Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis integral para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga más información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se explica cómo usar la actividad de copia en una canalización de Azure Data Factory o Synapse Analytics para copiar datos de Spark. El documento se basa en el artículo de introducción a la actividad de copia que describe información general de la actividad de copia.
Importante
La versión 2.0 del conector de Spark proporciona compatibilidad nativa mejorada con Spark. Si usa la versión 1.0 del conector de Spark en la solución, actualice el conector de Spark antes del 30 de septiembre de 2025. Consulte esta sección para obtener más información sobre la diferencia entre la versión 2.0 y la versión 1.0.
Funcionalidades admitidas
El conector Spark es compatible para las siguientes funcionalidades:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | 1 2 |
| Actividad de búsqueda | 1 2 |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Consulte la tabla de almacenes de datos compatibles para ver una lista de almacenes de datos que la actividad de copia admite como orígenes o receptores.
El servicio proporciona un controlador integrado para habilitar la conectividad. Por lo tanto, no es necesario instalar manualmente ningún controlador mediante este conector.
Requisitos previos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado en Spark mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado en Spark en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Spark y seleccione el conector de Spark.

Configure los detalles del servicio, pruebe la conexión y cree el servicio vinculado.
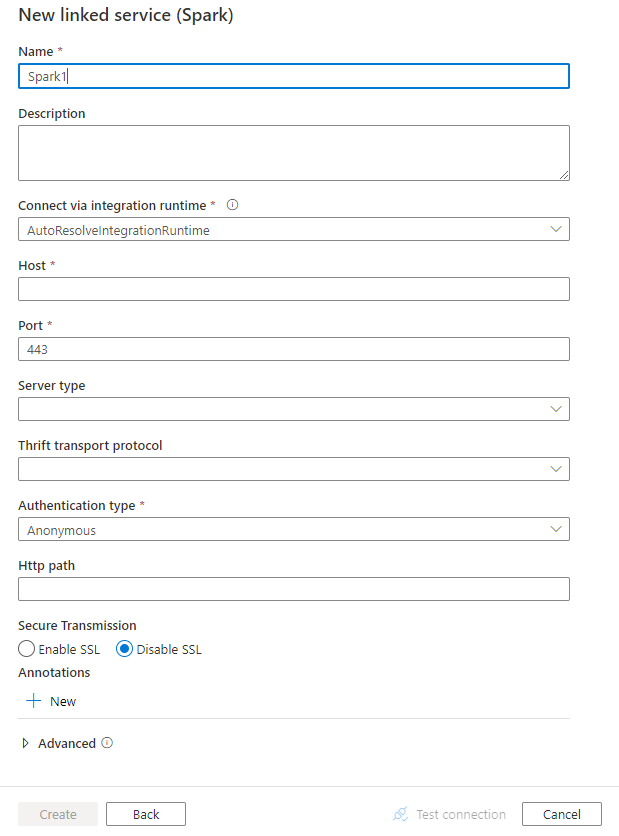
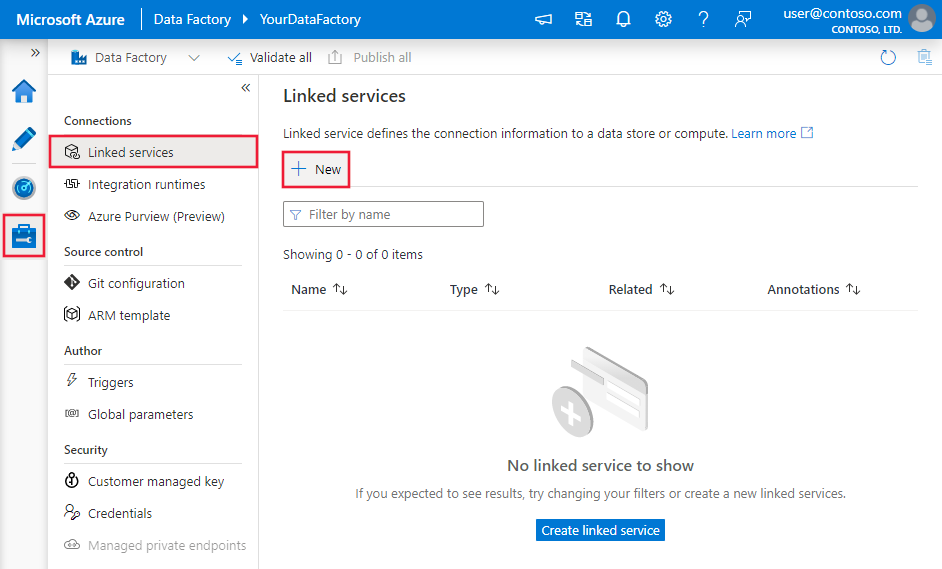
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas del conector de Spark.
Propiedades del servicio vinculado
El conector de Spark ahora admite la versión 2.0. Consulte esta sección para actualizar la versión del conector de Spark desde la versión 1.0. Para obtener los detalles de la propiedad, consulte las secciones correspondientes.
Versión 2.0
Las siguientes propiedades son compatibles con la versión 2.0 del servicio vinculado de Spark:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| tipo | La propiedad type debe establecerse en: Spark | Sí |
| versión | Versión que especifique. El valor es 2.0. |
Sí |
| anfitrión | Dirección IP o nombre de host del servidor de Spark | Sí |
| puerto | Puerto TCP que el servidor de Spark utiliza para escuchar las conexiones del cliente. Si se conecta a Azure HDInsight, especifique el puerto 443. | Sí |
| tipo de servidor | Tipo de servidor de Spark. El valor permitido es: SparkThriftServer |
No |
| thriftTransportProtocol | Protocolo de transporte que se va a usar en la capa de Thrift. El valor permitido es: HTTP |
No |
| Tipo de autenticación | Método de autenticación que se usa para tener acceso al servidor de Spark. Los valores permitidos son: Anonymous, UsernameAndPassword y WindowsAzureHDInsightService |
Sí |
| nombre de usuario | Nombre de usuario que utiliza para acceder al servidor de Spark. | No |
| contraseña | Contraseña que corresponde al usuario. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | No |
| httpPath (en inglés) | Dirección URL parcial correspondiente al servidor de Spark. | No |
| HabilitarSSL | Especifica si las conexiones al servidor se cifran mediante TLS. El valor predeterminado es true. | No |
| enableServerCertificateValidation | Especifique si se va a habilitar la validación de certificados SSL de servidor al conectarse. Use siempre el Almacén de confianza del sistema. El valor predeterminado es true. |
No |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"version": "2.0",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Versión 1.0
Las siguientes propiedades son compatibles con la versión 1.0 del servicio vinculado de Spark:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| tipo | La propiedad type debe establecerse en: Spark | Sí |
| anfitrión | Dirección IP o nombre de host del servidor de Spark | Sí |
| puerto | Puerto TCP que el servidor de Spark utiliza para escuchar las conexiones del cliente. Si se conecta a Azure HDInsight, especifique el puerto 443. | Sí |
| tipo de servidor | Tipo de servidor de Spark. Los valores permitidos son: SharkServer, SharkServer2 y SparkThriftServer |
No |
| thriftTransportProtocol | Protocolo de transporte que se va a usar en la capa de Thrift. Los valores permitidos son: Binary (Binario), SASL y HTTP |
No |
| Tipo de autenticación | Método de autenticación que se usa para tener acceso al servidor de Spark. Los valores permitidos son: Anonymous, Username, UsernameAndPassword y WindowsAzureHDInsightService |
Sí |
| nombre de usuario | Nombre de usuario que utiliza para acceder al servidor de Spark. | No |
| contraseña | Contraseña que corresponde al usuario. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | No |
| httpPath (en inglés) | Dirección URL parcial correspondiente al servidor de Spark. | No |
| HabilitarSSL | Especifica si las conexiones al servidor se cifran mediante TLS. El valor predeterminado es false. | No |
| trustedCertPath | Ruta de acceso completa del archivo .pem que contiene certificados de CA de confianza para comprobar el servidor al conectarse a través de TLS. Esta propiedad solo puede establecerse al utilizar TLS en IR autohospedados. El valor predeterminado es el archivo cacerts.pem instalado con el IR. | No |
| useSystemTrustStore | Especifica si se utiliza un certificado de CA del almacén de confianza del sistema o de un archivo PEM especificado. El valor predeterminado es false. | No |
| allowHostNameCNMismatch | Especifica si se requiere que el nombre del certificado TLS/SSL emitido por una CA coincida con el nombre de host del servidor al conectarse a través de TLS. El valor predeterminado es false. | No |
| allowSelfSignedServerCert | Especifica si se permiten los certificados autofirmados del servidor. El valor predeterminado es false. | No |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades compatibles con el conjunto de datos de Spark.
Para copiar datos de Spark, establezca la propiedad type del conjunto de datos en SparkObject. Se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| tipo | La propiedad tipo del conjunto de datos debe establecerse en: SparkObject | Sí |
| esquema | Nombre del esquema. | No (si se especifica "query" en el origen de la actividad) |
| tabla | Nombre de la tabla. | No (si se especifica "query" en el origen de la actividad) |
| tableName | Nombre de la tabla con el esquema. Esta propiedad permite la compatibilidad con versiones anteriores. Use schema y table para la carga de trabajo nueva. |
No (si se especifica "query" en el origen de la actividad) |
Ejemplo
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades compatibles con el origen de Spark.
Spark como origen
Para copiar datos de Spark, establezca el tipo de origen de la actividad de copia en SparkSource. Se admiten las siguientes propiedades en la sección source de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| tipo | La propiedad type del origen de la actividad de copia debe establecerse en: SparkSource | Sí |
| Query | Use la consulta SQL personalizada para leer los datos. Por ejemplo: "SELECT * FROM MyTable". |
No (si se especifica "tableName" en el conjunto de datos) |
Ejemplo:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Asignación de tipos de datos para Spark
Al copiar datos de y a Spark, se usan las siguientes asignaciones provisionales de tipos de datos dentro del servicio. Para más información acerca de la forma en que la actividad de copia asigna el tipo de datos y el esquema de origen al receptor, consulte el artículo sobre asignaciones de tipos de datos y esquema.
| Tipo de datos de Spark | Tipo de datos de servicio provisional (para la versión 2.0) | Tipo de datos de servicio provisional (para la versión 1.0) |
|---|---|---|
| Tipo Booleano | Booleano | Booleano |
| ByteType | Sbyte | Int16 |
| ShortType | Int16 | Int16 |
| IntegerType | Int32 | Int32 |
| LongType | Int64 | Int64 |
| FloatType | Soltero | Soltero |
| DoubleType | Doble | Doble |
| TipoDeFecha | FechaHora | FechaHora |
| TimestampType | DateTimeOffset | FechaHora |
| StringType | Cadena | Cadena |
| TipoBinario | Byte[] | Byte[] |
| DecimalType | Decimal | Decimal |
| ArrayType | Cadena | Cadena |
| StructType | Cadena | Cadena |
| Tipo de Mapa | Cadena | Cadena |
| TimestampNTZType | FechaHora | FechaHora |
| YearMonthIntervalType | Cadena | No está soportado. |
| TipoDeIntervaloDeTiempoDelDía | Cadena | No está soportado. |
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Actualizar el conector de Spark
En la página Editar servicio vinculado , seleccione 2.0 para la versión y configure el servicio vinculado haciendo referencia a las propiedades del servicio vinculado versión 2.0.
La asignación de tipos de datos para la versión 2.0 del servicio vinculado de Spark es diferente de la de la versión 1.0. Para obtener información sobre la asignación de tipos de datos más reciente, consulte Asignación de tipos de datos para Spark.
Diferencias entre la versión 2.0 de Spark y la versión 1.0
La versión 2.0 del conector de Spark ofrece nuevas funcionalidades y es compatible con la mayoría de las características de la versión 1.0. En la tabla siguiente se muestran las diferencias de características entre la versión 2.0 y la versión 1.0.
| Versión 2.0 | Versión 1.0 |
|---|---|
SharkServer y SharkServer2 no son compatibles con serverType. |
Admite SharkServer y SharkServer2 para serverType. |
Binary y SASL no se admiten para thriftTransportProtocl. |
Admite Binary y SASL para thriftTransportProtocl. |
| No se admite el tipo de autenticación de nombre de usuario. | Admite el tipo de autenticación de nombre de usuario. |
El valor predeterminado de enableSSL es verdadero.
No se admitentrustedCertPath, useSystemTrustStore, allowHostNameCNMismatch ni allowSelfSignedServerCert. enableServerCertificateValidation es compatible. |
El valor predeterminado de enableSSL es falso. Además, admite trustedCertPath, useSystemTrustStoreallowHostNameCNMismatch y allowSelfSignedServerCert. No se admite enableServerCertificateValidation. |
| Las siguientes asignaciones se usan de tipos de datos de Spark para los tipos de datos provisionales de servicio utilizados por el servicio internamente. TimestampType:> DateTimeOffset YearMonthIntervalType-> Cadena DayTimeIntervalType -> Cadena |
Las siguientes asignaciones se usan de tipos de datos de Spark para los tipos de datos provisionales de servicio utilizados por el servicio internamente. TimestampType:> DateTime Otras asignaciones admitidas por la versión 2.0 (versión preliminar) enumeradas a la izquierda no son compatibles con la versión 1.0. |
Contenido relacionado
Para obtener una lista de los almacenes de datos que admite la actividad de copia como orígenes y receptores, consulte Almacenes de datos compatibles.