Migración, ETL y carga de datos para migraciones desde Oracle
Este artículo es la segunda parte de una serie de siete partes, que proporciona instrucciones sobre cómo migrar de Oracle a Azure Synapse Analytics. El artículo se centra en los procedimientos recomendados para la migración de ETL y la carga.
Consideraciones sobre la migración de datos
Hay muchos factores que se deben tener en cuenta al migrar datos, ETL y cargas desde un almacenamiento de datos y data marts de Oracle heredados a Azure Synapse.
Decisiones iniciales sobre la migración de datos desde Oracle
Al planear una migración desde un entorno de Oracle existente, tenga en cuenta las siguientes preguntas relacionadas con los datos:
¿Deben migrarse las estructuras de tabla sin usar?
¿Cuál es el mejor enfoque de migración para minimizar el riesgo y el impacto de los usuarios?
Cuando se migran data marts, ¿siguen siendo físicos o pasan a ser virtuales?
En las secciones siguientes, se describen estos puntos en el contexto de la migración desde Oracle.
¿Migración de tablas sin usar?
Solo tiene sentido migrar las tablas que estén en uso. Las tablas que no están activas se pueden archivar en lugar de migrarlas, de modo que los datos estén disponibles si se necesitan en el futuro. Es mejor usar metadatos del sistema y archivos de registro en lugar de documentación para determinar qué tablas están en uso, ya que la documentación puede estar obsoleta.
Los registros y las tablas del catálogo del sistema de Oracle contienen información que se puede usar para determinar cuándo se accedió por última vez a una tabla determinada, lo que a su vez se puede usar para decidir si una tabla es candidata o no para la migración.
Si tiene licencias del Paquete de diagnóstico de Oracle, tiene acceso al historial de sesiones activas, que puede usar para determinar cuándo se ha accedido por última vez a una tabla.
Sugerencia
En los sistemas heredados, es habitual que las tablas se vuelvan redundantes a lo largo del tiempo; no es necesario migrarlas en la mayoría de los casos.
Esta es una consulta de ejemplo que busca el uso de una tabla específica dentro de un período de tiempo determinado:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
Esta consulta puede tardar un tiempo en ejecutarse si ha estado ejecutando numerosas consultas.
¿Cuál es el mejor enfoque de migración para minimizar el riesgo y el impacto en los usuarios?
Esta pregunta surge con frecuencia, ya que las empresas suelen querer reducir el impacto de los cambios en el modelo de datos del almacenamiento de datos para mejorar la agilidad. A menudo, las empresas ven una oportunidad para modernizar o transformar aún más sus datos durante una migración de ETL. Este enfoque conlleva un mayor riesgo, porque cambia varios factores simultáneamente, lo que dificulta la comparación de los resultados del sistema antiguo con el nuevo. Realizar cambios en el modelo de datos aquí también podría afectar a los trabajos ETL del flujo ascendente o descendente a otros sistemas. Debido a ese riesgo, es mejor modificar el diseño en esta escala después de la migración del almacenamiento de datos.
Incluso si se cambia intencionadamente un modelo de datos como parte de la migración global, es aconsejable migrar el modelo actual tal cual está a Azure Synapse, en lugar de rediseñarlo en la nueva plataforma. Este enfoque minimiza el efecto en los sistemas de producción actuales, a la vez que se beneficia del rendimiento y la escalabilidad elástica de la plataforma de Azure para tareas de rediseño puntuales.
Sugerencia
Migre el modelo existente tal cual inicialmente, incluso si se planea un cambio en el modelo de datos en el futuro.
Migración de data marts: ¿mantener el formato físico o pasar al virtual?
En entornos de almacenamiento de datos de Oracle heredados, un procedimiento común es crear varios data marts estructurados para proporcionar un buen rendimiento para las consultas e informes ad hoc de autoservicio para una función de negocio o departamento determinados dentro de una organización. Un data mart consta normalmente de un subconjunto del almacenamiento de datos y contiene versiones agregadas de los datos en un formato que permite a los usuarios consultar fácilmente esos datos con tiempos de respuesta rápidos. Los usuarios pueden utilizar herramientas de consulta fáciles de usar, como Microsoft Power BI, que admite interacciones de los usuarios empresariales con los data marts. La forma de los datos de un data mart suele ser un modelo de datos dimensional. Un uso de los data marts es exponer los datos en un formato utilizable, incluso si el modelo de datos del almacenamiento subyacente es algo distinto, como un almacén de datos.
Puede usar data marts independientes para unidades de negocio individuales dentro de una organización para implementar regímenes de seguridad de datos sólidos. Restrinja el acceso de los usuarios a los data marts específicos que les interesan y elimine, ofusque o anonimice la información confidencial.
Si estos data marts están implementados como tablas físicas, serán necesarios recursos de almacenamiento adicionales, así como procesamiento para crearlos y actualizarlos de forma periódica. Asimismo, los datos del data mart solo estarán actualizados según la última operación de actualización, por lo que puede que no sea adecuado para los paneles de datos altamente volátiles.
Sugerencia
La virtualización de data marts puede ahorrar en recursos de almacenamiento y procesamiento.
Con la llegada de arquitecturas de MPP escalables y con menor costo, como Azure Synapse, y sus características de rendimiento inherentes, puede proporcionar funcionalidad de data mart sin crear una instancia del data mart como un conjunto de tablas físicas. Un método consiste en virtualizar eficazmente los data marts mediante vistas SQL en el almacenamiento de datos principal. Otra manera es virtualizar los data marts mediante una capa de virtualización con características como vistas en Azure o productos de virtualización de terceros. Este enfoque simplifica o elimina la necesidad de almacenamiento adicional y el procesamiento de agregaciones y disminuye el número total de objetos de base de datos que se deben migrar.
Este enfoque ofrece otra ventaja potencial. Al implementar la lógica de agregación y de combinación dentro de una capa de virtualización y mostrar las herramientas de informes externas mediante una vista virtualizada, se reduce el procesamiento necesario para crear estas vistas en el almacenamiento de datos. El almacenamiento de datos suele ser el mejor lugar para ejecutar combinaciones, agregaciones y otras operaciones relacionadas en grandes volúmenes de datos.
Los principales motivos para implementar un data mart virtual en lugar de un data mart físico son:
Más agilidad, porque un data mart virtual es más fácil de cambiar que las tablas físicas y los procesos de ETL asociados.
Menor costo total de propiedad: una implementación virtualizada necesita menos almacenes y copias de datos.
Eliminación de trabajos ETL para migrar y simplificar arquitectura de almacenamiento de datos en un entorno virtualizado.
Rendimiento: aunque los data marts físicos han sido tradicionalmente más eficaces, ahora los productos de virtualización implementan técnicas de almacenamiento en caché inteligentes para mitigar esta diferencia.
Sugerencia
El rendimiento y la escalabilidad de Azure Synapse permite la virtualización sin sacrificar el rendimiento.
Migración de datos desde Oracle
Comprensión de los datos
Como parte del planeamiento de la migración, debe conocer en detalle el volumen de datos que se van a migrar, ya que puede afectar a las decisiones sobre el enfoque de migración. Use los metadatos del sistema para determinar el espacio físico que ocupan los datos sin procesar en las tablas que se van a migrar. En este contexto, el término "datos sin procesar" significa la cantidad de espacio utilizado por las filas de datos de una tabla, sin incluir sobrecargas, como los índices y la compresión. Las tablas de hechos más grandes suelen contener más del 95 % de los datos.
Esta consulta le proporcionará el tamaño total de la base de datos en Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
El tamaño de la base de datos es igual al tamaño de (data files + temp files + online/offline redo log files + control files). El tamaño total de la base de datos incluye espacio usado y espacio libre.
La consulta de ejemplo siguiente proporciona un desglose del espacio en disco usado por los datos de las tablas y los índices:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
Además, el equipo de migración de bases de datos de Microsoft proporciona muchos recursos, incluidos los Artefactos de script de inventario de Oracle. La herramienta Artefactos de script de inventario de Oracle incluye una consulta PL/SQL que accede a las tablas del sistema de Oracle y proporciona un recuento de objetos por tipo de esquema, tipo de objeto y estado. La herramienta también proporciona una estimación aproximada de los datos sin procesar de cada esquema y del dimensionamiento de las tablas de cada esquema, y almacena los resultados en formato CSV. Una hoja de cálculo de calculadora incluida toma los datos en formato CSV como entrada y proporciona datos de dimensionamiento.
Para cualquier tabla, puede calcular con precisión el volumen de datos que se deben migrar mediante la extracción de una muestra representativa de los datos, como un millón de filas, en un archivo de datos ASCII sin formato, con delimitadores y sin comprimir. A continuación, use el tamaño de ese archivo para obtener un tamaño medio de los datos sin procesar por cada fila. Por último, multiplique ese tamaño medio por el número total de filas de la tabla completa para proporcionar un tamaño de datos sin procesar para la tabla. Use ese tamaño de datos sin procesar en el planeamiento.
Uso de consultas SQL para buscar tipos de datos
Mediante una consulta a la vista DBA_TAB_COLUMNS del diccionario de datos estáticos de Oracle, puede determinar qué tipos de datos están en uso en un esquema y si se debe cambiar alguno de esos tipos de datos. Use consultas SQL para buscar las columnas de cualquier esquema de Oracle con tipos de datos que no se asignen directamente a los tipos de datos de Azure Synapse. Del mismo modo, puede usar consultas para contar el número de repeticiones de cada tipo de datos de Oracle que no se asigna directamente a Azure Synapse. Mediante el uso de los resultados de estas consultas en combinación con la tabla de comparación de tipos de datos, puede determinar qué tipos de datos se deben cambiar en un entorno de Azure Synapse.
Para buscar las columnas con tipos de datos que no se asignan a tipos de datos de Azure Synapse, ejecute la consulta siguiente después de reemplazar <owner_name> por el propietario correspondiente del esquema:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
Para contar el número de tipos de datos no asignables, use la consulta siguiente:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft ofrece SQL Server Migration Assistant (SSMA) para Oracle para automatizar la migración de los almacenes de datos desde entornos heredados de Oracle, incluida la asignación de tipos de datos. También puede usar Azure Database Migration Service para ayudar a planear y realizar una migración desde entornos como Oracle. Los proveedores de terceros también ofrecen herramientas y servicios para automatizar la migración. Si ya se utiliza una herramienta de ETL de terceros en el entorno de Oracle, puede utilizar dicha herramienta para implementar cualquier transformación de datos necesaria. En la sección siguiente, se explora la migración de los procesos de ETL existentes.
Consideraciones sobre la migración ETL
Decisiones iniciales sobre la migración de ETL de Oracle
Para el procesamiento de ETL/ELT, los almacenamientos de datos de Oracle heredados suelen usar scripts personalizados, herramientas de ETL de terceros o una combinación de enfoques que ha evolucionado con el tiempo. Cuando planee una migración a Azure Synapse, debe determinar la mejor manera de implementar el procesamiento de ETL/ELT necesario en el nuevo entorno, a la vez que minimiza el costo y el riesgo.
Sugerencia
Planee el enfoque para la migración de ETL con antelación y aproveche las instalaciones de Azure cuando corresponda.
El siguiente diagrama de flujo resume un enfoque:
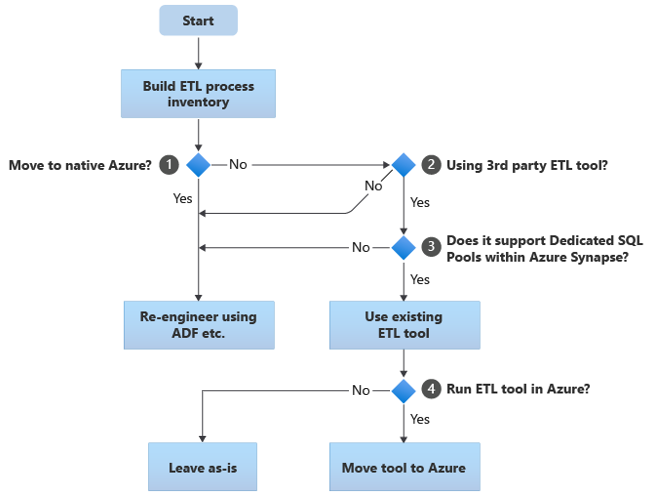
Como se muestra en el diagrama de flujo, el paso inicial siempre es crear un inventario de procesos de ETL/ELT que se deben migrar. Con las características estándar de Azure integradas, es posible que algunos procesos existentes no necesiten moverse. Para el planeamiento, es importante conocer la escala de la migración. A continuación, tenga en cuenta las preguntas del árbol de decisión del diagrama de flujo:
¿Mover a Azure nativo? La respuesta depende de si va a migrar a un entorno completamente nativo de Azure. En caso afirmativo, se recomienda volver a diseñar el procesamiento de ETL con canalizaciones y actividades de Azure Data Factory o canalizaciones de Azure Synapse.
¿Se utiliza una herramienta de ETL de terceros? Si no va a migrar a un entorno totalmente nativo de Azure, compruebe si ya se utiliza una herramienta de ETL de terceros existente. En el entorno de Oracle, es posible que encuentre que algunos o todos los procesos de ETL se realizan mediante scripts personalizados con utilidades específicas de Oracle, como Oracle SQL Developer, Oracle SQL*Loader u Oracle Data Pump. El enfoque en este caso es volver a diseñar mediante Azure Data Factory.
¿La herramienta de terceros admite grupos de SQL dedicados en Azure Synapse? Tenga en cuenta si hay una gran inversión en conocimientos sobre la herramienta de ETL de terceros o si los flujos de trabajo y las programaciones existentes usan esa herramienta. Si es así, determine si la herramienta puede admitir eficazmente Azure Synapse como un entorno de destino. Lo ideal es que la herramienta incluya conectores nativos que puedan usar las características de Azure, como PolyBase o COPY INTO, para una carga de datos más eficaz. Pero incluso sin conectores nativos, generalmente hay una manera de llamar a procesos externos, como PolyBase o
COPY INTO, y pasar los parámetros aplicables. En este caso, aproveche los conocimientos y los flujos de trabajo actuales, con Azure Synapse como el nuevo entorno de destino.Si usa Oracle Data Integrator (ODI) para el procesamiento de ELT, necesitará módulos de conocimiento de ODI para Azure Synapse. Si esos módulos no están disponibles para usted en su organización, pero tiene ODI, puede usar ODI para generar archivos planos. A continuación, esos archivos planos se pueden mover a Azure e ingerirlos en Azure Data Lake Storage para cargarlos en Azure Synapse.
¿Ejecutar las herramientas de ETL en Azure? Si decide conservar una herramienta de ETL de terceros existente, puede ejecutar esa herramienta en el entorno de Azure (en lugar de en un servidor de ETL local existente) y hacer que Azure Data Factory controle la orquestación global de los flujos de trabajo existentes. Por tanto, decida si va a dejar la herramienta existente ejecutándose tal cual o moverla al entorno de Azure para lograr ventajas de costos, rendimiento y escalabilidad.
Sugerencia
Considere la posibilidad de ejecutar las herramientas de ETL en Azure para aprovechar las ventajas de rendimiento, escalabilidad y costos.
Nuevo diseño de los scripts específicos de Oracle existentes
Si algunos o todos los procesos de ETL/ELT del almacenamiento de Oracle existentes se controlan mediante scripts personalizados que usan utilidades específicas de Oracle, como Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader u Oracle Data Pump, debe volver a codificar estos scripts para el entorno de Azure Synapse. De forma similar, si los procesos de ETL se han implementado mediante procedimientos almacenados en Oracle, debe volver a codificar esos procesos.
Algunos elementos del proceso de ETL son fáciles de migrar, por ejemplo, mediante una simple carga masiva de datos en una tabla de almacenamiento provisional desde un archivo externo. Incluso puede ser posible automatizar esas partes del proceso, por ejemplo, mediante el uso de COPY INTO de Azure Synapse o PolyBase en lugar de SQL*Loader. Otras partes del proceso que contienen SQL o procedimientos almacenados complejos arbitrarios tardarán más tiempo en volver a diseñarse.
Sugerencia
El inventario de tareas ETL que se van a migrar debe incluir scripts y procedimientos almacenados.
Una manera de probar Oracle SQL para que sea compatible con Azure Synapse es capturar algunas instrucciones SQL representativas de una combinación de las tablas v$active_session_history y v$sql de Oracle para obtener sql_text y, a continuación, anteponga EXPLAIN como prefijo de esas consultas. Suponiendo un modelo de datos migrado de forma similar en Azure Synapse, ejecute esas instrucciones EXPLAIN en Azure Synapse. Cualquier instrucción SQL incompatible devolverá un error. Puede usar esta información para determinar la escala de la tarea de recodificación.
Sugerencia
Use EXPLAIN para encontrar incompatibilidades de SQL.
En el peor de los casos, puede ser necesaria la recodificación manual. Sin embargo, hay productos y servicios disponibles de partners de Microsoft para ayudar a volver a diseñar el código específico de Oracle.
Sugerencia
Los partners ofrecen productos y conocimientos para ayudar a volver a diseñar el código específico de Oracle.
Uso de las herramientas de ETL de terceros existentes
En muchos casos, el sistema de almacenamiento de datos heredado existente ya se rellena y se mantiene con un producto de ETL de terceros. Consulte Asociados de integración de datos de Azure Synapse Analytics para obtener una lista de los partners actuales de integración de datos de Microsoft para Azure Synapse.
La comunidad de Oracle usa con frecuencia varios productos de ETL populares. En los párrafos siguientes, se describen las herramientas de ETL más populares para los almacenes de Oracle. Puede ejecutar todos esos productos en una máquina virtual en Azure y usarlos para leer y escribir archivos y bases de datos de Azure.
Sugerencia
Aproveche la inversión en herramientas de terceros existentes para reducir el costo y el riesgo.
Carga de datos desde Oracle
Opciones disponibles al cargar datos desde Oracle
Al prepararse para migrar datos desde un almacenamiento de datos de Oracle, decida cómo se moverán físicamente los datos del entorno local existente a Azure Synapse en la nube y qué herramientas se usarán para realizar la transferencia y carga. Tenga en cuenta las siguientes preguntas, que se describen en las secciones que siguen a continuación.
¿Extraerá los datos a los archivos o los moverá directamente a través de una conexión de red?
¿Orquestará el proceso desde el sistema de origen o desde el entorno de destino de Azure?
¿Qué herramientas usará para automatizar y administrar el proceso de migración?
¿Transferir datos a través de archivos o conexiones de red?
Una vez que las tablas de base de datos que se van a migrar se hayan creado en Azure Synapse, puede mover los datos que rellenan esas tablas fuera del sistema de Oracle heredado y dentro del nuevo entorno. Existen dos enfoques básicos:
Extracción de archivos: extraiga los datos de las tablas de Oracle a archivos planos delimitados, normalmente en formato CSV. Puede extraer los datos de las tablas de varias maneras:
- Use herramientas estándar de Oracle como SQL*Plus, SQL Developer y SQLcl.
- Use Oracle Data Integrator (ODI) para generar archivos planos.
- Use el conector de Oracle en Data Factory para descargar tablas de Oracle en paralelo para habilitar la carga de datos por particiones.
- Use una herramienta de ETL de terceros.
Para obtener ejemplos de cómo extraer los datos de las tablas de Oracle, consulte el apéndice del artículo.
Este enfoque requiere espacio para colocar los archivos de datos extraídos. El espacio podría ser local en la base de datos de origen de Oracle si hay suficiente almacenamiento disponible o remoto en Azure Blob Storage. El mejor rendimiento se consigue cuando un archivo se escribe localmente, ya que se evita la sobrecarga de red.
Para minimizar los requisitos de transferencia de red y almacenamiento, comprima los archivos de datos extraídos con una utilidad como gzip.
Después de la extracción, mueva los archivos planos a Azure Blob Storage. Microsoft proporciona varias opciones para mover grandes volúmenes de datos, entre las que se incluyen:
- AzCopy para mover archivos mediante la red a Azure Storage.
- Azure ExpressRoute para mover datos masivos mediante una conexión de red privada.
- Azure Data Box para mover archivos a un dispositivo de almacenamiento físico que se envía a un centro de datos de Azure para cargarlos.
Para más información, consulte Transferencia de datos a Azure y desde ahí.
Extracción y carga directa mediante la red: el entorno de Azure de destino envía una solicitud de extracción de datos, normalmente mediante un comando SQL, al sistema de Oracle heredado para extraer los datos. Los resultados se envían a través de la red y se cargan directamente en Azure Synapse, sin necesidad de colocar los datos en archivos intermedios. El factor de limitación de este escenario suele ser el ancho de banda de la conexión de red entre la base de datos de Oracle y el entorno de Azure. Para volúmenes de datos excepcionalmente grandes, este enfoque puede no ser práctico.
Sugerencia
Debe conocer los volúmenes de datos que se van a migrar y el ancho de banda de red disponible, ya que estos factores influyen a la hora de decidir el enfoque de migración.
También hay un enfoque híbrido que usa ambos métodos. Por ejemplo, puede usar el enfoque de extracción de red directa para tablas de dimensiones más pequeñas y muestras de las tablas de hechos más grandes para proporcionar rápidamente un entorno de prueba en Azure Synapse. En el caso de las tablas de hechos históricos de gran volumen, puede usar el enfoque de extracción y transferencia de archivos mediante Azure Data Box.
¿Orquestar desde Oracle o desde Azure?
El enfoque recomendado en el traslado a Azure Synapse es orquestar la extracción y carga de datos desde el entorno de Azure mediante SSMA o Data Factory. Use las utilidades asociadas, como PolyBase o COPY INTO, para una carga de datos más eficaz. Este enfoque aprovecha las ventajas de las funcionalidades integradas de Azure y reduce el esfuerzo de crear canalizaciones de carga de datos reutilizables. Puede usar canalizaciones de carga de datos controladas por metadatos para automatizar el proceso de migración.
El enfoque recomendado también minimiza el impacto en el rendimiento del entorno de Oracle existente durante el proceso de carga de datos, ya que el proceso de administración y carga se ejecuta en Azure.
Herramientas de migración de datos existentes
La transformación y el movimiento de datos es la función básica de todos los productos de ETL. Si ya está en uso una herramienta de migración de datos en el entorno de Oracle existente y admite Azure Synapse como entorno de destino, considere la posibilidad de usar esa herramienta para simplificar la migración de datos.
Incluso si no hay en funcionamiento una herramienta de ETL existente, los partners de integración de datos de Azure Synapse Analytics ofrecen herramientas de ETL para simplificar la tarea de migración de datos.
Por último, si tiene previsto usar una herramienta de ETL, considere la posibilidad de ejecutar esa herramienta en el entorno de Azure para aprovechar el rendimiento, la escalabilidad y el costo de la nube de Azure. Este enfoque también libera recursos en el centro de datos de Oracle.
Resumen
En resumen, nuestras recomendaciones para migrar los datos y los procesos de ETL asociados de Oracle a Azure Synapse son:
Planee con antelación para garantizar un ejercicio de migración correcto.
Cree un inventario detallado de datos y procesos que se van a migrar lo antes posible.
Use los metadatos del sistema y los archivos de registro para obtener una comprensión precisa del uso de datos y procesos. No confíe en la documentación, ya que puede estar obsoleta.
Comprenda los volúmenes de datos que se van a migrar y el ancho de banda de red entre el centro de datos local y los entornos en la nube de Azure.
Considere la posibilidad de usar una instancia de Oracle en una máquina virtual de Azure como paso intermedio para descargar la migración desde el entorno heredado de Oracle.
Utilice las características estándar integradas de Azure para minimizar la carga de trabajo de migración.
Identifique y conozca las herramientas más eficaces para la extracción y carga de datos en los entornos de Oracle y Azure. Usar las herramientas adecuadas en cada fase del proceso.
Use utilidades de Azure, como Data Factory, para orquestar y automatizar el proceso de migración, a la vez que minimiza el impacto en el sistema de Oracle.
Apéndice: Ejemplos de técnicas para extraer datos de Oracle
Puede usar varias técnicas para extraer datos de Oracle al migrar de Oracle a Azure Synapse. En las secciones siguientes, se muestra cómo extraer datos de Oracle mediante Oracle SQL Developer y el conector de Oracle de Data Factory.
Uso de Oracle SQL Developer para la extracción de datos
Puede usar la interfaz de usuario de Oracle SQL Developer para exportar los datos de las tablas a muchos formatos, incluido CSV, como se muestra en la captura de pantalla siguiente:

Otras opciones de exportación incluyen JSON y XML. Puede usar la interfaz de usuario para agregar un conjunto de nombres de tabla a un "carro" y, a continuación, aplicar la exportación a todo el conjunto del carro:

También puede usar la línea de comandos de Oracle SQL Developer (SQLcl) para exportar datos de Oracle. Esta opción admite la automatización mediante un script del shell.
En el caso de las tablas relativamente pequeñas, puede resultar útil esta técnica si experimenta problemas al extraer los datos mediante una conexión directa.
Uso del conector de Oracle de Azure Data Factory para la copia en paralelo
Puede usar el conector de Oracle de Data Factory para descargar tablas grandes de Oracle en paralelo. El conector de Oracle proporciona creación de particiones de datos integrada para copiar datos de Oracle en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.

Para obtener información sobre cómo configurar el conector de Oracle para la copia en paralelo, consulte Copia en paralelo desde Oracle.
Para más información sobre el rendimiento y la escalabilidad de la actividad de copia de Data Factory, consulte Guía de escalabilidad y rendimiento de la actividad de copia.
Pasos siguientes
Para más información sobre las operaciones de acceso de seguridad, consulte el siguiente artículo de esta serie: Seguridad, acceso y operaciones para migraciones de Oracle.