Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Este tutorial le guiará a través de la creación y ejecución de una canalización de Azure Data Factory que ejecuta una carga de trabajo de Azure Batch. Un script de Python se ejecuta en los nodos de Batch para obtener la entrada de valor separado por comas (CSV) de un contenedor de Azure Blob Storage, manipular los datos y escribir la salida en otro contenedor de almacenamiento. Utilizas Batch Explorer para crear un pool de Batch y nodos. Utilizas Azure Storage Explorer para gestionar contenedores y archivos.
En este tutorial aprenderá a:
- Use Batch Explorer para crear un grupo y nodos de Batch.
- Use Explorador de Storage para crear contenedores de almacenamiento y cargar archivos de entrada.
- Desarrolle un script de Python para manipular los datos de entrada y generar la salida.
- Cree una canalización de Data Factory que ejecute la carga de trabajo de Batch.
- Use Batch Explorer para ver los archivos de registro de salida.
Prerrequisitos
- Una cuenta de Azure con una suscripción activa. En caso de no tener ninguna, cree una cuenta gratuita.
- Una cuenta de Batch con una cuenta de Azure Storage vinculada. Puede crear las cuentas mediante cualquiera de los siguientes métodos: Azure Portal | CLI de Azure | Bicep | Plantilla de ARM | Terraform.
- Una instancia de Data Factory. Para crear la factoría de datos, siga las instrucciones de Creación de una factoría de datos.
- Batch Explorer se ha descargado e instalado.
- Explorador de Storage se ha descargado e instalado.
-
Python 3.8 o posterior, con el paquete Azure-storage-blob instalado mediante
pip. - El conjunto de datos de entrada iris.csv descargado de GitHub.
Uso de Batch Explorer para crear un grupo Batch y nodos
Use Batch Explorer para crear un grupo de nodos de ejecución para ejecutar la carga de trabajo.
Inicie sesión en Batch Explorer con sus credenciales de Azure.
Seleccione la cuenta de Batch.
Seleccione Grupos en la barra lateral izquierda y luego seleccione el icono + para agregar un grupo.
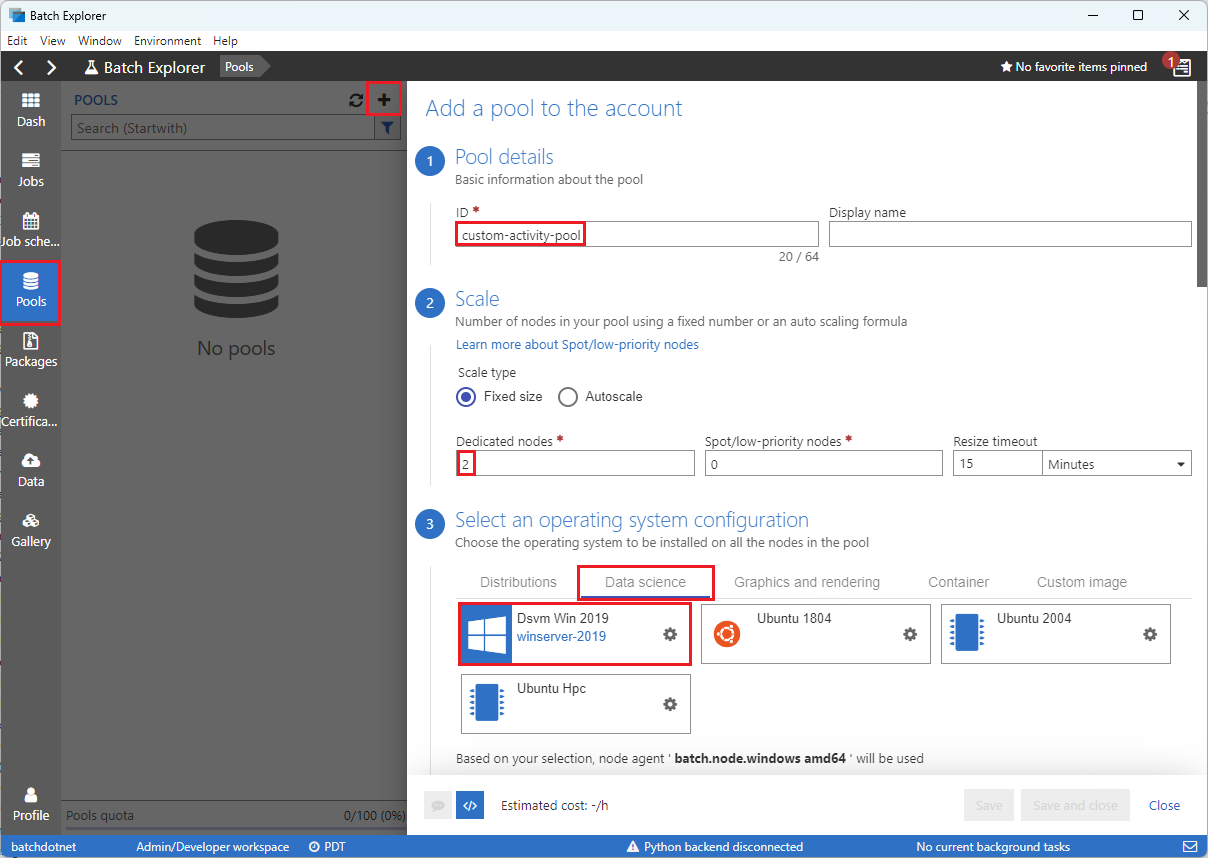
Complete el formulario Agregar un grupo a la cuenta de la siguiente manera:
- En Id., escriba custom-activity-pool.
- En Nodos dedicados, escriba 2.
- En Seleccionar una configuración de sistema operativo, seleccione la pestaña Ciencia de datos y, luego, seleccione Dsvm Win 2019.
- En Elegir un tamaño de máquina virtual, seleccione Standard_F2s_v2.
- En Tarea de inicio, seleccione Agregar una tarea de inicio.
En la pantalla de la tarea de inicio, en Línea de comandos, escriba
cmd /c "pip install azure-storage-blob pandas"y luego seleccione Seleccionar. Este comando instala el paqueteazure-storage-bloben cada nodo a medida que se inicia.
Haga clic en Guardar y cerrar.

Uso del Explorador de Storage para crear contenedores de blobs
Use el Explorador de Storage para crear contenedores de blobs para almacenar archivos de entrada y salida, y luego cargar los archivos de entrada.
- Inicie sesión en el Explorador de Storage con sus credenciales de Azure.
- En la barra lateral izquierda, busque y expanda la cuenta de almacenamiento vinculada a la cuenta de Batch.
- Haga clic con el botón derecho en Contenedores de blobs y seleccione Crear contenedor de blobs o seleccione Crear contenedor de blobs desde Acciones en la parte inferior de la barra lateral.
- Escriba entrada en el campo de entrada.
- Cree otro contenedor de blobs denominado output.
- Seleccione el contenedor input y luego seleccione Cargar>Cargar archivos en el panel derecho.
- En la pantalla Cargar archivos, en Archivos seleccionados, seleccione los puntos suspensivos ... junto al campo de entrada.
- Vaya a la ubicación del archivo descargado iris.csv, seleccione Abrir y luego seleccione Cargar.

Desarrollo de un script de Python
El siguiente script de Python carga el archivo de conjunto de datos iris.csv desde el contenedor input del Explorador de Storage, manipula los datos y guarda los resultados en el contenedor output.
El script debe usar la cadena de conexión para la cuenta de Azure Storage vinculada a la cuenta de Batch. Para obtener la cadena de conexión:
- En Azure Portal, busque y seleccione el nombre de la cuenta de almacenamiento vinculada a la cuenta de Batch.
- En la página de la cuenta de almacenamiento, seleccione Claves de acceso en el panel de navegación izquierdo en Seguridad y redes.
- En key1, seleccione Mostrar junto a Cadena de conexión y, luego, seleccione el icono Copiar para copiar la cadena de conexión.
Pegue la cadena de conexión en el siguiente script, reemplazando el marcador de posición <storage-account-connection-string>. Guarde el script como un archivo denominado main.py.
Importante
No se recomienda exponer las claves de cuenta en el origen de la aplicación para el uso de producción. Debes restringir el acceso a las credenciales y hacer referencia a ellas en tu código mediante el uso de variables o un archivo de configuración. Es mejor almacenar claves de cuenta de Batch y Storage en Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Para más información sobre cómo trabajar con Azure Blob Storage, consulte la documentación de Azure Blob Storage.
Ejecute el script localmente para probar y validar la funcionalidad.
python main.py
El script debe generar un archivo de salida denominado iris_setosa.csv que contenga solo los registros de datos que tengan Species = setosa. Después de comprobar que funciona correctamente, cargue el archivo de script main.py en el contenedor input de Explorador de Storage.
Configuración de una canalización de Data Factory
Cree y valide una canalización de Data Factory que use el script de Python.
Obtención de información de la cuenta
La canalización de Data Factory debe usar los nombres de cuenta de Batch y Storage, los valores de clave de cuenta y el punto de conexión de la cuenta de Batch. Para obtener esta información desde Azure Portal:
En la barra de Azure Search, busca y selecciona el nombre de la cuenta de Batch.
En la página Cuenta de Batch, seleccione Claves en el panel de navegación izquierdo.
En la página Claves, copia los valores siguientes:
- Cuenta de Batch
- Punto de conexión a la cuenta
- Clave de acceso principal
- Nombre de cuenta de almacenamiento
- Key1
Creación y ejecución de la canalización
Si Azure Data Factory Studio aún no se está ejecutando, seleccione Iniciar Studio en la página Data Factory de Azure Portal.
En Data Factory Studio, seleccione el icono de lápiz Autor en el panel de navegación izquierdo.
En Recursos de Fábrica, seleccione el icono +, y luego seleccione Tubería.
En el panel Propiedades de la derecha, cambie el nombre de la canalización a Ejecutar Python.
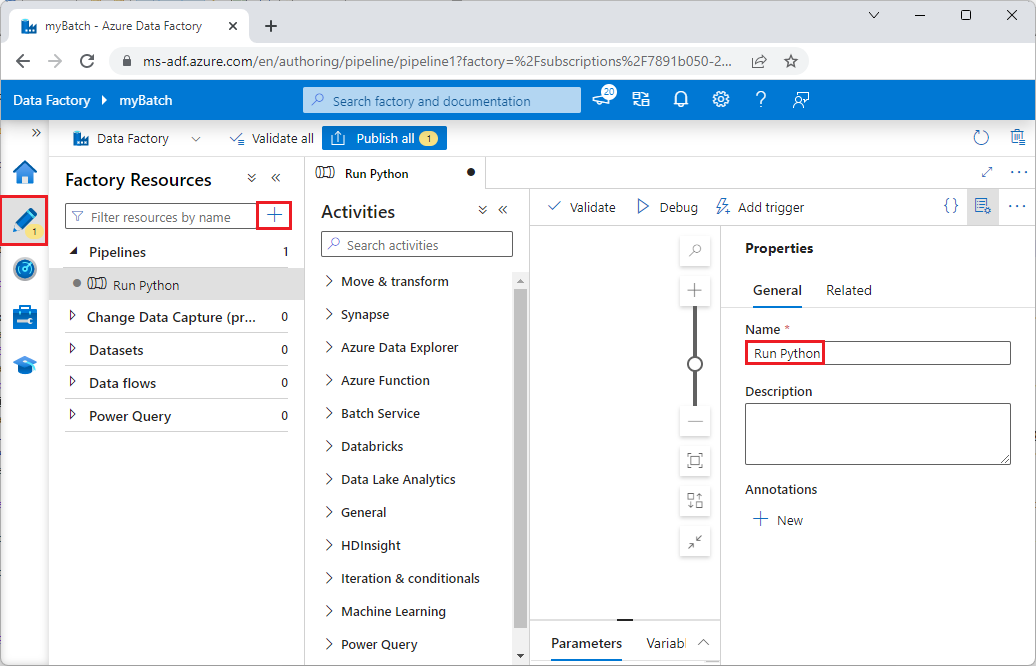
En el panel Actividades, expanda Servicio de Batch y arrastre la actividad Personalizado hasta la superficie del diseñador de canalizaciones.
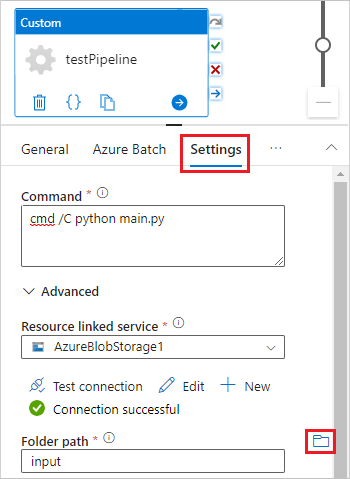
Debajo del lienzo del diseñador, en la pestaña General, escriba testPipeline en Nombre.
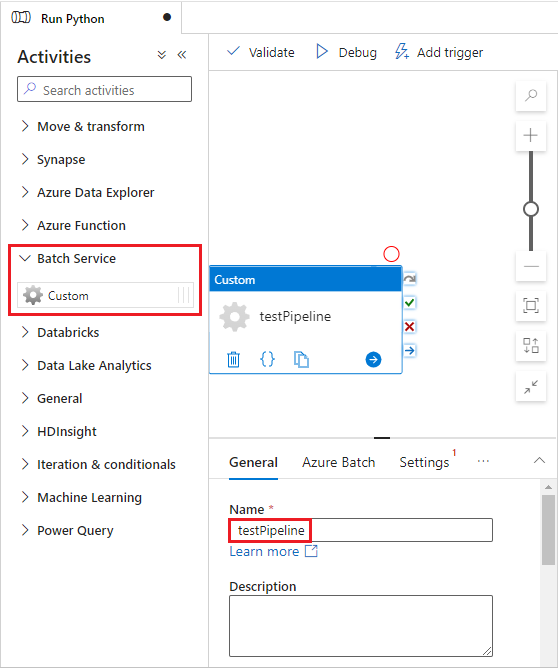
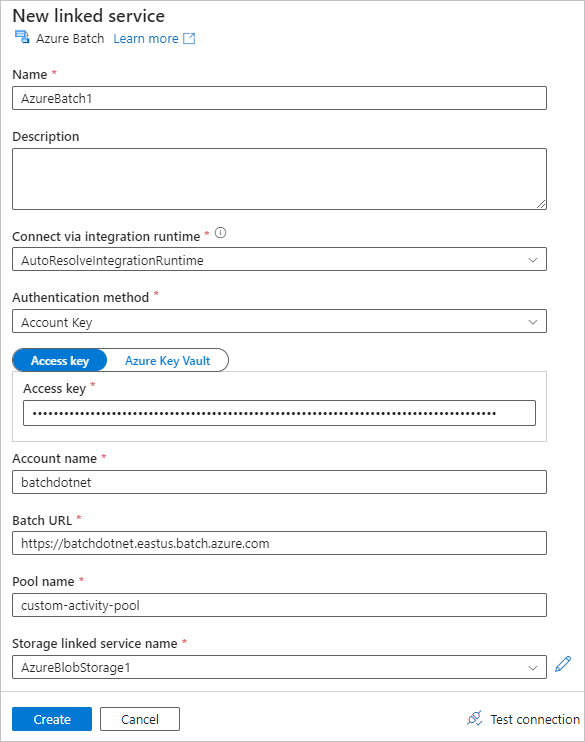
Seleccione la pestaña Azure Batch y, luego, seleccione Nuevo.
Complete el formulario Nuevo servicio vinculado de la siguiente manera:
- Nombre: escriba un nombre para el servicio vinculado, como AzureBatch1.
- Clave de acceso: escriba la clave de acceso principal que ha copiado de la cuenta de Batch.
- Nombre de cuenta: escriba el nombre de la cuenta de Batch.
-
Dirección URL de Batch: escriba el punto de conexión de cuenta que copió de la cuenta de Batch, como
https://batchdotnet.eastus.batch.azure.com. - Nombre del grupo: escriba custom-activity-pool, el grupo que ha creado en Batch Explorer.
- Nombre del servicio vinculado de la cuenta de almacenamiento: seleccione Nuevo. En la pantalla siguiente, escriba un nombre para el servicio de almacenamiento vinculado, como AzureBlobStorage1, seleccione la suscripción de Azure y la cuenta de almacenamiento vinculada y, luego, seleccione Crear.
En la parte inferior de la pantalla Nuevo servicio vinculado de Batch, seleccione Probar conexión. Después de validar que la conexión se realiza correctamente, seleccione Crear.
Seleccione la pestaña Configuración y escriba o seleccione la siguiente configuración:
-
Comando: escriba
cmd /C python main.py. - Servicio vinculado de recursos: seleccione el servicio de almacenamiento vinculado que ha creado, como AzureBlobStorage1 y pruebe la conexión para asegurarse de que se ha realizado correctamente.
- Ruta de acceso a la carpeta: seleccione el icono de carpeta y, luego, seleccione el contenedor input y seleccione Aceptar. Los archivos de esta carpeta se descargan del contenedor en los nodos del grupo antes de que se ejecute el script de Python.
-
Comando: escriba
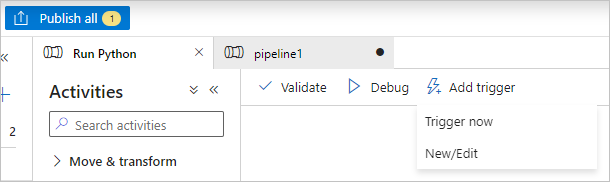
Seleccione Validar en la barra de herramientas de la canalización para validar la canalización.
Seleccione Depurar para probar la canalización y asegurarse de que funciona correctamente.
Selecciona Publicar todo para publicar el flujo de trabajo.
Seleccione Agregar desencadenador y, luego, seleccione Desencadenar ahora para ejecutar la canalización o Nuevo o Editar para programarla.

Uso de Batch Explorer para ver los archivos de registro
Si la ejecución de la canalización genera advertencias o errores, puede usar Batch Explorer para ver los archivos de salida stdout.txt y stderr.txt para obtener más información.
- En Batch Explorer, seleccione Trabajos en la barra lateral izquierda.
- Seleccione el trabajo adfv2-custom-activity-pool.
- Seleccione una tarea que haya tenido un código de salida de falla.
- Vea los archivos stdout.txt y stderr.txt para investigar y diagnosticar su problema.
Limpieza de recursos
Las cuentas, los trabajos y las tareas de Batch son gratuitas, pero los nodos de proceso incurren en cargos incluso cuando no ejecutan trabajos. Es mejor asignar grupos de nodos solo según sea necesario y eliminarlos cuando se haya terminado de trabajar con ellos. Al eliminar grupos, se elimina toda la salida de la tarea en los nodos y los nodos.
Los archivos de entrada y salida permanecen en la cuenta de almacenamiento y pueden incurrir en cargos. Cuando ya no necesite los archivos, puede eliminar los archivos o contenedores. Cuando ya no necesite la cuenta de Batch o la cuenta de almacenamiento vinculada, puede eliminarla.
Pasos siguientes
En este tutorial, ha aprendido a usar un script de Python con Batch Explorer, Explorador de Storage y Data Factory para ejecutar una carga de trabajo de Batch. Para obtener más información sobre Data Factory, consulte ¿Qué es Azure Data Factory?