Inicio rápido: Introducción a Azure Machine Learning
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
Este tutorial es una introducción a algunas de las características más utilizadas del servicio Azure Machine Learning. En él, va a crear, registrar e implementar un modelo. Este tutorial le ayuda a familiarizarse con los conceptos básicos de Azure Machine Learning y su uso más común.
Va a aprender a ejecutar un trabajo de entrenamiento en un recurso de proceso escalable, a implementarlo y, por último, a probar la implementación.
Va a crear un script de entrenamiento para controlar la preparación de los datos, entrenar y registrar un modelo. Una vez entrene el modelo, lo implementa como un punto de conexión y, a continuación, llama al punto de conexión para la inferencia.
Los pasos son:
- Configure un manipulador para su área de trabajo de Azure Machine Learning
- Crear su script de aprendizaje
- Cree un recurso de proceso escalable, un clúster de proceso
- Cree y ejecute un trabajo de comandos que ejecute el script de entrenamiento en el clúster de proceso, configurado con el entorno de trabajo apropiado
- Visualización de la salida del script de entrenamiento
- Implementar el modelo recién entrenado como un punto de conexión
- Llamar al punto de conexión de Azure Machine Learning para la inferencia
Vea este vídeo para una introducción a los pasos de esta guía rápida.
Requisitos previos
-
Para usar Azure Machine Learning, necesita un área de trabajo. Si no tiene una, complete Crear recursos necesarios para empezar para crear un área de trabajo y obtener más información sobre su uso.
Importante
Si su área de trabajo de Azure Machine Learning está configurada con una red virtual administrada, es posible que deba agregar reglas de salida para permitir el acceso a los repositorios públicos de paquetes de Python. Para más información, consulte Escenario: Acceso a paquetes de aprendizaje automático públicos.
-
Inicie sesión en Studio y seleccione el área de trabajo si aún no está abierta.
-
Abra o cree una libreta en el área de trabajo:
- Si desea copiar y pegar código en celdas, cree un cuaderno nuevo.
- O, abra tutorials/get-started-notebooks/quickstart.ipynb desde la sección Ejemplos de Studio. A continuación, seleccione Clonar para agregar el cuaderno a sus Archivos. Para encontrar cuadernos de ejemplo, consulte Aprender con cuadernos de ejemplo.
Establecer el kernel y abrirlo en Visual Studio Code (VS Code)
En la barra superior del cuaderno abierto, cree una instancia de proceso si aún no tiene una.

Si la instancia de proceso se detiene, seleccione Iniciar proceso y espere hasta que se ejecute.

Espere hasta que la instancia de cálculo esté en ejecución. A continuación, asegúrese de que el kernel, que se encuentra en la parte superior derecha, es
Python 3.10 - SDK v2. Si no es así, use la lista desplegable para seleccionar este kernel.
Si no ve este kernel, compruebe que la instancia de proceso se está ejecutando. Si es así, seleccione el botón Actualizar situado en la parte superior derecha del cuaderno.
Si ves un banner que dice que debes autenticarte, selecciona Autenticar.
Puede ejecutar el cuaderno aquí o abrirlo en VS Code para un entorno de desarrollo integrado (IDE) completo con la eficacia de los recursos de Azure Machine Learning. Seleccione Abrir en VS Codey, a continuación, seleccione la opción web o de escritorio. Cuando se inicia de esta manera, VS Code se adjunta a la instancia de proceso, el kernel y el sistema de archivos del área de trabajo.
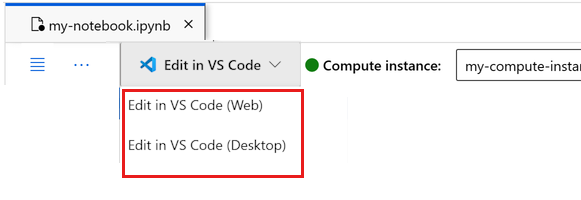




Importante
El resto de este tutorial contiene celdas del cuaderno del tutorial. Cópielas y péguelas en su nuevo cuaderno, o cambie al cuaderno actual si lo ha clonado.
Creación de un manipulador para el área de trabajo
Antes de profundizar en el código, necesita una manera de hacer referencia a su área de trabajo. El área de trabajo es el recurso de nivel superior para Azure Machine Learning, que proporciona un lugar centralizado para trabajar con todos los artefactos que crea al usar Azure Machine Learning.
Usted crea ml_client para un manejo del área de trabajo. A continuación, use ml_client para administrar los recursos y puestos de trabajo.
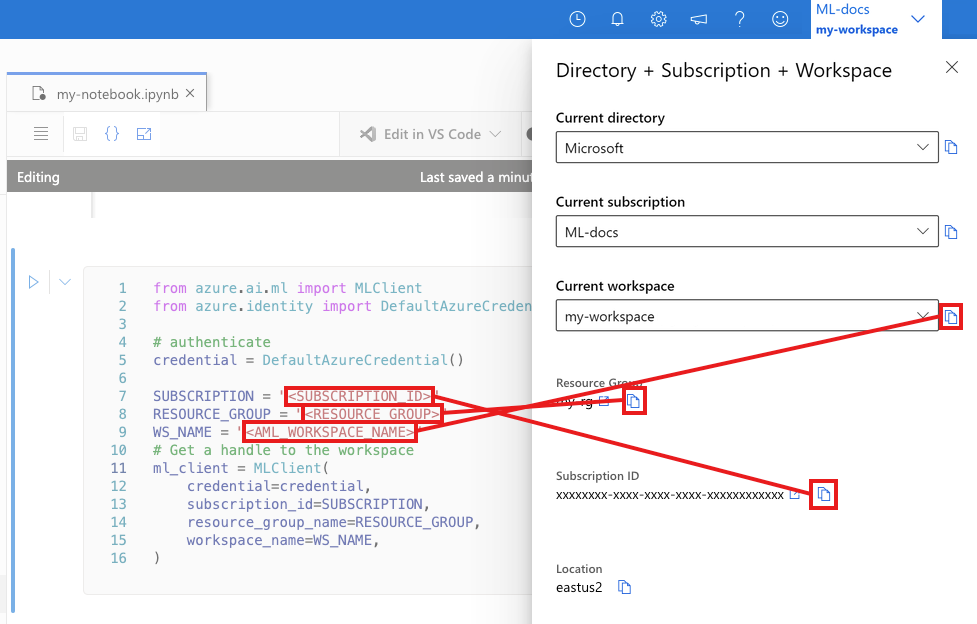
En la celda siguiente, escriba el identificador de suscripción, el nombre del grupo de recursos y el nombre del área de trabajo. Para establecer estos valores:
- En la barra de herramientas de Estudio de Azure Machine Learning superior derecha, seleccione el nombre del área de trabajo.
- Copie el valor del área de trabajo, el grupo de recursos y el identificador de suscripción en el código.
- Debe copiar un valor, cerrar el área y pegar y, a continuación, volver para el siguiente.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Nota
La creación de MLClient no se conectará al área de trabajo. La inicialización del cliente es lenta, esperará a la primera vez que necesite hacer una llamada (esto ocurrirá en la siguiente celda de código).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Creación del script de entrenamiento
Empecemos por crear el script de entrenamiento: el archivo de Python main.py.
En primer lugar, cree una carpeta de origen para el script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Este script controla el preprocesamiento de los datos, dividiéndolo en datos de prueba y de entrenamiento. A continuación, consume estos datos para entrenar un modelo basado en árbol y devolver el modelo de salida.
MLFlow se usa para registrar los parámetros y las métricas durante la ejecución de la canalización.
En la celda siguiente se usa IPython Magic para escribir el script de entrenamiento en el directorio que acaba de crear.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
# pin numpy
conda_env = {
'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': [
'python=3.10.15',
'pip<=21.3.1',
{
'pip': [
'mlflow==2.17.0',
'cloudpickle==2.2.1',
'pandas==1.5.3',
'psutil==5.8.0',
'scikit-learn==1.5.2',
'numpy==1.26.4',
]
}
],
}
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
conda_env=conda_env,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Como puede ver en este script, una vez entrenado el modelo, el archivo del modelo se guarda y registra en el área de trabajo. Ahora puede usar el modelo registrado en puntos de conexión de inferencia.
Es posible que tenga que seleccionar Actualizar para ver la nueva carpeta y el script en los archivos.
Configuración del comando
Ahora que tiene un script que puede realizar las tareas deseadas, y un clúster de proceso para ejecutar el script, va a usar un comando de uso general que puede ejecutar acciones de línea de comandos. Esta acción de línea de comandos puede llamar directamente a comandos del sistema o ejecutar un script.
Aquí, crea variables de entrada para especificar los datos de entrada, la relación de división, la velocidad de aprendizaje y el nombre del modelo registrado. El script de comando hará lo siguiente:
- Use un entorno que defina las bibliotecas de software y el runtime necesarios para el script de entrenamiento. Azure Machine Learning proporciona muchos entornos seleccionados o listos, que son útiles para escenarios comunes de entrenamiento e inferencia. Va a usar uno de esos entornos aquí. En Tutorial: Entrenamiento de un modelo en Azure Machine Learning, va a aprender a crear un entorno personalizado.
- Configure la propia acción de la línea de comandos,
python main.pyen este caso. Se puede acceder a las entradas y salidas del comando a través de la notación${{ ... }}. - En este ejemplo, se accede a los datos desde un archivo en Internet.
- Como no se ha especificado un recurso de proceso, el script se ejecutará en un clúster de proceso sin servidor que se crea automáticamente.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="azureml://registries/azureml/environments/sklearn-1.5/labels/latest",
display_name="credit_default_prediction",
)
Enviar el archivo
Ahora es el momento de enviar el trabajo para que se ejecute en Azure Machine Learning. Esta vez se usa create_or_update en ml_client.
ml_client.create_or_update(job)
Visualización de la salida del trabajo y espera para que finalice el trabajo
Para ver el trabajo en Estudio de Azure Machine Learning, seleccione el vínculo en la salida de la celda anterior.
La salida de este trabajo tendrá este aspecto en Estudio de Azure Machine Learning. Explore las pestañas para obtener varios detalles, como métricas, salidas, etc. Una vez completada, el trabajo registra un modelo en el área de trabajo como resultado del entrenamiento.

Importante
Espere hasta que se complete el estado del trabajo antes de volver a este cuaderno para continuar. El trabajo tardará entre 2 y 3 minutos en ejecutarse. Puede tardar más (hasta 10 minutos) si el clúster de proceso se ha reducido verticalmente a cero nodos y el entorno personalizado sigue creando.
Implementación del modelo como un punto de conexión en línea
Ahora, implemente el modelo de Machine Learning como un servicio web en la nube de Azure, un online endpoint.
Para implementar un servicio de aprendizaje automático, usará el modelo que registró.
Creación de un punto de conexión en línea
Ahora que tiene un modelo registrado, es hora de crear su punto de conexión en línea. El nombre del punto de conexión debe ser único en toda la región de Azure. En este tutorial, crea un nombre único mediante UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Creación del punto de conexión:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Nota
La creación del punto de conexión tardará unos minutos.
Una vez creado el punto de conexión, puede recuperarlo como se indica a continuación:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Implementación del modelo en el punto de conexión
Una vez creado el punto de conexión, implemente el modelo con el script de entrada. Cada punto de conexión puede tener varias implementaciones. El tráfico directo a estas implementaciones se puede especificar mediante reglas. Aquí crea una única implementación que controla el 100 % del tráfico entrante. Hemos elegido un nombre de color para la implementación, por ejemplo, implementaciones azules, verdes y rojas, que es arbitrario.
Puede consultar la página Modelos en el Estudio de Azure Machine Learning para identificar la última versión de su modelo registrado. Como alternativa, el código siguiente recuperará el número de la última versión para que lo use.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Implemente la última versión del modelo.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Nota
Esta implementación tardará entre 6 y 8 minutos aproximadamente.
Una vez finalizada la implementación, ya puede probarla.
Prueba con una consulta de ejemplo
Una vez que el modelo está implementado en el punto de conexión, puede ejecutar la inferencia con él.
Cree un archivo de solicitud de ejemplo después del diseño esperado en el método de ejecución en el script de puntuación.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Limpieza de recursos
Si no va a usar el punto de conexión, elimínelo para dejar de usar el recurso. Asegúrese de que ninguna otra implementación use un punto de conexión antes de eliminarlo.
Nota
El proceso de eliminación tardará aproximadamente 20 minutos.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Detención de una instancia de proceso
Si no va a utilizar ahora la instancia de proceso, deténgala:
- En el estudio, en el área de navegación de la izquierda, seleccione Proceso.
- En las pestañas superiores, seleccione Instancia de proceso.
- Seleccione la instancia de proceso en la lista.
- En la barra de herramientas superior, seleccione Detener.
Eliminación de todos los recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
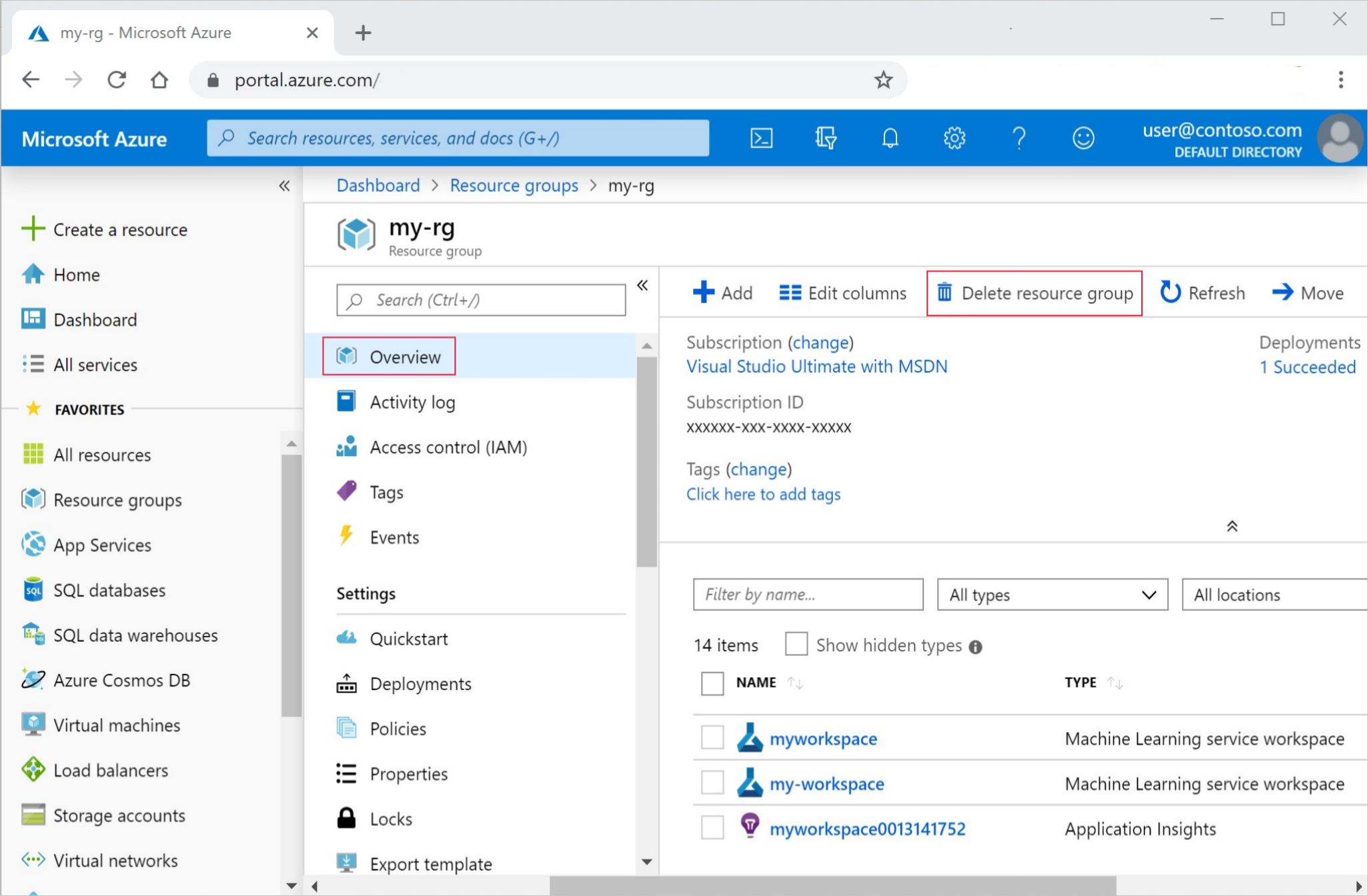
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Pasos siguientes
Ahora que tiene una idea de lo que implica el entrenamiento e implementación de un modelo, obtenga más información sobre el proceso en estos tutoriales:
| Tutorial | Descripción |
|---|---|
| Carga, acceso y exploración de datos en Azure Machine Learning | Almacenar datos grandes en la nube y recuperarlos de cuadernos y scripts |
| Desarrollo de modelos en una estación de trabajo en la nube | Iniciar prototipos y desarrollar modelos de aprendizaje automático |
| Entrenamiento de un modelo en Azure Machine Learning | Profundizar en los detalles del entrenamiento de un modelo |
| Implementar un modelo como un punto de conexión en línea | Profundizar en los detalles de la implementación de un modelo |
| Crear canalizaciones de aprendizaje automático de producción | Dividir una tarea de aprendizaje automático completa en un flujo de trabajo de varios pasos. |