Evaluación de los resultados del experimento de aprendizaje automático automatizado
En este artículo, aprenderá a evaluar y comparar los modelos entrenados por el experimento de aprendizaje automático automatizado (ML automatizado). En el transcurso de un experimento de ML automatizado, se crean muchos trabajos y cada uno de ellos crea un modelo. Para cada modelo, ML automatizado genera gráficos y métricas de evaluación que le ayudan a medir el rendimiento del modelo. También puede generar un panel de inteligencia artificial responsable para realizar una evaluación holística y depuración del mejor modelo recomendado de forma predeterminada. Esto incluye información como explicaciones del modelo, equidad y explorador de rendimiento, explorador de datos, análisis de errores del modelo. Obtenga más información sobre cómo puede generar un panel de inteligencia artificial responsable.
Por ejemplo, ML automatizado genera los siguientes gráficos en función del tipo de experimento.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Se ofrece la versión preliminar sin Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Requisitos previos
- Suscripción a Azure. (Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar).
- Un experimento Azure Machine Learning creado con cualquiera de las siguientes opciones:
- Estudio de Azure Machine Learning (no se requiere código)
- El SDK de Azure Machine Learning para Python
Visualización de los resultados de los trabajos
Una vez completado un experimento de ML automatizado, se puede obtener un historial de los trabajos mediante:
- Un explorador con Estudio de Azure Machine Learning
- Un cuaderno de Jupyter Notebook con el widget JobDetails para Jupyter
En el vídeo y los pasos siguientes, se muestra cómo ver el historial de ejecuciones y los gráficos y las métricas de evaluación del modelo en el estudio:
- Inicie sesión en el estudio y vaya al área de trabajo.
- En el menú de la izquierda, seleccione Trabajos.
- Seleccione el experimento en la lista de experimentos.
- En la tabla del final de la página, seleccione un trabajo de ML automatizado.
- En la pestaña Modelos, seleccione una opción en Nombre del algoritmo correspondiente al modelo que quiere evaluar.
- En la pestaña Métricas, utilice las casillas de la izquierda para ver las métricas y los gráficos.
Métricas de clasificación
ML automatizado calcula las métricas de rendimiento para cada modelo de clasificación generado para el experimento. Estas métricas se basan en la implementación de scikit-learn.
Muchas métricas de clasificación se definen para la clasificación binaria en dos clases y requieren el promedio de las clases para generar una puntuación para la clasificación de varias clases. Scikit-learn proporciona varios métodos de promedio, tres de los cuales expone ML automatizado: macro, micro, y ponderado.
- Macro: se calcula la métrica para cada clase y se toma el promedio no ponderado
- Micro: se calcula la métrica de forma global mediante el recuento del total de verdaderos positivos, falsos negativos y falsos positivos (independientemente de las clases).
- Ponderado: se calcula la métrica para cada clase y se toma el promedio ponderado en función del número de muestras por clase.
Aunque cada método de promedio tiene sus ventajas, una consideración común al seleccionar el método adecuado es el desequilibrio de clases. Si las clases tienen números de muestras diferentes, podría ser más informativo usar un promedio de macros, donde las clases minoritarias reciben la misma ponderación que las clases mayoritarias. Más información sobre las métricas binarias frente a las métricas multiclase en ML automatizado.
En la tabla siguiente se resumen las métricas de rendimiento de modelo que el aprendizaje automático automatizado calcula para cada modelo de clasificación generado para el experimento. Para obtener más información, consulte la documentación de scikit-learn vinculada en el campo Cálculo de cada métrica.
Nota
Vea la sección de métricas de imagen para obtener más detalles sobre las métricas de los modelos de clasificación de imágenes.
| Métrica | Descripción | Cálculo |
|---|---|---|
| AUC | AUC es el área bajo la curva de característica operativa del receptor. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] Entre los nombres de métricas admitidos se incluyen: AUC_macro: es la media aritmética del parámetro AUC para cada clase.AUC_micro: se calcula mediante el recuento del total de verdaderos positivos, falsos negativos y falsos positivos. AUC_weighted: es la media aritmética de la puntuación para cada clase, ponderada por el número de instancias verdaderas en cada clase. AUC_binary: es el valor de AUC al tratar una clase específica como true y combinar todas las demás clases como false. |
Cálculo |
| accuracy | La precisión es la relación de predicciones que coinciden exactamente con las etiquetas de clase. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] |
Cálculo |
| average_precision | La precisión promedio resume una curva de precisión-recuperación como la media ponderada de las precisiones conseguidas en cada umbral, donde el aumento de la recuperación del umbral anterior se usa como peso. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] Entre los nombres de métricas admitidos se incluyen: average_precision_score_macro: es la media aritmética de la puntuación de precisión media de cada clase.average_precision_score_micro: se calcula mediante el recuento del total de verdaderos positivos, falsos negativos y falsos positivos.average_precision_score_weighted: es la media aritmética de la puntuación de precisión promedio para cada clase, ponderada por el número de instancias verdaderas en cada clase. average_precision_score_binary: es el valor de la precisión media al tratar una clase específica como true y combinar todas las demás clases como false. |
Cálculo |
| balanced_accuracy | La precisión equilibrada es la media aritmética de recuperación para cada clase. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] |
Cálculo |
| f1_score | La puntuación F1 es la media armónica de precisión y recuperación. Es una medida equilibrada de falsos positivos y falsos negativos. Sin embargo, no tiene en cuenta los verdaderos negativos. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] Entre los nombres de métricas admitidos se incluyen: f1_score_macro: media aritmética de la puntuación F1 para cada clase. f1_score_micro: se calcula mediante el recuento del total de verdaderos positivos, falsos negativos y falsos positivos. f1_score_weighted: media ponderada por frecuencia de clase de la puntuación F1 para cada clase. f1_score_binary: es el valor de F1 al tratar una clase específica como true y combinar todas las demás clases como false. |
Cálculo |
| log_loss | Se trata de la función de pérdida que se usa en la regresión logística (multinomial) y sus extensiones, como las redes neuronales, definida como la verosimilitud logarítmica negativa de las etiquetas verdaderas, dadas las predicciones de un clasificador probabilístico. Objetivo: cuanto más cerca de 0, mejor Intervalo: [0, inf) |
Cálculo |
| norm_macro_recall | La coincidencia de macro normalizada es la coincidencia de macro promediada y normalizada para que el rendimiento aleatorio tenga una puntuación de 0 y el rendimiento perfecto una puntuación de 1. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] |
(recall_score_macro - R) / (1 - R) donde, R es el valor esperado de recall_score_macro para las predicciones aleatorias.R = 0.5 para la clasificación binaria. R = (1 / C) para problemas de clasificación de clase C. |
| matthews_correlation | El coeficiente de correlación de Matthews es una medida equilibrada de precisión, que se puede usar incluso si una clase tiene muchos más ejemplos que otra. Un coeficiente de 1 indica una predicción perfecta, 0 predicción aleatoria y -1 predicción inversa. Objetivo: cuanto más cerca de 1, mejor Intervalo: [-1, 1] |
Cálculo |
| Precisión | La precisión es la capacidad de un modelo para evitar que las etiquetas negativas se etiqueten como positivas. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] Entre los nombres de métricas admitidos se incluyen: precision_score_macro: es la media aritmética de la precisión para cada clase. precision_score_micro: se calcula de forma global mediante el recuento del total de verdaderos positivos y falsos positivos. precision_score_weighted: es la media aritmética de la precisión para cada clase, ponderada por el número de instancias verdaderas en cada clase. precision_score_binary: es el valor de la precisión al tratar una clase específica como true y combinar todas las demás clases como false. |
Cálculo |
| Coincidencia | La coincidencia es la capacidad de un modelo para detectar todas las muestras positivas. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] Entre los nombres de métricas admitidos se incluyen: recall_score_macro: es la media aritmética de la coincidencia para cada clase. recall_score_micro: se calcula de forma global mediante el recuento del total de verdaderos positivos, falsos negativos y falsos positivos.recall_score_weighted: es la media aritmética de la coincidencia para cada clase, ponderada por el número de instancias verdaderas en cada clase. recall_score_binary: es el valor de la coincidencia al tratar una clase específica como true y combinar todas las demás clases como false. |
Cálculo |
| weighted_accuracy | La precisión ponderada es la precisión en la que cada muestra está ponderada por el número total de muestras que pertenecen a la misma clase. Objetivo: cuanto más cerca de 1, mejor Intervalo: [0, 1] |
Cálculo |
Métricas de clasificación binaria y de varias clases
El aprendizaje automático automatizado detecta automáticamente si los datos son binarios y también permite a los usuarios activar métricas de clasificación binaria incluso si los datos son multiclase mediante la especificación de una clase true. Las métricas de clasificación multiclase se registran si un conjunto de datos tiene dos o más clases. Las métricas de clasificación binaria solo se notifican cuando los datos son binarios.
Tenga en cuenta que las métricas de clasificación multiclase están pensadas para la clasificación multiclase. Cuando estas métricas se aplican a un conjunto de datos binario, no tratan a ninguna clase como clase true, como cabría esperar. Las métricas que se han diseñado claramente para multiclase tienen como sufijo micro, macro o weighted. Entre los ejemplos se incluyen average_precision_score, f1_score, precision_score, recall_score y AUC. Por ejemplo, en lugar de calcular la recuperación como tp / (tp + fn), la recuperación media multiclase (micro, macro o weighted) promedia ambas clases de un conjunto de datos de clasificación binaria. Esto es equivalente a calcular la recuperación de la clase true y de la clase false por separado y, a continuación, tomar la media de ambas.
Además, aunque se admite la detección automática de la clasificación binaria, se recomienda especificar siempre la clase true manualmente, con el fin de asegurarse de que las métricas de clasificación binaria se calculan para la clase correcta.
Para activar las métricas de los conjuntos de datos de clasificación binaria cuando el propio conjunto de datos tiene varias clases, los usuarios solo tienen que especificar la clase que se va a tratar como true y se calcularán estas métricas.
Matriz de confusión
Las matrices de confusión proporcionan un aspecto visual de cómo un modelo de aprendizaje automático comete errores sistemáticos en sus predicciones para los modelos de clasificación. La palabra "confusión" en el nombre proviene de un modelo "confuso" o de un mal etiquetado de muestras. Una celda de la fila i y la columna j de una matriz de confusión contiene el número de muestras del conjunto de datos de evaluación que pertenecen a la clase C_i y que el modelo ha clasificado como clase C_j.
En el estudio, una celda más oscura indica un número mayor de muestras. Al seleccionar la vista Normalizada en la lista desplegable se normalizarán todas las filas de la matriz para mostrar el porcentaje de la clase C_i que se predice que va a ser la clase C_j. La ventaja de la vista Fila predeterminada es que puede ver si el desequilibrio en la distribución de clases reales hizo que el modelo clasificase erróneamente muestras de la clase minoritaria, un problema común en conjuntos de datos desequilibrados.
La matriz de confusión de un modelo adecuado tiene la mayoría de las muestras en la diagonal.
Matriz de confusión para un buen modelo
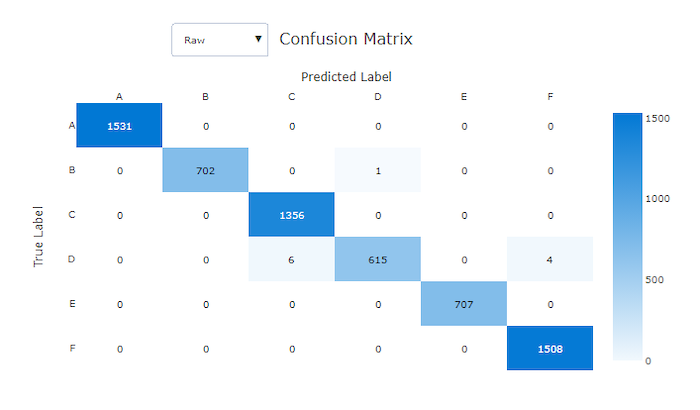
Matriz de confusión para un mal modelo

Curva ROC
La curva de característica operativa del receptor (ROC) traza la relación entre la tasa de verdaderos positivos (TPR) y la tasa de falsos positivos (FPR) a medida que cambia el umbral de decisión. La curva ROC puede ser menos informativa al entrenar modelos con conjuntos de datos con un gran desequilibrio de clases, ya que la mayoría de las clases pueden ahogar contribuciones de las clases minoritarias.
El área bajo la curva (AUC) se puede interpretar como la proporción de las muestras clasificadas correctamente. Más concretamente, AUC es la probabilidad de que el clasificador clasifique una muestra positiva aleatoriamente seleccionada más arriba que una muestra negativa elegida aleatoriamente. La forma de la curva proporciona una intuición de la relación entre TPR y FPR en función del umbral de clasificación o límite de decisión.
Una curva que se aproxima a la esquina superior izquierda del gráfico se está aproximando a un valor de TPR del 100 % y a un valor de FPR del 0 %, el mejor modelo posible. Un modelo aleatorio produciría una curva ROC a lo largo de la línea y = x desde la esquina inferior izquierda hasta la parte superior derecha. Un modelo peor que el aleatorio tendría una curva ROC que cae por debajo de la línea y = x.
Sugerencia
En el caso de los experimentos de clasificación, cada uno de los gráficos de líneas producidos para los modelos de ML automatizado se puede utilizar para evaluar el modelo por clase o promediar todas las clases. Puede cambiar entre estas diferentes vistas haciendo clic en las etiquetas de clase de la leyenda que se encuentra a la derecha del gráfico.
Curva ROC para un buen modelo

Curva ROC para un mal modelo

Curva de precisión-coincidencia
La curva de precisión-coincidencia traza la relación entre la precisión y la coincidencia a medida que cambia el umbral de decisión. La coincidencia es la capacidad de un modelo para detectar todas las muestras positivas y la precisión es la capacidad de un modelo de evitar el etiquetado de muestras negativas como positivas. Algunos problemas empresariales pueden requerir una coincidencia más alta y una precisión mayor en función de la importancia relativa de evitar falsos negativos frente a falsos positivos.
Sugerencia
En el caso de los experimentos de clasificación, cada uno de los gráficos de líneas producidos para los modelos de ML automatizado se puede utilizar para evaluar el modelo por clase o promediar todas las clases. Puede cambiar entre estas diferentes vistas haciendo clic en las etiquetas de clase de la leyenda que se encuentra a la derecha del gráfico.
Curva de precisión-coincidencia para un buen modelo

Curva de precisión-coincidencia para un mal modelo

Curva de beneficios acumulativos
La curva de ganancias acumulativas traza el porcentaje de muestras positivas correctamente clasificadas como una función del porcentaje de muestras consideradas cuando consideramos muestras en el orden de probabilidad predicha.
Para calcular el beneficio, ordene primero todas las muestras, desde la probabilidad más alta hasta la más baja predichas por el modelo. Después, tome x% de las predicciones de mayor confianza. Divida el número de muestras positivas detectadas en x% por el número total de muestras positivas para obtener el beneficio. El beneficio acumulativo es el porcentaje de muestras positivas que se detectan al considerar algún porcentaje de los datos que es más probable que pertenezcan a la clase positiva.
Un modelo perfecto clasifica todas las muestras positivas por encima de las negativas, lo que genera una curva de beneficios acumulados compuesta por dos segmentos rectos. La primera es una línea con pendiente 1 / x de (0, 0) a (x, 1) donde x es la fracción de ejemplos que pertenecen a la clase positiva (1 / num_classes si las clases están equilibradas). La segunda es una línea horizontal de (x, 1) a (1, 1). En el primer segmento, todas las muestras positivas se clasifican correctamente y la ganancia acumulativa va a 100% dentro del primer x% de muestras que se consideran.
El modelo aleatorio de línea base tendrá una curva de beneficios acumulados que sigue a y = x donde para x% de muestras consideradas solo se detectaron aproximadamente un x% de las muestras positivas totales. Un modelo perfecto para un conjunto de datos equilibrado tiene una curva de micro promedio y una línea de macro promedio que tiene una pendiente num_classes hasta que el beneficio acumulado sea del 100 % y luego horizontal hasta que el porcentaje de datos sea 100.
Sugerencia
En el caso de los experimentos de clasificación, cada uno de los gráficos de líneas producidos para los modelos de ML automatizado se puede utilizar para evaluar el modelo por clase o promediar todas las clases. Puede cambiar entre estas diferentes vistas haciendo clic en las etiquetas de clase de la leyenda que se encuentra a la derecha del gráfico.
Curva de beneficios acumulativos para un buen modelo

Curva de beneficios acumulativos para un mal modelo

Curva de elevación
Una curva de elevación muestra cuánto mejor se comporta un modelo en comparación con un modelo aleatorio. La elevación se define como la relación entre el beneficio acumulativo y el beneficio acumulativo de un modelo aleatorio (que siempre debe ser 1).
Este rendimiento relativo tiene en cuenta el hecho de que la clasificación se hace más difícil a medida que el número de clases aumenta. (Un modelo aleatorio predice incorrectamente más muestras de un conjunto de datos con diez clases, en comparación con un conjunto de datos con dos clases).
La curva de elevación de línea base es la línea y = 1 en la que el rendimiento del modelo es coherente con el de un modelo aleatorio. En general, la curva de elevación de un buen modelo será más alta en ese gráfico y más alejada del eje X, lo que muestra que cuando el modelo tiene más confianza en sus predicciones, funciona mucho mejor que las suposiciones aleatorias.
Sugerencia
En el caso de los experimentos de clasificación, cada uno de los gráficos de líneas producidos para los modelos de ML automatizado se puede utilizar para evaluar el modelo por clase o promediar todas las clases. Puede cambiar entre estas diferentes vistas haciendo clic en las etiquetas de clase de la leyenda que se encuentra a la derecha del gráfico.
Curva de elevación para un buen modelo

Curva de elevación para un mal modelo

Curva de calibración
La curva de calibración traza la confianza de un modelo en sus predicciones con respecto a la proporción de muestras positivas en cada nivel de confianza. Un modelo bien calibrado clasificará correctamente el 100 % de las predicciones a las que asigna un 100 % de confianza, el 50 % de las predicciones a las que asigna un 50 % de confianza, el 20 % de las predicciones a las que asigna un 20 % de confianza, etc. Los modelos perfectamente calibrado tienen una curva de calibración que sigue a la línea y = x donde el modelo predice perfectamente la probabilidad de que las muestras pertenezcan a cada clase.
Los modelo que tengan un exceso de confianza predicen en exceso las probabilidades cercanas a cero y uno, y muy ocasionalmente se mostrará incierto sobre la clase de cada muestra y la curva de calibración tendrá un aspecto similar a una "S" invertida. Los modelos con poca confianza asignan, de promedio, una probabilidad más baja a la clase que predice y la curva de calibración asociada tendrá un aspecto similar a una "S". La curva de calibración no representa la capacidad de un modelo para clasificar correctamente, sino su capacidad para asignar correctamente la confianza a sus predicciones. Un mal modelo puede seguir teniendo una buena curva de calibración si el modelo asigna correctamente baja confianza y alta incertidumbre.
Nota
La curva de calibración es sensible al número de muestras, por lo que un conjunto de validación pequeño puede generar resultados ruidosos que pueden ser difíciles de interpretar. Esto no significa necesariamente que el modelo no esté bien calibrado.
Curva de calibración para un buen modelo
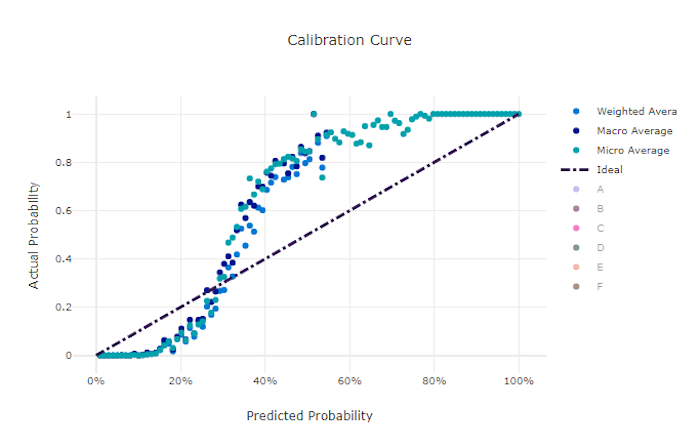
Curva de calibración para un mal modelo

Métricas de regresión y previsión
El aprendizaje automático automatizado calcula las mismas métricas de rendimiento para todos los modelos que se generan, independientemente de que sean un experimento de regresión o de previsión. Estas métricas también se someten a la normalización para habilitar la comparación entre los modelos entrenados en los datos con diferentes intervalos. Para obtener más información, vea la sección Normalización de métricas.
En la tabla siguiente se resumen las métricas de rendimiento del modelo generadas para los experimentos de regresión y previsión. Al igual que las métricas de clasificación, estas métricas también se basan en las implementaciones de scikit-learn. En el campo Cálculo se vincula la documentación de scikit-learn para cada métrica.
| Métrica | Descripción | Cálculo |
|---|---|---|
| explained_variance | La varianza explicada calcula la medida en que un modelo da cuenta de la variación en la variable de destino. Es el porcentaje de disminución de la varianza de los datos originales con respecto a la varianza de los errores. Cuando la media de los errores es 0, equivale al coeficiente de determinación (vea r2_score en el siguiente gráfico). Objetivo: cuanto más cerca de 1, mejor Intervalo: (-inf, 1] |
Cálculo |
| mean_absolute_error | El error absoluto medio es el valor esperado del valor absoluto de la diferencia entre el destino y la predicción. Objetivo: cuanto más cerca de 0, mejor Intervalo: [0, inf) Tipos: mean_absolute_error normalized_mean_absolute_error: es mean_absolute_error dividido por el intervalo de los datos. |
Cálculo |
| mean_absolute_percentage_error | El error de porcentaje absoluto medio (MAPE) es una medida de la diferencia promedio entre un valor predicho y el valor real. Objetivo: cuanto más cerca de 0, mejor Intervalo: [0, inf) |
|
| median_absolute_error | El error medio absoluto es la media de todas las diferencias absolutas entre el destino y la predicción. Esta pérdida es estable para los valores atípicos. Objetivo: cuanto más cerca de 0, mejor Intervalo: [0, inf) Tipos: median_absolute_errornormalized_median_absolute_error: es median_absolute_error dividido por el intervalo de los datos. |
Cálculo |
| r2_score | R2 (el coeficiente de determinación) mide la reducción proporcional del error cuadrado medio (MSE) con respecto a la varianza total de los datos observados. Objetivo: cuanto más cerca de 1, mejor Intervalo: [-1, 1] Nota: R2 a menudo tiene el intervalo [-inf, 1]. El MSE puede ser mayor que la varianza observada, por lo que R2 puede tener valores negativos arbitrariamente grandes, en función de los datos y las predicciones del modelo. Los clips de ML automatizado informaron puntuaciones de R2 de -1, por lo que un valor de -1 para R2 probablemente significa que la puntuación real de R2 es menor que -1. Tenga en cuenta el resto de valores de métricas y las propiedades de los datos al interpretar una puntuación negativa de R2. |
Cálculo |
| root_mean_squared_error | La raíz del error cuadrático medio (RMSE) es la raíz cuadrada de la diferencia cuadrática esperada entre el destino y la predicción. Para un estimador no sesgado, RMSE es igual a la desviación estándar. Objetivo: cuanto más cerca de 0, mejor Intervalo: [0, inf) Tipos: root_mean_squared_error normalized_root_mean_squared_error: es root_mean_squared_error dividido por el intervalo de los datos. |
Cálculo |
| root_mean_squared_log_error | La raíz del error logarítmico cuadrático medio es la raíz cuadrada del error logarítmico cuadrático esperado. Objetivo: cuanto más cerca de 0, mejor Intervalo: [0, inf) Tipos: root_mean_squared_log_error normalized_root_mean_squared_log_error: es root_mean_squared_log_error dividido por el intervalo de los datos. |
Cálculo |
| spearman_correlation | La correlación de Spearman es una medida no paramétrica de la monotonicidad de la relación entre dos conjuntos de datos. A diferencia de la correlación de Pearson, la correlación de Spearman no asume que los dos conjuntos de datos se distribuyen normalmente. Como sucede con otros coeficientes de correlación, Spearman varía entre -1 y + 1, y 0 implica que no hay ninguna correlación. Las correlaciones de -1 o 1 implican una relación monotónica exacta. Spearman es una métrica de correlación de orden de rango, lo que significa que los cambios en los valores previstos o reales no cambiarán el resultado de Spearman si no cambian el orden de rango de los valores previstos o reales. Objetivo: cuanto más cerca de 1, mejor Intervalo: [-1, 1] |
Cálculo |
Normalización de métricas
El aprendizaje automático automatizado normaliza las métricas de regresión y previsión, lo que permite realizar una comparación entre los modelos que se entrenan en los datos con diferentes intervalos. Un modelo entrenado en datos con un intervalo mayor tiene un error mayor que el mismo modelo entrenado en datos con un intervalo más pequeño, a menos que ese error esté normalizado.
Aunque no hay ningún método estándar para normalizar las métricas de error, el aprendizaje automático automatizado adopta el enfoque común de dividir el error entre el rango de los datos: normalized_error = error / (y_max - y_min).
Nota:
El rango de datos no se guarda con el modelo. Si hace la inferencia con el mismo modelo en un conjunto de prueba de datos de exclusión, y_min y y_max pueden cambiar según los datos de prueba y es posible que las métricas normalizadas no se usen directamente para comparar el rendimiento del modelo en los conjuntos de entrenamiento y prueba. Puede pasar el valor de y_min y y_max del conjunto de entrenamiento para que la comparación sea equitativa.
Métricas de previsión: normalización y agregación
El cálculo de métricas para la evaluación del modelo de previsión requiere algunas consideraciones especiales cuando los datos contienen varias series temporales. Hay dos opciones naturales para agregar métricas en varias series:
- Un promedio de macro en el que las métricas de evaluación de cada serie tienen el mismo peso,
- Un promedio de micro en el que las métricas de evaluación de cada predicción tienen el mismo peso.
Estos casos tienen analogías directas con los promedios de macro y micro en la clasificación multiclase.
La distinción entre promedios de macro y micro puede ser importante a la hora de seleccionar una métrica principal para la selección de modelos. Por ejemplo, considere un escenario minorista en el que desea prever la demanda de una selección de productos de consumo. Algunos productos venden a volúmenes más altos que otros. Si elige un RMSE con promedio de micro como métrica principal, es posible que los artículos de gran volumen sean los que más contribuyan al error de modelado y, en consecuencia, dominen la métrica. El algoritmo de selección de modelos podría favorecer los modelos con mayor precisión en los artículos de gran volumen que en los de bajo volumen. Por el contrario, un RMSE normalizado con promedio de macro otorga a los artículos de bajo volumen una ponderación aproximadamente igual a la de los artículos de gran volumen.
En la tabla siguiente se muestra cuáles de las métricas de previsión del aprendizaje automático automatizado usan promedio de macro frente a micro:
| Promedio de macro | Promedio de micro |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Tenga en cuenta que las métricas con promedio de macro normalizan cada serie por separado. Las métricas normalizadas de cada serie se calculan como promedio para proporcionar el resultado final. La elección correcta de macro frente a micro depende del escenario empresarial, pero generalmente se recomienda usar normalized_root_mean_squared_error.
Valores residuales
El gráfico de valores residuales es un histograma de los errores de predicción (residuales) generados para los experimentos de regresión y previsión. Los valores residuales se calculan como y_predicted - y_true para todas las muestras y luego se muestran como un histograma para mostrar el sesgo del modelo.
En este ejemplo, ambos modelos tienen un ligero sesgados, con el fin de predecir menos que el valor real. Esto no es infrecuente en los conjunto de datos con una distribución sesgada de los objetivos reales, pero indica que el rendimiento del modelo es peor. Un buen modelo tiene una distribución de valores residuales cuyo máximo es cero y con pocos valores residuales en los extremos. Un modelo peor tiene una distribución de valores residuales dispersos con menos muestras alrededor del cero.
Gráfico de valores residuales para un buen modelo

Gráfico de valores residuales para un mal modelo

Valores predichos frente a valores verdaderos
Para el experimento de regresión y previsión, el gráfico de predicho frente a verdadero traza la relación entre la característica de destino (valores verdaderos/reales) y las predicciones del modelo. Los valores verdaderos se discretizan a lo largo del eje X y para cada rango, el valor medio predicho se traza con barras de error. Esto le permite ver si un modelo está sesgado hacia la predicción de ciertos valores. La línea muestra la predicción promedio y el área sombreada indica la variación de las predicciones alrededor de esa media.
A menudo, el valor verdadero más común tiene las predicciones más precisas con la menor varianza. La distancia de la línea de tendencia de la línea y = x ideal donde hay pocos valores verdaderos es una buena medida del rendimiento del modelo en valores atípicos. Puede usar el histograma situado en la parte inferior del gráfico para razonar sobre la distribución de datos real. Incluir más muestras de datos, donde la distribución es dispersa, puede mejorar el rendimiento del modelo en datos no visibles.
En este ejemplo, observe que el mejor modelo tiene una línea de valores predichos frente a valores verdaderos que está más próxima a la línea y = x ideal.
Gráfico de valores predichos frente a valores verdaderos para un buen modelo

Gráfico de valores predichos frente a valores verdaderos para un mal modelo

Horizonte de previsión
En el caso de los experimentos de previsión, el gráfico de horizonte de previsión traza la relación entre el valor previsto de los modelos y los valores reales asignados a lo largo del tiempo por pliegue de validación cruzada, hasta cinco pliegues. El eje X asigna el tiempo en función de la frecuencia proporcionada durante la configuración del entrenamiento. La línea vertical del gráfico marca el punto del horizonte de previsión, también denominado línea de horizonte, que es el período de tiempo en el que quiere empezar a generar predicciones. A la izquierda de la línea del horizonte de previsión, puede ver los datos de entrenamiento históricos para visualizar mejor las tendencias anteriores. A la derecha del horizonte de previsión, puede visualizar las predicciones (la línea púrpura) frente a los valores reales (la línea azul) para los diferentes pliegues de validación cruzada e identificadores de serie temporal. El área púrpura sombreada indica los intervalos de confianza o la varianza de las predicciones en torno a esa media.
Puede elegir qué combinaciones de identificador de serie temporal y pliegue de validación cruzada se muestra al hacer clic en el icono de lápiz de edición en la esquina superior derecha del gráfico. Seleccione cualquiera de los cinco primeros pliegues de validación cruzada y hasta veinte identificadores de series temporales diferentes para visualizar el gráfico de sus distintas series temporales.
Importante
Este gráfico está disponible en la ejecución de entrenamiento para los modelos generados a partir de datos de entrenamiento y validación, así como en la ejecución de pruebas en función de los datos de entrenamiento y los datos de prueba. Se permiten hasta 20 puntos de datos antes del origen de la previsión, y hasta 80 puntos de datos después. En el caso de los modelos DNN, este gráfico de la ejecución de entrenamiento muestra los datos de la última época, es decir, después de que el modelo se haya entrenado por completo. Este gráfico de la ejecución de pruebas puede tener un intervalo antes de la línea de horizonte si los datos de validación se proporcionaron explícitamente durante la ejecución del entrenamiento. Esto se debe a que los datos de entrenamiento y los datos de prueba se usan en la ejecución de pruebas, lo que deja fuera los datos de validación, lo que da lugar a una brecha.

Métricas de modelos de imagen (versión preliminar)
ML automatizado usa las imágenes del conjunto de datos de validación para evaluar el rendimiento del modelo. El rendimiento del modelo se mide en un nivel de época para comprender cómo progresa el entrenamiento. Una época concluye cuando un conjunto de datos completo ha pasado hacia delante y hacia atrás a través de la red neuronal exactamente una vez.
Métricas de clasificación de imágenes
La métrica principal para la evaluación es accuracy en los modelos de clasificación binarios y multiclase, e IoU (Intersection over Union) en los modelos de clasificación multietiqueta. Las métricas de clasificación de los modelos de clasificación de imágenes son las mismas que las definidas en la sección de métricas de clasificación. Los valores de pérdida asociados a una época también se registran, lo que puede ayudar a supervisar cómo progresa el entrenamiento y a determinar si el modelo está sobreajustado o subajustado.
Cada predicción de un modelo de clasificación está asociada a una puntuación de confianza que indica el nivel de confianza con el que se ha realizado la predicción. Los modelos de clasificación de imágenes multietiqueta se evalúan de manera predeterminada con un umbral de puntuación de 0,5, lo que significa que solo las predicciones con al menos este nivel de confianza se consideran como una predicción positiva en la clase asociada. La clasificación multiclase no usa un umbral de puntuación, sino que la clase que tiene la máxima puntuación de confianza se considera la predicción.
Métricas de nivel de época para la clasificación de imágenes
A diferencia de las métricas de clasificación para conjuntos de datos tabulares, los modelos de clasificación de imágenes registran todas las métricas de clasificación en un nivel de época, como se muestra a continuación.

Métricas de resumen para la clasificación de imágenes
Además de las métricas escalares que se registran en el nivel de época, el modelo de clasificación de imágenes también registra métricas de resumen como matriz de confusión, gráficos de clasificación que incluyen curva ROC, curva de precisión-recuperación e informe de clasificación para el modelo de la mejor época en la que se obtiene la puntuación de métrica principal (accuracy) más alta.
El informe de clasificación ofrece los valores de nivel de clase de las métricas como precision, recall, f1-score, support, auc y average_precision, con varios niveles de promedio: micro, macro y ponderado, tal como se muestra a continuación. Consulte las definiciones de las métricas de la sección de métricas de clasificación.

Métricas de detección de objetos y segmentación de instancias
Cada predicción de un modelo de detección de objetos de imagen o segmentación de instancias está asociada a una puntuación de confianza.
Las predicciones con una puntuación de confianza mayor que el umbral de puntuación se devuelven como predicciones y se usan en el cálculo de métricas, cuyo valor predeterminado es específico del modelo y se puede consultar desde la página de optimización de hiperparámetros (hiperparámetro box_score_threshold).
El cálculo de métricas de un modelo de segmentación de instancias y detección de objetos de imagen se basa en una medida de superposición definida por una métrica denominada IoU (Intersection over Union), que se calcula dividiendo el área de superposición entre la verdad terreno y las predicciones por el área de unión de la verdad terreno y las predicciones. La IoU calculada a partir de cada predicción se compara con un umbral de superposición denominado umbral de IoU que determina cuánto debe superponerse una predicción con una verdad de base anotada por el usuario para que se considere una predicción positiva. Si la IoU calculada a partir de la predicción es inferior al umbral de superposición, la predicción no se considerará positiva para la clase asociada.
La métrica principal para la evaluación de modelos de detección de objetos de imagen y segmentación de instancias es la precisión media (mAP). mAP es el valor medio de la precisión media (AP) en todas las clases. Los modelos de detección de objetos de ML automatizado admiten el cálculo de mAP con los dos métodos populares siguientes.
Métricas de Pascal VOC:
mAP de Pascal VOC es la forma predeterminada de cálculo de mAP para modelos de segmentación de instancias o detección de objetos. El método mAP de estilo Pascal VOC calcula el área bajo una versión de la curva de precisión-recuperación. La primera p(ri), que es la precisión en la recuperación i, se calcula para todos los valores de recuperación únicos. p(rᵢ) luego se reemplaza por la precisión máxima obtenida de cualquier recuperación r' >= rᵢ. El valor de precisión disminuye de forma continuada en esta versión de la curva. La métrica mAP de Pascal VOC se evalúa de manera predeterminada con un umbral de IoU de 0,5. En este blog hay una explicación detallada de este concepto.
Métricas de COCO:
El método de evaluación COCO usa un método interpolado de 101 puntos para el cálculo de AP junto con un promedio de más de diez umbrales de IoU. AP@[.5:.95] corresponde al promedio de AP para IoU de 0,5 a 0,95 con un tamaño de paso de 0,05. El aprendizaje automático automatizado registra las doce métricas definidas por el método COCO, lo que incluye AP y AR (recuperación media) en varias escalas en los registros de aplicación, mientras que la interfaz de usuario de métricas muestra solo mAP en un umbral de IoU de 0,5.
Sugerencia
La evaluación del modelo de detección de objetos de imagen puede usar métricas de COCO si el hiperparámetro validation_metric_type está establecido en "coco", como se explica en la sección de optimización de hiperparámetros.
Métricas de nivel de época para la detección de objetos y la segmentación de instancias
Los valores de mAP, precision, and recall se registran en un nivel de época para los modelos de segmentación de instancias o detección de objetos de imagen. Las métricas mAP, precision y recall también se registran en un nivel de clase con el nombre "per_label_metrics". "per_label_metrics" debe verse como una tabla.
Nota
Las métricas de nivel de época precision, recall y per_label_metrics no están disponibles cuando se usa el método "coco".

Panel de inteligencia artificial responsable para el mejor modelo de AutoML recomendado (versión preliminar)
El panel de IA responsable de Azure Machine Learning proporciona una única interfaz para ayudarle a implementar IA responsable en la práctica de forma eficaz y eficiente. El panel de inteligencia artificial responsable solo se admite mediante datos tabulares y solo se admite en los modelos de clasificación y regresión. Reúne varias herramientas de IA responsable maduras en las áreas de:
- Evaluación del rendimiento y la equidad del modelo
- Exploración de datos
- Interpretabilidad de Machine Learning
- Análisis de errores
Aunque las métricas y los gráficos de evaluación de modelos son buenos para medir la calidad general de un modelo, las operaciones como inspeccionar la equidad del modelo, ver sus explicaciones (también conocidas como qué conjunto de datos incluye un modelo usado para realizar sus predicciones), inspeccionar sus errores y posibles puntos ciegos son esenciales al practicar la inteligencia artificial responsable. Por eso el aprendizaje automático automatizado proporciona un panel de IA responsable para ayudarle a observar una variedad de información para el modelo. Consulte la manera de ver el panel de IA responsable en el Estudio de Azure Machine Learning.
Vea cómo puede generar este panel a través de la interfaz de usuario o el SDK.
Explicaciones del modelo e importancias de las características
Si bien las métricas y los gráficos de evaluación del modelo son buenos para medir la calidad general de un modelo, inspeccionar qué características del conjunto de datos usa para hacer sus predicciones es esencial cuando se practica la IA responsable. Este es el motivo por el que ML automatizado proporciona un panel de explicaciones del modelo para medir y notificar las contribuciones relativas de las características del conjunto de datos. Consulte la manera de ver el panel de explicaciones en el Estudio de Azure Machine Learning.
Nota
La interpretabilidad, la mejor explicación del modelo, no está disponible para los experimentos de previsión de ML automatizados que recomiendan los algoritmos siguientes como el mejor modelo:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- Media
- Naive
- Media estacional
- Naive estacional
Pasos siguientes
- Pruebe los cuadernos de ejemplo de la explicación del modelo de aprendizaje automático automatizado.
- En el caso de preguntas específicas sobre ML automatizado, puede escribir a askautomatedml@microsoft.com.