Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Azure Stream Analytics puede generar datos en formato JSON para Azure Cosmos DB. Habilita el archivado de datos y las consultas de baja latencia en datos JSON no estructurados. En este artículo se describen algunos procedimientos recomendados para implementar esta configuración (Stream Analytics en Cosmos DB). Si no está familiarizado con Azure Cosmos DB, consulte la documentación de Azure Cosmos DB para comenzar.
Nota:
- En este momento, Stream Analytics solo admite la conexión a Azure Cosmos DB mediante la API de SQL. Todavía no se admiten otras API de Azure Cosmos DB. Si apunta Stream Analytics a las cuentas de Azure Cosmos DB creadas con otras API, puede que los datos no se almacenen correctamente.
- Se recomienda establecer el trabajo en el nivel de compatibilidad 1.2 al usar Azure Cosmos DB como salida.
Aspectos básicos de Azure Cosmos DB como destino de salida
La salida de Azure Cosmos DB de Stream Analytics permite escribir los resultados del procesamiento de secuencias como una salida JSON en los contenedores de Azure Cosmos DB. Stream Analytics no crea contenedores en la base de datos. En su lugar, debe crearlos por adelantado. A continuación, puede controlar los costos de facturación de los contenedores de Azure Cosmos DB. También puede ajustar el rendimiento, la coherencia y la capacidad de los contenedores directamente mediante las API de Azure Cosmos DB. En las secciones siguientes se detallan algunas de las opciones de contenedores de Azure Cosmos DB.
Ajuste de la coherencia, la disponibilidad y la latencia
Para satisfacer las necesidades de su aplicación, Azure Cosmos DB permite optimizar la base de datos y los contenedores y buscar el equilibrio entre coherencia, disponibilidad, latencia y rendimiento.
En función de los niveles de coherencia de lectura que requiera su situación contra la latencia de lectura y escritura, puede elegir un nivel de coherencia en su cuenta de base de datos. Se puede mejorar el rendimiento al escalar las Request Units (RUs) en el contenedor. También de forma predeterminada, Azure Cosmos DB permite la indexación sincrónica en cada operación CRUD del contenedor. Esta es otra opción útil para controlar el rendimiento de escritura y lectura en Azure Cosmos DB. Para obtener más información, revise el artículo sobre el cambio de los niveles de coherencia de bases de datos y consultas.
Upserts de Stream Analytics
La integración de Stream Analytics en Azure Cosmos DB permite insertar o actualizar registros en su contenedor en función de una columna de identificador de documento determinada. Esta operación también se denomina upsert. Stream Analytics usa un enfoque de upsert optimista. Las actualizaciones solo tienen lugar cuando se produce un error de inserción con un conflicto de id. de documento.
Con el nivel de compatibilidad 1.0, Stream Analytics realiza esta actualización como una operación de revisión, por lo que permite actualizaciones parciales en el documento. Stream Analytics agrega nuevas propiedades o reemplaza una propiedad existente de forma incremental. No obstante, los cambios en los valores de las propiedades de la matriz en el documento JSON provocan que toda la matriz se sobrescriba. Es decir, la matriz no se combina.
Con la versión 1.2, el comportamiento de upsert se ha modificado para insertar o sustituir el documento. En la sección posterior sobre el nivel de compatibilidad 1.2 se describe con más detalle este comportamiento.
Si el documento JSON entrante tiene un campo de id. existente, ese campo se utiliza automáticamente como columna Id. de documento en Azure Cosmos DB. Las escrituras posteriores se administran como tal, lo que conduce a una de estas situaciones:
- Los identificadores únicos provocan una operación de inserción.
- Los identificadores duplicados y el Identificador de documento establecido en Id. provocan una operación upsert.
- Los identificadores duplicados y el Identificador de documento no establecido provocan un error después del primer documento
Si quiere guardar todos los documentos, incluidos los que tienen un identificador duplicado, cambie el nombre del campo Id. en la consulta (mediante la palabra clave AS). Permita que Azure Cosmos DB cree el campo Id. o reemplace el identificador por el valor de otra columna (mediante la palabra clave AS o la opción Id. de documento ).
Creación de particiones en Azure Cosmos DB
Azure Cosmos DB escala automáticamente las particiones según la carga de trabajo. Por lo tanto, se recomienda usar contenedores ilimitados para crear particiones de los datos. Al escribir en contenedores ilimitados, Stream Analytics usa tantos escritores paralelos como el esquema de partición de entrada o el paso de consulta anterior.
Nota:
Azure Stream Analytics solo admite contenedores ilimitados con claves de partición en el nivel superior. Por ejemplo, se admite /region. No se admiten las claves de partición anidadas (por ejemplo, /region/name).
Según la clave de partición que elija, es posible que reciba esta advertencia:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Es importante elegir una propiedad de clave de partición que tenga muchos valores distintos y que le permita distribuir la carga de trabajo uniformemente entre estos valores. Como artefacto natural de creación de particiones, las solicitudes relacionadas con la misma clave de partición están limitadas por el rendimiento máximo de una sola partición.
El tamaño de almacenamiento para los documentos que pertenecen al mismo valor de clave de partición está limitado a 20 GB (el límite del tamaño de la partición física es de 50 GB). Una clave de partición idónea es la que aparece con frecuencia como filtro en sus consultas y que tiene suficiente cardinalidad para asegurar que la solución es escalable.
No es necesario que las claves de partición empleadas para las consultas de Stream Analytics y Azure Cosmos DB sean idénticas. Las topologías totalmente paralelas recomiendan el uso de la clave de partición de entrada (PartitionId) como la clave de partición de la consulta de Stream Analytics, pero es posible que no sea la opción recomendada para la clave de partición de un contenedor de Azure Cosmos DB.
Una clave de partición es también el límite para las transacciones de los procedimientos almacenados y desencadenadores de Azure Cosmos DB. Debe elegir la clave de partición para que los documentos que ocurren juntos en las transacciones compartan el mismo valor de clave de partición. El artículo Creación de particiones en Azure Cosmos DB proporciona más detalles acerca de cómo elegir una clave de partición.
Para los contenedores de Azure Cosmos DB fijos, Stream Analytics no permite ningún escalado vertical u horizontal una vez que están completos. Tienen un límite de 10 GB y un rendimiento de 10 000 RU/s. Para migrar los datos de un contenedor fijo a un contenedor ilimitado (por ejemplo, uno con al menos 1000 RU/s y una clave de partición), use la herramienta de migración de datos o la biblioteca de fuente de cambios.
La capacidad de escribir en varios contenedores fijos se está dejando en desuso. No lo recomendamos para la ampliación del trabajo de Stream Analytics.
Rendimiento mejorado con el nivel de compatibilidad 1.2
En el nivel de compatibilidad 1.2, Stream Analytics admite la integración nativa para una escritura en bloque en Azure Cosmos DB. Esta integración permite que la escritura en Azure Cosmos DB sea eficaz, a la vez que maximiza el rendimiento y controla de forma eficaz las solicitudes de limitación.
El mecanismo de escritura mejorado está disponible en un nuevo nivel de compatibilidad, debido a una diferencia en el comportamiento de upsert. En los niveles anteriores a 1.2, upsert inserta o combina el documento. Con la versión 1.2, el comportamiento de upsert se ha modificado para insertar o sustituir el documento.
En los niveles anteriores a 1.2, Stream Analytics utiliza un procedimiento almacenado personalizado para realizar el upsert masivo de los documentos por clave de partición en Azure Cosmos DB. Allí, un lote se registra como una operación. Incluso si se produce un error transitorio (limitación) en un único registro, se debe reintentar todo el lote. Este comportamiento provoca que incluso los escenarios con una limitación razonable sean relativamente lentos.
El siguiente ejemplo muestra dos trabajos de Stream Analytics idénticos que leen la misma entrada de Azure Event Hubs. Ambos trabajos de Stream Analytics están completamente particionados con una consulta de paso y escriben en contenedores de Azure Cosmos DB idénticos. Las métricas de la izquierda corresponden al trabajo configurado con el nivel de compatibilidad 1.0. Las métricas de la derecha están configuradas con 1.2. La clave de partición de un contenedor de Azure Cosmos DB es un GUID único que procede del evento de entrada.
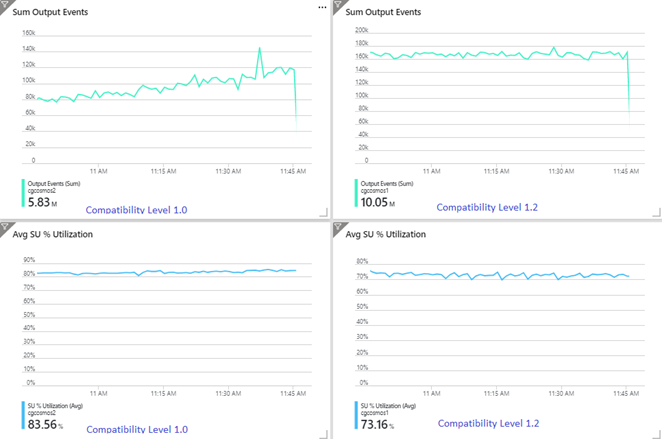
La tasa de eventos entrantes de Event Hubs es dos veces mayor que la configurada para que admitan los contenedores de Azure Cosmos DB (20 000 RU), por lo que se espera que se produzca una limitación en Azure Cosmos DB. Sin embargo, el trabajo con el nivel 1.2 escribe de forma constante con un mayor rendimiento (eventos de salida por minuto) y con un menor porcentaje medio de utilización de SU. En tu entorno, esta diferencia depende de algunos factores adicionales. Estos factores incluyen la elección del formato del evento, el tamaño de los mensajes y eventos de entrada, las claves de partición y la consulta.
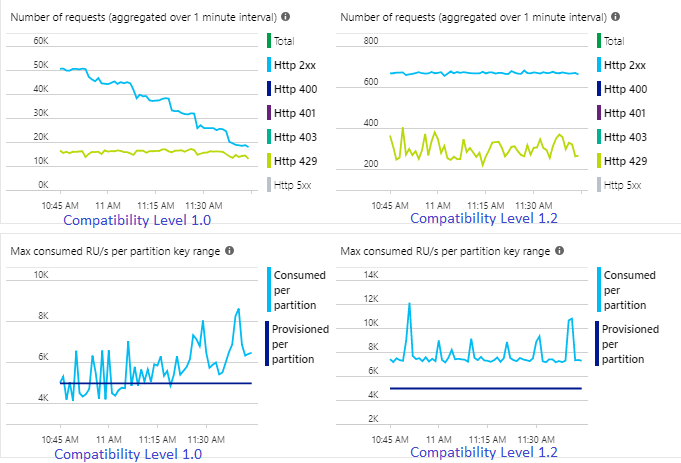
Con la versión 1.2, Stream Analytics es más inteligente al utilizar el 100 % de la capacidad de procesamiento disponible en Azure Cosmos DB, con pocas limitaciones o restricciones por velocidad. Este comportamiento proporciona una mejor experiencia para otras cargas de trabajo, como las consultas que se ejecutan en el contenedor al mismo tiempo. Si desea ver cómo Stream Analytics realiza el escalado horizontal con Azure Cosmos DB como un receptor de 1000 a 10 000 mensajes por segundo, pruebe este proyecto de ejemplo de Azure.
El rendimiento de salida de Azure Cosmos DB es idéntico con los niveles 1.0 y 1.1. Se recomienda encarecidamente que use el nivel de compatibilidad 1.2 en Stream Analytics con Azure Cosmos DB.
Configuración de Azure Cosmos DB para la salida JSON
El uso de Azure Cosmos DB como una salida en Stream Analytics genera la solicitud de información siguiente.
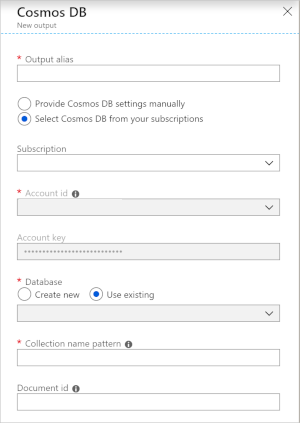
| Campo | Descripción |
|---|---|
| Alias de salida | Alias para hacer referencia a esta salida en la consulta de Stream Analytics. |
| Suscripción | Suscripción a Azure. |
| Identificador de cuenta | El nombre o el URI del punto de conexión de la cuenta de Azure Cosmos DB. |
| Clave de cuenta | La clave de acceso compartido para la cuenta de Azure Cosmos DB. |
| Base de datos | El nombre de la base de datos de Azure Cosmos DB. |
| Nombre del contenedor | Nombre del contenedor, como MyContainer. Debe existir un contenedor denominado MyContainer. |
| Id. de documento | Opcional. El nombre de la columna en los eventos de salida usado como clave única en la que deben basarse las operaciones de inserción o actualización. Si se deja vacío, se insertarán todos los eventos, sin ninguna opción de actualización. |
Una vez configurada la salida de Azure Cosmos DB, puede usarla en la consulta como destino de una instrucción INTO. Cuando se usa una salida de Azure Cosmos DB como tal, se debe establecer una clave de partición explícitamente.
El registro de salida debe contener una columna con distinción de mayúsculas y minúsculas con un nombre asignado después de la clave de partición en Azure Cosmos DB. Para lograr una mayor paralelización, la instrucción puede requerir la cláusula PARTITION BY que utilice la misma columna.
Esta es una consulta de ejemplo:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Control de errores y reintentos
En caso de un error transitorio, indisponibilidad del servicio o limitación al enviar eventos a Azure Cosmos DB, Stream Analytics reintenta de forma indefinida completar correctamente la operación. No prueba los reintentos en el caso de los errores siguientes:
- No autorizado (código de error HTTP 401)
- NotFound (código de error HTTP 404)
- Forbidden (código de error HTTP 403)
- BadRequest (código de error HTTP 400)
Problemas comunes
Se ha agregado una restricción de índice único a la colección y los datos de salida de Stream Analytics infringen esta restricción. Asegúrese de que los datos de salida de Stream Analytics no infringen las restricciones únicas o elimine las restricciones. Para más información, consulte Restricciones de clave única de Azure Cosmos DB.
La columna
PartitionKeyno existe.La columna
Idno existe.
Pasos siguientes
- Comprender los resultados de Azure Stream Analytics
- Salida de resultados de Azure Stream Analytics a la base de datos de Azure SQL
- Particionamiento de la salida de blobs personalizada en Azure Stream Analytics