Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’espace de noms Shell organise le système de fichiers et d’autres objets gérés par l’interpréteur de commandes dans une hiérarchie arborescence unique. D’un point de vue conceptuel, il s’agit d’une version plus grande et plus inclusive du système de fichiers.
Introduction
L’une des principales responsabilités de l’interpréteur de commandes consiste à gérer et à fournir l’accès à la grande variété d’objets qui composent le système. Les plus nombreux et les plus familiers de ces objets sont les dossiers et les fichiers qui résident sur les lecteurs de disque d’ordinateur. Toutefois, l’interpréteur de commandes gère également un certain nombre d’objets virtuels ou de système sans fichier. Voici quelques exemples :
- Imprimantes réseau
- Autres ordinateurs en réseau
- Panneau de configuration applications
- Corbeille
Certains objets virtuels n’impliquent pas du tout de stockage physique. L’objet printer, pour instance, contient une collection de liens vers des imprimantes en réseau. D’autres objets virtuels, tels que la Corbeille, peuvent contenir des données stockées sur un lecteur de disque, mais doivent être gérés différemment des fichiers normaux. Par exemple, un objet virtuel peut être utilisé pour représenter des données stockées dans une base de données. En termes d’espace de noms, les différents éléments de la base de données peuvent apparaître dans les Explorer Windows en tant qu’objets distincts, même s’ils sont tous stockés dans un fichier de disque unique.
Les objets virtuels peuvent même se trouver sur des ordinateurs distants. Par instance, pour faciliter l’itinérance, les fichiers de documents d’un utilisateur peuvent être stockés sur un serveur. Pour permettre aux utilisateurs d’accéder à leurs fichiers à partir de plusieurs PC de bureau, le dossier Mes documents sur le PC de bureau qu’ils utilisent actuellement pointe vers le serveur, et non vers le disque dur du PC de bureau. Son chemin d’accès inclut un lecteur réseau mappé ou un nom de chemin UNC.
Comme le système de fichiers, l’espace de noms comprend deux types d’objets de base : les dossiers et les fichiers. Les objets folder sont les nœuds de l’arborescence ; il s’agit de conteneurs pour les objets de fichier et d’autres dossiers. Les objets file sont les feuilles de l’arborescence ; il s’agit de fichiers de disque normaux ou d’objets virtuels, tels que des liens d’imprimante. Les dossiers qui ne font pas partie du système de fichiers sont parfois appelés dossiers virtuels.
Comme les dossiers de système de fichiers, la collection de dossiers virtuels varie généralement d’un système à l’autre. Il existe trois classes de dossiers virtuels :
- Dossiers virtuels standard, tels que la Corbeille, qui se trouvent sur tous les systèmes.
- Dossiers virtuels facultatifs qui ont des noms et des fonctionnalités standard, mais qui peuvent ne pas être présents sur tous les systèmes.
- Dossiers non standard installés par l’utilisateur.
Contrairement aux dossiers de système de fichiers, les utilisateurs ne peuvent pas créer eux-mêmes de nouveaux dossiers virtuels. Ils ne peuvent installer que ceux créés par des développeurs non-Microsoft. Le nombre de dossiers virtuels est donc normalement beaucoup moins élevé que le nombre de dossiers de système de fichiers. Pour plus d’informations sur l’implémentation de dossiers virtuels, consultez Extensions d’espace de noms.
Vous pouvez voir une représentation visuelle de la structure de l’espace de noms dans la barre Explorer de l’Explorer Windows. Par exemple, la capture d’écran suivante de Windows Explorer montre un espace de noms relativement simple.
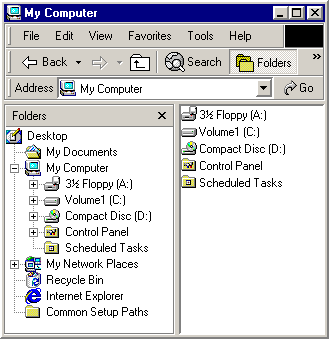
La racine ultime de la hiérarchie d’espaces de noms est le bureau. Juste en dessous de la racine se trouvent plusieurs dossiers virtuels tels que Poste de travail et la Corbeille.
Les systèmes de fichiers des différents lecteurs de disque peuvent être considérés comme des sous-ensembles de la hiérarchie d’espaces de noms plus grande. Les racines de ces systèmes de fichiers sont des sous-dossiers du dossier Poste de travail. Mon ordinateur inclut également les racines de tous les lecteurs réseau mappés. Les autres nœuds de l’arborescence, tels que Mes documents, sont des dossiers virtuels.
Identification des objets d’espace de noms
Avant de pouvoir utiliser un objet d’espace de noms, vous devez d’abord disposer d’un moyen de l’identifier. Un objet dans le système de fichiers peut avoir un nom tel que MyFile.htm. Étant donné qu’il peut y avoir d’autres fichiers portant ce nom ailleurs dans le système, l’identification unique d’un fichier ou d’un dossier nécessite un chemin d’accès complet tel que « C:\MyDocs\MyFile.htm ». Ce chemin est essentiellement une liste triée de tous les dossiers d’un chemin d’accès à partir de la racine du système de fichiers, C:\, se terminant par le fichier.
Dans le contexte de l’espace de noms, les chemins d’accès sont toujours très utiles pour identifier les objets situés dans la partie système de fichiers de l’espace de noms. Toutefois, ils ne peuvent pas être utilisés pour les objets virtuels. Au lieu de cela, l’interpréteur de commandes fournit un autre moyen d’identification qui peut être utilisé avec n’importe quel objet d’espace de noms.
ID d’élément
Dans un dossier, chaque objet a un ID d’élément, qui est l’équivalent fonctionnel d’un nom de fichier ou de dossier. L’ID d’élément est en fait une structure SHITEMID :
typedef struct _SHITEMID {
USHORT cb;
BYTE abID[1];
} SHITEMID, * LPSHITEMID;
Le membre abID est l’identificateur de l’objet. La longueur de abID n’est pas définie et sa valeur est déterminée par le dossier qui contient l’objet . Étant donné qu’il n’existe aucune définition standard pour la façon dont les valeurs abID sont attribuées par les dossiers, elles ne sont significatives que pour l’objet folder associé. Les applications doivent simplement les traiter comme un jeton qui identifie un objet dans un dossier particulier. Étant donné que la longueur de abID varie, le membre cb conserve la taille de la structure SHITEMID , en octets.
Étant donné que les ID d’élément ne sont pas utiles à des fins d’affichage, le dossier qui contient l’objet lui attribue normalement un nom d’affichage. Il s’agit du nom utilisé par Windows Explorer lorsqu’il affiche le contenu d’un dossier. Pour plus d’informations sur la façon dont les noms d’affichage sont gérés, consultez Obtention d’informations à partir d’un dossier.
Listes d’ID d’élément
L’ID d’élément est rarement utilisé par lui-même. Normalement, il fait partie d’une liste d’ID d’élément, qui a le même objectif qu’un chemin d’accès au système de fichiers. Toutefois, au lieu de la chaîne de caractères utilisée pour les chemins d’accès, une liste d’ID d’élément est une structure ITEMIDLIST . Cette structure est une séquence ordonnée d’un ou plusieurs ID d’élément, terminée par une valeur NULL de deux octets. Chaque ID d’élément dans la liste des ID d’élément correspond à un objet d’espace de noms. Leur ordre définit un chemin d’accès dans l’espace de noms, à l’instar d’un chemin d’accès au système de fichiers.
L’illustration suivante montre une représentation schématique de la structure ITEMIDLIST qui correspond à C:\MyDocs\MyFile.htm. Le nom complet de chaque ID d’élément s’affiche au-dessus de celui-ci. Les largeurs variables des membres abID sont arbitraires ; ils illustrent le fait que la taille de ce membre peut varier.

PIDLs
Pour l’API Shell, les objets d’espace de noms sont généralement identifiés par un pointeur vers leur structure ITEMIDLIST ou par un pointeur vers une liste d’identificateurs d’élément (PIDL). Pour des raisons pratiques, le terme PIDL fait généralement référence dans cette documentation à la structure elle-même plutôt qu’au pointeur vers celle-ci.
Le PIDL indiqué dans l’illustration précédente est appelé piDL complet ou absolu. Un FICHIER PIDL complet démarre à partir du bureau et contient les ID d’élément de tous les dossiers intermédiaires dans le chemin d’accès. Il se termine par l’ID d’élément de l’objet suivi d’une valeur NULL de deux octets de fin. Un PIDL complet est similaire à un chemin d’accès complet et identifie de manière unique l’objet dans l’espace de noms Shell.
Les PIDL complets sont rarement utilisés. De nombreuses fonctions et méthodes attendent un PIDL relatif. La racine d’un PIDL relatif est un dossier, et non le bureau. Comme pour les chemins d’accès relatifs, la série d’ID d’élément qui composent la structure définit un chemin d’accès dans l’espace de noms entre deux objets. Bien qu’ils n’identifient pas l’objet de manière unique, ils sont généralement plus petits qu’un PIDL complet et suffisants à de nombreuses fins.
Les PIDL relatifs les plus couramment utilisés, les PIDL de niveau unique, sont relatifs au dossier parent de l’objet. Ils contiennent uniquement l’ID d’élément de l’objet et une valeur NULL de fin. Les FICHIERS PIDL multiniveaux sont également utilisés à de nombreuses fins. Ils contiennent au moins deux ID d’élément et définissent généralement un chemin d’accès d’un dossier parent à un objet via une série d’un ou plusieurs sous-dossiers. Notez qu’un PIDL de niveau unique peut toujours être un PIDL complet. En particulier, les objets de bureau étant des enfants du bureau, leurs PIDL complets ne contiennent qu’un seul ID d’élément.
Comme indiqué dans Obtention de l’ID d’un dossier, l’API Shell fournit plusieurs façons de récupérer le CODE PIDL d’un objet. Une fois que vous l’avez, vous l’utilisez généralement pour identifier l’objet lorsque vous appelez d’autres fonctions et méthodes d’API Shell. Dans ce contexte, le contenu interne d’un PIDL est opaque et non pertinent. Pour les besoins de cette discussion, considérez les PIDL comme des jetons qui représentent des objets d’espace de noms particuliers et concentrez-vous sur la façon de les utiliser pour des tâches courantes.
Allocation de listes de contrôle d’identification personnelle
Bien que les PIDL présentent une certaine similarité avec les chemins d’accès, leur utilisation nécessite une approche quelque peu différente. La principale différence réside dans la façon d’allouer et de libérer la mémoire pour eux.
Comme la chaîne utilisée pour un chemin d’accès, la mémoire doit être allouée pour un PIDL. Si une application crée un PIDL, elle doit allouer suffisamment de mémoire pour la structure ITEMIDLIST . Dans la plupart des cas abordés ici, l’interpréteur de commandes crée le PIDL et gère l’allocation de mémoire. Quelle que soit la valeur allouée au PIDL, l’application est généralement responsable de la désaffectation du PIDL lorsqu’il n’est plus nécessaire.
Utilisez la fonction CoTaskMemAlloc pour allouer le PIDL et la fonction CoTaskMemFree pour le libérer.