Configuración de Pacemaker en Red Hat Enterprise Linux en Azure
En este artículo se describe cómo configurar un clúster de Pacemaker básico en Red Hat Enterprise Server (RHEL). Las instrucciones abarcan RHEL 7 y RHEL 8 y RHEL 9.
Requisitos previos
Lea primero las siguientes notas y artículos de SAP:
Documentación de alta disponibilidad (HA) de RHEL
- Configuración y administración de clústeres de alta disponibilidad.
- Directivas de soporte para clústeres de alta disponibilidad de RHEL: sbd y fence_sbd.
- Directivas de soporte técnico para clústeres de alta disponibilidad de RHEL: fence_azure_arm.
- Limitaciones conocidas del guardián emuladas por software.
- Exploración de los componentes de alta disponibilidad de RHEL: sbd y fence_sbd.
- Guía de diseño para clústeres de alta disponibilidad de RHEL: consideraciones sbd.
- Consideraciones para adoptar RHEL 8: alta disponibilidad y clústeres
Documentación de RHEL específica de Azure
Documentación de RHEL para ofertas de SAP
- Directivas de soporte técnico para clústeres de alta disponibilidad de RHEL: administración de SAP S/4HANA en un clúster.
- Configuración de SAP S/4HANA ASCS/ERS con Enqueue Server 2 (ENSA2) independiente en Pacemaker.
- Configuración de la replicación del sistema SAP HANA en el clúster de Pacemaker.
- Solución de alta disponibilidad de Red Hat Enterprise Linux para la escalabilidad horizontal de SAP HANA y replicación del sistema.
Información general
Importante
Los clústeres de Pacemaker que abarcan varias redes virtuales (VNets)/subredes no están cubiertos por las directivas de soporte técnico estándar.
Hay dos opciones disponibles en Azure para configurar la barrera en un clúster de Pacemaker para RHEL: agente de barrera de Azure, que reinicia un nodo con errores a través de las API de Azure o puede usar el dispositivo SBD.
Importante
En Azure, el clúster de alta disponibilidad de RHEL con barreras basadas en almacenamiento (fence_sbd) usa un guardián emulado por software. Es importante revisar lasLimitaciones conocidas del guardián emulado por software y lasdirectivas de soporte técnico para clústeres de alta disponibilidad de RHEL: sbd y fence_sbd al seleccionar SBD como mecanismo de barrera.
Uso de un dispositivo SBD
Nota:
El mecanismo de barreras con SBD se admite en RHEL 8.8 y versiones posteriores, y RHEL 9.0 y versiones posteriores.
Puede configurar el dispositivo SBD mediante cualquiera de estas dos opciones:
SBD con servidor de destino iSCSI
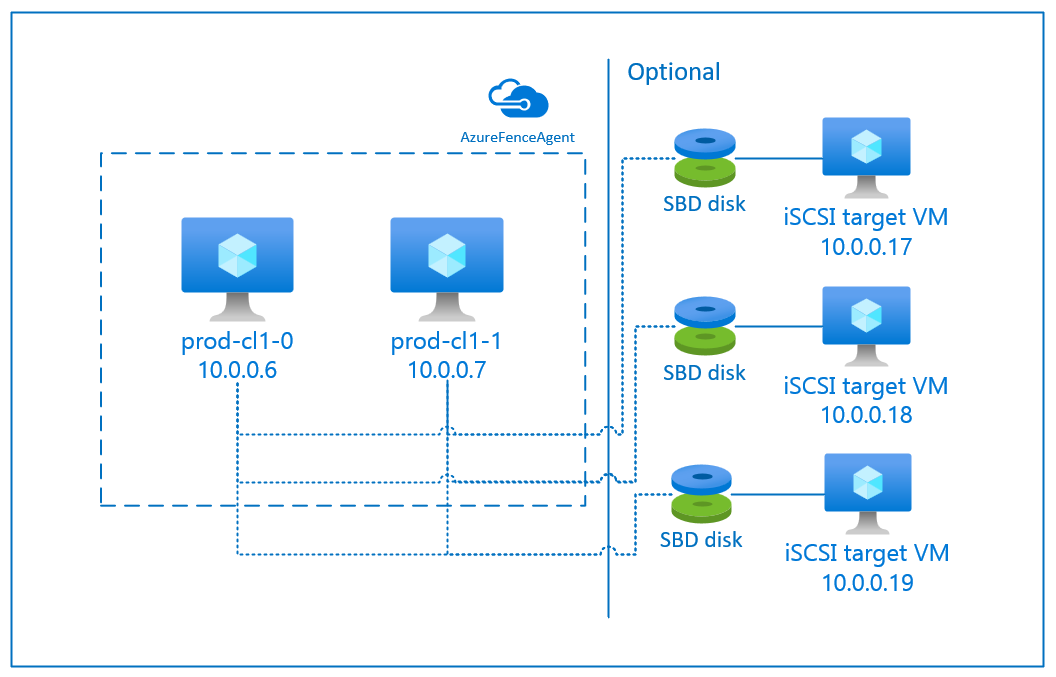
El dispositivo SBD requiere al menos una máquina virtual adicional (VM) que actúa como un servidor de destino de interfaz de sistema de proceso pequeño (iSCSI) de Internet y proporciona un dispositivo SBD. Sin embargo, estos servidores de destino iSCSI pueden compartirse con otros clústeres de Pacemaker. La ventaja de usar un dispositivo SBD es que, si ya usa dispositivos SBD en el entorno local, no requieren ningún cambio en la forma de operar el clúster de Pacemaker.
Puede usar hasta tres dispositivos SBD para un clúster de pacemaker para permitir que un dispositivo SBD deje de estar disponible (por ejemplo, durante la aplicación de revisiones del sistema operativo del servidor de destino iSCSI). Si desea usar más de un dispositivo SBD por pacemaker, asegúrese de implementar varios servidores de destino iSCSI y conectar un SBD desde cada servidor de destino iSCSI. Se recomienda usar uno o tres dispositivos SBD. Pacemaker no puede cercar automáticamente un nodo de clúster si solo se configuran dos dispositivos SBD y uno no está disponible. Si desea poder vallar cuando un servidor de destino iSCSI esté inactivo, deberá usar tres dispositivos SBD y, por tanto, tres servidores de destino iSCSI. Esta es la configuración más resistente cuando se usan SBD.
Importante
Cuando planifique la implantación y configuración de nodos de clúster pacemaker Linux y dispositivos SBD, no permita que el enrutamiento entre sus máquinas virtuales y las máquinas virtuales que alojan los dispositivos SBD pase por ningún otro dispositivo, como un dispositivo virtual de red (NVA).
Los eventos de mantenimiento y otros problemas con el NVA pueden tener un impacto negativo en la estabilidad y confiabilidad de la configuración general del clúster. Para obtener más información, consulte Reglas de enrutamiento definidas por el usuario.
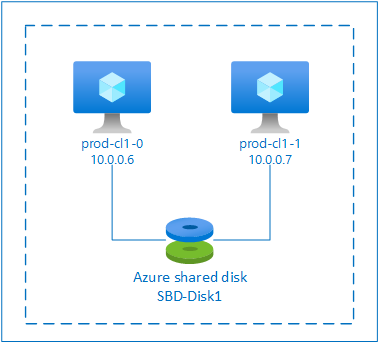
SBD con disco compartido de Azure
Para configurar un dispositivo SBD, debe conectar al menos un disco compartido de Azure a todas las máquinas virtuales que forman parte del clúster de pacemaker. La ventaja del dispositivo SBD mediante un disco compartido de Azure es que no es necesario implementar y configurar máquinas virtuales adicionales.
Estas son algunas consideraciones importantes acerca de los dispositivos SBD al configurar mediante Azure Shared Disk:
- El disco compartido de Azure con SSD prémium se admite como dispositivo SBD.
- Los dispositivos SBD que usan un disco compartido de Azure se admiten en RHEL 8.8 y versiones posteriores.
- Los dispositivos SBD que usan un disco de recursos compartidos Premium de Azure se admiten en almacenamiento con redundancia local (LRS) y almacenamiento con redundancia de zona (ZRS).
- En función del tipo de implementación, elija el almacenamiento redundante adecuado para un disco compartido de Azure como dispositivo SBD.
- Un dispositivo SBD que usa LRS para un disco compartido Premium de Azure (skuName - Premium_LRS) solo se admite con la implementación regional, como el conjunto de disponibilidad.
- Se recomienda un dispositivo SBD mediante ZRS para un disco compartido premium de Azure (skuName - Premium_ZRS) con implementación zonal, como zona de disponibilidad, o conjunto de escalado con FD=1.
- Un ZRS para disco administrado está disponible actualmente en las regiones enumeradas en el documento de disponibilidad regional.
- No es necesario que el disco compartido de Azure que use para dispositivos SBD sea grande. El valor maxShares determina cuántos nodos de clúster puede usar el disco compartido. Por ejemplo, puede usar tamaños de disco P1 o P2 para el dispositivo SBD en un clúster de dos nodos, como el escalado vertical SAP ASCS/ERS o SAP HANA.
- En el caso del escalado horizontal de HANA con la replicación del sistema de HANA (HSR) y pacemaker, puede usar un disco compartido de Azure para dispositivos SBD en clústeres con hasta cinco nodos por sitio de replicación debido al límite actual de maxShares.
- No se recomienda conectar un dispositivo SBD de disco compartido de Azure a través de clústeres de pacemaker.
- Si usa varios dispositivos SBD de disco compartido de Azure, compruebe el límite para el número máximo de discos de datos que se pueden conectar a la máquina virtual.
- Para más información sobre las limitaciones del disco compartido de Azure, repase minuciosamente la sección "Limitaciones" de la documentación del disco compartido de Azure.
Uso de un agente de barrera de Azure
Puede configurar barreras mediante un agente de barrera de Azure. El agente de barrera de Azure requiere identidades administradas para las máquinas virtuales del clúster o una entidad de servicio o una identidad del sistema administrada (MSI) que administra reiniciar los nodos con errores a través de las API de Azure. Los agentes de barrera de Azure no requieren la implementación de máquinas virtuales adicionales.
Configuración de un servidor de destino iSCSI
Para usar un dispositivo SBD que usa un servidor de destino iSCSI para la barrera, siga las instrucciones de las secciones siguientes.
Configuración del servidor de destino iSCSI
En primer lugar, debe crear las máquinas virtuales de destino iSCSI. Puede compartir servidores de destino iSCSI con varios clústeres de Pacemaker.
Implemente máquinas virtuales que se ejecuten en la versión compatible del sistema operativo RHEL y conéctese a ellas a través de SSH. Las máquinas virtuales no tienen que tener un tamaño grande. Los tamaños de máquina virtual, como Standard_E2s_v3 o Standard_D2s_v3, son suficientes. Asegúrese de usar almacenamiento Premium en el disco del sistema operativo.
No es necesario usar RHEL para SAP con HA y Update Services, ni RHEL para la imagen del sistema operativo sap Apps para el servidor de destino iSCSI. En su lugar, se puede usar una imagen estándar del sistema operativo RHEL. Sin embargo, tenga en cuenta que el ciclo de vida de soporte varía entre las distintas versiones del producto del sistema operativo.
Ejecute los siguientes comandos en todas las máquinas virtuales de destino iSCSI.
Actualice RHEL.
sudo yum -y updateNota:
Es posible que tenga que reiniciar el nodo después de actualizar o actualizar el sistema operativo.
Instale el paquete de destino iSCSI.
sudo yum install targetcliInicie y configure el destino para que se inicie en tiempo de arranque.
sudo systemctl start target sudo systemctl enable targetAbrir el puerto
3260en el firewallsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Creación de un dispositivo iSCSI en el servidor de destino iSCSI
Para crear los discos iSCSI para los clústeres del sistema SAP, ejecute los siguientes comandos en cada máquina virtual de destino iSCSI. En el ejemplo se muestra la creación de dispositivos SBD para varios clústeres que muestran el uso de un único servidor de destino iSCSI para varios clústeres. El dispositivo SBD está configurado en el disco del sistema operativo, por lo que debe asegurarse de que hay suficiente espacio.
- ascsnw1: representa el clúster asCS/ERS de NW1.
- dbhn1: representa el clúster de base de datos de HN1.
- sap-cl1 y sap-cl2: nombres de host de los nodos de clúster asCS/ERS de NW1.
- hn1-db-0 y hn1-db-1: nombres de host de los nodos del clúster de base de datos.
En las instrucciones siguientes, modifique el comando con sus nombres de host y SID específicos según sea necesario.
Cree la carpeta raíz para todos los dispositivos SBD.
sudo mkdir /sbdCree el dispositivo SBD para los servidores ASCS/ERS del sistema NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Cree el dispositivo SBD para el clúster de base de datos del HN1 del sistema.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Guarde la configuración de targetcli.
sudo targetcli saveconfigComprobación para asegurarse de que todo se configuró correctamente
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Configuración del dispositivo SBD del servidor de destino iSCSI
[A]: se aplica a todos los nodos. [1]: se aplica solo al nodo 1. [2]: Se aplica solo al nodo 2.
En los nodos del clúster, conecte y detecte el dispositivo iSCSI que se creó en la sección anterior. Ejecute los siguientes comandos en los nodos del clúster nuevo que desea crear.
[A] Instale o actualice las utilidades del iniciador iSCSI en todos los nodos del clúster.
sudo yum install -y iscsi-initiator-utils[A] Instale paquetes de clúster y SBD en todos los nodos del clúster.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Habilite el servicio iSCSI.
sudo systemctl enable iscsid iscsi[1] Cambie el nombre del iniciador en el primer nodo del clúster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Cambie el nombre del iniciador en el segundo nodo del clúster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Reiniciar el servicio iSCSI para aplicar los cambios.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Conecte los dispositivos iSCSI. En el ejemplo siguiente, 10.0.0.17 es la dirección IP del servidor de destino iSCSI y 3260 es el puerto predeterminado. El nombre
iqn.2006-04.ascsnw1.local:ascsnw1de destino se muestra al ejecutar el primer comandoiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Si usa varios dispositivos SBD, también se conecta al segundo servidor de destino iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Si usa varios dispositivos SBD, también se conecta al tercer servidor de destino iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Asegúrese de que los dispositivos iSCSI están disponibles y anote el nombre del dispositivo. En el ejemplo siguiente, se detectan tres dispositivos iSCSI conectando el nodo a tres servidores de destino iSCSI.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Recupere los identificadores de los dispositivos iSCSI.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgEl comando presenta tres identificadores de dispositivo para cada dispositivo SBD. Se recomienda usar el identificador que empieza por scsi-3. En el ejemplo anterior, los identificadores son:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Cree el dispositivo SBD.
Use el identificador de dispositivo de los dispositivos iSCSI para crear dispositivos SBD en el primer nodo del clúster.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createCree también el segundo y tercer dispositivo SBD si desea usar más de uno.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Adaptar la configuración de SBD
Abra el archivo de configuración de SBD.
sudo vi /etc/sysconfig/sbdCambie la propiedad del dispositivo SBD, habilite la integración de Pacemaker y cambie el modo de inicio del SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Ejecutar el siguiente comando para cargar el módulo
softdog.modprobe softdog[A] Ejecute el siguiente comando para asegurarse de que
softdogse carga automáticamente después de reiniciar un nodo.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] El valor de tiempo de espera del servicio SBD se establece en 90 s de forma predeterminada. Sin embargo, si el
SBD_DELAY_STARTvalor se establece enyes, el servicio SBD retrasará su inicio hasta después delmsgwaittiempo de espera. Por lo tanto, el valor de tiempo de espera del servicio SBD debe superar elmsgwaittiempo de espera cuandoSBD_DELAY_STARTestá habilitado.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
SBD con un disco compartido de Azure
Esta sección solo se aplica si desea usar un dispositivo SBD con un disco compartido de Azure.
Configuración del disco compartido de Azure con PowerShell
Para crear y conectar un disco compartido de Azure con PowerShell, ejecute las instrucciones siguientes. Si desea implementar recursos mediante la CLI de Azure o Azure Portal, también puede consultar el documento Implementación de un disco ZRS.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Configuración del dispositivo SBD de disco compartido de Azure
[A] Instale paquetes de clúster y SBD en todos los nodos del clúster.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Asegúrese de que el disco conectado esté disponible.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Recupere el identificador de dispositivo del disco compartido conectado.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaIdentificador de dispositivo de lista de comandos para el disco compartido conectado. Se recomienda usar el identificador que empieza por scsi-3. En este ejemplo, el identificador es /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Creación del dispositivo SBD
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Adaptar la configuración de SBD
Abra el archivo de configuración de SBD.
sudo vi /etc/sysconfig/sbdCambiar la propiedad del dispositivo SBD, habilitar la integración de pacemaker y cambiar el modo de inicio de SBD
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Ejecutar el siguiente comando para cargar el módulo
softdog.modprobe softdog[A] Ejecute el siguiente comando para asegurarse de que
softdogse carga automáticamente después de reiniciar un nodo.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] El valor de tiempo de espera del servicio SBD se establece en 90 segundos de forma predeterminada. Sin embargo, si el
SBD_DELAY_STARTvalor se establece enyes, el servicio SBD retrasará su inicio hasta después delmsgwaittiempo de espera. Por lo tanto, el valor de tiempo de espera del servicio SBD debe superar elmsgwaittiempo de espera cuandoSBD_DELAY_STARTestá habilitado.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Configuración del agente de barrera de Azure
El dispositivo de barrera usa una identidad administrada para el recurso de Azure o una entidad de servicio para la autorización frente a Azure. Según el método de administración de identidades, siga los procedimientos adecuados:
Configuración de la administración de identidades
Use la identidad administrada o la entidad de servicio.
Para crear una identidad administrada (MSI), cree una identidad administrada asignada por el sistema para cada máquina virtual del clúster. Si ya existe una identidad administrada asignada por el sistema, se usaría. No use identidades administradas asignadas por el usuario con Pacemaker en este momento. Un dispositivo de barrera, basado en la identidad administrada, se admite en RHEL 7.9 y RHEL 8.x/RHEL 9.x.
Creación de un rol personalizado para el agente de barrera
De forma predeterminada, ni la identidad administrada ni la entidad de servicio tienen permisos para acceder a los recursos de Azure. Debe conceder permisos a la identidad administrada o a la entidad de servicio para iniciar y detener (desasignar) todas las máquinas virtuales del clúster. Si no ha creado aún el rol personalizado, puede crearlo mediante PowerShell o la CLI de Azure.
Utilice el siguiente contenido para el archivo de entrada. Debe adaptar el contenido a las suscripciones, es decir, reemplazar
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxyyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyypor los identificadores de la suscripción. Si solo tiene una suscripción, quite la segunda entrada enAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Asignación del rol personalizado
Use la identidad administrada o la entidad de servicio.
Asigne el rol personalizado
Linux Fence Agent Roleque se creó en la última sección para cada identidad administrada de las máquinas virtuales del clúster. Cada identidad administrada asignada por el sistema de la máquina virtual necesita el rol asignado para cada recurso de máquina virtual del clúster. Para más información, consulte Asignación de acceso de una identidad administrada a un recurso mediante Azure Portal. Compruebe que la asignación de roles de identidad administrada de cada máquina virtual contiene todas las máquinas virtuales del clúster.Importante
Tenga en cuenta que la asignación y eliminación de la autorización con identidades administradas se puede retrasar hasta que sea efectiva.
Instalación del clúster
Las diferencias en los comandos o la configuración entre RHEL 7 y RHEL 8/RHEL 9 se marcan en el documento.
[A] Instalación del complemento de alta disponibilidad de RHEL.
sudo yum install -y pcs pacemaker nmap-ncat[A] En RHEL 9.x, instale los agentes de recursos para la implementación en la nube.
sudo yum install -y resource-agents-cloud[A] Instale el paquete de agentes de barrera si usa un dispositivo de barrera basado en el agente de barrera de Azure.
sudo yum install -y fence-agents-azure-armImportante
Se recomiendan las siguientes versiones del agente de barrera de Azure (o posterior) para los clientes que deseen usar identidades administradas para recursos de Azure en lugar de nombres de entidad de seguridad de servicio para el agente de barrera:
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Importante
En RHEL 9, se recomiendan las siguientes versiones de paquete (o posteriores) para evitar problemas con el agente de barrera de Azure:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Compruebe la versión del agente de delimitación de Azure. Si es necesario, actualícelo a la versión mínima requerida o posterior.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armImportante
Si necesita actualizar el agente de barrera de Azure y, si usa un rol personalizado, asegúrese de actualizar el rol personalizado para incluir la acción powerOff. Para obtener más información, consulte Creación de un rol personalizado para el agente de barrera.
[A] Configure la resolución de nombres de host.
Puede usar un servidor DNS o modificar el archivo
/etc/hostsen todos los nodos. En este ejemplo se muestra cómo utilizar el archivo/etc/hosts. Reemplace la dirección IP y el nombre de host en los siguientes comandos.Importante
Si usa nombres de host en la configuración del clúster, es esencial tener una resolución de nombre de host confiable. Se producirá un error si los nombres no están disponibles, lo que puede provocar retrasos en la conmutación por error del clúster.
La ventaja de usar
/etc/hostses que el clúster es independiente de DNS, lo que también podría representar un único punto de error.sudo vi /etc/hostsInserte las líneas siguientes en
/etc/hosts. Cambie la dirección IP y el nombre de host para que coincidan con su entorno.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Cambie la contraseña de
haclustera la misma contraseña.sudo passwd hacluster[A] Adición de reglas de firewall para Pacemaker.
Agregue las siguientes reglas de firewall para todas las comunicaciones entre los nodos del clúster.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Habilitación de los servicios básicos del clúster.
Ejecute los comandos siguientes para habilitar el servicio de Pacemaker e inícielo.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Creación de un clúster de Pacemaker.
Ejecute los comandos siguientes para autenticar los nodos y crear el clúster. Establezca el token en 30000 para permitir el mantenimiento con conservación de memoria. Para más información, consulte este artículo para Linux.
Si va a compilar un clúster en RHEL 7.x, use los comandos siguientes:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allSi va a compilar un clúster en RHEL 8.x/RHEL 9.x, use los comandos siguientes:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allCompruebe el estado de clúster con el comando siguiente:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Establecimiento de votos esperados.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Sugerencia
Si crea un clúster de varios nodos, es decir, un clúster con más de dos nodos, no establezca los votos en 2.
[1] Permitir acciones de barrera simultáneas.
sudo pcs property set concurrent-fencing=true
Creación de un dispositivo de barrera en un clúster de Pacemaker
Sugerencia
- Para evitar carreras de barrera dentro de un clúster de Pacemaker de dos nodos, puede configurar la propiedad adicional del clúster
priority-fencing-delay. Esta propiedad introduce un retraso adicional en la limitación de un nodo que tiene una prioridad de recurso total mayor cuando se produce un escenario de cerebro dividido. Para más información, consulte ¿Puede Pacemaker cercar el nodo de clúster con los recursos en ejecución más pequeños?. - La propiedad
priority-fencing-delayes aplicable a la versión 2.0.4-6.el8 de Pacemaker o posterior, y en un clúster de dos nodos. Si configura la propiedad de clústerpriority-fencing-delay, no es necesario establecer la propiedadpcmk_delay_max. Pero si la versión de Pacemaker es inferior a la 2.0.4-6.el8, debe establecer la propiedadpcmk_delay_max. - Para obtener instrucciones sobre cómo establecer la propiedad de clúster
priority-fencing-delay, consulte los documentos de alta disponibilidad de escalado vertical de SAP ASCS/ERS y SAP HANA correspondientes.
En función del mecanismo de barrera seleccionado, siga solo una sección para obtener instrucciones pertinentes: SBD como dispositivo de barrera o agente de barrera de Azure como dispositivo de barrera.
SBD como dispositivo de barrera
[A] Habilitación del servicio SBD
sudo systemctl enable sbd[1] Para el dispositivo SBD configurado mediante servidores de destino iSCSI o disco compartido Azure, ejecute los siguientes comandos.
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Reiniciar el clúster
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allNota:
Si se produce el siguiente error al iniciar el clúster de pacemaker, puede ignorar el mensaje. Como alternativa, puede iniciar el clúster mediante el comando
pcs cluster start --all --request-timeout 140.Error: no se pueden iniciar todos los nodos node1/node2: No se puede conectar a node1/node2, compruebe si pcsd se está ejecutando allí o intente establecer un tiempo de espera superior con
--request-timeoutla opción (Operación agota el tiempo de espera después de 60000 milisegundos con 0 bytes recibidos)
Agente de barrera de Azure como dispositivo de barrera
[1] Después de asignar roles a ambos nodos de clúster, puede configurar los dispositivos de barrera en el clúster.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Ejecute el comando adecuado en función de si usa una identidad administrada o una entidad de servicio para el agente de barrera de Azure.
Nota:
La opción
pcmk_host_mapsolo es necesaria en el comando si los nombres de host RHEL y los nombres de VM de Azure no son idénticos. Especifique la asignación en el formato hostname:nombre-VM.Consulte la sección en negrita en el comando. Para obtener más información, consulte el artículo sobre el formato que se debe usar para especificar las asignaciones de nodo en los dispositivos de barrera en pcmk_host_map.
Para configurar el dispositivo de barrera en RHEL 7.X, use el comando siguiente:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600Para configurar el dispositivo de barrera en RHEL 8.x/9.x, use el comando siguiente:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
Si usa un dispositivo de barrera, según la configuración de la entidad de servicio, lea Cambio de SPN a MSI para clústeres de Pacemaker mediante barreras de Azure y aprenda a realizar la conversión a la configuración de identidad administrada.
Las operaciones de supervisión y barrera se deserializan. Como resultado, si hay una operación de supervisión más larga y un evento de barrera simultánea, no habrá ningún retraso en la conmutación por error del clúster porque la operación de supervisión ya se está ejecutando.
Sugerencia
El agente de barrera de Azure requiere conectividad saliente a puntos de conexión públicos. Para obtener más información junto con las posibles soluciones, consulte Conectividad del punto de conexión público para las máquinas virtuales que usan el ILB estándar.
Configuración de Pacemaker para eventos programados de Azure
Azure ofrece eventos programados. Los eventos programados se envían a través del servicio de metadatos y dan tiempo a la aplicación para prepararse para dichos eventos.
El agente de recursos de Pacemaker azure-events-az supervisa los eventos programados de Azure. Si se detectan eventos y el agente de recursos determina que hay otro nodo de clúster disponible, se establece un atributo de mantenimiento del clúster.
Cuando el atributo de mantenimiento del clúster se establece para un nodo, se desencadena la restricción de ubicación y todos los recursos cuyo nombre no comience por health- se migran fuera del nodo con evento programado. Una vez que el nodo de clúster afectado queda libre de ejecutar recursos de clúster, se confirma el evento programado y puede ejecutar su acción, como reiniciar.
[A] Asegúrese de que el paquete del agente de
azure-events-azya está instalado y actualizado.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudRequisitos mínimos de versión:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 y versiones más recientes:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Configure los recursos en Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Establezca la estrategia y la restricción de los nodos de mantenimiento del clúster de Pacemaker.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Importante
No defina ningún otro recurso del clúster que empiece por
health-, aparte de los recursos descritos en los pasos siguientes.[1] Establezca el valor inicial de los atributos del clúster. Ejecútelo para cada nodo de clúster y para entornos de escalabilidad horizontal que incluyan la máquina virtual para lograr la mayoría.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configure los recursos en Pacemaker. Asegúrese de que los recursos empiezan por
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true failure-timeout=120sSacar el clúster de Pacemaker del modo de mantenimiento.
sudo pcs property set maintenance-mode=falseBorre los posibles errores durante la habilitación y compruebe que los recursos
health-azure-eventsse han iniciado correctamente en todos los nodos del clúster.sudo pcs resource cleanupLa primera vez, la ejecución de consultas para eventos programados puede tardar hasta dos minutos. Las pruebas de Pacemaker con eventos programados pueden usar acciones de reinicio o reimplementación para las máquinas virtuales del clúster. Para obtener más información, consulte Eventos programados.
Configuración de barreras opcionales
Sugerencia
Esta sección solo es aplicable si se desea configurar el dispositivo de barrera especial para fence_kdump.
Si es necesario recopilar información de diagnóstico dentro de la máquina virtual, puede ser útil configurar otro dispositivo de barrera basado en el agente de barrera fence_kdump. El agente fence_kdump puede detectar que un nodo ha entrado en la recuperación de bloqueos de kdump y puede permitir que se complete el servicio de recuperación de bloqueos antes de que se invoque a otros métodos de barrera. Tenga en cuenta que fence_kdump no es un reemplazo de los mecanismos de barrera tradicionales, como SBD o el agente de barrera de Azure, cuando se usan máquinas virtuales de Azure.
Importante
Tenga en cuenta que cuando fence_kdump se configura como un dispositivo de barrera de primer nivel, introduce retrasos en las operaciones de barrera y, respectivamente, retrasos en la conmutación por error de los recursos de la aplicación.
Si se detecta correctamente un volcado de memoria, la creación de barreras se retrasará hasta que se complete el servicio de recuperación de bloqueos. Si no se puede acceder al nodo con errores o este no responde, la creación de barreras se retrasará según el tiempo determinado, el número configurado de iteraciones y el tiempo de espera de fence_kdump. Para obtener más información, consulte Configuración de fence_kdump en un clúster de Pacemaker de Red Hat.
Es posible que el tiempo de espera propuesto de fence_kdump deba adaptarse al entorno específico.
Se recomienda configurar fence_kdump barrera solo cuando sea necesario para recopilar diagnósticos dentro de la máquina virtual y siempre en combinación con métodos de barrera tradicionales, como SBD o agente de barrera de Azure.
Los siguientes artículos de KB de Red Hat contienen información importante sobre la configuración de la barrera fence_kdump:
- Consulte Configuración de fence_kdump en un clúster de Pacemaker de Red Hat.
- Consulte Cómo configurar y administrar niveles de barrera en un clúster de RHEL con Pacemaker.
- Consulte Error de fence_kdump con el mensaje "tiempo de espera después de X segundos" en un clúster de alta disponibilidad de RHEL 6 o 7 con una versión de kexec-tools anterior a la versión 2.0.14.
- Para obtener información sobre cómo cambiar el tiempo de espera predeterminado, consulte Configuración de kdump para su uso con el complemento de alta disponibilidad de RHEL 6, 7 y 8.
- Para obtener información sobre cómo reducir el retraso de la conmutación por error al usar
fence_kdump, consulte ¿Puedo reducir el retraso esperado de la conmutación por error al agregar la configuración de fence_kdump?
Ejecute los siguientes pasos opcionales para agregar fence_kdump como una configuración de barrera de primer nivel, además de la configuración del agente de barrera de Azure.
[A] Compruebe que
kdumpesté activo y configurado.systemctl is-active kdump # Expected result # active[A] Instale el agente de barrera
fence_kdump.yum install fence-agents-kdump[1] Cree un dispositivo de barrera
fence_kdumpen el clúster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configure los niveles de barrera de modo que el mecanismo de barrera
fence_kdumpse establezca primero.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Permita los puertos necesarios para
fence_kdumpen el firewall.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Realice la configuración de
fence_kdump_nodesen el archivo/etc/kdump.confpara evitar quefence_kdumpgenere errores de tiempo de espera para algunas versiones dekexec-tools. Para obtener más información, consulte Error de tiempo de espera de fence_kdump cuando no se especifica fence_kdump_nodes con la versión 2.0.15 o posterior de kexec-tools y Error de fence_kdump con el mensaje "tiempo de espera después de X segundos" en un clúster de alta disponibilidad de RHEL 6 o 7 con versiones de kexec-tools anteriores a la versión 2.0.14. La configuración de ejemplo para un clúster de dos nodos se muestra aquí. Después de realizar un cambio en el archivo/etc/kdump.conf, se debe regenerar la imagen de kdump. Para regenerarla, reinicie el serviciokdump.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Asegúrese de que el archivo de imagen
initramfscontenga los archivosfence_kdumpyhosts. Para obtener más información, consulte Configuración de fence_kdump en un clúster de Pacemaker de Red Hat.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendPruebe la configuración bloqueando un nodo. Para obtener más información, consulte Configuración de fence_kdump en un clúster de Pacemaker de Red Hat.
Importante
Si el clúster ya está en uso productivo, planee la prueba en consecuencia, ya que bloquear un nodo tendrá un impacto en la aplicación.
echo c > /proc/sysrq-trigger
Pasos siguientes
- Consulte Planeamiento e implementación de Azure Virtual Machines para SAP.
- Consulte Implementación de Azure Virtual Machines para SAP.
- Consulte Implementación de DBMS de Azure Virtual Machines para SAP.
- Para obtener más información sobre cómo establecer la alta disponibilidad y planear la recuperación ante desastres de SAP HANA en VM de Azure, consulte Alta disponibilidad de SAP HANA en Azure Virtual Machines.
Comentarios
Proximamente: Ao longo de 2024, retiraremos gradualmente GitHub Issues como mecanismo de comentarios sobre o contido e substituirémolo por un novo sistema de comentarios. Para obter máis información, consulte: https://aka.ms/ContentUserFeedback.
Enviar e ver os comentarios