Entrenamiento del modelo de regresión con ML automatizado y Python (SDK v1)
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, aprenderá a entrenar un modelo de regresión con el SDK de Python para Azure Machine Learning mediante el modelo de ML automatizado de Azure Machine Learning. El modelo de regresión predice tarifas de pasajeros para taxis que operan en la ciudad de Nueva York (NYC). Puede escribir código con el SDK de Python para configurar un área de trabajo con datos preparados, entrenar el modelo localmente con parámetros personalizados y explorar los resultados.
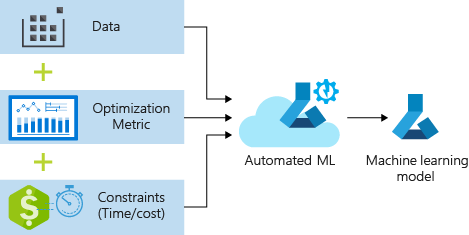
El proceso acepta los datos de entrenamiento y las opciones de configuración. Itera automáticamente a través de combinaciones de diferentes métodos de normalización y estandarización de características, modelos y configuración de hiperparámetros para llegar al mejor modelo. En el diagrama siguiente, se muestra el flujo de proceso para el entrenamiento del modelo de regresión:
Requisitos previos
Suscripción a Azure. Puede crear una cuenta gratuita o de pago de Azure Machine Learning.
Un área de trabajo o una instancia de proceso de Azure Machine Learning. Para preparar estos recursos, consulte Inicio rápido: Introducción a Azure Machine Learning.
Obtenga los datos de ejemplo preparados para los ejercicios del tutorial cargando un cuaderno en el área de trabajo:
Vaya al área de trabajo en Estudio de Azure Machine Learning, seleccione Cuadernos y, a continuación, seleccione la pestaña Ejemplos.
En la lista de cuadernos, expanda el nodo Ejemplos>SDK v1>tutoriales>regression-automl-nyc-taxi-data.
Seleccione el cuaderno regression-automated-ml.ipynb.
Para ejecutar cada celda del cuaderno como parte de este tutorial, seleccione Clonar este archivo.
Enfoque alternativo: si lo prefiere, puede ejecutar los ejercicios del tutorial en un entorno local. El tutorial está disponible en el repositorio de Cuadernos de Azure Machine Learning en GitHub. Para este enfoque, siga estos pasos para obtener los paquetes necesarios:
Ejecute el comando
pip install azureml-opendatasets azureml-widgetsen el equipo local para obtener los paquetes necesarios.
Descargar y preparar los datos
El paquete de Open Datasets contiene una clase que representa cada origen de datos (como NycTlcGreen) para filtrar fácilmente los parámetros de fecha antes de la descarga.
El código siguiente importa los paquetes necesarios:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
El primer paso es crear un dataframe para los datos del taxi. Cuando trabaja en un entorno que no es de Spark, el paquete de Open Datasets permite descargar solo un mes de datos a la vez con determinadas clases. Este enfoque ayuda a evitar el problema MemoryError que puede producirse con grandes conjuntos de datos.
Para descargar los datos del taxi, capture iterativamente un mes a la vez. Antes de anexar el siguiente conjunto de datos al dataframe green_taxi_df, muestree aleatoriamente 2000 registros de cada mes y, a continuación, obtenga una vista previa de los datos. Este enfoque ayuda a evitar el sobredimensionamiento del dataframe.
El código siguiente crea el dataframe, captura los datos y lo carga en el dataframe:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
En la tabla siguiente, se muestran las varias columnas de valores de los datos de taxi de ejemplo:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1,88 | None | None | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15.0 | 1.0 | 0,5 | 0,3 | 4,00 | 0,0 | None | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | None | None | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11,5 | 0,5 | 0,5 | 0,3 | 2.55 | 0,0 | None | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3.54 | None | None | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13.5 | 0,5 | 0,5 | 0,3 | 2,80 | 0,0 | None | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1.00 | None | None | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0,0 | 0,5 | 0,3 | 0.00 | 0,0 | None | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | None | None | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18.5 | 0,0 | 0,5 | 0,3 | 3.85 | 0,0 | None | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | None | None | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24,0 | 0,0 | 0,5 | 0,3 | 4.80 | 0,0 | None | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | None | None | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0,0 | 0,5 | 0,3 | 1.30 | 0,0 | None | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | None | None | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0,0 | 0,5 | 0,3 | 0.00 | 0,0 | None | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3.00 | None | None | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14,0 | 0,5 | 0,5 | 0,3 | 2,00 | 0,0 | None | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | None | None | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0,0 | 0,5 | 0,3 | 2,00 | 0,0 | None | 12,80 | 1.0 |
Resulta útil quitar algunas columnas que no necesita para el entrenamiento ni para otra compilación de características. Por ejemplo, puede quitar la columna lpepPickupDatetime porque ML automatizado controla automáticamente las características basadas en el tiempo.
El código siguiente quita 14 columnas de los datos de ejemplo:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Limpieza de datos
El siguiente paso es limpiar los datos.
El código siguiente ejecuta la función describe() en el nuevo dataframe para generar estadísticas de resumen para cada campo:
green_taxi_df.describe()
En la tabla siguiente, se muestran las estadísticas de resumen de los campos restantes de los datos de ejemplo:
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| mean | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| min | 1.00 | 0.00 | 0.00 | -74.357101 | 0.00 | -74.342766 | 0.00 | -120.80 |
| 25% | 2.00 | 1.00 | 1.05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8.00 |
| 50% | 2.00 | 1.00 | 1,93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| El 75 % | 2.00 | 1.00 | 3,70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| max | 2.00 | 8.00 | 154.28 | 0.00 | 41.109089 | 0.00 | 40.982826 | 425.00 |
Las estadísticas de resumen revelan varios campos atípicos, que son valores que reducen la precisión del modelo. Para solucionar este problema, filtre los campos latitud/longitud (lat/long) para que los valores estén dentro de los límites del área de Manhattan. Este enfoque filtrará los trayectos en taxi más largos o los trayectos que sean valores atípicos en lo que respecta a su relación con otras características.
Después, filtre el campo tripDistance para los valores mayores que cero, pero menores que 31 millas (la distancia del semiverseno entre los dos pares lat/long). Esta técnica elimina los recorridos atípicos largos que tengan un costo de trayecto incoherente.
Por último, el campo totalAmount tiene valores negativos para las tarifas de taxi, que no tienen sentido en el contexto del modelo. El campo passengerCount también contiene datos incorrectos en los que el valor mínimo es cero.
El código siguiente filtra estas anomalías de valor mediante funciones de consulta. A continuación, el código quita las últimas columnas que no son necesarias para el entrenamiento:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
El último paso de esta secuencia es llamar a la función describe() de nuevo en los datos para garantizar que la limpieza funcione según lo previsto. Ahora tiene un conjunto preparado y limpio de datos meteorológicos, de taxis y de días festivos que se utilizará para entrenar el modelo de Machine Learning:
final_df.describe()
Configuración del área de trabajo
Cree un objeto de área de trabajo desde el área de trabajo existente. Un área de trabajo es una clase que acepta la información de recursos y suscripciones de Azure. También crea un recurso en la nube para supervisar y realizar un seguimiento de las ejecuciones del modelo.
El código siguiente llama a la función Workspace.from_config() para leer el archivo config.json y cargar los detalles de autenticación en un objeto denominado ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
En el resto del código de este tutorial, se usa el objeto ws.
Dividir los datos en conjuntos de entrenamiento y prueba
Divida los datos en conjuntos de entrenamiento y prueba mediante la función train_test_split de la biblioteca scikit-learn. Esta función segrega los datos entre el conjunto de datos "x" (características) para el entrenamiento del modelo y el conjunto de datos "y" (valores a predecir) para la realización de pruebas.
El parámetro test_size determina el porcentaje de datos que se va a asignar a las pruebas. El parámetro random_state establece un valor de inicialización para el generador de números aleatorios, de forma que las divisiones de entrenamiento o prueba son deterministas.
El código siguiente llama a la función train_test_split para cargar los conjuntos de datos "x" y "y":
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
El propósito de este paso es preparar los puntos de datos para probar el modelo terminado que no se usa para entrenar el modelo. Estos puntos se usan para medir la precisión verdadera. Un modelo bien entrenado es aquel que puede realizar predicciones precisas a partir de datos no vistos. Ahora tiene los datos preparados para entrenar automáticamente un modelo de Machine Learning.
Entrenamiento automático de un modelo
Para entrenar automáticamente un modelo, realice los pasos siguientes:
Defina la configuración de la ejecución del experimento. Asocie los datos de entrenamiento a la configuración y modifíquela para controlar el entrenamiento.
Envíe el experimento para la optimización del modelo. Después de enviar el experimento, el proceso se itera mediante distintos algoritmos de aprendizaje automático y configuraciones de hiperparámetros, de conformidad con las restricciones definidas. Elige el modelo de ajuste perfecto mediante la optimización de una métrica de precisión.
Definición de la configuración del entrenamiento
Defina los parámetros del experimento y la configuración de los modelos para el entrenamiento. Vea la lista completa de valores. El envío del experimento con esta configuración predeterminada tarda aproximadamente entre 5 y 20 minutos. Para reducir el tiempo de ejecución, reduzca el parámetro experiment_timeout_hours.
| Propiedad | Valor en este tutorial | Descripción |
|---|---|---|
iteration_timeout_minutes |
10 | Límite de tiempo en minutos para cada iteración. Aumente este valor para conjuntos de datos mayores que necesiten más tiempo para cada iteración. |
experiment_timeout_hours |
0,3 | Cantidad máxima de tiempo en horas que pueden tardar todas las iteraciones combinadas antes de que finalice el experimento. |
enable_early_stopping |
True | Marca para permitir la finalización prematura si la puntuación no mejora a corto plazo. |
primary_metric |
spearman_correlation | Métrica que desea optimizar. El modelo de ajuste perfecto se elegirá según esta métrica. |
featurization |
auto | El valor automático permite que el experimento preprocese los datos de entrada, incluido el control de los datos que faltan, la conversión de texto en numérico, etc. |
verbosity |
logging.INFO | Controla el nivel de registro. |
n_cross_validations |
5 | Número de divisiones de la validación cruzada que se realizarán cuando no se especifiquen datos de validación. |
El código siguiente envía el experimento:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
El código siguiente le permite usar la configuración de entrenamiento definida como parámetro **kwargs para un objeto AutoMLConfig. Además, puede especificar los datos de entrenamiento y el tipo de modelo, regression, en este caso.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Nota:
Los pasos previos al procesamiento de ML automatizado (normalización de características, control de los datos que faltan, conversión de valores de texto a numéricos, etc.) se convierten en parte del modelo subyacente. Cuando se utiliza el modelo para las predicciones, se aplican automáticamente a los datos de entrada los mismos pasos previos al procesamiento que se aplican durante el entrenamiento.
Entrenamiento del modelo de regresión automática
Cree un objeto de experimento en el área de trabajo. Un experimento actúa como un contenedor para los trabajos individuales. Pase el objeto automl_config definido al experimento y establezca la salida en True para ver el progreso durante el trabajo.
Después de iniciar el experimento, la salida mostrada se actualiza en directo a medida que se ejecuta el experimento. Para cada iteración, verá el tipo de modelo, la duración de la ejecución y la precisión del entrenamiento. El campo BEST realiza el seguimiento de la mejor puntuación de entrenamiento en ejecución en función del tipo de métrica:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Esta es la salida:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Exploración de los resultados
Explore los resultados del entrenamiento automático con un widget de Jupyter. El widget le permite ver un grafo y una tabla de todas las iteraciones de trabajo individuales, junto con los metadatos y las métricas de precisión del entrenamiento. Además, puede filtrar por métricas de precisión diferentes de la principal con el selector desplegable.
El código siguiente genera un gráfico para explorar los resultados:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Los detalles de ejecución del widget de Jupyter:

Gráfico de trazado para el widget de Jupyter:

Recuperación del mejor modelo
El código siguiente le permite seleccionar el mejor modelo de las iteraciones. La función get_output devuelve la mejor ejecución y el modelo ajustado de la última invocación de ajuste. Mediante el uso de las sobrecargas en la función get_output, puede recuperar la mejor ejecución y el modelo ajustado para cualquier métrica registrada o para una iteración concreta.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Probar la mejor precisión del modelo
Use el mejor modelo para ejecutar predicciones en el conjunto de datos de prueba para predecir las tarifas del taxi. La función predict usa el mejor modelo y predice los valores de "y", precio del recorrido, a partir del conjunto de datos x_test.
El código siguiente imprime los 10 primeros valores de costo previstos del conjunto de datos y_predict:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Calcule el valor root mean squared error de los resultados. Convierta el dataframe y_test en una lista para compararla con los valores predichos. La función mean_squared_error toma dos matrices de valores y calcula el error medio al cuadrado entre ellos. Al tomar la raíz cuadrada del resultado, se produce un error en las mismas unidades que la variable y, costo. Indica aproximadamente cuánto se alejan las predicciones de la tarifa del taxi de las reales.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Ejecute el siguiente código para calcular el error medio absoluto porcentual (MAPE) usando los conjuntos de datos y_actual y y_predict completos. Esta métrica calcula una diferencia absoluta entre cada valor predicho y real, y suma todas las diferencias. A continuación, expresa esa suma como porcentaje del total de los valores reales.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Esta es la salida:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
A partir de las dos métricas de precisión de la predicción, verá que el modelo es bastante bueno en la predicción de las tarifas de taxi a partir de las características del conjunto de datos, normalmente en un margen de +/-4,00 dólares estadounidenses y con un error del 15 %, aproximadamente.
El proceso de desarrollo de modelos de Machine Learning tradicional es muy intensivo respecto de recursos. Requiere un conocimiento significativo del dominio y una inversión de tiempo para ejecutar y comparar los resultados de docenas de modelos. El uso del aprendizaje automático automatizado es una manera estupenda de probar muchos modelos distintos para el escenario rápidamente.
Limpieza de recursos
Si no tiene previsto trabajar en otros tutoriales de Azure Machine Learning, complete los pasos siguientes para quitar los recursos que ya no necesita.
Detención del proceso
Si ha usado un proceso, puede detener la máquina virtual cuando no la use y reducir los costos:
Vaya al área de trabajo en Estudio de Azure Machine Learning y seleccione Proceso.
En la lista, seleccione el proceso que desea detener y, a continuación, seleccione Detener.
Cuando esté listo para volver a usar el proceso, puede reiniciar la máquina virtual.
Eliminación de otros recursos
Si no tiene previsto usar los recursos que ha creado en este tutorial, puede eliminarlos y evitar incurrir en cargos adicionales.
Siga estos pasos para quitar el grupo de recursos y todos los recursos:
En Azure Portal, vaya a Grupo de recursos.
En la lista, seleccione el grupo de recursos que ha creado en este tutorial y, a continuación, seleccione Eliminar grupo de recursos.
En el mensaje de confirmación, escriba el nombre del grupo de recursos y seleccione Eliminar.
Si desea mantener el grupo de recursos y eliminar solo una sola área de trabajo, siga estos pasos:
En Azure Portal, vaya al grupo de recursos que contiene el área de trabajo que desea quitar.
Seleccione el área de trabajo, seleccione Propiedades y, a continuación, seleccione Eliminar.