Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Nota:
Este es el cuarto de una serie de temas sobre el diseño de personalización escalable. Para empezar al principio, consulte Diseño de personalización escalable en Microsoft Dataverse.
En esta sección se describen los patrones de diseño para evitar o minimizar y sus implicaciones. Cada patrón de diseño debe considerarse en el contexto del problema empresarial que se está solucionando y puede ser útil como opciones para investigar.
No evite el bloqueo
El bloqueo es un componente importante de SQL Server y Dataverse, y es esencial para el funcionamiento correcto y la coherencia del sistema. Por esta razón, es importante comprender sus implicaciones en el diseño, especialmente a escala.
Use de transacciones: Sugerencia Nolock
Una funcionalidad de Dataverse que utilizan mucho las vistas es la capacidad de especificar que una consulta pueda realizarse con una sugerencia Nolock, que indica a la base de datos de que no se necesita un bloqueo para esta consulta.
Las vistas usan este método porque no hay un vínculo directo entre la acción de iniciar la vista y las acciones posteriores. Muchas otras actividades pueden producirse bien ese usuario u otros y no es práctico ni ventajoso bloquear la tabla completa de datos que muestra la vista mientras hasta que el usuario prosiga.
Dado que una consulta en un conjunto de datos de gran tamaño significa que puede afectar a otros usuarios que intentan interactuar con cualquiera de esos datos, poder especificar que no se requiere ningún bloqueo puede tener una ventaja significativa en la escalabilidad del sistema.
Al realizar una consulta de la plataforma a través del SDK, puede ser valioso especificar que se puede usar nolock. Indica que se reconoce que esta consulta no requiere un bloqueo de lectura en la base de datos. Es especialmente útil para las consultas en las que:
- Hay una amplia gama de datos
- Se consultan los recursos altamente disputados
- La serialización no es importante
Nolock no debe usarse si una acción posterior no depende de ningún cambio en los resultados, como en el ejemplo de bloqueo automático de números anteriormente.
Un escenario de ejemplo en el que puede resultar útil es determinar si un correo electrónico está relacionado con un caso existente. Impedir que otros usuarios creen nuevos casos para asegurarse de que no hay posibilidad de que se genere un caso al que el correo electrónico pueda vincular no sea un nivel beneficioso de control de coherencia.
En su lugar, hacer un esfuerzo razonable para consultar los casos relacionados y adjuntar el correo electrónico a un caso existente o crear uno nuevo, a la vez que permite generar otros casos, es más adecuado. En particular, dado que no hay ningún vínculo inherente en el tiempo entre estas dos acciones, el correo electrónico podría haber llegado tan fácilmente en unos segundos antes y no se habría detectado ningún vínculo.
Si las sugerencias Nolock fuesen válidas para un escenario particular se basarían normalmente en la posibilidad y el impacto de los conflictos que surjan y la implicación en el negocio de no garantizar la coherencia en las acciones, entre la acción de recuperar y las subsecuentes. Donde no se produciría ningún impacto empresarial al evitar el bloqueo, el uso de nolocks sería una opción de optimización valiosa. Si hay un posible impacto empresarial, la consecuencia de esto se puede ponderar contra el rendimiento y las ventajas de escalabilidad de evitar el bloqueo.
Considerar el orden de bloqueos
Otro enfoque que puede ser útil para reducir el impacto del bloqueo y, especialmente, evitar interbloqueos, es tener un enfoque coherente con el orden de bloqueos en una implementación.
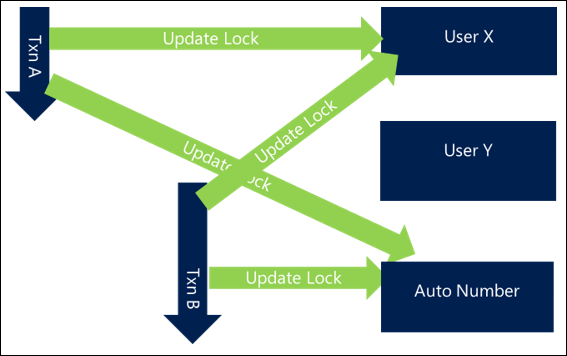
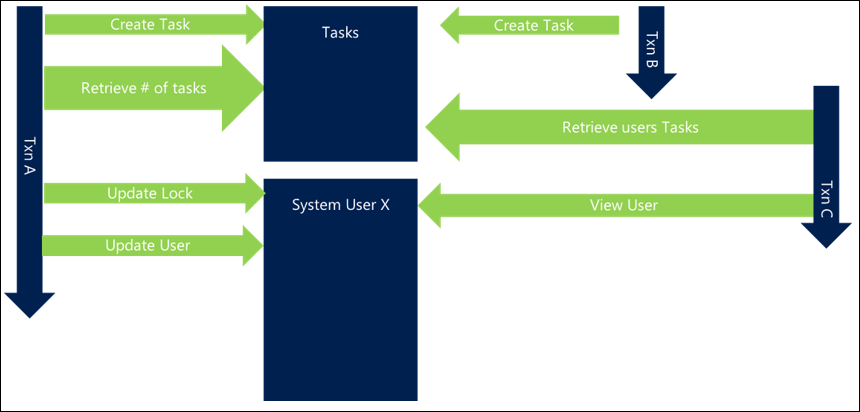
Un ejemplo sencillo y común es al actualizar o interactuar con grupos de usuarios. Si tiene solicitudes que actualizan usuarios relacionados (como agregar miembros a equipos o actualizar todos los participantes de una actividad), no especificar un orden puede significar que si dos actividades simultáneas intentan actualizar los mismos usuarios, puede terminar con el siguiente comportamiento, lo que da como resultado un interbloqueo:
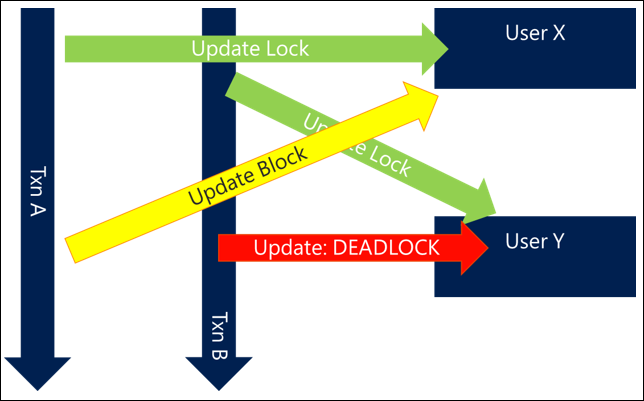
- Transacción A intenta actualizar el usuario X y, a continuación, el usuario Y
- La transacción B intenta actualizar el usuario Y y, a continuación, el usuario X
Dado que ambas solicitudes comienzan juntas, la transacción A puede obtener un bloqueo sobre el usuario X y la transacción B puede obtener un bloqueo sobre el usuario Y, pero tan pronto como cada uno de ellos intenta obtener un bloqueo sobre el otro usuario, se bloquean entre sí y luego se produce un interbloqueo.
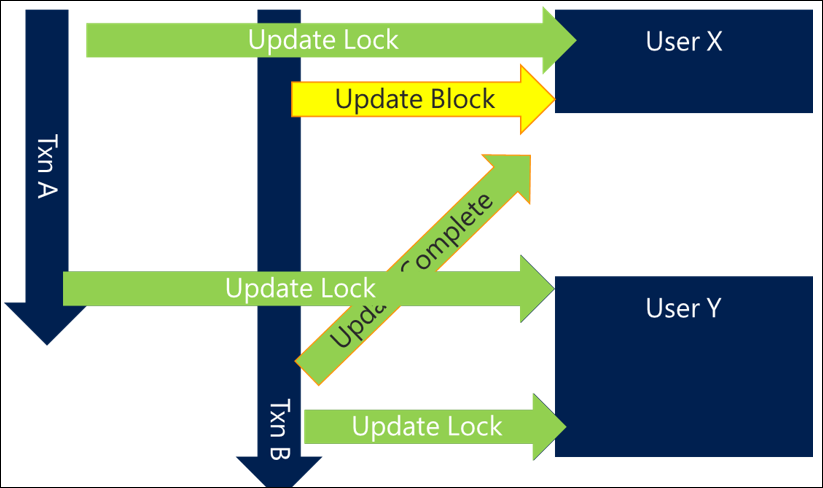
Simplemente ordenando los recursos a los que accede de forma coherente, puede evitar muchas situaciones de interbloqueo. El mecanismo de ordenación a menudo no es importante siempre que sea coherente y se puede hacer lo más eficaz posible. Por ejemplo, ordenar los usuarios por nombre o incluso por GUID puede garantizar al menos un nivel de coherencia que evite interbloqueos.
En un escenario con este enfoque, la transacción A obtendría el usuario X, pero la transacción B también intentaría obtener ahora el usuario X en lugar del usuario Y primero. Aunque esto significa que la transacción B se bloquea hasta que se completa la transacción A, este escenario evita el interbloqueo y se completa correctamente.
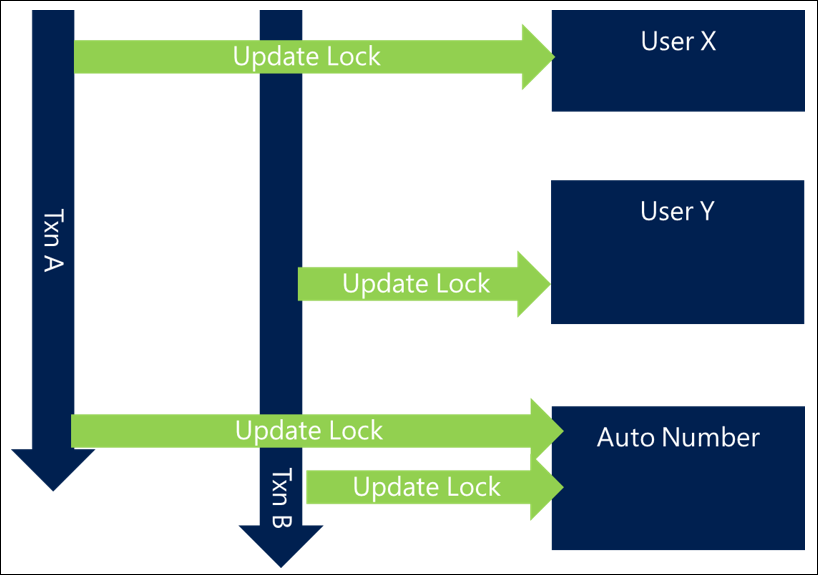
En escenarios más complejos y eficientes, puede suceder que se bloqueen primero a los usuarios menos referenciados y, al final, a los usuarios más frecuentemente referenciados, lo que lleva al siguiente patrón de diseño.
Mantener bloqueos contenciosos durante un período más corto
Hay escenarios, como el enfoque de numeración automática, en el que no hay forma de evitar que haya un recurso muy controvertido que se deba bloquear. En ese caso, no se puede evitar el problema de bloqueo, pero se puede minimizar.
Cuando tiene recursos muy disputados, un buen diseño es no incluir la interacción con ese recurso en el punto funcionalmente lógico del proceso, pero mover la interacción con él a lo más cerca posible del final de la transacción.
Con este enfoque, aunque todavía habrá algún bloqueo en este recurso, reduce la cantidad de tiempo que el recurso está bloqueado y, por lo tanto, disminuye la probabilidad y el tiempo en que otras solicitudes se bloquean mientras esperan el recurso.
Reducir la longitud de las transacciones
De forma similar, un bloqueo solo se convierte en un problema de bloqueo si dos procesos necesitan acceso al mismo recurso al mismo tiempo. Cuanto menor sea la transacción que contiene un bloqueo, menos probable es que dos procesos, incluso si acceden al mismo recurso, lo necesitarán exactamente al mismo tiempo y provocarán una colisión. Cuanto menos tiempo se mantengan las transacciones, será menos probable que el bloqueo se convierta en un problema.
En el ejemplo siguiente, se toman los mismos bloqueos, pero el procesamiento adicional dentro de la transacción hace que se prolongue la duración total de la transacción, lo cual conduce a solicitudes superpuestas para los mismos recursos. Esto significa que el bloqueo se produce y cada solicitud es más lenta en general.
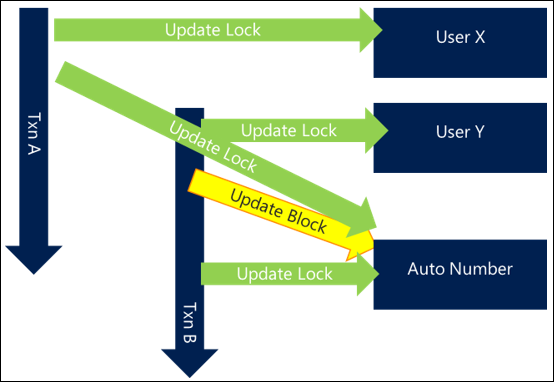
Al acortar la longitud general de la transacción, la primera transacción completa y libera sus bloqueos antes de que se inicie la segunda solicitud, lo que significa que no hay ningún bloqueo y ambas transacciones se completan de forma eficaz.
Otras actividades dentro de una solicitud que amplían la vida de una transacción pueden aumentar la posibilidad de bloqueo, especialmente cuando hay varias solicitudes superpuestas y pueden dar lugar a un sistema más lento.
Hay muchas maneras de reducir la longitud de la transacción.
Optimización de solicitudes
Cada transacción se compone de una serie de solicitudes de base de datos. Si cada solicitud se realiza lo más eficaz posible, esto reduce la longitud total de una transacción y reduce la probabilidad de colisión.
Revise cada consulta que realice para determinar si:
La consulta solo solicita lo que necesita, por ejemplo, columnas, registros o tipos de entidad.
- Esto maximiza la posibilidad de que se pueda usar un índice para atender eficazmente la consulta.
- Reduce el número de tablas y recursos a los que se debe acceder, lo que reduce la sobrecarga en otros recursos del servidor de bases de datos y reduce el tiempo de consulta.
- Evita posibles bloqueos en recursos que no necesitas, especialmente cuando se solicita una unión a otra tabla que podría evitarse o es innecesaria.
Existe un índice disponible para ayudar a la consulta, realiza la consulta de manera eficiente y se lleva a cabo una búsqueda de índice en lugar de un escaneo.
Cabe destacar que la introducción de un índice no evita bloquear la creación o actualización de registros en la tabla subyacente. Las entradas de los índices también se bloquean cuando el registro relacionado se actualiza a medida que el propio índice está sujeto a cambios. La existencia de índices no evita este problema por completo.
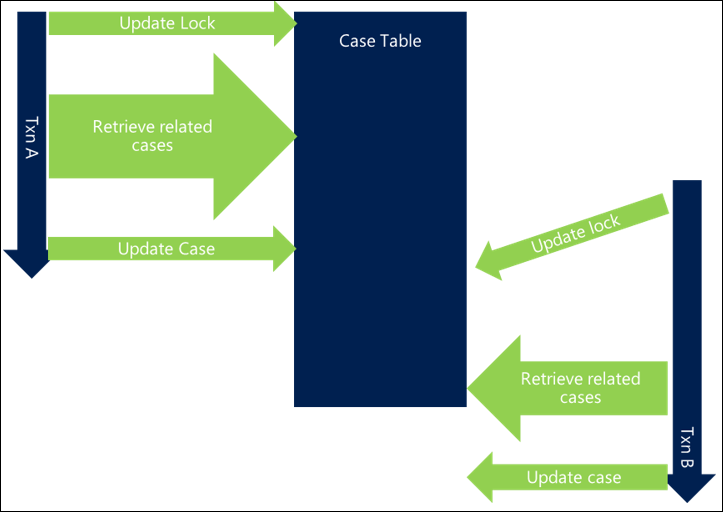
En el ejemplo siguiente, la recuperación de casos relacionados no está optimizada y se agrega a la longitud general de la transacción, lo que introduce el bloqueo entre subprocesos.
Al optimizar la consulta, hay menos tiempo dedicado a realizarla y la posibilidad de colisión es menor, lo que reduce el bloqueo.
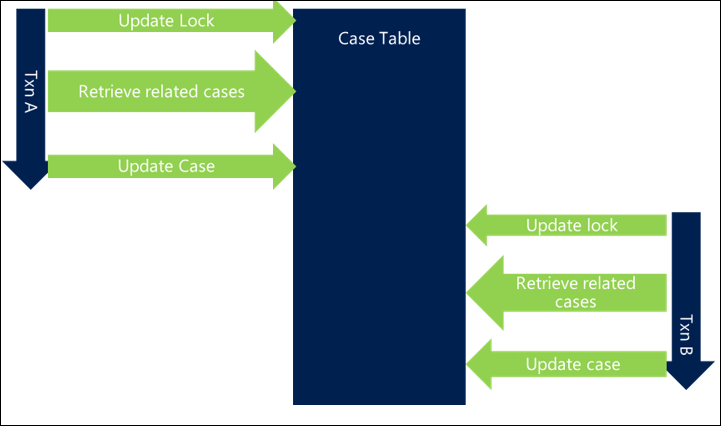
Asegúrese de que el servidor de bases de datos puede procesar la consulta de la forma más eficaz posible, lo que puede reducir significativamente el tiempo total de las transacciones y reducir el potencial de bloqueo.
Reducción de la cadena de eventos
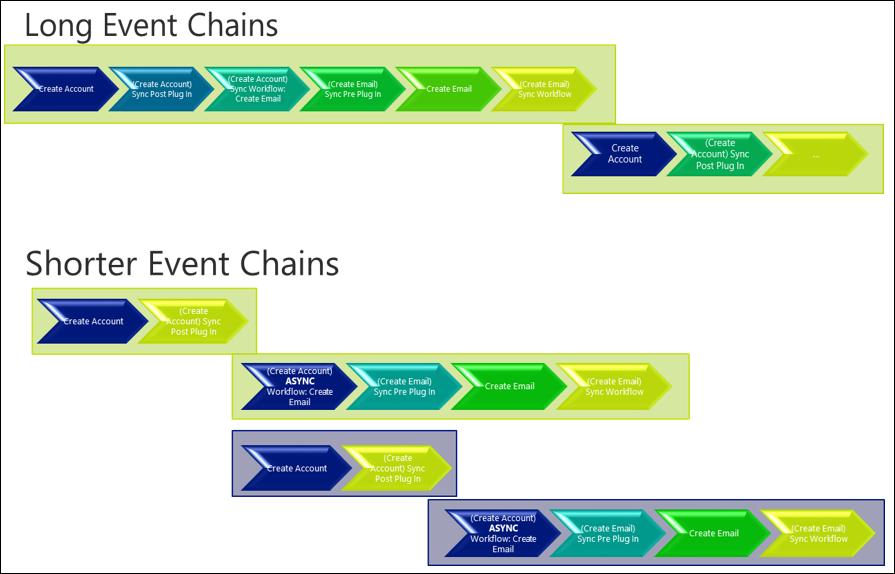
Como se mostró en ejemplos anteriores, las consecuencias de cadenas largas de eventos relacionados pueden tener un impacto material en el tiempo de transacción general y, por lo tanto, se produce el potencial de bloqueo. Esto es especialmente el caso cuando se desencadenan complementos y flujos de trabajo sincrónicos, que luego desencadenan otras acciones y, a su vez, desencadenan complementos y flujos de trabajo sincrónicos adicionales.
Revisar y diseñar cuidadosamente una implementación para evitar cadenas largas de eventos que se producen sincrónicamente puede ser beneficioso para reducir la longitud total de una transacción. Esto permite liberar los bloqueos aplicados con mayor rapidez y reducir los posibles bloqueos.
También reduce la probabilidad de que los bloqueos secundarios se conviertan en un problema importante. En el ejemplo de numeración automática en la creación de cuentas, el problema principal inicialmente es el acceso a la tabla de numeración automática, pero cuando se realizan muchas acciones diferentes en una secuencia, una obstrucción secundaria, como las actualizaciones de un registro de usuario relacionado, también podría empezar a exponerse. Una vez implicados varios recursos impugnados, evitar el bloqueo se vuelve aún más difícil.
Teniendo en cuenta si algunas actividades deben ser sincrónicas o asincrónicas pueden significar que se logran las mismas actividades, pero tienen menos impacto inicial. Especialmente para acciones más prolongadas o aquellas que dependen de recursos muy disputados, separarlas de la transacción principal al realizarlas en una acción asincrónica puede tener ventajas significativas. Este método no funcionará si la acción necesita completarse o fracasar en el paso más general de la plataforma, como actualizar un informe de crimen de la policía con el siguiente valor de numeración automática asegurando que se mantiene un esquema de numeración continua y secuencial. En esos escenarios se deben adoptar otros enfoques para minimizar el impacto.
Como se muestra en el ejemplo siguiente, simplemente moviendo algunas acciones a un proceso asincrónico, lo que significa que las acciones se realizan fuera de la transacción de la plataforma, pueden significar que la longitud de la transacción es más corta y la posibilidad de que aumente el procesamiento simultáneo.
Evitar varias actualizaciones en el mismo registro
Al diseñar varias capas de actividad funcional, aunque se recomienda desglosar las acciones necesarias para los flujos lógicos y fácilmente seguidos de la actividad, en muchos casos esto provocaría varias actualizaciones independientes en el mismo registro.
En el escenario de gestión de casos, actualizar primero un caso con un propietario predeterminado en función del cliente contra el cual se genera y luego tener un proceso independiente para enviar automáticamente las comunicaciones a ese cliente y actualizar la última fecha de contacto en el caso es algo perfectamente lógico desde el punto de vista funcional.
Sin embargo, el desafío es que esto significa que hay varias solicitudes a Dataverse para actualizar el mismo registro, lo que tiene muchas implicaciones:
- Cada solicitud es una actualización de plataforma independiente, lo que agrega carga general al servidor de Dataverse y agrega tiempo a la longitud general de la transacción, lo que aumenta la posibilidad de bloqueo.
- También significa que el registro del caso se bloqueará desde la primera acción realizada en ese caso, manteniéndose el bloqueo en todo el resto de la transacción. Si varios procesos paralelos acceden al caso, esto podría provocar el bloqueo de otras actividades.
La consolidación de las actualizaciones del mismo registro en un solo paso de actualización y, más adelante en la transacción, puede tener una ventaja significativa para la escalabilidad general, especialmente si el registro es muy disputado o es accedido por varias personas rápidamente después de su creación, por ejemplo, en el caso de un expediente.
Decidir si consolidar las actualizaciones del mismo registro en un único proceso se basaría en el equilibrio de la complejidad de la implementación frente al potencial de conflicto que podrían introducir actualizaciones independientes. Pero para los sistemas de gran volumen, esto puede ser beneficioso para los recursos altamente demandados.
Solo actualice aquellas cosas que necesite
Aunque es importante no reducir la ventaja de un sistema de Dataverse excluyendo las actividades que serían beneficiosas, a menudo se realizan solicitudes para incluir personalizaciones que agregan poco valor empresarial, pero impulsan la complejidad técnica real.
Si cada vez que creamos una tarea también actualizamos el registro del usuario con el número de tareas que actualmente tienen asignadas, esto podría introducir un nivel secundario de bloqueo, ya que el registro del usuario también estaría muy disputado. Agregaría otro recurso que cada solicitud tendría que bloquear o por el que esperar, pese a que no fuera fundamental para la acción. En ese ejemplo, considere usted cuidadosamente si almacenar el recuento de tareas asociadas al usuario es importante o si el recuento se puede calcular a petición o almacenarse en otro lugar, utilizando capacidades de jerarquía y de campos acumulativos en Dataverse de forma nativa.
Como se mostrará más adelante, la actualización de los registros de usuario del sistema puede tener consecuencias negativas desde una perspectiva de escalabilidad.
Varias personalizaciones desencadenadas en el mismo evento
Desencadenar varias acciones en el mismo evento puede dar lugar a una mayor probabilidad de colisión que por la naturaleza de las solicitudes que esas acciones probablemente interactúen con los mismos objetos relacionados o con el objeto primario.
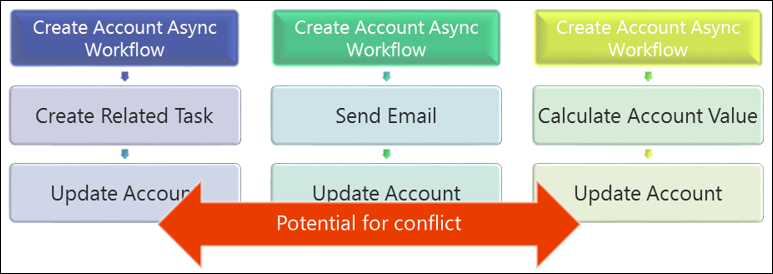
Este es un patrón que debe considerarse cuidadosamente o evitarse, ya que es fácil pasar por alto conflictos, especialmente cuando diferentes personas implementan los distintos procesos.
Cuándo usar diferentes tipos de personalización
Cada tipo de personalización tiene implicaciones diferentes para su uso. En la tabla siguiente se resaltan algunos patrones comunes, cuando se debe tener en cuenta y usar cada uno, y cuando no es adecuado para su uso.
A menudo, es posible que deba considerarse un compromiso entre diferentes comportamientos, por lo que esto proporciona orientación sobre algunas de las características y escenarios comunes que se deben tener en cuenta, pero cada escenario debe evaluarse y se elija el enfoque adecuado en función de todos los factores pertinentes.
| Fase previa y posterior | Sincronización/asincronización | Tipo de personalización | Cuándo usar | Cuándo no usar |
|---|---|---|---|---|
| Validación previa | Sincronizar | Complemento | Validación a corto plazo de valores de entrada | Acciones de larga duración. Cuando se crean elementos relacionados que se deben revertirse si los pasos posteriores no se realizan correctamente. |
| Operación previa | Sincronizar | Flujo de trabajo/Complemento | Validación a corto plazo de los valores de entrada. Cuando se crean elementos relacionados que se deben revertirse como parte de un error en el paso de la plataforma. |
Acciones de larga duración. Cuando se crea un elemento y el GUID resultante deberá ser almacenado según el elemento que creará o actualizará el paso de la plataforma. |
| Operación posterior | Sincronizar | Flujo de trabajo o complemento | Acciones corta ejecución que sigan naturalmente el paso de la plataforma y necesiten revertirse si se producen errores en los pasos posteriores, por ejemplo, la creación de una tarea para el propietario de una cuenta recién creada. Creación de los elementos relacionados que necesita el GUID del elemento creado y que deben revertir el paso de la plataforma en caso de error. |
Acciones de larga duración. Si el error no debería afectar a la terminación del paso de la canalización de la plataforma. |
| No en la canalización de eventos | Async | Flujo de trabajo o complemento | Acciones de longitud media que afectarían a la experiencia del usuario. Acciones que no se pueden revertir de todos modos en caso de error. Acciones que no deberían forzar la reversión del paso de la plataforma en caso de error. |
Acciones que se ejecutan durante mucho tiempo. No se deben administrar en Dataverse. Acciones de bajo costo. La sobrecarga de generar un comportamiento asincrónico para acciones de bajo costo puede ser prohibitiva; siempre que sea posible, realice estas tareas sincrónicamente y evite la sobrecarga del procesamiento asincrónico. |
| N/A Toma el contexto de la ubicación desde donde se invoca |
Acciones personalizadas | Combinaciones de acciones iniciadas desde un origen externo, por ejemplo, desde un recurso web | Cuando se desencadena siempre en respuesta a un evento de plataforma, use complemento o flujo de trabajo en estos casos. |
Los complementos o flujos de trabajo no son mecanismos de procesamiento por lotes
Las acciones de volumen o de ejecución prolongada no están diseñadas para ejecutarse desde complementos o flujos de trabajo. Dataverse no está pensado para ser una plataforma de proceso y, especialmente, no está pensado como controlador para impulsar grandes grupos de actualizaciones no relacionadas.
Si tiene que hacerlo, descargue y ejecute desde un servicio independiente, como un rol de trabajo de Azure.
Configuración de la seguridad
Un área de escalación común es la escalabilidad de la configuración de la seguridad. Se trata de una operación costosa, por lo que cuando se hace en volumen siempre puede causar desafíos si no se entiende y se considera cuidadosamente.
Configuración del equipo
- Agregue siempre usuarios en el mismo orden: evite interbloqueos.
- Actualice solo a los usuarios si necesitan actualizarse: evite invalidar las memorias caché de los usuarios innecesariamente.
Propietario v. Acceder a Teams
- Si los equipos de los usuarios cambian periódicamente, tenga cuidado de usar los equipos propietarios en gran medida; cada vez que cambian, invalidan la memoria caché del usuario en el servidor web.
- Lo ideal es realizar cambios cuando el usuario no está trabajando, para reducir el impacto, como durante la noche.
Gran cantidad de pertenencia a los equipos/Unidades de negocio
- Tenga en cuenta los escenarios con una gran cantidad de equipos o unidades de negocio (BU) que aumentan la complejidad del cálculo.
Comportamiento en cascada
- Considere el uso compartido en cascada, por ejemplo, la asignación
Actualización cuidadosa de los registros de usuario
- No actualice periódicamente los registros de usuario del sistema a menos que haya cambiado algo fundamental, ya que esto obliga a que la memoria caché del usuario se vuelva a cargar y se vuelvan a calcular los privilegios de seguridad, una actividad costosa.
- No use el usuario del sistema para registrar cuántas actividades abiertas tiene el usuario, por ejemplo
Acciones relacionadas con el diagrama
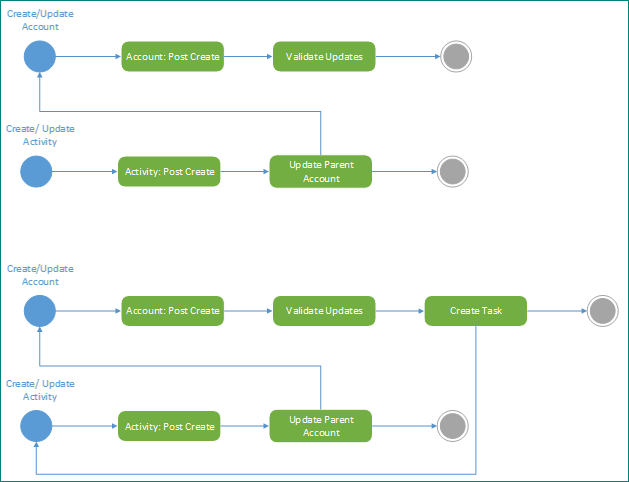
Una actividad que es beneficiosa como medida preventiva y una herramienta para diagnosticar problemas de bloqueo es diagramar las acciones relacionadas desencadenadas en la plataforma dataverse. Al hacerlo, ayuda a resaltar tanto dependencias intencionadas como involuntarias y desencadenadores en el sistema. Si no puede hacerlo para la solución, es posible que no tenga una idea clara de lo que realmente hace la implementación. La creación de este diagrama puede exponer consecuencias no deseadas y es recomendable en cualquier momento en una implementación.
En el ejemplo siguiente se resalta cómo funcionan perfectamente dos procesos inicialmente juntos, pero en mantenimiento continuo, la adición de un nuevo paso para crear una tarea puede crear un bucle no deseado. El uso de esta técnica de documentación puede resaltarlo en la fase de diseño y evitar que esto afecte al sistema.
Revisión de la telemetría y los seguimientos
Puede configurar un entorno de Application Insights para recibir telemetría sobre los diagnósticos y el rendimiento capturados por la plataforma Dataverse. Aprenda a analizar la telemetría de Dataverse con Application Insights
Cuando tenga un entorno de Application Insights, puede utilizar la interfaz Microsoft.Xrm.Sdk.PluginTelemetry.ILogger en su código del complemento para escribir telemetría en Application insights. Aprenda a escribir telemetría en el recurso de Application Insights mediante ILogger.
Cuando se producen ciertos errores, el uso de los archivos de seguimiento del servidor para comprender dónde pueden producirse problemas relacionados en la plataforma también puede ser útil. Más información: Uso del seguimiento
Resumen
El contenido de Diseño de Personalización Escalable en Dataverse y los artículos posteriores Transacciones de Base de Datos, Problemas de Concurrencia y este han descrito los siguientes conceptos con ejemplos y estrategias que le ayudan a comprender cómo diseñar e implementar personalizaciones escalables para Dataverse.
Algunos aspectos clave que hay que recordar incluyen lo siguiente:
Bloqueos y transacciones
- Los bloqueos y las transacciones son esenciales para un sistema correcto
- Pero cuando se usa incorrectamente, puede provocar problemas
Restricciones de plataforma
- Las restricciones de plataforma a menudo se muestran en forma de errores
- Pero rara vez es la restricción la causa del problema
- Están ahí para proteger la plataforma y otras actividades de sufrir las consecuencias
Diseño para uso de transacciones
- Si las implementaciones están diseñadas teniendo en cuenta el comportamiento de las transacciones, esto puede provocar una mayor escalabilidad y mejorar el rendimiento del usuario.