Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
- Prérequis pour muI
- Séparation du code source des ressources spécifiques au langage
- Chargement dynamique de ressources spécifiques à la langue
- Génération d’applications MUI
Prérequis pour muI
La condition préalable de base à la création d’une application compatible muI pour Windows Vista et au-delà consiste à concevoir l’application conformément aux directives de globalisation de Windows.
Séparation du code source des ressources spécifiques au langage
L’un des principes fondamentaux de la technologie MUI est la séparation du code source d’application des ressources spécifiques au langage, pour permettre des scénarios multilingues dans les applications plus efficacement. La séparation du code et des ressources a été obtenue via différents mécanismes et à différents degrés au fil du temps, comme indiqué dans les sections suivantes. Chaque méthode offrait différents degrés de flexibilité dans la création, le déploiement et la maintenance de l’application.
La solution recommandée pour les applications compatibles MUI est la dernière méthode décrite ici, à savoir la séparation physique du code source d’application et des ressources, les ressources elles-mêmes étant ensuite décomposées en un seul fichier par langue prise en charge pour une flexibilité maximale dans la création, le déploiement et la maintenance.
Les premiers jours : le code et les ressources vivent ensemble
Initialement, les applications localisées ont été créées en modifiant le code source et en modifiant les ressources (généralement des chaînes) dans le code lui-même et en recompilant les applications. Cela signifiait que pour produire une version localisée, il fallait copier le code source d’origine, traduire les éléments de texte (ressources) dans le code source et recompiler le code. L’image suivante montre le code d’application avec du texte qui doit être localisé.
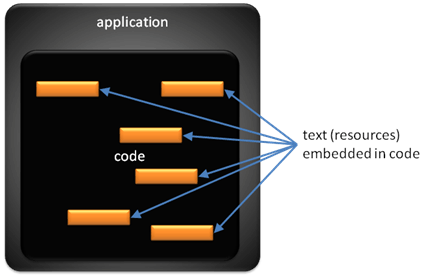
Bien que cette approche permette la création d’applications localisées, elle présente également des inconvénients importants :
- Il nécessite plusieurs versions du code source, au moins une pour la langue source et une pour chacune des langues cibles. Cela crée des problèmes importants lors de la synchronisation des différentes versions linguistiques de l’application. En particulier, lorsqu’un défaut doit être corrigé dans le code, il doit l’être dans chaque copie du code source (une par langue).
- Elle est également extrêmement sujette aux erreurs, car elle exigeait des localiseurs (qui ne sont pas des développeurs) d’apporter des modifications au code source, créant ainsi un risque considérable en termes d’intégrité du code.
La combinaison de ces inconvénients en fait une proposition extrêmement inefficace, et un meilleur modèle était nécessaire.
Séparation logique du code et des ressources localisables
Une amélioration significative par rapport au modèle précédent est la séparation logique du code et des ressources localisables pour une application. Cela isole le code des ressources et garantit que le code reste intact lorsque les ressources sont modifiées par localisation. Du point de vue de l’implémentation, les chaînes et autres éléments d’interface utilisateur sont stockés dans des fichiers de ressources, qui sont relativement faciles à traduire et sont logiquement séparés des sections de code.
Dans l’idéal, l’ajout de la prise en charge d’une langue donnée peut être aussi simple que la traduction des ressources localisables dans cette nouvelle langue et l’utilisation de ces ressources traduites pour créer une nouvelle version localisée de l’application, sans nécessiter de modification du code. L’image suivante montre comment le code et les ressources localisables doivent être séparés logiquement au sein d’une application.

Ce modèle permet de créer plus facilement des versions localisées d’une application et constitue une amélioration significative par rapport au modèle précédent. Ce modèle, implémenté à l’aide d’outils de gestion des ressources, a été très réussi au fil des ans et est encore couramment utilisé par de nombreuses applications aujourd’hui. Toutefois, il présente des inconvénients importants :
- Bien qu’elles soient séparées logiquement, le code et les ressources localisées sont toujours physiquement joints dans un fichier exécutable. En particulier, la facilité de maintenance reste problématique, car le même défaut de code (identique dans toutes les versions de langage) nécessite un correctif par langue. Par conséquent, si vous expédiez l’application en 20 langues, un correctif de service doit être émis 20 fois (une pour chaque langue), même si le code n’est corrigé qu’une seule fois.
- La distribution et l’utilisation d’applications multilingues ne sont pas correctement prises en charge par ce modèle. Il peut s’agir d’un problème important dans les scénarios OEM et d’entreprise. Par instance, si un ordinateur doit être partagé entre deux utilisateurs en utilisant des langues différentes, les applications devront être installées deux fois avec ce modèle, puis certains mécanismes devront être activés pour alterner entre les deux installations. Cela suppose qu’il n’existe aucune dépendance supplémentaire qui empêche même ce scénario d’être implémenté. L’image suivante montre un exemple de défaut de code unique qui nécessite deux correctifs.

Il est clair que bien que ce modèle fonctionne bien dans certains scénarios, ses limitations pour les applications multilingues et leurs déploiements peuvent être très problématiques.
Une variante de ce modèle qui atténue certains problèmes liés aux applications multilingues est le modèle où les ressources localisables contiennent un ensemble de ressources linguistiques différentes. Ce modèle a une base de code commune et plusieurs ressources pour différents langages dans la même application. Par exemple, une application peut être livrée avec l’anglais, l’allemand, l’Français, l’espagnol, le néerlandais et l’italien dans le même package. L’image suivante montre une application qui contient plusieurs ressources linguistiques.

Ce modèle facilite la maintenance de l’application lorsqu’un défaut de code doit être corrigé (ce qui est une amélioration), mais ne s’améliore pas par rapport aux modèles précédents lorsqu’il s’agit de prendre en charge des langages supplémentaires. Dans ce cas, il faut toujours publier une nouvelle version de l’application (et cette version est potentiellement compliquée par la nécessité de s’assurer que toutes les ressources linguistiques sont synchronisées au sein de la même distribution).
Séparation physique du code et des ressources
L’étape évolutive suivante consiste à séparer physiquement le code et les ressources. Dans ce modèle, les ressources sont extraites du code et physiquement séparées dans différents fichiers d’implémentation. En particulier, cela signifie que le code peut devenir véritablement indépendant du langage; le même code physique est en fait fourni pour toutes les versions localisées d’une application. L’image suivante montre que le code et les ressources localisables doivent être physiquement séparées.

Cette approche présente plusieurs avantages par rapport aux approches précédentes :
- Le déploiement de solutions multilingues est considérablement simplifié. L’ajout de la prise en charge d’une langue donnée nécessite uniquement l’expédition et l’installation d’un nouvel ensemble de ressources linguistiques pour cette langue particulière. Cela est particulièrement important lorsque les ressources linguistiques ne sont pas toutes disponibles simultanément. Avec ce modèle, vous pouvez déployer une application dans un ensemble de langages principaux et augmenter le nombre de langues prises en charge au fil du temps sans avoir à modifier ou redéployer le code réel. Cet avantage est encore étendu par un mécanisme de secours qui permet une localisation partielle des applications et des composants système dans une langue donnée en veillant à ce que les ressources qui ne se trouvent pas dans cette langue préférée « retombent » vers une autre langue que les utilisateurs comprennent également. Dans l’ensemble, ce modèle permet d’atténuer la charge considérable que doivent supporter les entreprises mondiales dans le déploiement d’applications dans plusieurs langues, car il permet le déploiement d’une seule image de manière beaucoup plus efficace.
- La facilité de maintenance est améliorée. Une erreur de code ne doit être corrigée et déployée qu’une seule fois, car le code est complètement indépendant de la localisation. Avec ce modèle, l’émission d’une correction pour un défaut de code, à condition que la modification ne soit pas liée à l’interface utilisateur, est beaucoup plus simple et rentable que dans l’un des modèles précédents.
Chargement dynamique de ressources spécifiques à la langue
Les concepts fondamentaux de l’interface utilisateur utilisateur qui consiste à séparer physiquement le code source des ressources spécifiques au langage et à créer un fichier binaire de base indépendant du langage pour une application, configurent essentiellement une architecture qui est propice à l’implémentation du chargement dynamique de ressources spécifiques à la langue en fonction des paramètres de langage utilisateur et système.
Le code source de l’application regroupé dans le fichier binaire principal indépendant du langage peut utiliser les API MUI dans la plateforme Windows pour extraire la sélection de la langue d’interface utilisateur d’affichage appropriée pour un contexte donné. L’interface utilisateur utilisateur prend en charge ce qui suit :
- Construction d’une liste hiérarchisée des langues de l’interface utilisateur d’affichage en fonction des paramètres système, utilisateur et au niveau de l’application, au niveau de l’utilisateur et au niveau du système.
- Implémentation d’un mécanisme de secours qui choisit un candidat approprié dans cette liste hiérarchisée de langues, en fonction de la disponibilité des ressources localisées.
Les avantages du chargement dynamique des ressources d’interface utilisateur avec une priorité de secours sont les suivants :
- Il permet la localisation partielle des applications et des composants système dans une langue donnée, car les ressources qui ne sont pas trouvées dans cette langue préférée retombent automatiquement vers la langue suivante de la liste prioritaire.
- Il permet des scénarios tels que le passage dynamique d’une langue à une autre.
- Il permet de créer des images de déploiement unique régionales ou mondiales qui couvrent un ensemble de langues pour les fabricants OEM et les entreprises.
Génération d’applications MUI
Les sections précédentes ont décrit les options permettant de séparer le code source des ressources spécifiques à la langue, et l’avantage qui en résulte d’être en mesure d’utiliser les API de plateforme Windows principales pour charger dynamiquement des ressources localisées. Bien qu’il s’agit de recommandations, il convient également de souligner qu’il n’existe aucun moyen normatif spécifique de développer une application MUI pour la plateforme Windows.
Les développeurs d’applications ont le choix complet dans la façon dont ils gèrent les différents paramètres de langue de l’interface utilisateur, les options de création de ressources et les méthodes de chargement des ressources. Les développeurs peuvent évaluer les instructions fournies dans ce document et choisir une combinaison qui correspond à leurs exigences et à leur environnement de développement.
Le tableau suivant récapitule les différentes options de conception disponibles pour les développeurs d’applications qui cherchent à créer une application MUI pour la plateforme Windows.
| Paramètres de langue de l’interface utilisateur | Création de ressources | Chargement des ressources |
|---|---|---|
| Suivre les paramètres de langue de l’interface utilisateur dans le système d’exploitation${REMOVE}$ |
Langage unique dans un binaire de ressources fractionnées (technologie de ressources MUI) -ou- Plusieurs langues dans un binaire de ressource non fractionné |
L’application appelle des fonctions de chargement de ressources standard. Les ressources sont retournées dans les langues correspondant aux paramètres du système d’exploitation. |
| Mécanisme de ressource spécifique à l’application |
L’application appelle l’API MUI pour récupérer les langues d’interface utilisateur préférées des threads ou les langues d’interface utilisateur préférées des processus du système d’exploitation et utiliser ces paramètres pour charger ses propres ressources. |
|
| Paramètres de langue de l’interface utilisateur spécifiques à l’application${REMOVE}$ |
Langage unique dans un binaire de ressource fractionnée -ou- Plusieurs langues dans un binaire de ressource non fractionné |
L’application appelle l’API MUI pour définir des langages d’interface utilisateur spécifiques à l’application ou des langages d’interface utilisateur préférés des processus, puis appelle des fonctions de chargement de ressources standard. Les ressources sont retournées dans les langues définies par les langues de l’application ou du système. -ou- L’application sonde les ressources dans un langage spécifique et gère sa propre extraction de ressources à partir des données binaires récupérées. |
| Mécanisme de ressources spécifique à l’application |
L’application gère son propre chargement de ressources. |