Integración de Azure Stream Analytics con Azure Machine Learning
Puede implementar modelos de Machine Learning como funciones definidas por el usuario en los trabajos de Azure Stream Analytics para realizar predicciones y puntuaciones en tiempo real a partir de los datos de entrada de streaming. Azure Machine Learning le permite usar cualquier herramienta de código abierto popular (como TensorFlow, scikit-learn o PyTorch) para preparar, entrenar e implementar modelos.
Prerrequisitos
Siga los pasos que se indican a continuación antes de agregar un modelo de Machine Learning como función a su trabajo de Stream Analytics:
Use Azure Machine Learning para implementar el modelo como servicio web.
El punto de conexión de aprendizaje automático debe tener un swagger asociado que ayuda a Stream Analytics a conocer que el esquema de la entrada y salida. Puede usar este ejemplo de definición de Swagger como referencia para asegurarse de que la ha configurado correctamente.
Asegúrese de que el servicio web acepta y devuelve datos serializados de JSON.
Implemente el modelo en Azure Kubernetes Service para implementaciones de producción a gran escala. Si el servicio web no es capaz de controlar el número de solicitudes procedentes del trabajo, se reducirá el rendimiento del trabajo de Stream Analytics, lo que afectará a la latencia. Los modelos implementados en Azure Container Instances solo se admiten cuando se usa Azure Portal.
Incorporación de un modelo de Machine Learning en el trabajo
Puede agregar funciones de Azure Machine Learning a su trabajo de Stream Analytics directamente desde Azure Portal o Visual Studio Code.
Azure portal
Vaya al trabajo de Stream Analytics en Azure Portal y seleccione Funciones en Topología de trabajo. A continuación, seleccione Azure Machine Learning Service en el menú desplegable + Agregar.

Rellene el formulario Función de Azure Machine Learning Service con los siguientes valores de propiedad:
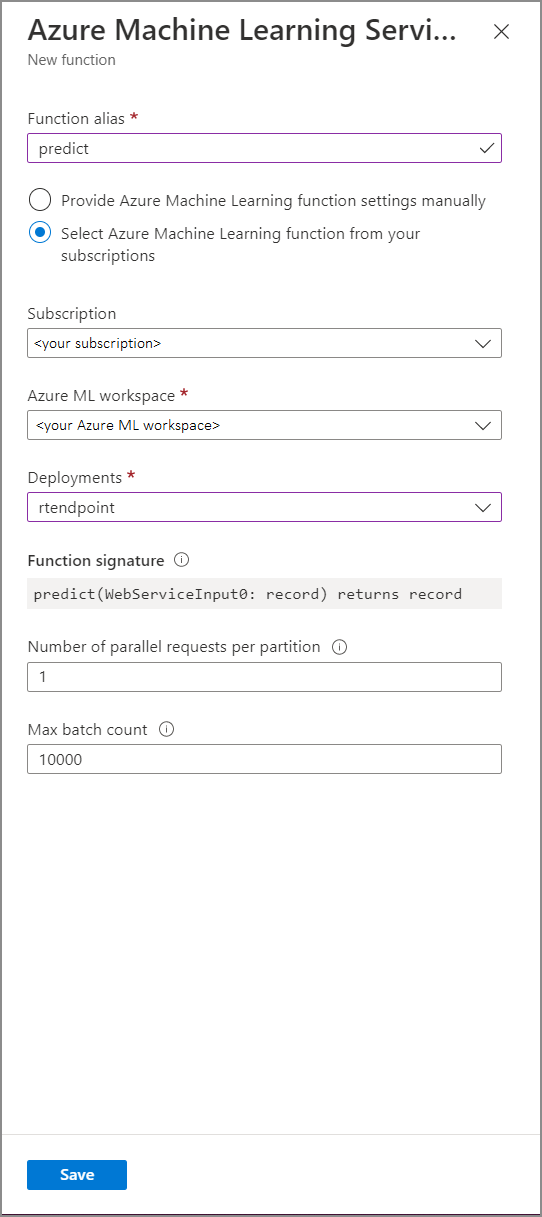
En la tabla siguiente se describe cada una de las propiedades de las funciones de Azure Machine Learning Service en Stream Analytics.
| Propiedad. | Descripción |
|---|---|
| Alias de función | Escriba un nombre para invocar la función en la consulta. |
| Suscripción | Su suscripción de Azure. |
| Área de trabajo de Azure Machine Learning | Área de trabajo de Azure Machine Learning que usó para implementar el modelo como servicio web. |
| Punto de conexión | Servicio web que hospeda el modelo. |
| Signatura de función | Firma del servicio web que se deduce a partir de la especificación del esquema de la API. Si no se puede cargar la firma, compruebe que ha proporcionado entradas y salidas de ejemplo en el script de puntuación para generar el esquema automáticamente. |
| Número de solicitudes paralelas por partición | Se trata de una configuración avanzada para optimizar el rendimiento a gran escala. Este número representa las solicitudes simultáneas enviadas desde cada partición del trabajo al servicio web. Los trabajos con seis unidades de streaming (SU) o menos tienen una partición. Los trabajos con 12 SU tienen dos particiones, los de 18 SU tienen tres particiones y así sucesivamente. Por ejemplo, si el trabajo tiene dos particiones y establece este parámetro en cuatro, habrá ocho solicitudes simultáneas del trabajo al servicio web. |
| Número máximo de lotes | Se trata de una configuración avanzada para la optimización del rendimiento a gran escala. Este número representa el número máximo de eventos que se van a procesar por lotes en una única solicitud enviada al servicio web. |
Llamada a un punto de conexión de aprendizaje automático desde una consulta
Cuando la consulta de Stream Analytics invoca una función definida por el usuario de Azure Machine Learning, el trabajo crea una solicitud serializada de JSON para el servicio web. La solicitud se basa en un esquema específico del modelo que Stream Analytics infiere del swagger del punto de conexión.
Advertencia
No se llama a los puntos de conexión de Machine Learning cuando se prueban con el editor de consultas de Azure Portal porque el trabajo no se está ejecutando. Para probar la llamada al punto de conexión desde el portal, el trabajo de Stream Analytics debe ejecutarse.
La siguiente consulta de Stream Analytics es un ejemplo de cómo invocar una función definida por el usuario de Azure Machine Learning:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Si los datos de entrada enviados a la UDF de ML son incoherentes con el esquema esperado, el punto de conexión devolverá una respuesta con el código de error 400, lo que hará que el trabajo de Stream Analytics llegue a un estado de error. Se recomienda habilitar los registros de recursos para el trabajo, lo que le permitirá depurar y solucionar estos problemas fácilmente. Por lo tanto, se recomienda encarecidamente que:
- Compruebe que la entrada a la UDF de ML no es NULL.
- Valide el tipo de cada campo que sea una entrada a la UDF de ML para asegurarse de que coincide con lo que espera el punto de conexión.
Nota
Las UDF de ML se evalúan para cada fila de un paso de consulta determinado, incluso cuando se las llama mediante una expresión condicional (por ejemplo, CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Si es necesario, use la cláusula WITH para crear rutas de acceso divergentes, llamando a la UDF de ML solo cuando sea necesario, antes de usar UNION para combinar las rutas de acceso de nuevo.
Pasar varios parámetros de entrada a la función definida por el usuario
Los ejemplos más comunes de entradas para los modelos de aprendizaje automático son los DataFrames y las matrices de NumPy. Puede crear una matriz mediante una función definida por el usuario de JavaScript; también puede crear un DataFrame serializado con JSON mediante la cláusula WITH.
Creación de una matriz de entradas
Puede crear una función definida por el usuario de JavaScript que acepte un número N de entradas y cree una matriz que se puede usar como entrada para la función definida por el usuario de Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Una vez que haya agregado la función definida por el usuario de JavaScript a su trabajo, puede invocar la función definida por el usuario de Azure Machine Learning mediante la siguiente consulta:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
El siguiente código JSON es una solicitud de ejemplo:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Creación de un DataFrame de Pandas o PySpark
Puede usar la cláusula WITH para crear un DataFrame serializado de JSON que se pueda pasar como entrada para la función definida por el usuario de Azure Machine Learning, tal como se muestra a continuación.
La siguiente consulta crea un DataFrame al seleccionar los campos necesarios y usa dicho DataFrame como entrada para la función definida por el usuario de Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
El siguiente código JSON es una solicitud de ejemplo de la consulta anterior:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Optimización del rendimiento de las funciones definidas por el usuario de Azure Machine Learning
Al implementar el modelo en Azure Kubernetes Service, puede generar un perfil de modelo para determinar el uso de los recursos. También puede habilitar App Insights para sus implementaciones. De este modo, aprenderá sobre las tasas de solicitudes, los tiempos de respuesta y las tasas de error.
Si tiene un escenario con un alto procesamiento de eventos, quizá necesite cambiar los siguientes parámetros en Stream Analytics para lograr un rendimiento óptimo con latencias bajas de un extremo a otro:
- Número máximo de lotes.
- Número de solicitudes paralelas por partición.
Determinación del tamaño de lote adecuado
Una vez que haya implementado el servicio web, envíe una solicitud de ejemplo con distintos tamaños de lote a partir de 50 y aumente la cifra en grupos de cien. Por ejemplo, 200, 500, 1000, 2000, etc. Verá que, después de un tamaño de lote determinado, aumentará la latencia de la respuesta. El punto en el que la latencia de la respuesta aumente debe indicar el número máximo de lotes para el trabajo.
Definición del número de solicitudes paralelas por partición
En condiciones de escalado óptimas, el trabajo de Stream Analytics debe ser capaz de enviar varias solicitudes paralelas al servicio web y obtener una respuesta en unos pocos milisegundos. La latencia de la respuesta del servicio web puede afectar de forma directa a la latencia y el rendimiento del trabajo de Stream Analytics. Si la llamada del trabajo al servicio web tarda mucho tiempo, probablemente notará un aumento en el retraso de la marca de agua, además de un aumento en el número de eventos de entrada pendientes.
Para lograr una latencia baja, asegúrese de que el clúster de Azure Kubernetes Service (AKS) se aprovisionó con el número correcto de nodos y réplicas. Es fundamental que el servicio web tenga alta disponibilidad y devuelva respuestas correctas. Si el trabajo recibe un error que se puede reintentar, como la respuesta de servicio no disponible (503), se reintentará automáticamente con retroceso exponencial. Si el trabajo recibe uno de estos errores como respuesta del punto de conexión, el trabajo pasará a un estado de error.
- Solicitud incorrecta (400)
- Conflicto (409)
- No encontrado (404)
- No autorizado (401)
Limitaciones
Si usa un servicio de punto de conexión administrado por Azure ML, Stream Analytics solo podrá acceder a los puntos de conexión que tengan habilitado el acceso a la red pública. Obtenga más información al respecto en la página relativa a los puntos de conexión privados de Azure ML.