Seguridad, acceso y operaciones para migraciones de Teradata
Este artículo es la tercera parte de una serie de siete partes, que proporciona instrucciones sobre cómo migrar de Teradata a Azure Synapse Analytics. Este artículo se centra en los procedimientos recomendados para las operaciones de acceso de seguridad.
Consideraciones sobre la seguridad
En este artículo se describen los métodos de conexión para entornos heredados de Teradata existentes e indica cómo se pueden migrar a Azure Synapse Analytics con un riesgo y un impacto mínimo para el usuario.
Este artículo asume que hay un requisito dedicado a migrar los métodos existentes de conexión y usuario, de rol y de estructura de permisos tal cual. Si no es así, use Azure Portal para crear y administrar un nuevo régimen de seguridad.
Para obtener más información sobre las opciones de seguridad de Azure Synapse, consulte Notas del producto seguridad.
Conexión y autenticación
Opciones de autorización de Teradata
Sugerencia
La autenticación en Teradata y Azure Synapse puede hacerse "en la base de datos" o a través de métodos externos.
Teradata admite varios mecanismos para la conexión y autorización. Los valores de mecanismo válidos son:
TD1, que selecciona Teradata 1 como mecanismo de autenticación. Es necesario especificar el nombre de usuario y la contraseña.
TD2, que selecciona Teradata 2 como mecanismo de autenticación. Es necesario especificar el nombre de usuario y la contraseña.
TDNEGO, que selecciona uno de los mecanismos de autenticación automáticamente en función de la directiva, sin intervención del usuario.
LDAP, que selecciona el Protocolo ligero de acceso a directorios (LDAP) como mecanismo de autenticación. La aplicación proporciona el nombre de usuario y la contraseña.
KRB5, que selecciona Kerberos (KRB5) en clientes de Windows que trabajan con servidores Windows. Para iniciar sesión con KRB5, el usuario debe proporcionar un dominio, un nombre de usuario y una contraseña. Para especificar el dominio debe establecer el nombre de usuario en
MyUserName@MyDomain.NTLM, que selecciona NTLM en clientes de Windows que trabajan con servidores Windows. La aplicación proporciona el nombre de usuario y la contraseña.
Kerberos (KRB5), Compatibilidad de Kerberos (KRB5C), NT LAN Manager (NTLM) y Compatibilidad con NT LAN Manager (NTLMC) son solo para Windows.
Opciones de autorización de Azure Synapse
Azure Synapse admite dos opciones básicas para la conexión y la autorización:
Autenticación de SQL: la autenticación de SQL se realiza a través de una conexión de base de datos que incluye un identificador de base de datos, un id. de usuario y una contraseña más otros parámetros opcionales. Esto es, funcionalmente, equivalente a Teradata TD1, TD2 y conexiones predeterminadas.
Autenticación de Microsoft Entra: con la autenticación de Microsoft Entra puede administrar centralmente las identidades de los usuarios de la base de datos y otros servicios de Microsoft en una ubicación central. La administración de identificadores central ofrece un lugar único para administrar usuarios de SQL Data Warehouse y simplifica la administración de permisos. Microsoft Entra ID también puede admitir conexiones a los servicios LDAP y Kerberos; por ejemplo, Microsoft Entra ID se puede usar para conectarse a los directorios LDAP existentes si estos deben permanecer en vigor después de la migración de la base de datos.
Usuarios, roles y permisos
Información general
Sugerencia
El planeamiento de alto nivel es esencial para obtener un proyecto de migración correcto.
Tanto Teradata como Azure Synapse implementan el control de acceso a la base de datos a través de una combinación de usuarios, roles y permisos. Usan las instrucciones SQL estándar CREATE USER y CREATE ROLE para definir usuarios y roles, así como instrucciones GRANT y REVOKE para asignar o quitar permisos a esos usuarios o roles.
Sugerencia
Se recomienda automatizar los procesos de migración para reducir el tiempo transcurrido y el ámbito de los errores.
Conceptualmente, las dos bases de datos son similares y es posible automatizar la migración de identificadores de usuario, roles y permisos existentes hasta cierto punto. Para migrar estos datos, extraiga la información del rol y el usuario heredado existente de las tablas del catálogo del sistema de Teradata y genere las instrucciones equivalentes CREATE USER y CREATE ROLE que se ejecutarán en Azure Synapse para volver a crear la misma jerarquía de roles y usuarios.
Después de extraer los datos, use las tablas del catálogo del sistema de Teradata para generar instrucciones GRANT equivalentes para asignar permisos (donde exista una instrucción equivalente). En el diagrama siguiente se muestra cómo usar los metadatos existentes para generar la instancia de SQL necesaria.
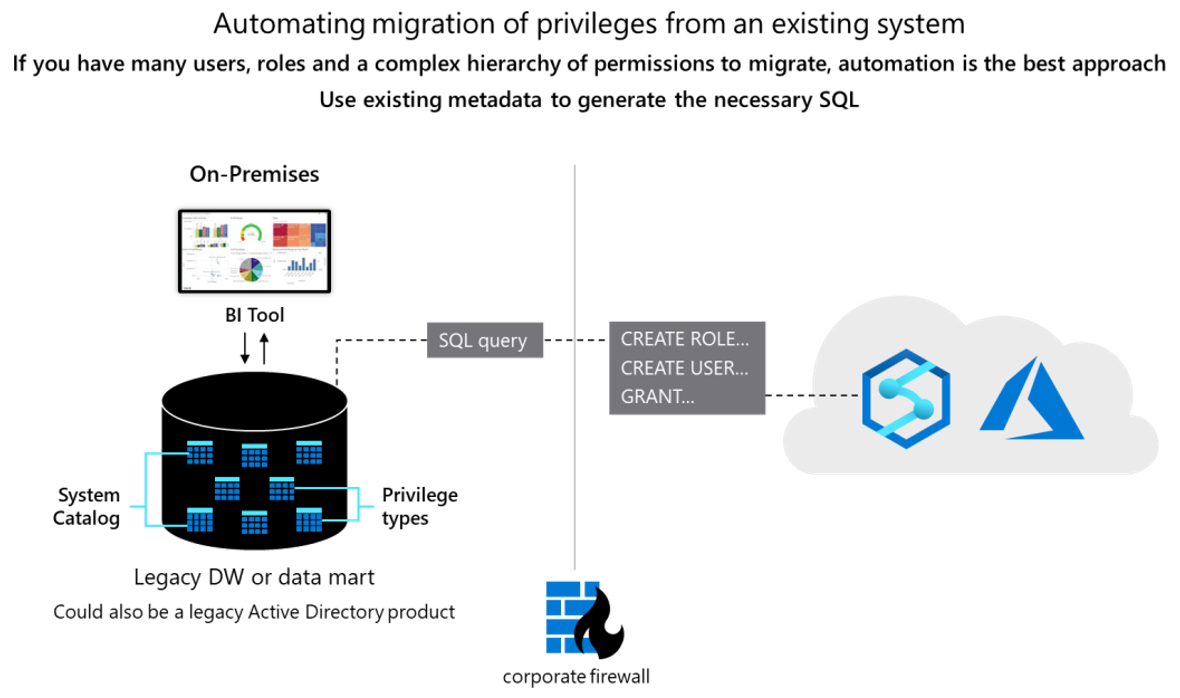
Usuarios y roles
Sugerencia
Recuerde que la migración de un almacenamiento de datos requiere tablas, vistas e instrucciones de SQL.
La información sobre los usuarios y roles actuales en un sistema de Teradata se encuentra en las tablas DBC.USERS (o DBC.DATABASES) y DBC.ROLEMEMBERS del catálogo del sistema. Consulte estas tablas (si el usuario tiene acceso de tipo SELECT a esas tablas) para obtener las listas actuales de usuarios y roles definidos en el sistema. A continuación se muestran ejemplos de consultas para seguir estos pasos en todos los usuarios individuales:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
Estos ejemplos modifican las instrucciones SELECT para generar un conjunto de resultados, que es una serie de instrucciones CREATE USER y CREATE ROLE, incluyendo el texto literal adecuado dentro de la instrucción SELECT.
No hay ninguna manera de recuperar las contraseñas existentes, por lo que debe implementar un esquema para asignar nuevas contraseñas iniciales en Azure Synapse.
Permisos
Sugerencia
Hay permisos de Azure Synapse equivalentes para las operaciones básicas de base de datos, como DML y DDL.
En un sistema de Teradata, el sistema tablas DBC.ALLRIGHTS y DBC.ALLROLERIGHTS contiene los derechos de acceso para los usuarios y roles. Consulte estas tablas (si el usuario tiene acceso de tipo SELECT a esas tablas) para obtener las listas actuales de acceso definidas en el sistema. A continuación se muestran ejemplos de consultas para los usuarios individuales:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Modifique las instrucciones SELECT de ejemplo para generar un conjunto de resultados, que sea una serie de instrucciones GRANT, incluyendo el texto literal adecuado dentro de la instrucción SELECT.
Use la tabla AccessRightsAbbv para buscar el texto completo del derecho de acceso, ya que la clave de combinación es un campo "type" abreviado. Consulte la tabla siguiente para obtener una lista de los derechos de acceso de Teradata y su equivalente en Azure Synapse.
| Nombre del permiso de Teradata | Tipo Teradata | Equivalente de Azure Synapse |
|---|---|---|
| ABORT SESSION | AS | KILL DATABASE CONNECTION |
| ALTER EXTERNAL PROCEDURE | AE | 4 |
| ALTER FUNCTION | AF | ALTER FUNCTION |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| CHECKPOINT | CP | CHECKPOINT |
| CREATE AUTHORIZATION | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| CREAR PROCEDIMIENTO EXTERNO | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CREATE GLOP | GC | 3 |
| CREATE MACRO | CM | CREATE PROCEDURE 2 |
| CREATE OWNER PROCEDURE | OP | CREATE PROCEDURE |
| CREATE PROCEDURE | PC | CREATE PROCEDURE |
| CREATE PROFILE | CO | CREATE LOGIN 1 |
| CREATE ROLE | CR | CREATE ROLE |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | .DROP FUNCTION |
| DROP GLOP | GD | 3 |
| DROP MACRO | DM | DROP PROCEDURE 2 |
| DROP PROCEDURE | PD | DELETE PROCEDURE |
| DROP PROFILE | DO | DROP LOGIN 1 |
| DROP ROLE | DR | DELETE ROLE |
| DROP TABLE | DT | DROP TABLE |
| DROP_TRIGGER | DG | 3 |
| DROP USER | DU | DROP USER |
| DROP VIEW | DV | DROP VIEW |
| DUMP | DP | 4 |
| EXECUTE | E | Ejecute |
| EXECUTE FUNCTION | EF | Ejecute |
| EXECUTE PROCEDURE | PE | Ejecute |
| GLOP MEMBER | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | MS | 5 |
| OVERRIDE DUMP CONSTRAINT | ED | 4 |
| OVERRIDE RESTORE CONSTRAINT | O BIEN | 4 |
| REFERENCES | RF | REFERENCES |
| REPLCONTROL | RO | 5 |
| RESTORE | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| SHOW | SH | 3 |
| UPDATE | U | UPDATE |
Notas de la tabla AccessRightsAbbv:
Teradata
PROFILEes funcionalmente equivalente aLOGINen Azure Synapse.En la tabla siguiente se resumen las diferencias entre macros y procedimientos almacenados en Teradata. En Azure Synapse, los procedimientos proporcionan la funcionalidad descrita en la tabla.
Macro Procedimiento almacenado Contiene SQL Contiene SQL Puede contener comandos de punto BTEQ Contiene SPL completo Puede recibir valores de parámetro pasados a esta Puede recibir valores de parámetro pasados a esta Puede recuperar una o varias filas Debe usar un cursor para recuperar más de una fila Almacenada en el espacio DBC PERM Almacenada en DATABASE o USER PERM Devuelve filas al cliente Puede devolver uno o varios valores al cliente como parámetros SHOW,GLOPyTRIGGERno tienen ningún equivalente directo en Azure Synapse.El sistema administra automáticamente estas características en Azure Synapse. Consulte Consideraciones operativas.
En Azure Synapse, estas características se controlan fuera de la base de datos.
Para obtener más información sobre los derechos de acceso en Azure Synapse, consulte Permisos de seguridad de Azure Synapse Analytics.
Consideraciones acerca de las operaciones
Sugerencia
Las tareas operativas son necesarias para que cualquier almacenamiento de datos funcione de forma eficaz.
En esta sección se describe cómo implementar tareas operativas típicas de Teradata en Azure Synapse con un riesgo y un impacto mínimos para los usuarios.
Igual que sucede con todos los productos de almacenamiento de datos, una vez en producción, hay tareas de administración continuas que son necesarias para mantener el sistema funcionando de forma eficaz y así poder proporcionar datos para la supervisión y auditoría. El uso de recursos y el planeamiento de la capacidad para el crecimiento futuro también entran en esta categoría, igual que la copia de seguridad o la restauración de los datos.
Aunque conceptualmente las tareas de administración y operaciones de diferentes almacenes de datos son similares, las implementaciones individuales pueden tener puntos diferentes. En general, los productos modernos basados en la nube, como Azure Synapse, tienden a incorporar un enfoque más automatizado y "administrado por el sistema" (en lugar de un enfoque más manual en almacenes de datos heredados, como Teradata).
En las secciones siguientes se comparan las opciones de Teradata y Azure Synapse para diversas tareas operativas.
Tareas de limpieza
Sugerencia
Las tareas de limpieza mantienen un almacén de producción que funciona eficazmente y optimizan el uso de recursos, como el almacenamiento.
En la mayoría de los entornos de almacenamiento de datos heredados, hay un requisito para realizar tareas normales de "limpieza", como reclamar espacio de almacenamiento en disco que se pueda liberar quitando versiones antiguas de filas actualizadas o eliminadas, o reorganizando archivos de registro de datos o bloques de índice para mejorar la eficacia. La recopilación de estadísticas también es una tarea potencialmente tediosa. La recopilación de estadísticas es necesaria después realizar una ingesta masiva de datos, ya que debe proporcionar al optimizador de consultas datos actualizados para la generación base de planes de ejecución de consultas.
Teradata recomienda recopilar estadísticas de la siguiente manera:
Recopile estadísticas en tablas no rellenadas para configurar el histograma de intervalo que se usa en el procesamiento interno. Esta colección inicial hace que las recopilaciones de estadísticas posteriores sean más rápidas. Asegúrese de volver a recopilar las estadísticas después de agregar los datos.
Recopile estadísticas de la fase de prototipo para las tablas rellenadas por primera vez.
Recopile estadísticas de la fase de producción después de un porcentaje significativo de cambio en la tabla o partición (~10 % de filas). Para grandes volúmenes de valores no únicos, como fechas o marcas de tiempo, puede ser ventajoso realizar una recoleción al 7 %.
Recopile estadísticas de la fase de producción después de crear usuarios y aplicar cargas de consultas reales a la base de datos (hasta tres meses de consulta).
Recopile estadísticas en las primeras semanas después de realizar una actualización o migración durante períodos de bajo uso de CPU.
La recopilación de estadísticas se puede administrar manualmente mediante las API abiertas de Administración de estadísticas automatizada o automáticamente mediante el portlet Stats Manager del punto de vista de Teradata.
Sugerencia
Automatice y supervise las tareas de limpieza en Azure.
La base de datos de Teradata contiene muchas tablas de registro en el diccionario de datos que acumulan datos, ya sea automáticamente o después de habilitar determinadas características. Dado que los datos de registro crecen con el tiempo, purgue la información anterior para evitar el uso de espacio permanente. Hay opciones para automatizar el mantenimiento de estos registros disponibles. Las tablas de diccionario de Teradata que requieren mantenimiento se describen a continuación.
Tablas de diccionario que se van a mantener
Restablezca los acumuladores y los valores máximos mediante la vista DBC.AMPUsage y la macro ClearPeakDisk que se proporcionan con el software:
DBC.Acctg: uso de recursos por cuenta y usuarioDBC.DataBaseSpace: contabilidad del espacio de tablas y base de datos
Teradata mantiene automáticamente estas tablas, pero los procedimientos recomendados pueden reducir su tamaño:
DBC.AccessRights: derechos de usuario en objetosDBC.RoleGrants: derechos de roles en objetosDBC.Roles: roles definidosDBC.Accounts: códigos de cuenta por usuario
Archive estas tablas de registro (si quiere) y purgue información de 60-90 días de antigüedad. La retención depende de los requisitos del cliente:
DBC.SW_Event_Log: registro de la consola de base de datosDBC.ResUsage: tablas de supervisión de recursosDBC.EventLog: historial de inicio o fin de sesiónDBC.AccLogTbl: eventos de usuarios u objetos registradosDBC.DBQL tables: actividad de usuarios o elementos SQL registrados.NETSecPolicyLogTbl: registra seguimientos de auditoría de directivas de seguridad dinámicas.NETSecPolicyLogRuleTbl: controla cuándo y cómo se registra la directiva de seguridad dinámica
Purgue estas tablas cuando el medio extraíble asociado haya expirado y se sobrescriba:
DBC.RCEvent: eventos de archivos y recuperaciónDBC.RCConfiguration: configuración de archivos y recuperaciónDBC.RCMedia: VolSerial para archivos y recuperación
Azure Synapse tiene una opción para crear automáticamente estadísticas que puede usar según sea necesario. Realice la desfragmentación de índices y bloques de datos manualmente, de forma programada o automática. Aproveche las funcionalidades nativas integradas de Azure y reduzca el esfuerzo necesario en un ejercicio de migración.
Supervisión y auditoría
Sugerencia
Con el tiempo, se han implementado varias herramientas diferentes para permitir la supervisión y el registro de sistemas de Teradata.
Teradata proporciona varias herramientas para supervisar la operación, incluido el punto de vista de Teradata y el Administrador del ecosistema. Para registrar el historial de consultas, el Registro de consultas de base de datos (DBQL) es una característica de base de datos de Teradata que proporciona una serie de tablas predefinidas que pueden almacenar registros históricos de consultas y su duración, rendimiento y actividades de destino, en función de las reglas definidas por el usuario.
Los administradores de bases de datos pueden usar el punto de vista de Teradata para determinar el estado del sistema, las tendencias y el estado de las consultas individuales. Al observar las tendencias en el uso del sistema, los administradores del sistema pueden planear mejor las implementaciones del proyecto, los trabajos por lotes y el mantenimiento para evitar períodos de uso máximos. Los usuarios empresariales pueden usar el punto de vista de Teradata para acceder rápidamente al estado de los informes y las consultas y explorar en profundidad los detalles.
Sugerencia
Azure Portal proporciona una interfaz de usuario para administrar las tareas de supervisión y auditoría de todos los datos y procesos de Azure.
Igualmente, Azure Synapse proporciona una experiencia de supervisión enriquecida en Azure Portal que proporciona detalles a la carga de trabajo del almacenamiento de datos. Azure Portal es la herramienta recomendada al supervisar el almacenamiento de datos, ya que proporciona períodos de retención configurables, alertas, recomendaciones, y gráficos y paneles personalizables para métricas y registros.
El portal también le permite integrarse con otros servicios de supervisión de Azure, tales como Operations Management Suite (OMS) y Azure Monitor (registros) para ofrecer una experiencia de supervisión holística no solo para el almacenamiento de datos sino también para toda la plataforma Azure Analytics como experiencia de supervisión integrada.
Sugerencia
Las métricas de bajo nivel y en todo el sistema se registran automáticamente en Azure Synapse.
Las estadísticas de uso de recursos para Azure Synapse se registran automáticamente en el sistema. Las métricas de cada consulta incluyen estadísticas de uso de CPU, memoria, caché, E/S y área de trabajo temporal, así como información de conectividad, como intentos de conexión con error.
Azure Synapse proporciona un conjunto de vistas de administración dinámica (DMV). Estas vistas resultan útiles para la solución de problemas y la identificación activas de cuellos de botella de rendimiento con la carga de trabajo.
Para obtener más información, consulte Operaciones y opciones de administración de Azure Synapse.
Alta disponibilidad (HA) y recuperación ante desastres (DR)
Teradata implementa características como FALLBACK, la utilidad Archive Restore Copy (ARC) y Data Stream Architecture (DSA) para proporcionar protección contra la pérdida de datos y la alta disponibilidad (HA) a través de la replicación y el archivo de datos. Entre las opciones de recuperación ante desastres (DR) se incluyen la Solución activa dual, la recuperación ante desastres como servicio o un sistema de reemplazo según el requisito de tiempo de recuperación.
Sugerencia
Azure Synapse crea instantáneas automáticamente para garantizar tiempos de recuperación rápidos.
Azure Synapse usa instantáneas de base de datos para proporcionar una alta disponibilidad del almacén. Una instantánea de almacenamiento de datos crea un punto de restauración que se puede usar para copiar el almacenamiento de datos o recuperarlo a un estado anterior. Dado que Azure Synapse es un sistema distribuido, una instantánea de almacenamiento de datos consta de muchos archivos que se almacenan en Azure Storage. Las instantáneas capturan los cambios incrementales de los datos almacenados en el almacenamiento de datos.
Azure Synapse toma automáticamente instantáneas a lo largo del día y crea puntos de restauración que están disponibles durante siete días. Este período de retención no se puede modificar. Azure Synapse admite un objetivo de punto de recuperación (RPO) de ocho horas. Un almacenamiento de datos se puede restaurar en la región primaria a partir de cualquiera de las instantáneas tomadas en los últimos siete días.
Sugerencia
Use instantáneas definidas por el usuario para definir un punto de recuperación antes de las actualizaciones de claves.
También se admiten puntos de restauración definidos por el usuario, lo que permite el desencadenamiento manual de instantáneas para crear puntos de restauración de un almacenamiento de datos antes y después de modificaciones de gran tamaño. Esta funcionalidad garantiza que los puntos de restauración sean lógicamente coherentes, lo que proporciona una protección de datos adicional en caso de interrupciones de la carga de trabajo o de errores del usuario para un tiempo de recuperación rápido o para menos de 8 horas.
Sugerencia
Microsoft Azure proporciona copias de seguridad automáticas en una ubicación geográfica independiente para habilitar la recuperación ante desastres.
Además de las instantáneas descritas anteriormente, Azure Synapse también realiza de forma predeterminada una copia de seguridad geográfica una vez al día en un centro de datos emparejado. El RPO para una restauración geográfica es de 24 horas. Puede restaurar la copia de seguridad geográfica en un servidor de cualquier otra región donde se admita Azure Synapse. Una copia de seguridad geográfica garantiza que se pueda restaurar un almacenamiento de datos en caso de que los puntos de restauración de la región primaria no estén disponibles.
Administración de cargas de trabajo
Sugerencia
En un almacenamiento de datos de producción, normalmente hay cargas de trabajo mixtas con diferentes características de uso de recursos que se ejecutan simultáneamente.
Una carga de trabajo es una clase de solicitudes de base de datos con rasgos comunes, cuyo acceso a la base de datos se puede administrar con un conjunto de reglas. Las cargas de trabajo son útiles para:
Establecer diferentes prioridades de acceso para diferentes tipos de solicitudes.
Supervisar patrones de uso de recursos, ajustar el rendimiento y planear la capacidad.
Limitar el número de solicitudes o sesiones que se pueden ejecutar al mismo tiempo.
En un sistema de Teradata, la administración de cargas de trabajo es el acto de administrar el rendimiento de la carga de trabajo mediante la supervisión de la actividad del sistema y la acción cuando se alcanzan los límites predefinidos. La administración de cargas de trabajo usa reglas y cada regla solo se aplica a algunas solicitudes de base de datos. Sin embargo, la colección de todas las reglas se aplica a todo el trabajo activo en la plataforma. Teradata Active System Management (TASM) realiza una administración completa de cargas de trabajo en una base de datos de Teradata.
En Azur Synapse, las clases de recursos son límites de recursos predeterminados que rigen los recursos de proceso y la simultaneidad de la ejecución de las consultas. Las clases de recursos pueden ayudarle a administrar la carga de trabajo mediante el establecimiento de límites en el número de consultas que se ejecutan simultáneamente y en los recursos de proceso que se asignan a cada consulta. Gracias a esto, la memoria y la simultaneidad se compensan.
Azure Synapse registra automáticamente las estadísticas de uso de recursos. Las métricas incluyen estadísticas de uso para CPU, memoria, caché, E/S y área de trabajo temporal para cada consulta. Azure Synapse también registra información de conectividad, como los intentos de conexión con error.
Sugerencia
Las métricas de bajo nivel y de todo el sistema se registran automáticamente en Azure.
Azure Synapse admite estos conceptos básicos de administración de cargas de trabajo:
Clasificación de cargas de trabajo: puede asignar una solicitud a un grupo de cargas de trabajo para establecer niveles de importancia.
Importancia de la carga de trabajo: puede influir en el orden en el que una solicitud obtiene acceso a los recursos. De manera predeterminada, las consultas se liberan desde la cola sobre la base primero en entrar, primero en salir, a medida que los recursos están disponibles. La importancia de las cargas de trabajo permite que las consultas de prioridad más alta reciban recursos de inmediato, independientemente de la cola.
Aislamiento de la carga de trabajo: puede reservar recursos para un grupo de cargas de trabajo, asignar un uso máximo y mínimo para distintos recursos, limitar los recursos que puede consumir un grupo de solicitudes y establecer un valor de tiempo de espera para terminar automáticamente las consultas descontroladas.
La ejecución de cargas de trabajo mixtas puede suponer desafíos de recursos en sistemas ocupados. Un esquema de administración de cargas de trabajo correcto administra los recursos de manera eficaz, garantiza un uso de recursos muy eficaz y maximiza la rentabilidad de la inversión (ROI). La clasificación de la carga de trabajo, la importancia de la carga de trabajo y el aislamiento de la carga de trabajo proporcionan más control sobre cómo la carga de trabajo utiliza los recursos del sistema.
En la guía de administración de cargas de trabajo se describen las técnicas para analizar la carga de trabajo, administrar y supervisar la importancia de la carga de trabajo](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) y los pasos para convertir una clase de recurso en un grupo de cargas de trabajo. Use Azure Portal y las consultas de T-SQL en DMV para supervisar la carga de trabajo para asegurarse de que los recursos aplicables se usan de forma eficaz. Azure Synapse proporciona un conjunto de vistas de administración dinámica (DMV) para supervisar todos los aspectos de la administración de cargas de trabajo. Estas vistas resultan útiles para la solución de problemas y la identificación activas de cuellos de botella de rendimiento en la carga de trabajo.
Esta información también se puede usar para planear la capacidad, determinar los recursos necesarios para usuarios adicionales o para cargas de trabajo de la aplicación. Esto también se aplica a la planificación del escalado vertical o la reducción vertical de recursos de proceso para la conseguir una compatibilidad rentable de las cargas de trabajo que cuentan con "picos".
Para más información sobre la administración de cargas de trabajo en Azure Synapse, consulte Administración de cargas de trabajo con clases de recursos.
Escalado de los recursos de proceso
Sugerencia
Una ventaja importante de Azure es la capacidad de escalar y reducir verticalmente los recursos de proceso de forma independiente y a petición, para controlar las cargas de trabajo máximas de forma rentable.
La arquitectura de Azure Synapse separa el proceso y el almacenamiento, lo que permite que cada uno se escale de forma independiente. Por consiguiente, los recursos de proceso se puede escalar para satisfacer las demandas de rendimiento independientemente del almacenamiento de datos. También puede pausar y reanudar los recursos de proceso. Un beneficio natural de esta arquitectura es que la facturación por proceso y almacenamiento está separada. Si un almacenamiento de datos no está en uso, puede ahorrar en los costos pausando el proceso.
Los recursos de proceso se pueden escalar o reducir verticalmente ajustando la configuración de unidades de almacenamiento de datos para el almacenamiento de datos. La carga y el rendimiento de las consultas pueden aumentar linealmente a medida que agrega más unidades de almacenamiento de datos.
Agregar más nodos de proceso incrementa la capacidad del proceso y la facultad para aprovechar más procesamiento paralelo. A medida que aumenta el número de nodos de proceso, se reduce el número de distribuciones por nodo de proceso, de forma que hay más capacidad de proceso y procesamiento paralelo para las consultas. De forma similar, al reducir las unidades de almacenamiento de datos se reduce el número de nodos de proceso, de forma que se reducen los recursos de proceso para las consultas.
Pasos siguientes
Para obtener más información sobre la visualización y los informes, consulte el siguiente artículo de esta serie: Visualización e informes para migraciones de Teradata.