Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le service de modèle personnalisé de régression logistique vous permet de créer des modèles de régression logistique (parfois appelés « modèles logit ») pour prédire la probabilité de clics ou de conversions en fonction d’une combinaison de plusieurs signaux. Les modèles de régression logistique peuvent ensuite être associés à un élément de ligne à l’aide du service d’élément de ligne - ALI (archivé).
Remarque
Cette offre est actuellement en version bêta fermée et est disponible pour un ensemble limité de clients. Pour plus d’informations sur l’ensemble d’outils d’annonces avancées et les cas d’usage potentiels qui peuvent s’appliquer à votre entreprise, contactez votre représentant de compte.
La formule de régression logistique est la suivante :
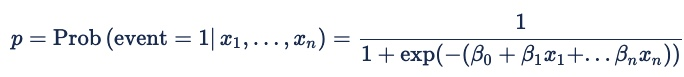
Pour la publicité en ligne, l’événement est un clic, un feu de pixels ou une autre action en ligne. La probabilité est conditionnelle aux prédicteurs x 1 à xn et à un ensemble implicite de variables qui représentent les caractéristiques d’une demande d’offre. Les coefficients bêta sont les pondérations que le modèle attribue à différents prédicteurs.
Nous convertissons cette probabilité qu’un événement se produise en valeur attendue en multipliant la probabilité par la valeur de l’événement (l’objectif eCPC pour une prédiction de clic), en ajoutant un décalage additif à l’estimation, puis en appliquant des limites de valeur minimale/maximale attendue pour réduire l’impact des mauvaises prédictions.
La formule permettant de dériver une valeur attendue pour une impression à partir de la probabilité qu’un événement se produise est la suivante :
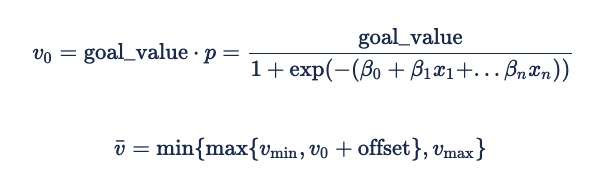
Le décalage est généralement 0. Toutefois, une valeur négative peut être utile en tant que facteur de sécurité pour garantir les performances au détriment de la livraison sur des stocks peu performants. Cela permettra de s’assurer que l’annonceur ne soumissionne pas, au lieu d’enchérir très peu et peut entraîner des frais fixes.
Pour plus d’informations sur le fonctionnement des modèles personnalisés de régression logistique, consultez Modèles de régression logistique.
API REST
Ajouter un nouveau modèle de régression logistique
POST https://api.appnexus.com/custom-model-logit
(template JSON)
Modifier un modèle de régression logistique
PUT https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
(template JSON)
Supprimer un modèle de régression logistique
DELETE https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
Afficher tous les modèles de régression logistique
GET https://api.appnexus.com/custom-model-logit
Afficher un modèle de régression logistique spécifique
GET https://api.appnexus.com/custom-model-logit?id=CUSTOM_MODEL_LOGIT_ID
Champs JSON
Généralités
| Champ | Type | Description |
|---|---|---|
id |
int | ID du modèle personnalisé de régression logistique. Par défaut : nombre généré automatiquement Obligatoire sur : PUT/ DELETE dans la chaîne de requête |
name |
string | Nom du modèle. |
beta0 |
float | β coefficient 0 dans l’équation de régression logistique. |
max |
float | Max dans l’équation de valeur attendue. |
min |
float | Min dans l’équation de valeur attendue. |
offset |
float | Décalage dans l’équation de valeur attendue. |
scale |
float | Mettre à l’échelle l’équation de valeur attendue. |
predictors |
tableau | Tableau de prédicteurs. Pour plus d’informations, consultez Prédicteurs ci-dessous. |
Prédicteurs
| Champ | Type | Description |
|---|---|---|
predictor_type |
scalar_descriptor, custom_model_descriptor, freq_rec_descriptor, segment_descriptor, categorical_descriptor |
|
keys |
||
hash_seed |
||
default_value |
||
hash_table_size_log |
||
coefficients |
Descripteur haché
Ce point de terminaison consiste à envoyer une table pré-hachée.
bucket_index0 et bucket_index1, de 64 bits chacun, sont là pour prendre en charge les algorithmes de hachage qui produisent des valeurs longues en tant que clés. Actuellement, nous ne prenons en charge qu’un seul algorithme de hachage : MurmurHash3_x64_128, qui créera deux entiers 64 bits, mais nous n’utilisons que les 64 bits inférieurs du hachage.
Les valeurs dans bucket_index0 doivent toujours être inférieures (2 ^ hash_table_size_log) à ou elles seront rejetées.
Actuellement, les valeurs dans bucket_index1 sont ignorées, car elles doivent être utilisées pour une extension ultérieure. Si une valeur est envoyée pour bucket_index1, elle doit être 0. Le paramètre est facultatif.
Clés de table de hachage
Pour chacune de vos clés de table de hachage, vous aurez besoin d’une valeur uint32. Ces valeurs doivent être l’ID de l’objet respectif que vous référencez à partir de notre système , domain_idpour instance, plutôt que la valeur de chaîne de domaine. Ces clés uint32 sont ensuite transformées en tableau d’octets (little-endian) et hachées.
Exemple Python
hash_bucket = (mmh3.hash64(bytes, seed)[ 0 ]) % table_size
| Champ | Type | Description |
|---|---|---|
type |
||
keys |
Tableau d’un à 5 descripteurs dans cette liste : | |
hashed_seeds |
Semences utilisées lorsqu’elles sont passées à Murmurhash3_x64_128 la fonction, une seule première est utilisée pour l’instant, array est pour les futures fonctions de hachage planifiées qui ont besoin de plusieurs seed |
|
hash_id |
ID de table de hachage existant | |
default_value |
Valeur retournée par le descripteur si aucune correspondance n’est trouvée dans votre table de hachage | |
hash_table_size_log |
Journal de la valeur maximale pour une clé de votre table. Les valeurs supérieures 2^hash_table_size_log à seront rejetées. Max for hash_table_size_log is 64 (no bucketing) |
Exemple de descripteur haché
{
"type": "hashed",
"keys": [
],
"hash_seeds": [42, 42, 42, 42, 42, 42],
"hash_id": ,
"default_value": 0,
"hash_table_size_log": 20
}
Descripteur de la table de recherche (LUT)
| Champ | Type | Description |
|---|---|---|
type |
||
feature_keyword |
||
default_value |
||
initial_range_log |
||
bucket_count_log_per_range |
Exemple de descripteur LUT
{
"type": "lookup",
"default_value": 0.1,
"features": [
{
"type": "categorical_descriptor",
"feature_keyword": "advertiser_id"
},
{
"type": "scalar_descriptor",
"feature_keyword": "user_age",
"default_value": 0
}
],
"coefficients": [
{'weight': 1.1, 'key': [1, 1]},
{'weight': 1.3, 'key': [2, 2]},
{'weight': 1.2, 'key': [3, 3]},
]
}
Descripteur catégoriel
Étant donné qu’il s’agit de trouver une correspondance exacte, les default_valueparamètres , initial_range_log et bucket_count_log_per_range ne sont pas nécessaires.
Valeurs manquantes
La valeur de clé de -1 peut être utilisée comme espace réservé pour une fonctionnalité manquante ; Par instance, lorsqu’un domaine n’est pas signalé par le vendeur. Sinon, la valeur par défaut du LUT ou du modèle de hachage sera utilisée, car aucune correspondance n’est trouvée pour cette valeur de fonctionnalité.
| Champ | Type | Description |
|---|---|---|
type |
||
feature_keyword |
- country- region- city- dma- postal_code- user_day- user_hour- os_family- os_extended- browser- language- user_gender- domain- ip_address- position- placement- placement_group- publisher- seller_member_id- supply_type- device_type- device_model- carrier- mobile_app- mobile_app_instance- mobile_app_bundle- appnexus_intended_audience- seller_intended_audience- spend_protection- user_group_id- advertiser_id- brand_category- creative- inventory_url_id- media_type |
|
default_value |
||
object_type |
Advertiser, li - ne_item, ( campaign non fractionné ?) |
|
object_id |
ID de l’annonceur référencé, |
Exemple de descripteur catégoriel
{
"type": "categorical_descriptor",
"feature_keyword": "city"
}
Descripteur de fréquence et de récence
| Champ | Type | Description |
|---|---|---|
type |
||
feature_keyword |
frequency_lifefrequency_dailyrecency |
|
default_value |
||
object_type |
Advertiser, line_item, ( campaign non fractionné ?) |
|
object_id |
ID de l’annonceur référencé, | |
default_value |
Valeur retournée par le descripteur si aucune correspondance n’est trouvée | |
initial_range_log |
Utilisé pour le compartimentage des journaux, plage initiale | |
bucket_count_log_per_range |
utilisé pour le compartimentage des journaux, nombre de compartiments par plage |
Exemple de descripteur de fréquence et de récence
{
"type": "frequency_recency_descriptor",
"feature_keyword": 'frequency_life',
"object_type": 'advertiser',
"object_id": 1,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
Descripteur scalaire
| Champ | Type | Description |
|---|---|---|
type |
||
feature_keyword |
- appnexus_audited- cookie_age- estimated_average_price- estimated_clearing_price- predicted_iab_view_rate- predicted_video_completion_rate- self_audited- size- creative_size- spend_protection- uniform- user_ageRemarque : Le descripteur de taille est représenté sous la forme d’une chaîne dans vos modèles (« 300 x 250 », pour instance), mais converti en scalaire dans notre soumissionnaire. Toute taille étant techniquement valide dans notre système, cette fonctionnalité est traitée comme une caractéristique scalaire plutôt qu’une caractéristique catégorielle. |
|
default_value |
Valeur retournée par le descripteur si aucune correspondance n’est trouvée | |
initial_range_log |
Utilisé pour le compartimentage des journaux, plage initiale | |
bucket_count_log_per_range |
Utilisé pour le compartimentage des journaux, nombre de compartiments par plage |
Exemple de descripteur scalaire
{
"type": "scalar_descriptor",
"feature_keyword": "cookie_age",
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}
Descripteur de segment
| Champ | Type | Description |
|---|---|---|
type |
||
feature_keyword |
segment_valuesegment_agesegment_presence |
|
segment_id |
ID du segment référencé | |
default_value |
Valeur retournée par le descripteur si aucune correspondance n’est trouvée | |
initial_range_log |
Utilisé pour le compartimentage des journaux, plage initiale | |
bucket_count_log_per_range |
Utilisé pour le compartimentage des journaux, nombre de compartiments par plage |
Exemple de descripteur de segment
{
"type": "segment_descriptor",
"feature_keyword": "segment_age",
"segment_id": 2,
"default_value": 0,
"initial_range_log": 4,
"bucket_count_log_per_range": 2
}