Tutorial: Detección y análisis de anomalías mediante funcionalidades de aprendizaje automático de KQL en Azure Monitor
Lenguaje de consulta Kusto (KQL) incluye operadores de aprendizaje automático, funciones y complementos para el análisis de series temporales, detección de anomalías, previsión y análisis de causa principal. Use estas funcionalidades de KQL para realizar análisis avanzados de datos en Azure Monitor sin la sobrecarga de exportar datos a herramientas de aprendizaje automático externas.
En este tutorial, aprenderá a:
- Creación de una serie temporal
- Identificación de anomalías en una serie temporal
- Ajuste de la configuración de detección de anomalías para refinar los resultados
- Análisis de la causa principal de anomalías
Nota
En este tutorial se proporcionan vínculos a un entorno de demostración de Log Analytics en el que puede ejecutar los ejemplos de consultas de KQL. Sin embargo, puede implementar las mismas consultas y entidades de seguridad de KQL en todas las herramientas de Azure Monitor que usan KQL.
Requisitos previos
- Una cuenta de Azure con una suscripción activa. Cree una cuenta gratuita.
- Un área de trabajo con datos de registro.
Permisos necesarios
Debe tener los permisos de Microsoft.OperationalInsights/workspaces/query/*/read para las áreas de trabajo de Log Analytics que consulte, tal y como los proporciona el Rol integrado de lector de Log Analytics, por ejemplo.
Creación de una serie temporal
Use el operador make-series de KQL para crear una serie temporal.
Vamos a crear una serie temporal basada en los registros de la tabla de uso, que contiene información sobre la cantidad de datos que cada tabla de un área de trabajo ingiere cada hora, incluidos los datos facturables y no facturables.
Esta consulta usa make-series para trazar la cantidad total de datos facturables ingeridos por cada tabla del área de trabajo todos los días, en los últimos 21 días:
Haga clic para ejecutar la consulta
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
En el gráfico resultante, puede ver claramente algunas anomalías, por ejemplo, en los tipos de datos AzureDiagnostics y SecurityEvent:
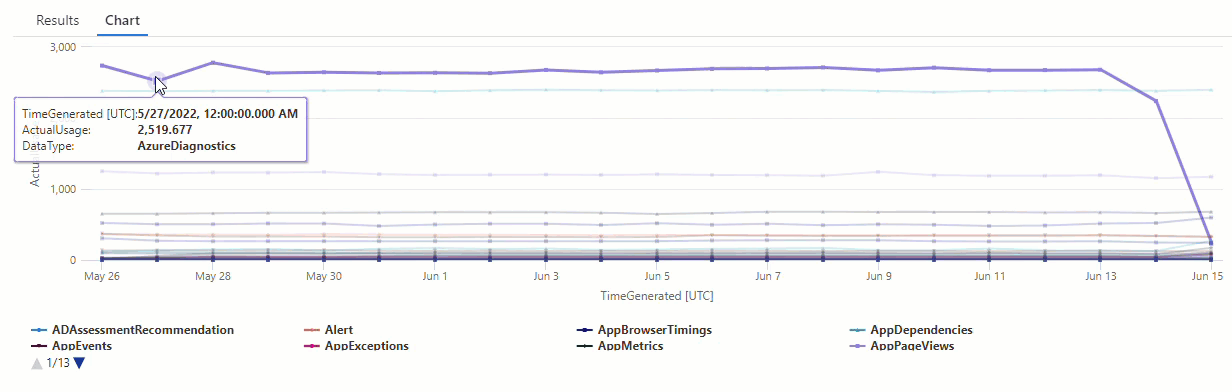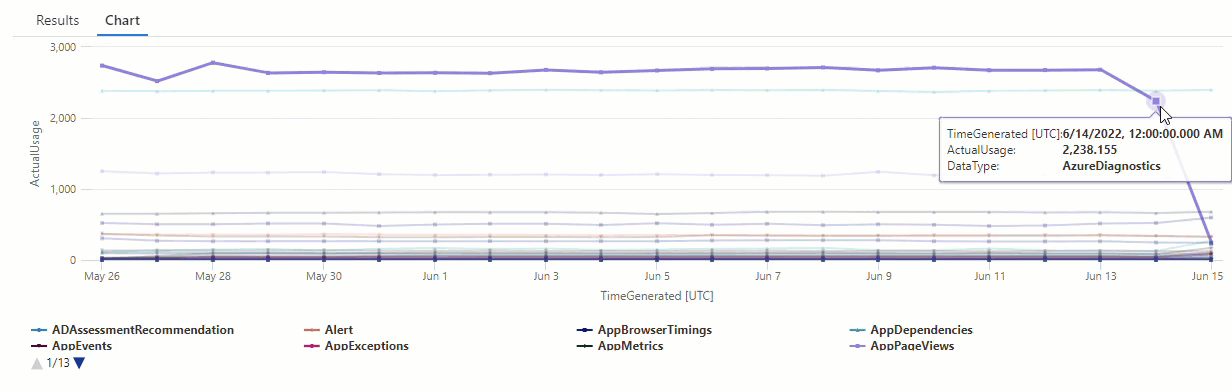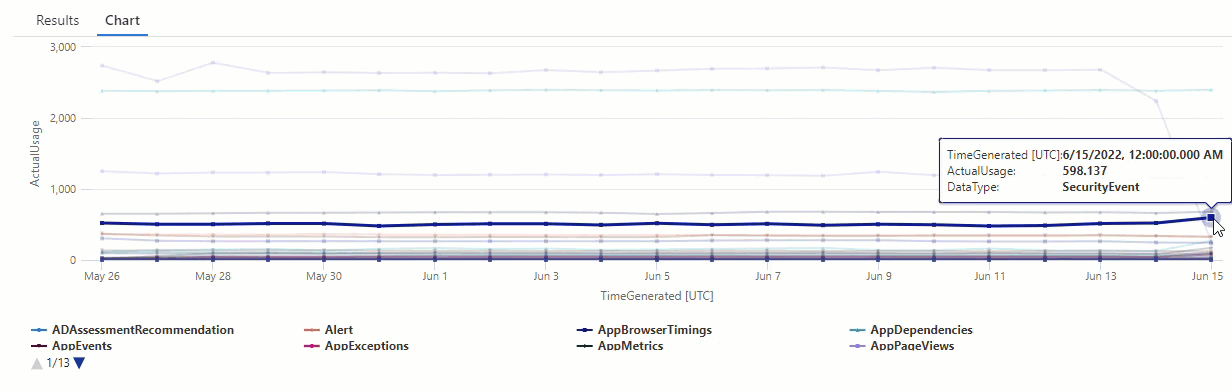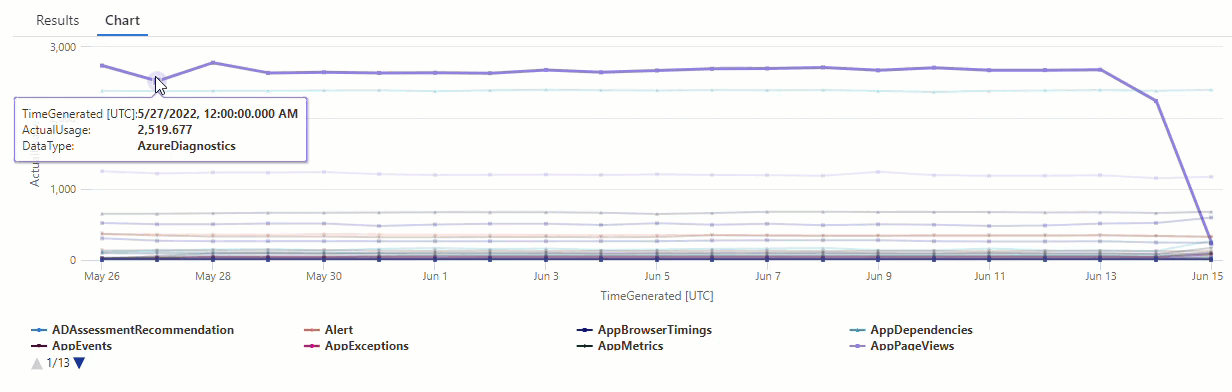
A continuación, usaremos una función KQL para enumerar todas las anomalías de una serie temporal.
Nota
Para más información sobre la sintaxis y el uso de make-series, consulte Operador make-series.
Búsqueda de anomalías en una serie temporal
La función series_decompose_anomalies() toma una serie de valores como entrada y extrae anomalías.
Vamos a proporcionar el conjunto de resultados de nuestra consulta de serie temporal como entrada a la función series_decompose_anomalies():
Haga clic para ejecutar la consulta
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Esta consulta devuelve todas las anomalías de uso de todas las tablas de las últimas tres semanas:

Al examinar los resultados de la consulta, puede ver que la función:
- Calcula un uso diario esperado para cada tabla.
- Compara el uso diario real con el uso esperado.
- Asigna una puntuación de anomalías a cada punto de datos, lo que indica la extensión de la desviación del uso real del uso esperado.
- Identifica anomalías positivas (
1) y negativas (-1) en cada tabla.
Nota
Para más información sobre la sintaxis y el uso de series_decompose_anomalies(), consulte series_decompose_anomalies().
Ajuste de la configuración de detección de anomalías para refinar los resultados
Es recomendable revisar los resultados iniciales de la consulta y realizar ajustes en esta, si es necesario. Los valores atípicos de los datos de entrada pueden afectar al aprendizaje de la función y es posible que tenga que ajustar la configuración de detección de anomalías de la función para obtener resultados más precisos.
Filtre los resultados de la consulta series_decompose_anomalies() para detectar anomalías en el tipo de datos AzureDiagnostics:

Los resultados muestran dos anomalías el 14 de junio y el 15 de junio. Compare estos resultados con el gráfico de nuestra primera consulta make-series, donde puede ver otras anomalías el 27 y el 28 de mayo:

La diferencia en los resultados se produce porque la función series_decompose_anomalies() puntúa anomalías en relación con el valor de uso esperado, que la función calcula en función del intervalo completo de valores de la serie de entrada.
Para obtener resultados más refinados de la función, excluya el uso del 15 de junio, que es un valor atípico en comparación con los demás valores de la serie, del proceso de aprendizaje de la función.
La sintaxis de la función series_decompose_anomalies() es:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points especifica el número de puntos al final de la serie que se excluirán del proceso de aprendizaje (regresión).
Para excluir el último punto de datos, establezca Test_points en 1:
Haga clic para ejecutar la consulta
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filtre los resultados del tipo de datos AzureDiagnostics:

Todas las anomalías del gráfico de la primera consulta make-series aparecen ahora en el conjunto de resultados.
Análisis de la causa principal de anomalías
Comparar los valores esperados con valores anómalos le ayuda a comprender la causa de las diferencias entre los dos conjuntos.
El complemento diffpatterns() de KQL compara dos conjuntos de datos de la misma estructura y busca patrones que caracterizan las diferencias entre los dos conjuntos de datos.
Esta consulta compara el uso AzureDiagnostics del 15 de junio, el valor atípico extremo en nuestro ejemplo, con el uso de la tabla en otros días:
Haga clic para ejecutar la consulta
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
La consulta identifica cada entrada de la tabla como se produce en AnomalyDate (15 de junio) u OtherDates. A continuación, el complemento diffpatterns() divide estos conjuntos de datos, denominados A (OtherDates) y B (AnomalyDate) en nuestro ejemplo, y devuelve algunos patrones que contribuyen a las diferencias en los dos conjuntos:

Al examinar los resultados de la consulta, puede ver las siguientes diferencias:
- Hay 24 892 147 instancias de ingesta del recurso CH1-GEARAMAAKS en todos los demás días del intervalo de tiempo de consulta y no hay ingesta de datos de este recurso el 15 de junio. Los datos del recurso CH1-GEARAMAAKS tienen en cuenta el 73,36 % de la ingesta total en otros días en el intervalo de tiempo de consulta y el 0 % de la ingesta total el 15 de junio.
- Hay 2 168 448 instancias de ingesta del recurso NSG-TESTSQLMI519 en todos los demás días del intervalo de tiempo de consulta y 110 544 instancias de ingesta de este recurso el 15 de junio. Los datos del recurso NSG-TESTSQLMI519 tienen en cuenta el 6,39 % de la ingesta total en otros días en el intervalo de tiempo de consulta y el 25,61 % de ingesta el 15 de junio.
Observe que, en promedio, hay 108 422 instancias de ingesta del recurso NSG-TESTSQLMI519 durante los 20 días que componen el período de otros días (2 168 448 dividido entre 20). Por lo tanto, la ingesta del recurso NSG-TESTSQLMI519 el 15 de junio no es significativamente diferente de la ingesta de este recurso en otros días. Sin embargo, dado que no hay ninguna ingesta de CH1-GEARAMAAKS el 15 de junio, la ingesta de NSG-TESTSQLMI519 constituye un porcentaje significativamente mayor de la ingesta total en la fecha de anomalía en comparación con otros días.
La columna PercentDiffAB muestra la diferencia de punto porcentual absoluta entre A y B (PercentA - PercentB|), que es la medida principal de la diferencia entre los dos conjuntos. De forma predeterminada, el complemento diffpatterns() devuelve una diferencia de más del 5 % entre los dos conjuntos de datos, pero puede ajustar este umbral. Por ejemplo, para devolver solo las diferencias del 20 % o más entre los dos conjuntos de datos, puede establecer | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) en la consulta anterior. La consulta ahora solo devuelve un resultado:

Nota
Para más información sobre la sintaxis y el uso de diffpatterns(), consulte Complemento diffpaterns.
Pasos siguientes
Más información sobre:
Comentarios
Proximamente: Ao longo de 2024, retiraremos gradualmente GitHub Issues como mecanismo de comentarios sobre o contido e substituirémolo por un novo sistema de comentarios. Para obter máis información, consulte: https://aka.ms/ContentUserFeedback.
Enviar e ver os comentarios