Cómo crear una definición de trabajo de Apache Spark en Fabric
En este tutorial, aprenderá a crear una definición de trabajo de Spark en Microsoft Fabric.
Requisitos previos
Antes de comenzar, necesita:
- Una cuenta de arrendatario de Fabric con una suscripción activa. Cree una cuenta gratuita.
Sugerencia
Para ejecutar el elemento de definición de trabajo de Spark, debe disponer de un archivo de definición principal y de un contexto de almacén de lago predeterminado. Si no tiene un lago de datos, puede crear una siguiendo los pasos descritos en Creación de un lago de datos.
Creación de una definición de trabajo de Spark
El proceso de creación de una definición de empleo en Spark es rápido y sencillo; hay varias formas de empezar.
Opciones para crear una definición de trabajo de Spark
Hay varias maneras de empezar a trabajar con el proceso de creación:
Página principal de ingeniería de datos: puede crear fácilmente una definición de trabajo de Spark a través de la tarjeta de definición de trabajo de Spark en la sección Nuevo de la página principal.

Vista del área de trabajo: también puede crear una definición de trabajo Spark a través de la vista del área de trabajo en Ingeniería de datos, utilizando el menú desplegable Nuevo.

Crear vista: Otro punto de entrada para crear una definición de trabajo Spark es la página Crear en Ingeniería de Datos.
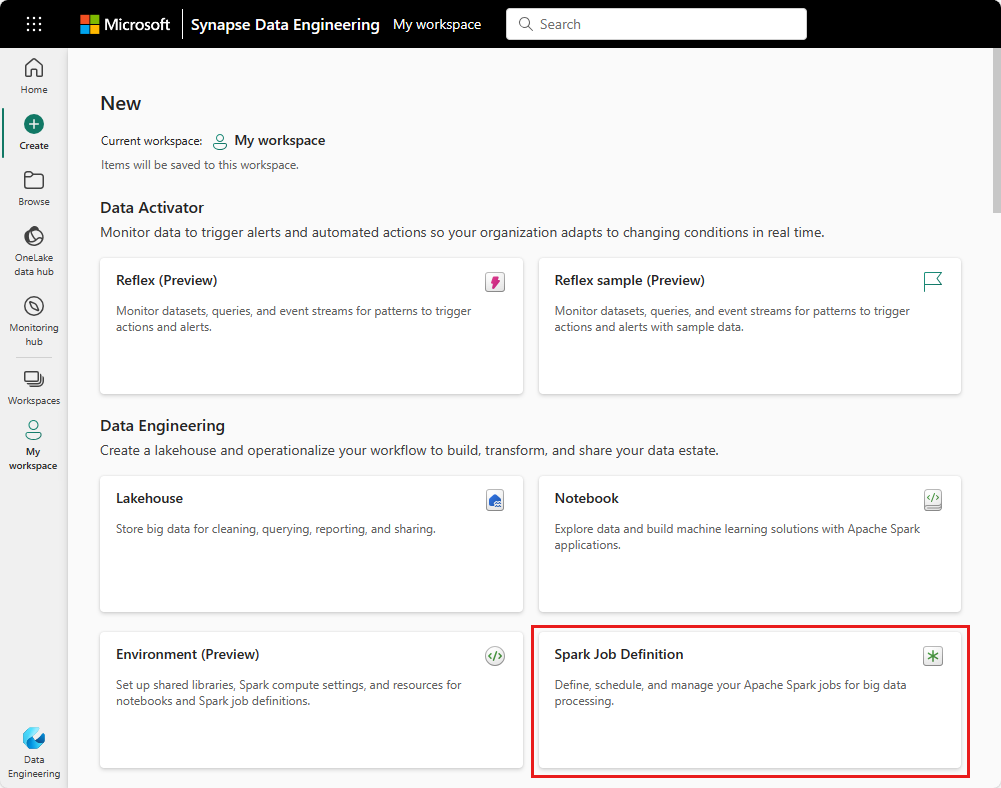
Debe asignarle un nombre a su definición de trabajo Spark cuando la cree. El nombre debe ser único dentro del área de trabajo actual. La nueva definición de trabajo Spark se crea en su área de trabajo actual.
Creación de una definición de trabajo de Apache Spark para PySpark (Python)
Para crear una definición de trabajo Spark para PySpark:
Descarga el archivo Parquet de ejemplo yellow_tripdata_2022-01.parquet y cárgalo en la sección de archivos del lakehouse.
Cree una nueva definición de trabajo de Spark.
Seleccione PySpark (Python) en la lista desplegable Lenguaje .
Descarga el ejemplo createTablefromParquet.py y cárgalo como archivo de definición principal. El archivo de definición principal (job.Main) es el archivo que contiene la lógica de la aplicación y es obligatorio para ejecutar un trabajo Spark. Para cada definición de trabajo Spark, solo puede cargar un archivo de definición principal.
Puede cargar el archivo de definición principal desde su escritorio local, o puede cargarlo desde un Azure Data Lake Storage (ADLS) Gen2 existente proporcionando la ruta ABFSS completa del archivo. Por ejemplo,
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Cargue los archivos de referencia como archivos .py. Los archivos de referencia son los módulos python importados por el archivo de definición principal. Al igual que el archivo de definición principal, puede cargarlo desde su escritorio o desde un ADLS Gen2 existente. Se admiten varios archivos de referencia.
Sugerencia
Si utiliza una ruta ADLS Gen2, para asegurarse de que se puede acceder al archivo, debe dar a la cuenta de usuario que ejecuta el trabajo el permiso adecuado a la cuenta de almacenamiento. Sugerimos dos formas diferentes de hacerlo:
- Asigne a la cuenta de usuario una función de colaborador para la cuenta de almacenamiento.
- Conceda permiso de Lectura y Ejecución a la cuenta de usuario para el archivo a través de la Lista de Control de Acceso (ACL) de ADLS Gen2.
Para una ejecución manual, se utiliza la cuenta del usuario de inicio de sesión actual para ejecutar el trabajo.
Proporcione argumentos de línea de comandos para el trabajo, si es necesario. Utilice un espacio como separador para separar los argumentos.
Agregue la referencia de lakehouse al trabajo. Debe tener al menos una referencia de lakehouse agregada al trabajo. Este lakehouse es el contexto de lakehouse predeterminado para el trabajo.
Se admiten varias referencias de lakehouse. Encuentre el nombre no predeterminado del almacén del lago y la URL completa de OneLake en la página de Configuración de Spark.

Creación de una definición de trabajo de Spark para Scala/Java
Para crear una definición de trabajo Spark para Scala/Java:
Cree una nueva definición de trabajo de Spark.
Seleccione Spark(Scala/Java) en la lista desplegable Lenguaje .
Cargue el archivo de definición principal como archivo .jar. El archivo de definición principal es el archivo que contiene la lógica de aplicación de este trabajo y es obligatorio para ejecutar un trabajo Spark. Para cada definición de trabajo Spark, solo puede cargar un archivo de definición principal. Seleccione el nombre de clase Main.
Cargue los archivos de referencia como archivo .jar. Los archivos de referencia son los archivos a los que hace referencia/importa el archivo de definición principal.
Proporcione argumentos de línea de comandos para el trabajo, si es necesario.
Agregue la referencia de lakehouse al trabajo. Debe tener al menos una referencia de lakehouse agregada al trabajo. Este lakehouse es el contexto de lakehouse predeterminado para el trabajo.
Creación de una definición de trabajo de Spark
Para crear una definición de trabajo Spark para SparkR(R):
Cree una nueva definición de trabajo de Spark.
Seleccione SparkR(R) en la lista desplegable Lenguaje .
Cargue el archivo de definición principal como archivo .R. El archivo de definición principal es el archivo que contiene la lógica de aplicación de este trabajo y es obligatorio para ejecutar un trabajo Spark. Para cada definición de trabajo Spark, solo puede cargar un archivo de definición principal.
Cargue los archivos de referencia como Archivo .R. Los archivos de referencia son los archivos a los que hace referencia/importa el archivo de definición principal.
Proporcione argumentos de línea de comandos para el trabajo, si es necesario.
Agregue la referencia de lakehouse al trabajo. Debe tener al menos una referencia de lakehouse agregada al trabajo. Este lakehouse es el contexto de lakehouse predeterminado para el trabajo.
Nota:
La definición del trabajo Spark se creará en su área de trabajo actual.
Opciones para personalizar las definiciones de trabajo de Spark
Existen algunas opciones para personalizar aún más la ejecución de las definiciones de trabajo de Spark.
- Spark Compute: Dentro de la pestaña Spark Compute, puede ver la Versión de runtime que es la versión de Spark que se utilizará para ejecutar el trabajo. También puede ver los valores de configuración de Spark que se usarán para ejecutar el trabajo. Para personalizar las opciones de configuración de Spark, haga clic en el botón Agregar .
Optimización: En la pestaña Optimización, puede habilitar y configurar la Directiva de Reintentos para el trabajo. Cuando está habilitada, el trabajo se reintenta si falla. También puedes establecer el número máximo de reintentos y el intervalo entre ellos. Por cada intento de reintento, el trabajo se reinicia. Asegúrese de que el trabajo es idempotente.
