Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Los grupos de inicio proporcionan un inicio rápido de la sesión de Spark en Fabric. Puede iniciar el trabajo de Spark rápidamente, en lugar de esperar a que se aprovisione el clúster completo en cada ejecución.
Los grupos de inicio usan nodos medianos y admiten el escalado automático en función de la demanda de cargas de trabajo. Los límites predeterminados y máximos dependen de la capacidad SKU de Fabric.
Prerrequisitos
Para personalizar un grupo de inicio, necesita el rol Administrador en el área de trabajo.
Entender la configuración del grupo inicial
En la configuración del área de trabajo, puede configurar estos controles de grupo de inicio:
- Escalado automático: si está habilitado, el grupo de Apache Spark se escala y reduce verticalmente automáticamente en función de la actividad.
- Asignar ejecutores dinámicamente: si está habilitado, Spark asigna y libera ejecutores en función de la demanda de cargas de trabajo.
Ambas opciones están habilitadas de forma predeterminada. Use los controles deslizantes para aumentar o disminuir los límites configurados para la carga de trabajo.
Configuración del grupo de inicio
Para administrar el grupo inicial asociado al área de trabajo:
Vaya al área de trabajo y seleccione Configuración del área de trabajo.

Expanda Ingeniería de datos/Ciencia en el panel izquierdo y, a continuación, seleccione Configuración de Spark.
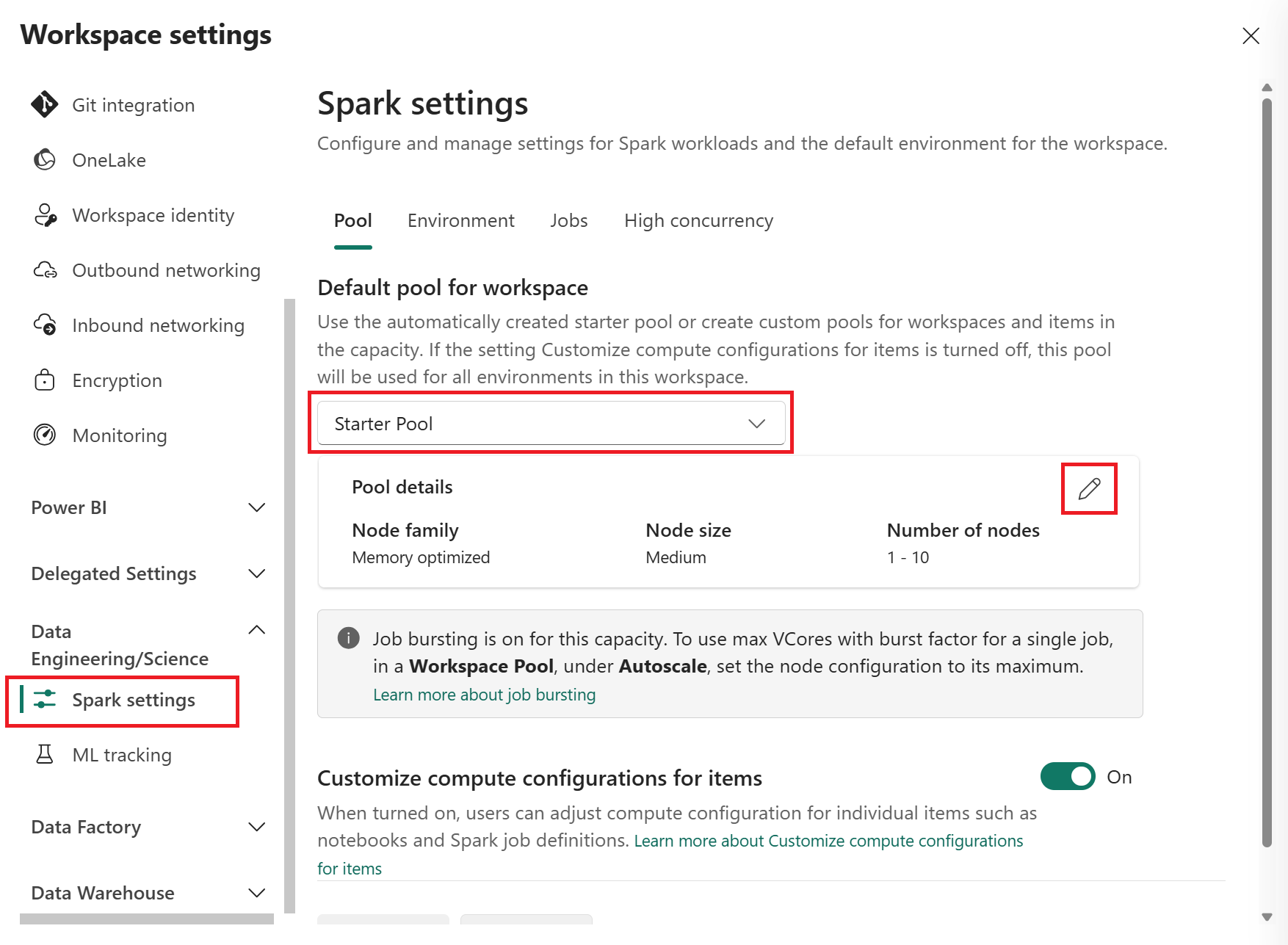
Seleccione StarterPool en la lista desplegable Grupo predeterminado para el área de trabajo para ver información general sobre la configuración del grupo de inicio.
Seleccione el icono de lápiz de la sección Detalles del grupo para editar la configuración del grupo de inicio.
En la vista de edición, configure escalabilidad automática y asigne ejecutores dinámicamente.
Use los controles deslizantes para aumentar o disminuir cada configuración en función de las necesidades de la carga de trabajo.
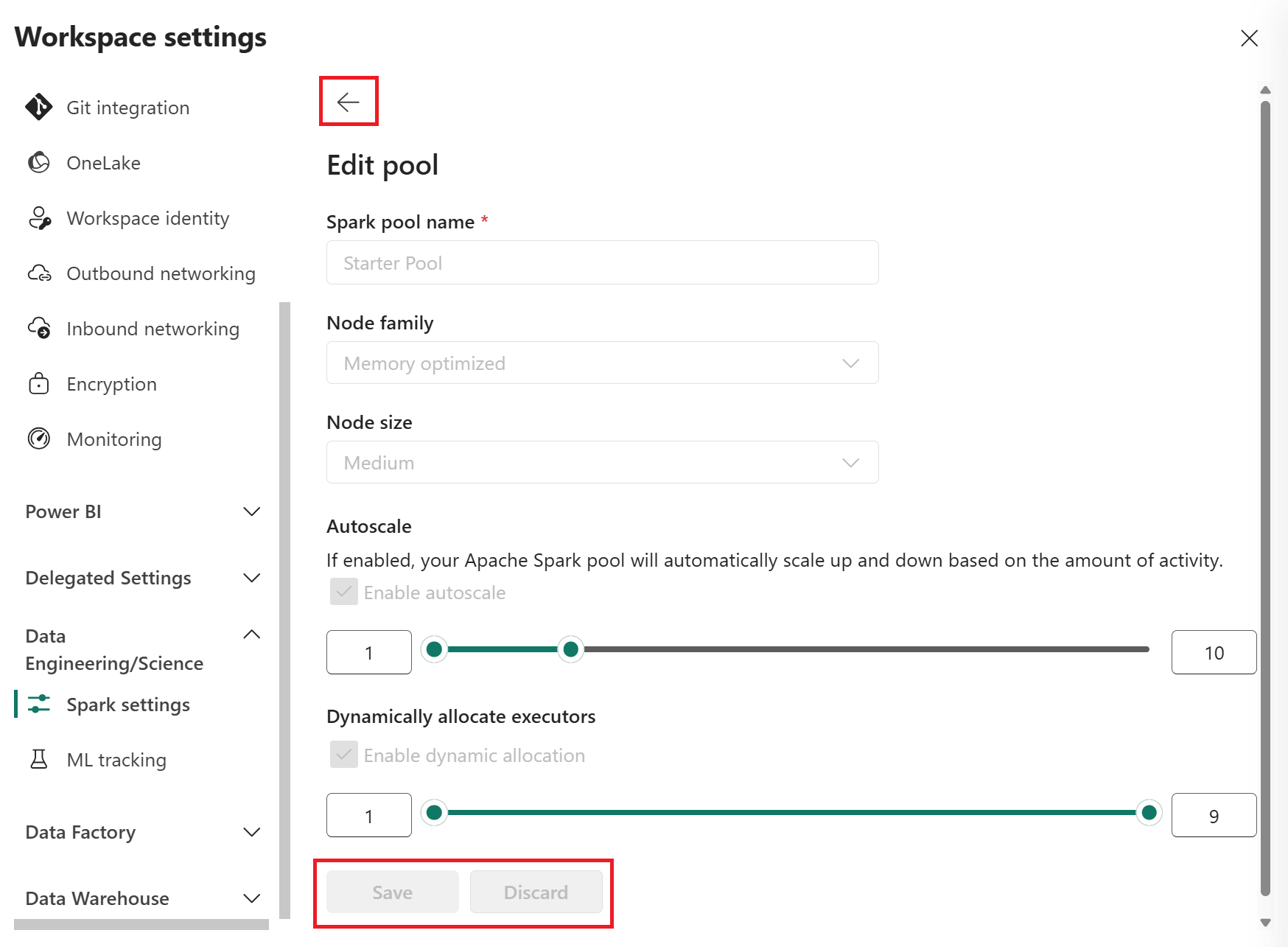
Puede mantener los valores predeterminados o reducir los límites de las cargas de trabajo más pequeñas. También puede aumentar los valores hasta el máximo permitido para la SKU.
Después de realizar los cambios, seleccione Guardar para aplicar la nueva configuración del grupo de inicio o seleccione Descartar para descartar los cambios. De lo contrario, puede seleccionar la flecha atrás para salir sin guardar o descartar los cambios.



En la tabla siguiente se muestran los límites predeterminados y máximos de nodos del grupo de inicio por SKU.
| Nombre de SKU | Unidades de capacidad | Núcleos virtuales de Spark | Tamaño del nodo | Nodos máximos predeterminados | Número máximo de nodos |
|---|---|---|---|---|---|
| F2 | 2 | 4 | Medio | 1 | 1 |
| F4 | 4 | 8 | Medio | 1 | 1 |
| F8 | 8 | 16 | Medio | 2 | 2 |
| F16 | 16 | 32 | Medio | 3 | 4 |
| F32 | 32 | 64 | Medio | 8 | 8 |
| F64 | 64 | 128 | Medio | 10 | 16 |
| (Capacidad de prueba) | 64 | 128 | Medio | 10 | 16 |
| F128 | 128 | 256 | Medio | 10 | 32 |
| F256 | 256 | 512 | Medio | 10 | 64 |
| F512 | 512 | 1024 | Medio | 10 | 128 |
| F1024 | 1024 | 2048 | Medio | 10 | 200 |
| F2048 | 2048 | 4096 | Medio | 10 | 200 |
Contenido relacionado
- Obtenga más información en la documentación pública de Apache Spark.
- Introducción a la configuración de administración del área de trabajo de Spark en Microsoft Fabric.