Full text search in Azure AI Search
Full text search is an approach in information retrieval that matches on plain text stored in an index. For example, given a query string "hotels in San Diego on the beach", the search engine looks for tokenized strings based on those terms. To make scans more efficient, query strings undergo lexical analysis: lower-casing all terms, removing stop words like "the", and reducing terms to primitive root forms. When matching terms are found, the search engine retrieves documents, ranks them in order of relevance, and returns the top results.
Query execution can be complex. This article is for developers who need a deeper understanding of how full text search works in Azure AI Search. For text queries, Azure AI Search seamlessly delivers expected results in most scenarios, but occasionally you might get a result that seems "off" somehow. In these situations, having a background in the four stages of Lucene query execution (query parsing, lexical analysis, document matching, scoring) can help you identify specific changes to query parameters or index configuration that produce the desired outcome.
Note
Azure AI Search uses Apache Lucene for full text search, but Lucene integration is not exhaustive. We selectively expose and extend Lucene functionality to enable the scenarios important to Azure AI Search.
Architecture overview and diagram
Query execution has four stages:
- Query parsing
- Lexical analysis
- Document retrieval
- Scoring
A full text search query starts with parsing the query text to extract search terms and operators. There are two parsers so that you can choose between speed and complexity. An analysis phase is next, where individual query terms are sometimes broken down and reconstituted into new forms. This step helps to cast a broader net over what could be considered as a potential match. The search engine then scans the index to find documents with matching terms and scores each match. A result set is then sorted by a relevance score assigned to each individual matching document. Those at the top of the ranked list are returned to the calling application.
The diagram below illustrates the components used to process a search request.
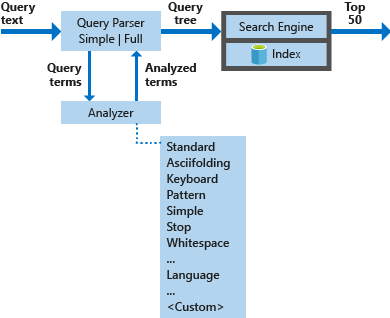
| Key components | Functional description |
|---|---|
| Query parsers | Separate query terms from query operators and create the query structure (a query tree) to be sent to the search engine. |
| Analyzers | Perform lexical analysis on query terms. This process can involve transforming, removing, or expanding of query terms. |
| Index | An efficient data structure used to store and organize searchable terms extracted from indexed documents. |
| Search engine | Retrieves and scores matching documents based on the contents of the inverted index. |
Anatomy of a search request
A search request is a complete specification of what should be returned in a result set. In simplest form, it's an empty query with no criteria of any kind. A more realistic example includes parameters, several query terms, perhaps scoped to certain fields, with possibly a filter expression and ordering rules.
The following example is a search request you might send to Azure AI Search using the REST API.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
For this request, the search engine does the following operations:
Finds documents where the price is at least $60 and less than $300.
Executes the query. In this example, the search query consists of phrases and terms:
"Spacious, air-condition* +\"Ocean view\""(users typically don't enter punctuation, but including it in the example allows us to explain how analyzers handle it).For this query, the search engine scans the description and title fields specified in "searchFields" for documents that contain
"Ocean view", and additionally on the term"spacious", or on terms that start with the prefix"air-condition". The "searchMode" parameter is used to match on any term (default) or all of them, for cases where a term isn't explicitly required (+).Orders the resulting set of hotels by proximity to a given geography location, and then returns the results to the calling application.
Most this article is about processing of the search query: "Spacious, air-condition* +\"Ocean view\"". Filtering and ordering are out of scope. For more information, see the Search API reference documentation.
Stage 1: Query parsing
As noted, the query string is the first line of the request:
"search": "Spacious, air-condition* +\"Ocean view\"",
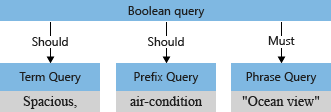
The query parser separates operators (such as * and + in the example) from search terms, and deconstructs the search query into subqueries of a supported type:
- term query for standalone terms (like spacious)
- phrase query for quoted terms (like ocean view)
- prefix query for terms followed by a prefix operator
*(like air-condition)
For a full list of supported query types, see Lucene query syntax
Operators associated with a subquery determine whether the query "must be" or "should be" satisfied in order for a document to be considered a match. For example, +"Ocean view" is "must" due to the + operator.
The query parser restructures the subqueries into a query tree (an internal structure representing the query) it passes on to the search engine. In the first stage of query parsing, the query tree looks like this.
Supported parsers: Simple and Full Lucene
Azure AI Search exposes two different query languages, simple (default) and full. By setting the queryType parameter with your search request, you tell the query parser which query language you choose so that it knows how to interpret the operators and syntax.
The Simple query language is intuitive and robust, often suitable to interpret user input as-is without client-side processing. It supports query operators familiar from web search engines.
The Full Lucene query language, which you get by setting
queryType=full, extends the default Simple query language by adding support for more operators and query types like wildcard, fuzzy, regex, and field-scoped queries. For example, a regular expression sent in Simple query syntax would be interpreted as a query string and not an expression. The example request in this article uses the Full Lucene query language.
Impact of searchMode on the parser
Another search request parameter that affects parsing is the "searchMode" parameter. It controls the default operator for Boolean queries: any (default) or all.
When "searchMode=any", which is the default, the space delimiter between spacious and air-condition is OR (||), making the sample query text equivalent to:
Spacious,||air-condition*+"Ocean view"
Explicit operators, such as + in +"Ocean view", are unambiguous in boolean query construction (the term must match). Less obvious is how to interpret the remaining terms: spacious and air-condition. Should the search engine find matches on ocean view and spacious and air-condition? Or should it find ocean view plus either one of the remaining terms?
By default ("searchMode=any"), the search engine assumes the broader interpretation. Either field should be matched, reflecting "or" semantics. The initial query tree illustrated previously, with the two "should" operations, shows the default.
Suppose that we now set "searchMode=all". In this case, the space is interpreted as an "and" operation. Each of the remaining terms must both be present in the document to qualify as a match. The resulting sample query would be interpreted as follows:
+Spacious,+air-condition*+"Ocean view"
A modified query tree for this query would be as follows, where a matching document is the intersection of all three subqueries:

Note
Choosing "searchMode=any" over "searchMode=all" is a decision best arrived at by running representative queries. Users who are likely to include operators (common when searching document stores) might find results more intuitive if "searchMode=all" informs boolean query constructs. For more about the interplay between "searchMode" and operators, see Simple query syntax.
Stage 2: Lexical analysis
Lexical analyzers process term queries and phrase queries after the query tree is structured. An analyzer accepts the text inputs given to it by the parser, processes the text, and then sends back tokenized terms to be incorporated into the query tree.
The most common form of lexical analysis is *linguistic analysis that transforms query terms based on rules specific to a given language:
- Reducing a query term to the root form of a word
- Removing non-essential words (stopwords, such as "the" or "and" in English)
- Breaking a composite word into component parts
- Lower casing an upper case word
All of these operations tend to erase differences between the text input provided by the user and the terms stored in the index. Such operations go beyond text processing and require in-depth knowledge of the language itself. To add this layer of linguistic awareness, Azure AI Search supports a long list of language analyzers from both Lucene and Microsoft.
Note
Analysis requirements can range from minimal to elaborate depending on your scenario. You can control complexity of lexical analysis by the selecting one of the predefined analyzers or by creating your own custom analyzer. Analyzers are scoped to searchable fields and are specified as part of a field definition. This allows you to vary lexical analysis on a per-field basis. Unspecified, the standard Lucene analyzer is used.
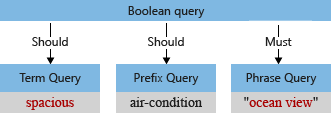
In our example, prior to analysis, the initial query tree has the term "Spacious," with an uppercase "S" and a comma that the query parser interprets as a part of the query term (a comma isn't considered a query language operator).
When the default analyzer processes the term, it will lowercase "ocean view" and "spacious", and remove the comma character. The modified query tree looks like:
Testing analyzer behaviors
The behavior of an analyzer can be tested using the Analyze API. Provide the text you want to analyze to see what terms given analyzer generates. For example, to see how the standard analyzer would process the text "air-condition", you can issue the following request:
{
"text": "air-condition",
"analyzer": "standard"
}
The standard analyzer breaks the input text into the following two tokens, annotating them with attributes like start and end offsets (used for hit highlighting) as well as their position (used for phrase matching):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Exceptions to lexical analysis
Lexical analysis applies only to query types that require complete terms – either a term query or a phrase query. It doesn’t apply to query types with incomplete terms – prefix query, wildcard query, regex query – or to a fuzzy query. Those query types, including the prefix query with term air-condition* in our example, are added directly to the query tree, bypassing the analysis stage. The only transformation performed on query terms of those types is lowercasing.
Stage 3: Document retrieval
Document retrieval refers to finding documents with matching terms in the index. This stage is understood best through an example. Let's start with a hotels index having the following simple schema:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Further assume that this index contains the following four documents:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
How terms are indexed
To understand retrieval, it helps to know a few basics about indexing. The unit of storage is an inverted index, one for each searchable field. Within an inverted index is a sorted list of all terms from all documents. Each term maps to the list of documents in which it occurs, as evident in the example below.
To produce the terms in an inverted index, the search engine performs lexical analysis over the content of documents, similar to what happens during query processing:
- Text inputs are passed to an analyzer, lower-cased, stripped of punctuation, and so forth, depending on the analyzer configuration.
- Tokens are the output of lexical analysis.
- Terms are added to the index.
It's common, but not required, to use the same analyzers for search and indexing operations so that query terms look more like terms inside the index.
Note
Azure AI Search lets you specify different analyzers for indexing and search via additional indexAnalyzer and searchAnalyzer field parameters. If unspecified, the analyzer set with the analyzer property is used for both indexing and searching.
Inverted index for example documents
Returning to our example, for the title field, the inverted index looks like this:
| Term | Document list |
|---|---|
| atman | 1 |
| beach | 2 |
| hotel | 1, 3 |
| ocean | 4 |
| playa | 3 |
| resort | 3 |
| retreat | 4 |
In the title field, only hotel shows up in two documents: 1, 3.
For the description field, the index is as follows:
| Term | Document list |
|---|---|
| air | 3 |
| and | 4 |
| beach | 1 |
| conditioned | 3 |
| comfortable | 3 |
| distance | 1 |
| island | 2 |
| kauaʻi | 2 |
| located | 2 |
| north | 2 |
| ocean | 1, 2, 3 |
| of | 2 |
| on | 2 |
| quiet | 4 |
| rooms | 1, 3 |
| secluded | 4 |
| shore | 2 |
| spacious | 1 |
| the | 1, 2 |
| to | 1 |
| view | 1, 2, 3 |
| walking | 1 |
| with | 3 |
Matching query terms against indexed terms
Given the inverted indexes above, let’s return to the sample query and see how matching documents are found for our example query. Recall that the final query tree looks like this:
During query execution, individual queries are executed against the searchable fields independently.
The TermQuery, "spacious", matches document 1 (Hotel Atman).
The PrefixQuery, "air-condition*", doesn't match any documents.
This is a behavior that sometimes confuses developers. Although the term air-conditioned exists in the document, it's split into two terms by the default analyzer. Recall that prefix queries, which contain partial terms, aren't analyzed. Therefore terms with prefix "air-condition" are looked up in the inverted index and not found.
The PhraseQuery, "ocean view", looks up the terms "ocean" and "view" and checks the proximity of terms in the original document. Documents 1, 2 and 3 match this query in the description field. Notice document 4 has the term ocean in the title but isn’t considered a match, as we're looking for the "ocean view" phrase rather than individual words.
Note
A search query is executed independently against all searchable fields in the Azure AI Search index unless you limit the fields set with the searchFields parameter, as illustrated in the example search request. Documents that match in any of the selected fields are returned.
On the whole, for the query in question, the documents that match are 1, 2, 3.
Stage 4: Scoring
Every document in a search result set is assigned a relevance score. The function of the relevance score is to rank higher those documents that best answer a user question as expressed by the search query. The score is computed based on statistical properties of terms that matched. At the core of the scoring formula is TF/IDF (term frequency-inverse document frequency). In queries containing rare and common terms, TF/IDF promotes results containing the rare term. For example, in a hypothetical index with all Wikipedia articles, from documents that matched the query the president, documents matching on president are considered more relevant than documents matching on the.
Scoring example
Recall the three documents that matched our example query:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Document 1 matched the query best because both the term spacious and the required phrase ocean view occur in the description field. The next two documents match only the phrase ocean view. It might be surprising that the relevance score for document 2 and 3 is different even though they matched the query in the same way. It's because the scoring formula has more components than just TF/IDF. In this case, document 3 was assigned a slightly higher score because its description is shorter. Learn about Lucene's Practical Scoring Formula to understand how field length and other factors can influence the relevance score.
Some query types (wildcard, prefix, regex) always contribute a constant score to the overall document score. This allows matches found through query expansion to be included in the results, but without affecting the ranking.
An example illustrates why this matters. Wildcard searches, including prefix searches, are ambiguous by definition because the input is a partial string with potential matches on a very large number of disparate terms (consider an input of "tour*", with matches found on “tours”, “tourettes”, and “tourmaline”). Given the nature of these results, there's no way to reasonably infer which terms are more valuable than others. For this reason, we ignore term frequencies when scoring results in queries of types wildcard, prefix and regex. In a multi-part search request that includes partial and complete terms, results from the partial input are incorporated with a constant score to avoid bias towards potentially unexpected matches.
Relevance tuning
There are two ways to tune relevance scores in Azure AI Search:
Scoring profiles promote documents in the ranked list of results based on a set of rules. In our example, we could consider documents that matched in the title field more relevant than documents that matched in the description field. Additionally, if our index had a price field for each hotel, we could promote documents with lower price. Learn more about adding scoring profiles to a search index.
Term boosting (available only in the Full Lucene query syntax) provides a boosting operator
^that can be applied to any part of the query tree. In our example, instead of searching on the prefix air-condition*, one could search for either the exact term air-condition or the prefix, but documents that match on the exact term are ranked higher by applying boost to the term query: air-condition^2||air-condition*. Learn more about term boosting in a query.
Scoring in a distributed index
All indexes in Azure AI Search are automatically split into multiple shards, allowing us to quickly distribute the index among multiple nodes during service scale up or scale down. When a search request is issued, it’s issued against each shard independently. The results from each shard are then merged and ordered by score (if no other ordering is defined). It's important to know that the scoring function weights query term frequency against its inverse document frequency in all documents within the shard, not across all shards!
This means a relevance score could be different for identical documents if they reside on different shards. Fortunately, such differences tend to disappear as the number of documents in the index grows due to more even term distribution. It’s not possible to assume on which shard any given document will be placed. However, assuming a document key doesn't change, it will always be assigned to the same shard.
In general, document score isn't the best attribute for ordering documents if order stability is important. For example, given two documents with an identical score, there's no guarantee that one appears first in subsequent runs of the same query. Document score should only give a general sense of document relevance relative to other documents in the results set.
Conclusion
The success of commercial search engines has raised expectations for full text search over private data. For almost any kind of search experience, we now expect the engine to understand our intent, even when terms are misspelled or incomplete. We might even expect matches based on near equivalent terms or synonyms that we never specified.
From a technical standpoint, full text search is highly complex, requiring sophisticated linguistic analysis and a systematic approach to processing in ways that distill, expand, and transform query terms to deliver a relevant result. Given the inherent complexities, there are many factors that can affect the outcome of a query. For this reason, investing the time to understand the mechanics of full text search offers tangible benefits when trying to work through unexpected results.
This article explored full text search in the context of Azure AI Search. We hope it gives you sufficient background to recognize potential causes and resolutions for addressing common query problems.
Next steps
Build the sample index, try out different queries and review results. For instructions, see Build and query an index in the portal.
Try other query syntax from the Search Documents example section or from Simple query syntax in Search explorer in the portal.
Review scoring profiles if you want to tune ranking in your search application.
Learn how to apply language-specific lexical analyzers.
Configure custom analyzers for either minimal processing or specialized processing on specific fields.