Copy data from Amazon RDS for SQL Server by using Azure Data Factory or Azure Synapse Analytics
This article outlines how to use the copy activity in Azure Data Factory and Azure Synapse pipelines to copy data from Amazon RDS for SQL Server database. To learn more, read the introductory article for Azure Data Factory or Azure Synapse Analytics.
Supported capabilities
This Amazon RDS for SQL Server connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/-) | ① ② |
| Lookup activity | ① ② |
| GetMetadata activity | ① ② |
| Stored procedure activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores that are supported as sources or sinks by the copy activity, see the Supported data stores table.
Specifically, this Amazon RDS for SQL Server connector supports:
- SQL Server version 2005 and above.
- Copying data by using SQL or Windows authentication.
- As a source, retrieving data by using a SQL query or a stored procedure. You can also choose to parallel copy from Amazon RDS for SQL Server source, see the Parallel copy from SQL database section for details.
SQL Server Express LocalDB is not supported.
Prerequisites
If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it.
If your data store is a managed cloud data service, you can use the Azure Integration Runtime. If the access is restricted to IPs that are approved in the firewall rules, you can add Azure Integration Runtime IPs to the allow list.
You can also use the managed virtual network integration runtime feature in Azure Data Factory to access the on-premises network without installing and configuring a self-hosted integration runtime.
For more information about the network security mechanisms and options supported by Data Factory, see Data access strategies.
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create an Amazon RDS for SQL Server linked service using UI
Use the following steps to create an Amazon RDS for SQL Server linked service in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Amazon RDS for SQL server and select the Amazon RDS for SQL Server connector.
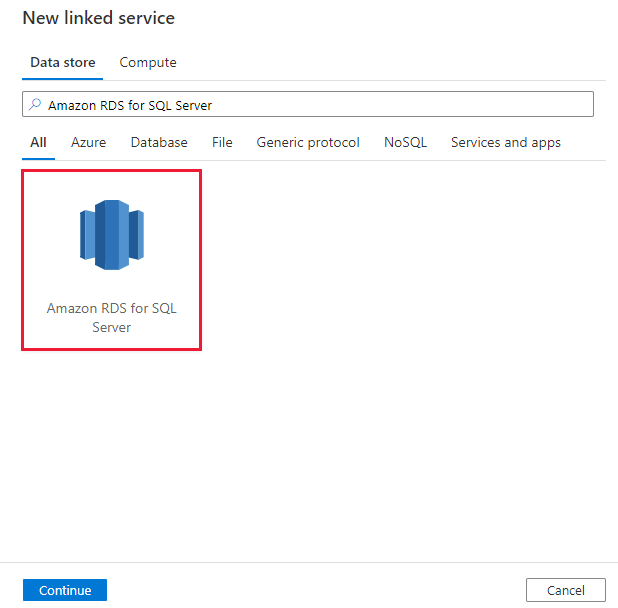
Configure the service details, test the connection, and create the new linked service.
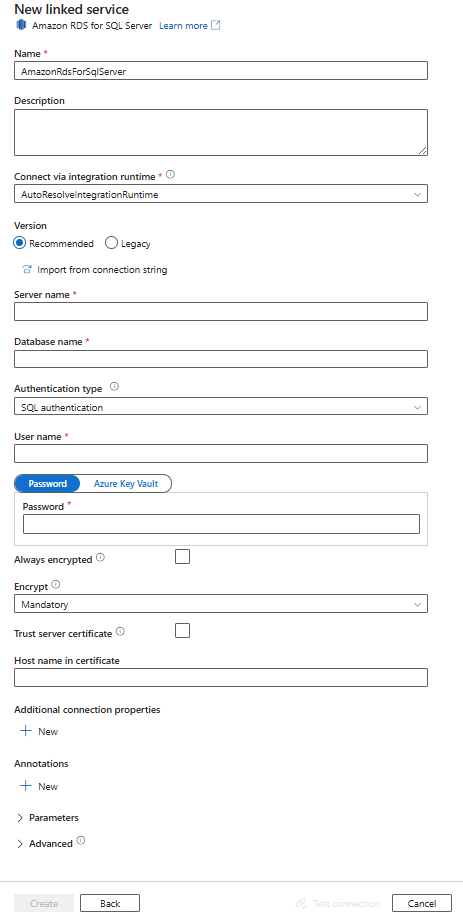
Connector configuration details
The following sections provide details about properties that are used to define Data Factory and Synapse pipeline entities specific to the Amazon RDS for SQL Server database connector.
Linked service properties
The Amazon RDS for SQL Server connector Recommended version supports TLS 1.3. Refer to this section to upgrade your Amazon RDS for SQL Server connector version from Legacy one. For the property details, see the corresponding sections.
Note
Amazon RDS for SQL Server Always Encrypted is not supported in data flow.
Tip
If you hit an error with the error code "UserErrorFailedToConnectToSqlServer" and a message like "The session limit for the database is XXX and has been reached," add Pooling=false to your connection string and try again.
Recommended version
These generic properties are supported for an Amazon RDS for SQL Server linked service when you apply Recommended version:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to AmazonRdsForSqlServer. | Yes |
| server | The name or network address of the SQL server instance you want to connect to. | Yes |
| database | The name of the database. | Yes |
| authenticationType | The type used for authentication. Allowed values are SQL (default), Windows. Go to the relevant authentication section on specific properties and prerequisites. | Yes |
| alwaysEncryptedSettings | Specify alwaysencryptedsettings information that's needed to enable Always Encrypted to protect sensitive data stored in Amazon RDS for SQL Server by using either managed identity or service principal. For more information, see the JSON example following the table and Using Always Encrypted section. If not specified, the default always encrypted setting is disabled. | No |
| encrypt | Indicate whether TLS encryption is required for all data sent between the client and server. Options: mandatory (for true, default)/optional (for false)/strict. | No |
| trustServerCertificate | Indicate whether the channel will be encrypted while bypassing the certificate chain to validate trust. | No |
| hostNameInCertificate | The host name to use when validating the server certificate for the connection. When not specified, the server name is used for certificate validation. | No |
| connectVia | This integration runtime is used to connect to the data store. Learn more from Prerequisites section. If not specified, the default Azure integration runtime is used. | No |
For additional connection properties, see the table below:
| Property | Description | Required |
|---|---|---|
| applicationIntent | The application workload type when connecting to a server. Allowed values are ReadOnly and ReadWrite. |
No |
| connectTimeout | The length of time (in seconds) to wait for a connection to the server before terminating the attempt and generating an error. | No |
| connectRetryCount | The number of reconnections attempted after identifying an idle connection failure. The value should be an integer between 0 and 255. | No |
| connectRetryInterval | The amount of time (in seconds) between each reconnection attempt after identifying an idle connection failure. The value should be an integer between 1 and 60. | No |
| loadBalanceTimeout | The minimum time (in seconds) for the connection to live in the connection pool before the connection being destroyed. | No |
| commandTimeout | The default wait time (in seconds) before terminating the attempt to execute a command and generating an error. | No |
| integratedSecurity | The allowed values are true or false. When specifying false, indicate whether userName and password are specified in the connection. When specifying true, indicates whether the current Windows account credentials are used for authentication. |
No |
| failoverPartner | The name or address of the partner server to connect to if the primary server is down. | No |
| maxPoolSize | The maximum number of connections allowed in the connection pool for the specific connection. | No |
| minPoolSize | The minimum number of connections allowed in the connection pool for the specific connection. | No |
| multipleActiveResultSets | The allowed values are true or false. When you specify true, an application can maintain multiple active result sets (MARS). When you specify false, an application must process or cancel all result sets from one batch before it can execute any other batches on that connection. |
No |
| multiSubnetFailover | The allowed values are true or false. If your application is connecting to an AlwaysOn availability group (AG) on different subnets, setting this property to true provides faster detection of and connection to the currently active server. |
No |
| packetSize | The size in bytes of the network packets used to communicate with an instance of server. | No |
| pooling | The allowed values are true or false. When you specify true, the connection will be pooled. When you specify false, the connection will be explicitly opened every time the connection is requested. |
No |
SQL authentication
To use SQL authentication, in addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| userName | The user name used to connect to the server. | Yes |
| password | The password for the user name. Mark this field as SecureString to store it securely. Or, you can reference a secret stored in Azure Key Vault. | Yes |
Example: Use SQL authentication
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Use SQL authentication with a password in Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Use Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows authentication
To use Windows authentication, in addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| userName | Specify a user name. An example is domainname\username. | Yes |
| password | Specify a password for the user account you specified for the user name. Mark this field as SecureString to store it securely. Or, you can reference a secret stored in Azure Key Vault. | Yes |
Example: Use Windows authentication
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Legacy version
These generic properties are supported for an Amazon RDS for SQL Server linked service when you apply Legacy version:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to AmazonRdsForSqlServer. | Yes |
| alwaysEncryptedSettings | Specify alwaysencryptedsettings information that's needed to enable Always Encrypted to protect sensitive data stored in Amazon RDS for SQL Server by using either managed identity or service principal. For more information, see Using Always Encrypted section. If not specified, the default always encrypted setting is disabled. | No |
| connectVia | This integration runtime is used to connect to the data store. Learn more from Prerequisites section. If not specified, the default Azure integration runtime is used. | No |
This Amazon RDS for SQL Server connector supports the following authentication types. See the corresponding sections for details.
SQL authentication for the legacy version
To use SQL authentication, in addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| connectionString | Specify connectionString information that's needed to connect to the Amazon RDS for SQL Server database. Specify a login name as your user name, and ensure the database that you want to connect is mapped to this login. | Yes |
| password | If you want to put a password in Azure Key Vault, pull the password configuration out of the connection string. For more information, see Store credentials in Azure Key Vault. |
No |
Windows authentication for the legacy version
To use Windows authentication, in addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| connectionString | Specify connectionString information that's needed to connect to the the Amazon RDS for SQL Server database. | Yes |
| userName | Specify a user name. An example is domainname\username. | Yes |
| password | Specify a password for the user account you specified for the user name. Mark this field as SecureString to store it securely. Or, you can reference a secret stored in Azure Key Vault. | Yes |
Dataset properties
For a full list of sections and properties available for defining datasets, see the datasets article. This section provides a list of properties supported by the Amazon RDS for SQL Server dataset.
To copy data from an Amazon RDS for SQL Server database, the following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to AmazonRdsForSqlServerTable. | Yes |
| schema | Name of the schema. | No |
| table | Name of the table/view. | No |
| tableName | Name of the table/view with schema. This property is supported for backward compatibility. For new workload, use schema and table. |
No |
Example
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Copy activity properties
For a full list of sections and properties available for use to define activities, see the Pipelines article. This section provides a list of properties supported by the Amazon RDS for SQL Server source.
Amazon RDS for SQL Server as a source
Tip
To load data from Amazon RDS for SQL Server efficiently by using data partitioning, learn more from Parallel copy from SQL database.
To copy data from Amazon RDS for SQL Server, set the source type in the copy activity to AmazonRdsForSqlServerSource. The following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to AmazonRdsForSqlServerSource. | Yes |
| sqlReaderQuery | Use the custom SQL query to read data. An example is select * from MyTable. |
No |
| sqlReaderStoredProcedureName | This property is the name of the stored procedure that reads data from the source table. The last SQL statement must be a SELECT statement in the stored procedure. | No |
| storedProcedureParameters | These parameters are for the stored procedure. Allowed values are name or value pairs. The names and casing of parameters must match the names and casing of the stored procedure parameters. |
No |
| isolationLevel | Specifies the transaction locking behavior for the SQL source. The allowed values are: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. If not specified, the database's default isolation level is used. Refer to this doc for more details. | No |
| partitionOptions | Specifies the data partitioning options used to load data from Amazon RDS for SQL Server. Allowed values are: None (default), PhysicalPartitionsOfTable, and DynamicRange. When a partition option is enabled (that is, not None), the degree of parallelism to concurrently load data from Amazon RDS for SQL Server is controlled by the parallelCopies setting on the copy activity. |
No |
| partitionSettings | Specify the group of the settings for data partitioning. Apply when the partition option isn't None. |
No |
Under partitionSettings: |
||
| partitionColumnName | Specify the name of the source column in integer or date/datetime type (int, smallint, bigint, date, smalldatetime, datetime, datetime2, or datetimeoffset) that will be used by range partitioning for parallel copy. If not specified, the index or the primary key of the table is auto-detected and used as the partition column.Apply when the partition option is DynamicRange. If you use a query to retrieve the source data, hook ?DfDynamicRangePartitionCondition in the WHERE clause. For an example, see the Parallel copy from SQL database section. |
No |
| partitionUpperBound | The maximum value of the partition column for partition range splitting. This value is used to decide the partition stride, not for filtering the rows in table. All rows in the table or query result will be partitioned and copied. If not specified, copy activity auto detect the value. Apply when the partition option is DynamicRange. For an example, see the Parallel copy from SQL database section. |
No |
| partitionLowerBound | The minimum value of the partition column for partition range splitting. This value is used to decide the partition stride, not for filtering the rows in table. All rows in the table or query result will be partitioned and copied. If not specified, copy activity auto detect the value. Apply when the partition option is DynamicRange. For an example, see the Parallel copy from SQL database section. |
No |
Note the following points:
- If sqlReaderQuery is specified for AmazonRdsForSqlServerSource, the copy activity runs this query against the Amazon RDS for SQL Server source to get the data. You also can specify a stored procedure by specifying sqlReaderStoredProcedureName and storedProcedureParameters if the stored procedure takes parameters.
- When using stored procedure in source to retrieve data, note if your stored procedure is designed as returning different schema when different parameter value is passed in, you may encounter failure or see unexpected result when importing schema from UI or when copying data to SQL database with auto table creation.
Example: Use SQL query
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Example: Use a stored procedure
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
The stored procedure definition
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Parallel copy from SQL database
The Amazon RDS for SQL Server connector in copy activity provides built-in data partitioning to copy data in parallel. You can find data partitioning options on the Source tab of the copy activity.
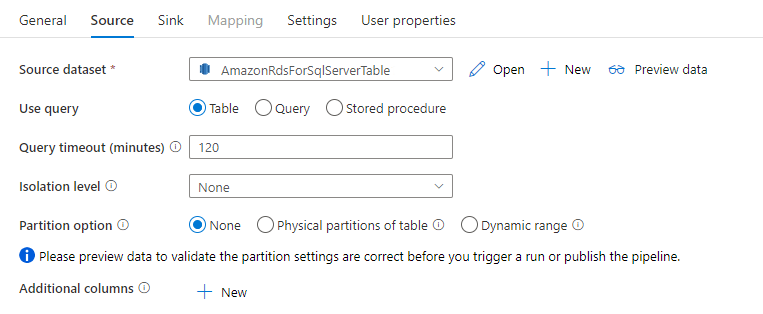
When you enable partitioned copy, copy activity runs parallel queries against your Amazon RDS for SQL Server source to load data by partitions. The parallel degree is controlled by the parallelCopies setting on the copy activity. For example, if you set parallelCopies to four, the service concurrently generates and runs four queries based on your specified partition option and settings, and each query retrieves a portion of data from your Amazon RDS for SQL Server.
You are suggested to enable parallel copy with data partitioning especially when you load large amount of data from your Amazon RDS for SQL Server. The following are suggested configurations for different scenarios. When copying data into file-based data store, it's recommended to write to a folder as multiple files (only specify folder name), in which case the performance is better than writing to a single file.
| Scenario | Suggested settings |
|---|---|
| Full load from large table, with physical partitions. | Partition option: Physical partitions of table. During execution, the service automatically detects the physical partitions, and copies data by partitions. To check if your table has physical partition or not, you can refer to this query. |
| Full load from large table, without physical partitions, while with an integer or datetime column for data partitioning. | Partition options: Dynamic range partition. Partition column (optional): Specify the column used to partition data. If not specified, the primary key column is used. Partition upper bound and partition lower bound (optional): Specify if you want to determine the partition stride. This is not for filtering the rows in table, all rows in the table will be partitioned and copied. If not specified, copy activity auto detects the values and it can take long time depending on MIN and MAX values. It is recommended to provide upper bound and lower bound. For example, if your partition column "ID" has values range from 1 to 100, and you set the lower bound as 20 and the upper bound as 80, with parallel copy as 4, the service retrieves data by 4 partitions - IDs in range <=20, [21, 50], [51, 80], and >=81, respectively. |
| Load a large amount of data by using a custom query, without physical partitions, while with an integer or date/datetime column for data partitioning. | Partition options: Dynamic range partition. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partition column: Specify the column used to partition data. Partition upper bound and partition lower bound (optional): Specify if you want to determine the partition stride. This is not for filtering the rows in table, all rows in the query result will be partitioned and copied. If not specified, copy activity auto detect the value. For example, if your partition column "ID" has values range from 1 to 100, and you set the lower bound as 20 and the upper bound as 80, with parallel copy as 4, the service retrieves data by 4 partitions- IDs in range <=20, [21, 50], [51, 80], and >=81, respectively. Here are more sample queries for different scenarios: 1. Query the whole table: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Query from a table with column selection and additional where-clause filters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query with subqueries: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query with partition in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Best practices to load data with partition option:
- Choose distinctive column as partition column (like primary key or unique key) to avoid data skew.
- If the table has built-in partition, use partition option "Physical partitions of table" to get better performance.
- If you use Azure Integration Runtime to copy data, you can set larger "Data Integration Units (DIU)" (>4) to utilize more computing resource. Check the applicable scenarios there.
- "Degree of copy parallelism" control the partition numbers, setting this number too large sometime hurts the performance, recommend setting this number as (DIU or number of Self-hosted IR nodes) * (2 to 4).
Example: full load from large table with physical partitions
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Example: query with dynamic range partition
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Sample query to check physical partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
If the table has physical partition, you would see "HasPartition" as "yes" like the following.

Lookup activity properties
To learn details about the properties, check Lookup activity.
GetMetadata activity properties
To learn details about the properties, check GetMetadata activity
Using Always Encrypted
When you copy data from/to Amazon RDS for SQL Server with Always Encrypted, follow below steps:
Store the Column Master Key (CMK) in an Azure Key Vault. Learn more on how to configure Always Encrypted by using Azure Key Vault
Make sure to grant access to the key vault where the Column Master Key (CMK) is stored. Refer to this article for required permissions.
Create linked service to connect to your SQL database and enable 'Always Encrypted' function by using either managed identity or service principal.
Troubleshoot connection issues
Configure your Amazon RDS for SQL Server instance to accept remote connections. Start Amazon RDS for SQL Server Management Studio, right-click server, and select Properties. Select Connections from the list, and select the Allow remote connections to this server check box.
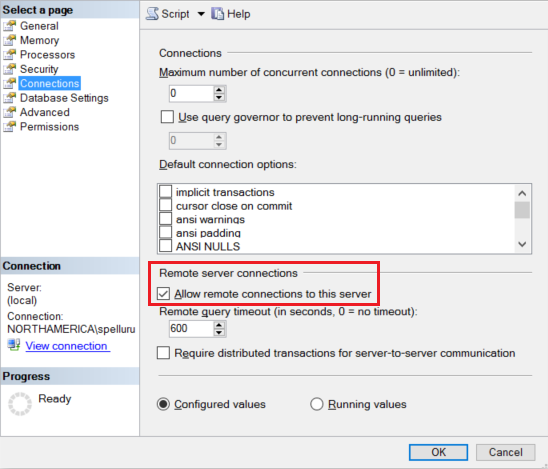
For detailed steps, see Configure the remote access server configuration option.
Start Amazon RDS for SQL Server Configuration Manager. Expand Amazon RDS for SQL Server Network Configuration for the instance you want, and select Protocols for MSSQLSERVER. Protocols appear in the right pane. Enable TCP/IP by right-clicking TCP/IP and selecting Enable.
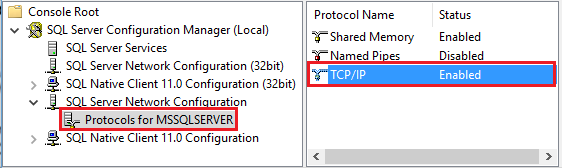
For more information and alternate ways of enabling TCP/IP protocol, see Enable or disable a server network protocol.
In the same window, double-click TCP/IP to launch the TCP/IP Properties window.
Switch to the IP Addresses tab. Scroll down to see the IPAll section. Write down the TCP Port. The default is 1433.
Create a rule for the Windows Firewall on the machine to allow incoming traffic through this port.
Verify connection: To connect to Amazon RDS for SQL Server by using a fully qualified name, use Amazon RDS for SQL Server Management Studio from a different machine. An example is
"<machine>.<domain>.corp.<company>.com,1433".
Upgrade the Amazon RDS for SQL Server version
To upgrade the Amazon RDS for SQL Server version, in Edit linked service page, select Recommended under Version and configure the linked service by referring to Linked service properties for the recommended version.
Differences between the recommended and the legacy version
The table below shows the differences between Amazon RDS for SQL Server using the recommended and the legacy version.
| Recommended version | Legacy version |
|---|---|
Support TLS 1.3 via encrypt as strict. |
TLS 1.3 is not supported. |
Related content
For a list of data stores supported as sources and sinks by the copy activity, see Supported data stores.