les performances peuvent ne pas être aussi rapides qu’avec une grammaire personnalisée installée sur l’appareil.
Ces grammaires prédéfinies peuvent être utilisées pour reconnaître jusqu’à 10 secondes d’entrée vocale et ne nécessitent aucun effort de création de votre part. Toutefois, ils nécessitent une connexion à un réseau.
Pour utiliser des contraintes de service web, la prise en charge de l’entrée vocale et de la dictée doit être activée dans Paramètres en activant l’option « Me connaître » dans Paramètres -> Confidentialité -> Reconnaissance vocale, entrée manuscrite et saisie.
Ici, nous montrons comment tester si l’entrée vocale est activée et ouvrir les paramètres -> Confidentialité -> Reconnaissance vocale, entrée manuscrite et page de saisie, si ce n’est pas le cas.
Tout d’abord, nous initialisons une variable globale (HResultPrivacyStatementDeclined) à la valeur HResult de 0x80045509. Consultez la gestion des exceptions en C# ou Visual Basic.
private static uint HResultPrivacyStatementDeclined = 0x80045509;
Nous interceptons ensuite toutes les exceptions standard lors de la reconnaissance et testons si la valeur HResult est égale à la valeur de la variable HResultPrivacyStatementDeclined. Dans ce cas, nous affichons un avertissement et appelons await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts")); pour ouvrir la page Paramètres.
catch (Exception exception)
{
// Handle the speech privacy policy error.
if ((uint)exception.HResult == HResultPrivacyStatementDeclined)
{
resultTextBlock.Visibility = Visibility.Visible;
resultTextBlock.Text = "The privacy statement was declined." +
"Go to Settings -> Privacy -> Speech, inking and typing, and ensure you" +
"have viewed the privacy policy, and 'Get To Know You' is enabled.";
// Open the privacy/speech, inking, and typing settings page.
await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts"));
}
else
{
var messageDialog = new Windows.UI.Popups.MessageDialog(exception.Message, "Exception");
await messageDialog.ShowAsync();
}
}
Voir SpeechRecognitionTopicConstraint.
Contraintes de liste programmatique
Les contraintes de liste programmatique offrent une approche légère pour créer des grammaires simples à l’aide d’une liste de mots ou d’expressions. Une contrainte de liste fonctionne bien pour reconnaître des expressions courtes et distinctes. La spécification explicite de tous les mots d’une grammaire améliore également la précision de la reconnaissance, car le moteur de reconnaissance vocale ne doit traiter que la voix pour confirmer une correspondance. La liste peut également être mise à jour par programmation.
Une contrainte de liste se compose d’un tableau de chaînes qui représente l’entrée vocale que votre application accepte pour une opération de reconnaissance. Vous pouvez créer une contrainte de liste dans votre application en créant un objet de contrainte de liste de reconnaissance vocale et en passant un tableau de chaînes. Ensuite, ajoutez cet objet à la collection de contraintes du module de reconnaissance. La reconnaissance réussit lorsque le module de reconnaissance vocale reconnaît l’une des chaînes du tableau.
Voir SpeechRecognitionListConstraint.
Grammaires SRGS
Une grammaire SRGS (Speech Recognition Grammar Specification) est un document statique qui, contrairement à une contrainte de liste programmatique, utilise le format XML défini par la version 1.0 de SRGS. Une grammaire SRGS offre le meilleur contrôle de l’expérience de reconnaissance vocale en vous permettant de capturer plusieurs significations sémantiques dans une seule reconnaissance.
Voir SpeechRecognitionGrammarFileConstraint.
Contraintes de commande vocale
Utilisez un fichier XML VCD (Voice Command Definition) pour définir les commandes que l’utilisateur peut dire pour lancer des actions lors de l’activation de votre application. Voir SpeechRecognitionVoiceCommandDefinitionConstraint.
Note Le type de contrainte que vous utilisez dépend de la complexité de l’expérience de reconnaissance que vous souhaitez créer. Tout peut être le meilleur choix pour une tâche de reconnaissance spécifique, et vous pouvez trouver des utilisations pour tous les types de contraintes dans votre application.
Pour commencer à utiliser des contraintes, consultez Définir des contraintes de reconnaissance personnalisée.
La grammaire de dictée universelle Windows prédéfinie reconnaît la plupart des mots et des phrases courtes dans une langue. Il est activé par défaut lorsqu’un objet de reconnaissance vocale est instancié sans contraintes personnalisées.
Dans cet exemple, nous montrons comment :
- Créez un module de reconnaissance vocale.
- Compilez les contraintes d'application de Windows universelle par défaut (aucune grammaire n'a été ajoutée au jeu de grammaires du module de reconnaissance vocale).
- Commencez à écouter la voix à l’aide de l’interface utilisateur de reconnaissance de base et des commentaires TTS fournis par la méthode RecognizeWithUIAsync . Utilisez la méthode RecognizeAsync si l’interface utilisateur par défaut n’est pas requise.
private async void StartRecognizing_Click(object sender, RoutedEventArgs e)
{
// Create an instance of SpeechRecognizer.
var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer();
// Compile the dictation grammar by default.
await speechRecognizer.CompileConstraintsAsync();
// Start recognition.
Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync();
// Do something with the recognition result.
var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken");
await messageDialog.ShowAsync();
}
Personnaliser l’interface utilisateur de reconnaissance
Lorsque votre application tente la reconnaissance vocale en appelant SpeechRecognizer.RecognizeWithUIAsync, plusieurs écrans sont affichés dans l’ordre suivant.
Si vous utilisez une contrainte basée sur une grammaire prédéfinie (dictée ou recherche web) :
- Écran d’écoute .
- Écran Réflexion .
- L’écran « Heard you say » ou l’écran d’erreur.
Si vous utilisez une contrainte basée sur une liste de mots ou d’expressions, ou une contrainte basée sur un fichier de grammaire SRGS :
- Écran d’écoute .
- L’écran Did you say, si ce que l’utilisateur a dit pourrait être interprété comme plusieurs résultats potentiels.
- L’écran « Heard you say » ou l’écran d’erreur.
L’image suivante montre un exemple de flux entre les écrans d’un module de reconnaissance vocale qui utilise une contrainte basée sur un fichier de grammaire SRGS. Dans cet exemple, la reconnaissance vocale a réussi.
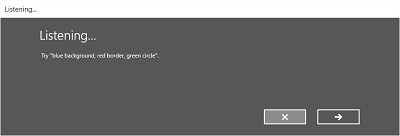
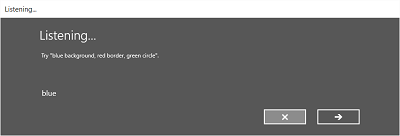
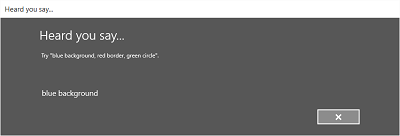
L’écran d’écoute peut fournir des exemples de mots ou d’expressions que l’application peut reconnaître. Ici, nous montrons comment utiliser les propriétés de la classe SpeechRecognizerUIOptions (obtenue en appelant la classe SpeechRecognizer.UIOptions propriété) pour personnaliser le contenu sur l’écran Listening.
private async void WeatherSearch_Click(object sender, RoutedEventArgs e)
{
// Create an instance of SpeechRecognizer.
var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer();
// Listen for audio input issues.
speechRecognizer.RecognitionQualityDegrading += speechRecognizer_RecognitionQualityDegrading;
// Add a web search grammar to the recognizer.
var webSearchGrammar = new Windows.Media.SpeechRecognition.SpeechRecognitionTopicConstraint(Windows.Media.SpeechRecognition.SpeechRecognitionScenario.WebSearch, "webSearch");
speechRecognizer.UIOptions.AudiblePrompt = "Say what you want to search for...";
speechRecognizer.UIOptions.ExampleText = @"Ex. 'weather for London'";
speechRecognizer.Constraints.Add(webSearchGrammar);
// Compile the constraint.
await speechRecognizer.CompileConstraintsAsync();
// Start recognition.
Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync();
//await speechRecognizer.RecognizeWithUIAsync();
// Do something with the recognition result.
var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken");
await messageDialog.ShowAsync();
}
Articles connexes
Échantillons