Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Note
La función Fuente de cambios de datos de Lakebase está en versión preliminar pública.
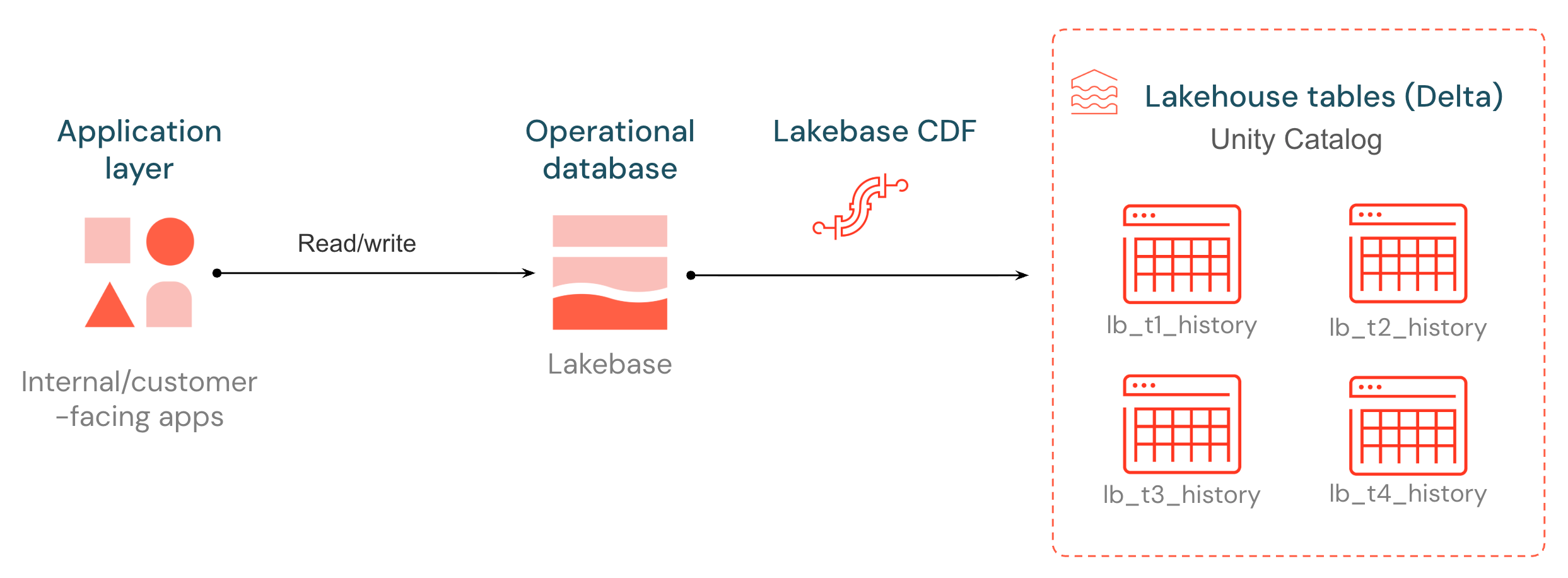
¿Qué es el flujo de datos de cambios de Lakebase?
Lakebase presenta una fuente nativa de datos de cambios (CDF), que pone sus datos operativos a disposición de canalizaciones, modelos y aplicaciones posteriores. Cada inserción, actualización y eliminación en una tabla Postgres de Lakebase se registra a partir del write-ahead log (WAL) y se almacena como una nueva fila en una tabla Delta gestionada por Unity Catalog, agrupándose en lotes y volcándose cada ~15 segundos. El historial de cambios se almacena en un formato abierto que cualquier motor de proceso puede leer.
Las tablas de destino siguen la misma estructura que Delta Change Data Feed: cada fila contiene un _pg_change_type, un LSN, un identificador de transacción y una marca de tiempo. Los cambios operativos se convierten en una fuente de primer nivel para los procesos de ETL, la auditoría y los consumidores posteriores, sin necesidad de implementar una pila de CDC externa.
Casos de uso
Lakebase CDF incorpora datos operativos al entorno lakehouse para que los procesos y las aplicaciones posteriores puedan reaccionar a los cambios en el momento en que se producen.
| Caso de uso | Description |
|---|---|
| Canalizaciones de ETL | Use Lakebase como origen de bronce para canalizaciones de medallion. Cree trabajos incrementales de SDP o de Spark Structured Streaming a partir del feed de cambios y actualice las tablas silver y gold posteriores. |
| Registros de auditoría | Mantenga un historial completo y consultable de cada inserción, actualización y eliminación en una tabla de Lakebase para el cumplimiento y el análisis forense. El historial es Delta inmutable. |
| Sistemas externos | Store Lakebase cambia los datos en un formato abierto que cualquier motor puede consumir. Dado que el destino es una tabla Delta en Unity Catalog, los sistemas externos y los lectores no pertenecientes a Databricks pueden acceder al flujo directamente. |
Habilitación de esta versión preliminar
Un administrador del espacio de trabajo debe habilitar la versión preliminar de Lakebase Change Data Feed desde la página de versiones preliminares del espacio de trabajo.
Requirements
- Escalado automático de Lakebase: Un proyecto de escalado automático de Lakebase que ejecuta Postgres 17.
-
Base de datos de origen: Las tablas deben residir en la
databricks_postgresbase de datos de Lakebase. Cada proyecto se crea con esta base de datos predeterminada. Es una limitación conocida. - Catálogo de Unity: La identidad que configura CDF necesita USE CATALOG, USE SCHEMA y CREATE TABLE en el catálogo y el esquema de destino. Consulte Concesión de permisos en un objeto.
- Almacenamiento predeterminado: No se admiten los catálogos de destino configurados con almacenamiento predeterminado.
- Proyecto Lakebase: El rol de Postgres requiere los permisos CAN MANAGE en el proyecto Lakebase. Los propietarios del proyecto tienen CAN MANAGE de forma predeterminada. Consulte Administración de permisos de proyecto.
- Tipos de datos: Consulte Asignación de tipos de datos. Los tipos sin un equivalente de Delta directo se almacenan como STRING.
Configuración de Lakebase CDF
Para empezar, establezca la identidad de réplica completa en las tablas que desee en la fuente (paso 1), inicie CDF en la aplicación Lakebase (paso 2). Los datos aparecen como lb_<table_name>_history tablas delta en el catálogo de Unity Catalog y el esquema que elija.
Paso 1: Configurar la identidad de réplica como completa
Para que una tabla de Lakebase participe en CDF, debe haber REPLICA IDENTITY FULL establecido. De forma predeterminada, Postgres registra solo la clave principal cuando se actualiza o elimina una fila. Establecer la identidad completa indica a Postgres que registre el estado de fila antes y después en el registro de escritura anticipada, que CDF necesita para crear un historial de cambios completo.
Puede ejecutar estos comandos en el Editor de SQL de Lakebase o en cualquier cliente de Postgres.
Tabla única
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Todas las tablas existentes de un esquema
Para establecer la identidad de réplica en cada tabla existente de un esquema (public en este ejemplo), ejecute:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Aplicación automática a tablas futuras
Para que cada tabla recién creada reciba REPLICA IDENTITY FULLautomáticamente , instale un desencadenador de eventos postgres. Se ejecuta después de cada CREATE TABLE y establece la identidad en la nueva tabla:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Combine el desencadenador de eventos con el bucle en la pestaña anterior para cubrir las tablas existentes y futuras en una configuración.
Compruebe qué tablas tienen configurada la identidad de réplica
Para ver qué tablas de un esquema tienen configurada la identidad de réplica, ejecute:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Solo las filas con replica_identity = 'full' están listas para CDF.
Paso 2: Iniciar el flujo de cambios de datos
Lakebase CDF se configura a nivel de esquema. Una vez iniciada, todas las tablas actuales y futuras del esquema de origen se incluyen en la fuente.
- En el área de trabajo de Azure Databricks, abra Lakebase Postgres desde el conmutador de la aplicación (superior derecha).
- Seleccione el proyecto de Lakebase y la rama que desea usar (por ejemplo, producción o principal).
- Abra Información general sobre la rama y haga clic en la pestaña Fuente de distribución de datos modificados .
- Haga clic en Iniciar.
- En el cuadro de diálogo de configuración:
-
Base de datos: El valor predeterminado es
databricks_postgres. - Esquema: Seleccione el esquema postgres de origen.
- Al catálogo: Seleccione el catálogo de destino de Unity Catalog.
- Esquema: Seleccione el esquema de catálogo de Unity de destino.
-
Base de datos: El valor predeterminado es
- Haga clic en Iniciar para iniciar la transmisión.
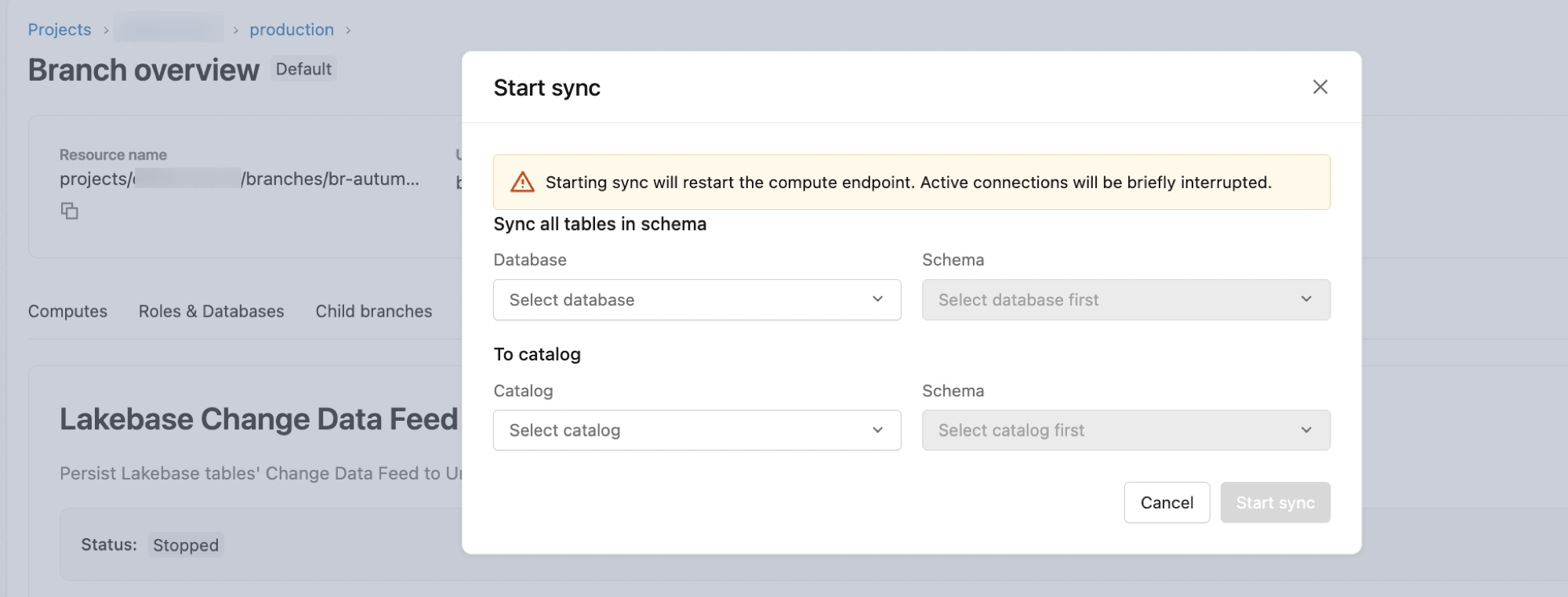
Las tablas aparecen en el destino como lb_<table_name>_history. Para encontrarlos, abra Catálogo en la barra lateral, vaya al esquema y el catálogo de destino y abra la pestaña Tablas .
La pestaña Fuente de distribución de datos modificados de Lakebase tiene dos sub pestañas:
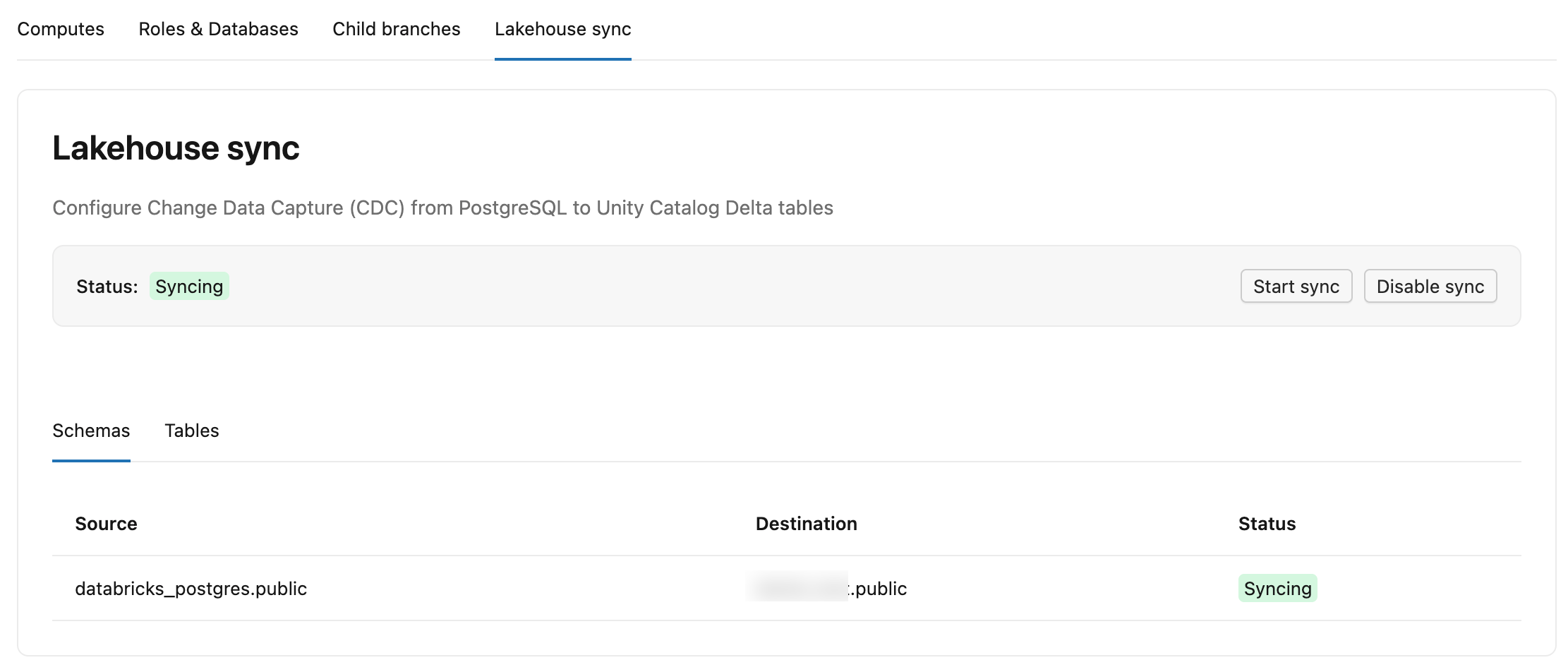
- Esquemas: Enumera cada esquema de origen, su catálogo de destino y su esquema en el catálogo de Unity y un estado.
-
Tablas: Muestra cada tabla de origen, su tabla
lb_<table_name>_historyde destino, el estado (StreamingoSnapshotting), LSN confirmado (hasta dónde el flujo ha escrito en Delta, que se muestra como-mientras aún está en la instantánea inicial) y Última actualización (la última vez que la tabla recibió cambios).
También puede inspeccionar el estado de fuente desde Postgres ejecutando esto en el Editor de SQL de Lakebase:
SELECT * FROM wal2delta.tables;
El resultado incluye table_oid, status (STREAMING o SNAPSHOTTING), committed_lsny last_write_time por tabla.
Important
¿Qué es wal2delta? Lakebase CDF se basa en la extensión wal2delta Postgres, que se ejecuta dentro del proceso de Lakebase. Usa la descodificación lógica para capturar los cambios del registro de escritura anticipada (WAL) y escribirlos en tablas Delta en el catálogo de Unity.
Esquema de la tabla de destino
CDF escribe una tabla Delta por tabla de origen, denominada lb_<table_name>_history en el esquema y el catálogo de destino. Además de las columnas fuente, cada fila incluye estas columnas del sistema:
| Columna | Tipo | Description |
|---|---|---|
_pg_change_type |
Mensaje de texto | Tipo de operación: insert, delete, update_preimageo update_postimage. |
_pg_lsn |
BIGINT | Número de secuencia de registro de Postgres. |
_pg_xid |
INTEGER | Identificador de transacción de Postgres. |
_timestamp |
TIMESTAMP | Marca de tiempo cuando se procesó el cambio (sin zona horaria). |
_sort_by |
BIGINT | Clave de ordenación monotónica usada para ordenar todos los cambios. |
Patrones de cambio comunes
-
Instantánea inicial: La primera vez que CDF se ejecuta en una tabla de Lakebase existente, cada fila existente se escribe con
_pg_change_type = 'insert'. -
Actualizaciones: Una actualización genera dos filas: una con
_pg_change_type = 'update_preimage'(fila antigua) y otra con_pg_change_type = 'update_postimage'(nueva fila). -
Elimina: Una eliminación genera una fila con
_pg_change_type = 'delete'.
Estos son los mismos eventos de cambio que Delta Change Data Feed, por lo que se aplican los mismos patrones de procesamiento posteriores.
Comportamiento operativo
-
Colisiones de nombres: Si dos tablas de origen se asignan al mismo nombre de destino (por ejemplo,
sales.usersymarketing.usersambas se asignan alb_users_history), CDF escribe la primera enlb_users_historyy añade automáticamente un sufijo a la segunda enlb_users_history_1. Puede renombrar cualquiera de las tablas de destino en Unity Catalog y el flujo sigue funcionando. - Ámbito de nivel de esquema: Al iniciar CDF en un esquema de Lakebase, se incluyen todas las tablas actuales y futuras de ese esquema. Se omiten las tablas vacías: una tabla debe tener al menos una fila para que aparezca en el destino.
- Tablas de origen quitadas: Si quita una tabla en Lakebase, se conserva la tabla Delta de destino en el catálogo de Unity.
Crear canalizaciones descendentes
Lakebase CDF está diseñado para canalizaciones de bajada que reaccionan a los cambios operativos. Los patrones siguientes muestran tres maneras de consumir la fuente, ordenadas de más sencilla a más flexible.
Escenario de ejemplo. Una aplicación de comercio electrónico registra pedidos en una tabla de Postgres orders, donde cada fila contiene un item_id y quantity. El equipo de logística necesita niveles de inventario activos. Con CDF, cada cambio en orders se almacena en la tabla Delta lb_orders_history de Unity Catalog. Las canalizaciones posteriores leen ese flujo de cambios y actualizan una tabla inventory_levels cada vez que se realiza, se modifica o se cancela un pedido.
Calcular el inventario actual con una vista materializada
El patrón más sencillo es una vista materializada de SQL sobre la tabla de historial. La MV se actualiza incrementalmente a medida que llegan los nuevos eventos de cambio y los consumidores de bajada lo consultan como cualquier otra tabla.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
Las dos filas generadas para cada actualización se cancelan entre sí, excepto por el cambio neto, por lo que la suma en ejecución permanece correcta a medida que se editan los pedidos.
Procesamiento en flujo de cambios con canalizaciones declarativas de Spark
Para una arquitectura de medallón estructurada, utilice las canalizaciones declarativas de Spark (SDP) para declarar tablas de bronce, plata y oro. SDP los ejecuta como una canalización integrada, ocupándose de los puntos de control y de la gestión de dependencias por usted.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments
lb_orders_history realiza una lectura incremental con readStream y produce un delta por evento.
inventory_levels agrega por item_id para calcular las existencias actuales. Se espera que se descarten las filas que harían que el stock quedara en negativo, lo que indica un error en un proceso anterior.
Para ver un tutorial completo de un extremo a otro, consulte Tutorial: Creación de una canalización de ETL mediante la captura de datos modificados.
Procesamiento personalizado con Spark Structured Streaming
Cuando necesite un control completo —por ejemplo, fusiones personalizadas, efectos secundarios o varios destinos—, lea la tabla de historial directamente con Spark Structured Streaming y use foreachBatch para escribir en su destino.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Cada microlote agrupa los eventos de cambio según item_id y fusiona los deltas netos en inventory_levels.
Diseñado para ser incremental. Cada tabla lb_<table_name>_history es una tabla Delta de solo adición. Cada cambio de origen se registra como una nueva fila con _pg_change_type la marca de la operación. Las vistas materializadas de Databricks SQL, los flujos de Lakeflow Spark Declarative Pipelines y los trabajos de Spark Structured Streaming procesan de forma incremental las filas nuevas del registro de transacciones de Delta, por lo que las canalizaciones posteriores solo realizan un trabajo proporcional a los cambios. No es necesario habilitar Delta Change Data Feed en la tabla de historial, porque la semántica de los cambios ya está codificada en los datos de la fila.
Asignación de tipos de datos
CDF admite la mayoría de los tipos primitivos de PostgreSQL estándar. Los tipos sin un equivalente de Delta directo se almacenan como STRING.
| Tipo de PostgreSQL | tipo Delta de Azure Databricks | Notas |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
| TEXT, VARCHAR, CHAR | STRING | |
| JSONB | STRING | Se almacena como una cadena JSON. |
| ENUM | STRING | Se almacena como etiqueta de enum. |
| NUMÉRICO / DECIMAL | DECIMAL o CADENA | Usa la precisión y la escala de origen siempre que sea posible. Realiza un reescalado sin pérdida de información para valores de precisión y escala incompatibles. Se convierte en STRING cuando la precisión supera 38 o cuando no se han definido la precisión o la escala (NUMERIC sin límites). Todas las columnas NUMERIC/DECIMAL admiten valores NULL porque los valores NaN se asignan a NULL. Consulte Tipos numéricos de PostgreSQL. |
| DATE | DATE | |
| TIMESTAMP | TIMESTAMP_NTZ | |
| TIMESTAMPTZ | TIMESTAMP | |
| FLOAT, DOUBLE | FLOAT, DOUBLE |
Tipos almacenados como STRING:
-
Geography/Geometry (PostGIS): Tipos de la extensión PostGIS (por ejemplo,
geometry,geography). -
Vector (pgvector): Tipo
vectorde la extensión pgvector. -
Tipos compuestos o struct: Tipos personalizados definidos con
CREATE TYPE ... AS (field_name type, ...). Estos son tipos similares a filas con campos con nombre. -
Mapa: Tipos de clave-valor de tipo mapa, como hstore (de la extensión
hstore). Postgres no tiene ningún tipo de mapa integrado.hstorees la manera común de almacenar pares clave-valor en una columna.
Administración de cambios de esquema
-
Cambiar el nombre de una tabla en Postgres (por ejemplo,
ALTER TABLE users RENAME TO customers) permite que la fuente continúe. El nombre de la tabla Delta de destino no cambia; permanecelb_users_history. - Los cambios de esquema (agregar una columna, quitar una columna o cambiar el tipo de datos de una columna) desencadenan una nueva instantánea de la tabla afectada. CDF vuelve a leer toda la tabla de Postgres y la vuelve a escribir en la tabla Delta de destino.
Deshabilitar Lakebase CDF
Deshabilitar CDF detiene el flujo para todos los esquemas de Lakebase del proyecto.
- En el área de trabajo de Azure Databricks, abra Lakebase Postgres desde el conmutador de la aplicación (superior derecha).
- Seleccione el proyecto Lakebase y la rama donde configuró CDF.
- Abra Información general sobre la rama y haga clic en la pestaña Fuente de distribución de datos modificados .
- Haga clic en Deshabilitar. En el cuadro de diálogo de confirmación, revise la advertencia de que los cambios dejarán de fluir a las tablas Delta y, a continuación, haga clic en Deshabilitar de nuevo para confirmar.
Al deshabilitar CDF no se reinicia el proceso.
Advertencia
Si vuelve a habilitar CDF más adelante, el sistema no realiza una nueva instantánea completa. Los cambios que se produjeron mientras CDF estaba deshabilitado se perderán de forma permanente en las tablas Delta de destino.
Limitaciones y solución de problemas
Puede ver el estado por tabla (instantáneas, omitidas o streaming) en la pestaña Fuente de distribución de datos modificados o ejecutando esto en Lakebase:
SELECT * FROM wal2delta.tables;
Motivos comunes por los que una tabla no aparece en la fuente:
-
REPLICA IDENTITY FULLsin establecer: EjecuteALTER TABLE <table_name> REPLICA IDENTITY FULL;para la tabla. Consulte Paso 1: Establecimiento de la identidad de réplica completa. - Tablas con particiones: No se admiten tablas con particiones de Lakebase. Un esquema que contiene tablas con particiones hace que se produzca un error en esas tablas.
- Tablas vacías: Se omite una tabla con cero filas hasta que exista al menos una fila.
Pasos siguientes
- Cree ETL incrementales con Spark Declarative Pipelines. Consulte Tutorial: Compilación de una canalización de ETL mediante la captura de datos modificados para ver un tutorial completo.
- Consulte la capa de bronce con Databricks SQL. Consulte Introducción al almacenamiento de datos mediante Databricks SQL.
- Historial de auditoría con consultas de viaje en el tiempo en las tablas Delta de destino.