Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Intégrez la reconnaissance vocale et la synthèse vocale (également appelée TTS ou synthèse vocale) directement dans l’expérience utilisateur de votre application.
Reconnaissance vocale La reconnaissance vocale convertit les mots prononcés par l’utilisateur en texte pour l’entrée de formulaire, pour la dictée de texte, pour spécifier une action ou une commande et pour accomplir des tâches. Il prend en charge les grammaires prédéfinies pour la dictée en texte libre et la recherche web, ainsi que les grammaires personnalisées créées à l’aide de la spécification de grammaire de reconnaissance vocale (SRGS) version 1.0.
Speech synthesis/Text to Speech (TTS) TTS utilise un moteur de synthèse vocale (voix) pour convertir une chaîne de texte en mots parlés. La chaîne d’entrée peut être de base, de texte nonadorné ou de langage de balisage de synthèse vocale plus complexe (SSML). SSML offre un moyen standard de contrôler les caractéristiques de la sortie vocale, telles que la prononciation, le volume, le ton, la vitesse, et l'emphase.
Conception de l’interaction vocale
Lorsque vous concevez et implémentez la parole de manière réfléchie, il peut s’agir d’un moyen efficace, accessible et naturel pour les personnes d’interagir avec vos applications Windows, de compléter ou même de remplacer les expériences d’interaction traditionnelles basées sur une souris, un clavier, un contrôleur ou une interaction tactile.
Ces instructions et recommandations décrivent comment intégrer au mieux la reconnaissance vocale et le TTS dans l’expérience d’interaction de votre application.
Si vous envisagez de prendre en charge les interactions vocales dans votre application, posez-vous les questions suivantes :
- Quelles actions les utilisateurs peuvent-ils effectuer via la parole ? Peut-il naviguer entre les pages, appeler des commandes ou entrer des données sous forme de champs de texte, de brèves notes ou de messages longs ?
- L’entrée vocale est-elle une bonne option pour effectuer une tâche ?
- Comment un utilisateur sait-il quand l’entrée vocale est disponible ?
- L’application écoute-t-elle toujours ou l’utilisateur doit-il effectuer une action pour que l’application entre en mode d’écoute ?
- Quelles expressions lancent une action ou un comportement ? Les expressions et les actions doivent-elles être énumérées à l’écran ?
- Les écrans d’invite, de confirmation et de désambiguïsation, ou des TTS, sont-ils requis ?
- Qu’est-ce que la boîte de dialogue d’interaction entre l’application et l’utilisateur ?
- Un vocabulaire personnalisé ou limité est-il nécessaire (comme la médecine, la science ou les paramètres régionaux) pour le contexte de votre application ?
- La connectivité réseau est-elle requise ?
Entrée de texte
L’entrée de texte peut aller d’une entrée de forme courte, telle qu’un mot ou une expression unique, à une entrée de formulaire long, telle que plusieurs expressions, paragraphes ou dictée continue. L’entrée de formulaire court est généralement inférieure à 10 secondes, tandis que les sessions d’entrée de formulaire longues peuvent avoir jusqu’à deux minutes de longueur. La saisie de texte long peut redémarrer sans intervention de l’utilisateur pour donner l’impression d’une dictée continue.
Fournissez un indicateur visuel pour indiquer que la reconnaissance vocale est prise en charge et disponible pour l’utilisateur et si l’utilisateur doit l’activer. Par exemple, utilisez un bouton de barre de commandes avec un glyphe de microphone (voir barres de commandes) pour afficher la disponibilité et l’état.
Fournissez des commentaires de reconnaissance continus pour réduire tout manque apparent de réponse pendant l’exécution de la reconnaissance.
Permettre aux utilisateurs de modifier le texte de reconnaissance à l’aide d’une entrée au clavier, de messages de désambiguïsation, de suggestions ou de reconnaissance vocale supplémentaire.
Arrêtez la reconnaissance si l’entrée est détectée à partir d’un appareil autre que la reconnaissance vocale, par exemple tactile ou clavier. Cette entrée indique probablement que l’utilisateur est passé à une autre tâche, comme corriger le texte de reconnaissance ou interagir avec d’autres champs de formulaire.
Spécifiez la durée pendant laquelle aucune entrée vocale n’indique que la reconnaissance est terminée. Ne redémarrez pas automatiquement la reconnaissance après cette période, car elle indique généralement que l’utilisateur a cessé d’interagir avec votre application.
Dans certains cas, une connexion réseau peut être nécessaire pour prendre en charge la reconnaissance vocale. Si l’un n’est pas disponible, désactivez l’interface utilisateur de reconnaissance continue et terminez la session de reconnaissance.
Commandement
L’entrée vocale peut lancer des actions, appeler des commandes et accomplir des tâches.
Si l’espace le permet, envisagez d’afficher les réponses prises en charge pour le contexte d’application actuel, avec des exemples d’entrée valides. Cette approche réduit les réponses potentielles que votre application doit traiter et élimine également la confusion pour l’utilisateur.
Essayez de formuler vos questions pour susciter une réponse aussi précise que possible. Par exemple, « Que voulez-vous faire aujourd’hui ? » est très ouvert et nécessite une définition grammaticale très importante en raison de la diversité des réponses. Ou sinon, « Voulez-vous jouer à un jeu ou écouter de la musique ? » limite la réponse à l'une des deux réponses valides avec une définition de grammaire simple correspondante. Une petite grammaire est beaucoup plus facile à créer et entraîne des résultats de reconnaissance beaucoup plus précis.
Demander la confirmation de l’utilisateur lorsque la confiance de la reconnaissance vocale est faible. Si l’intention de l’utilisateur n’est pas claire, il est préférable d’obtenir des précisions que de lancer une action involontaire.
Fournissez un indicateur visuel pour indiquer que la reconnaissance vocale est prise en charge et disponible pour l’utilisateur et si l’utilisateur doit l’activer. Par exemple, utilisez un bouton de barre de commandes avec un glyphe de microphone (voir Instructions pour les barres de commandes) pour afficher la disponibilité et l’état.
Si le commutateur de reconnaissance vocale est généralement hors vue, envisagez d’afficher un indicateur d’état dans la zone de contenu de l’application.
Si l’utilisateur lance la reconnaissance, envisagez d’utiliser l’expérience de reconnaissance intégrée pour la cohérence. L’expérience intégrée inclut des écrans personnalisables avec des invites, des exemples, des ambiguïtés, des confirmations et des erreurs.
Les écrans varient en fonction des contraintes spécifiées :
Grammaire prédéfinie (dictée ou recherche web)
- Écran d’écoute .
- Écran Réflexion .
- L’écran « Heard you say » ou l’écran d’erreur.
Liste de mots ou d’expressions ou d’un fichier de grammaire SRGS
- Écran d’écoute .
- L’écran Did you say, si ce que l’utilisateur a dit pourrait être interprété comme plusieurs résultats potentiels.
- L’écran « Heard you say » ou l’écran d’erreur.
Sur l’écran d’écoute , vous pouvez :
- Personnalisez le texte du titre.
- Fournissez un exemple de texte de ce que l’utilisateur peut dire.
- Spécifiez si l’écran J’ai entendu ce que vous dites s’affiche.
- Lisez la chaîne reconnue à l’utilisateur sur l’écran Heard que vous dites .
Les images suivantes illustrent un exemple de flux de reconnaissance intégré pour un module de reconnaissance vocale qui utilise une contrainte définie par SRGS. Dans cet exemple, la reconnaissance vocale réussit.
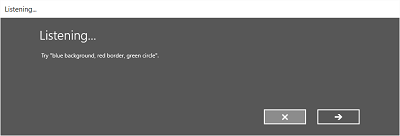
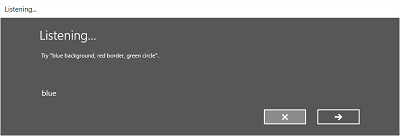
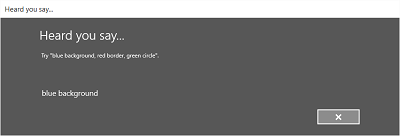
Toujours écouter
Votre application peut écouter et reconnaître l’entrée vocale dès le lancement de l’application, sans intervention de l’utilisateur.
Personnalisez les contraintes de grammaire en fonction du contexte de l’application. Cette approche maintient l’expérience de reconnaissance vocale très ciblée et pertinente pour la tâche actuelle et réduit les erreurs.
« Que puis-je dire ? »
Lorsque vous activez l’entrée vocale, aidez les utilisateurs à découvrir ce que l’application peut comprendre et quelles actions il peut effectuer.
Si les utilisateurs activent la reconnaissance vocale, envisagez d’utiliser la barre de commandes ou une commande de menu pour afficher tous les mots et expressions pris en charge dans le contexte actuel.
Si la reconnaissance vocale est toujours activée, envisagez d’ajouter l’expression « Que puis-je dire ? » à chaque page. Lorsque l’utilisateur indique cette expression, affichez tous les mots et expressions pris en charge dans le contexte actuel. L’utilisation de cette expression permet aux utilisateurs de découvrir des fonctionnalités vocales dans le système.
Défaillances de reconnaissance
La reconnaissance vocale peut échouer. Les défaillances se produisent lorsque la qualité audio est médiocre, lorsque le module de reconnaissance détecte uniquement une partie d’une expression, ou lorsque le module de reconnaissance détecte aucune entrée du tout.
Gérez correctement l’échec, aidez l’utilisateur à comprendre pourquoi la reconnaissance a échoué et à récupérer.
Votre application doit informer l’utilisateur que le module de reconnaissance ne les comprenait pas et qu’il doit réessayer.
Envisagez de fournir des exemples d’une ou plusieurs expressions prises en charge. L’utilisateur est susceptible de répéter une expression suggérée, ce qui augmente la réussite de la reconnaissance.
Affichez la liste des correspondances potentielles à partir de laquelle l’utilisateur doit effectuer une sélection. Cette approche peut être beaucoup plus efficace que de passer à nouveau par le processus de reconnaissance.
Prenez toujours en charge d’autres types d’entrée, particulièrement utiles pour la gestion des échecs de reconnaissance répétés. Par exemple, vous pouvez suggérer que l’utilisateur tente d’utiliser un clavier, ou d’utiliser l’interaction tactile ou une souris pour effectuer une sélection dans une liste de correspondances potentielles.
Utilisez l’expérience de reconnaissance vocale intégrée, car elle inclut des écrans qui informent l’utilisateur que la reconnaissance n’a pas réussi et permet à l’utilisateur d’effectuer une autre tentative de reconnaissance.
Écoutez et essayez de corriger les problèmes dans l’entrée audio. Le module de reconnaissance vocale peut détecter les problèmes de qualité audio susceptibles d’affecter la précision de la reconnaissance vocale. Vous pouvez utiliser les informations fournies par le module de reconnaissance vocale pour informer l’utilisateur du problème et leur permettre de prendre des mesures correctives, si possible. Par exemple, si le paramètre de volume sur le microphone est trop faible, vous pouvez inviter l’utilisateur à parler plus fort ou à activer le volume.
Contraintes
Les contraintes, ou grammaires, définissent les mots et expressions prononcés que le module de reconnaissance vocale peut associer. Vous pouvez spécifier l’une des grammaires de service web prédéfinies ou créer une grammaire personnalisée que vous installez avec votre application.
Grammaires prédéfinies
Les grammaires de dictée et de recherche web prédéfinies fournissent une reconnaissance vocale pour votre application sans que vous deviez créer une grammaire. Lorsque vous utilisez ces grammaires, un service web distant effectue la reconnaissance vocale et retourne les résultats sur l’appareil.
- La grammaire de dictée de texte libre par défaut reconnaît la plupart des mots et expressions qu’un utilisateur peut dire dans une langue particulière. Il est optimisé pour reconnaître les phrases courtes. Utilisez la dictée en texte libre lorsque vous ne souhaitez pas limiter les types d’éléments qu’un utilisateur peut dire. Les utilisations classiques incluent la création de notes ou la dictée du contenu d’un message.
- La grammaire de recherche web, comme une grammaire de dictée, contient un grand nombre de mots et d’expressions qu’un utilisateur peut dire. Toutefois, il est optimisé pour reconnaître les termes que les utilisateurs utilisent généralement lors de la recherche sur le web.
Note
Étant donné que les grammaires de dictée et de recherche web prédéfinies peuvent être volumineuses et parce qu’elles sont en ligne (pas sur l’appareil), les performances peuvent ne pas être aussi rapides qu’avec une grammaire personnalisée installée sur l’appareil.
Ces grammaires prédéfinies peuvent reconnaître jusqu’à 10 secondes d’entrée vocale et ne nécessitent aucun effort de création. Toutefois, ils nécessitent une connexion à un réseau.
Grammaires personnalisées
Concevez et créez une grammaire personnalisée et installez-la avec votre application. L’appareil effectue la reconnaissance vocale à l’aide d’une contrainte personnalisée.
Les contraintes de liste programmatique offrent une approche légère de la création de grammaires simples à l’aide d’une liste de mots ou d’expressions. Une contrainte de liste fonctionne bien pour reconnaître des expressions courtes et distinctes. La spécification explicite de tous les mots d’une grammaire améliore également la précision de la reconnaissance, car le moteur de reconnaissance vocale ne doit traiter que la voix pour confirmer une correspondance. Vous pouvez également mettre à jour la liste par programmation.
Une grammaire SRGS est un document statique qui, contrairement à une contrainte de liste programmatique, utilise le format XML défini par la version SRGS 1.0. Une grammaire SRGS offre le meilleur contrôle de l’expérience de reconnaissance vocale en vous permettant de capturer plusieurs significations sémantiques dans une seule reconnaissance.
Voici quelques conseils pour créer des grammaires SRGS :
- Gardez chaque ensemble de règles grammaticales petit. Les grammaires qui contiennent moins d’expressions ont tendance à fournir une reconnaissance plus précise que les grammaires plus volumineuses qui contiennent de nombreuses expressions. Il est préférable d’avoir plusieurs grammaires plus petites pour des scénarios spécifiques que pour avoir une grammaire unique pour l’ensemble de votre application.
- Indiquez aux utilisateurs ce qu’il faut dire pour chaque contexte d’application et activez et désactivez les grammaires si nécessaire.
- Concevez chaque grammaire afin que les utilisateurs puissent parler une commande de différentes façons. Par exemple, utilisez la règle GARBAGE pour faire correspondre l’entrée vocale que votre grammaire ne définit pas. Cette règle permet aux utilisateurs de parler des mots supplémentaires qui n’ont aucune signification pour votre application. Par exemple, « donne-moi », « et », « uh », « peut-être », et ainsi de suite.
- Utilisez l’élément sapi :sous-ensemble pour aider à faire correspondre l’entrée vocale. Cet élément est une extension Microsoft à la spécification SRGS pour vous aider à faire correspondre les expressions partielles.
- Essayez d’éviter de définir des expressions dans votre grammaire qui ne contiennent qu’une seule syllabe. La reconnaissance tend à être plus précise pour les expressions contenant deux syllabes ou plus.
- Évitez d’utiliser des expressions qui semblent similaires. Par exemple, les expressions telles que « hello », « bellow » et « fellow » peuvent confondre le moteur de reconnaissance et entraîner une mauvaise précision de reconnaissance.
Note
Le type de contrainte que vous utilisez dépend de la complexité de l’expérience de reconnaissance que vous souhaitez créer. Tout type peut être le meilleur choix pour une tâche de reconnaissance spécifique, et vous pouvez trouver des utilisations pour tous les types de contraintes dans votre application.
Prononciations personnalisées
Si votre application contient un vocabulaire spécialisé avec des mots inhabituels ou fictifs, ou des mots avec des prononciations rares, vous pouvez améliorer les performances de reconnaissance pour ces mots en définissant des prononciations personnalisées.
Pour obtenir une petite liste de mots et d’expressions, ou une liste de mots et expressions rarement utilisés, créez des prononciations personnalisées dans une grammaire SRGS. Pour plus d’informations, consultez l’élément de jeton .
Pour des listes plus volumineuses de mots et d’expressions, ou des mots et expressions fréquemment utilisés, créez des documents lexiques de prononciation distincts. Pour plus d’informations, voir À propos des lexicons et des alphabets phonétiques .
Essai
Testez la précision de la reconnaissance vocale et toute interface utilisateur de prise en charge avec le public cible de votre application. Cette approche vous aide à déterminer l’efficacité de l’expérience d’interaction vocale dans votre application. Par exemple, les utilisateurs obtiennent-ils des résultats de reconnaissance médiocres, car votre application n’écoute pas une expression courante ?
Modifiez la grammaire pour prendre en charge cette expression ou fournissez aux utilisateurs une liste d’expressions prises en charge. Si vous fournissez déjà la liste des expressions prises en charge, assurez-vous que les utilisateurs peuvent facilement le trouver.
Synthèse vocale (TTS)
TTS génère une sortie vocale à partir de texte brut ou de SSML.
Essayez de concevoir des invites polies et encourageantes.
Déterminez si vous devez lire de longues chaînes de texte. Il est une chose d’écouter un sms, mais une autre pour écouter une longue liste de résultats de recherche difficile à mémoriser.
Fournissez des contrôles multimédias pour permettre aux utilisateurs de suspendre ou d’arrêter TTS.
Écoutez toutes les chaînes TTS pour vous assurer qu’elles sont intelligibles et sons naturels.
- Enchaîner une séquence inhabituelle de mots, de numéros de pièces ou de ponctuation peut rendre une phrase inintelligible.
- La voix peut sembler anormale lorsque la prosodie ou la cadence est différente de la façon dont un orateur natif dirait une expression.
Vous pouvez résoudre les deux problèmes à l’aide de SSML au lieu de texte brut comme entrée au synthétiseur vocal. Pour plus d’informations sur SSML, consultez Utiliser SSML pour contrôler la synthèse vocale et la référence du langage de balisage de synthèse vocale.