Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
[Este artigo é a documentación de prelanzamento e está suxeito a cambios.]
O novo modelo semántico optimizado de DirectLake permite unha análise de procesos máis rápida e eficiente en canto á memoria. Ao aforrar memoria, podes analizar procesos máis grandes e aforrar custos ao usar capacidades de Fabric máis pequenas para realizar análises. Ademais, utilízase unha estrutura de datos de modelo semántico máis intuitiva, que permite afondar na información con menos tempo e esforzo. Power BI
Importante
- Esta é unha funcionalidade de vista previa.
- As funcionalidades de vista previa non se deseñaron para uso de produción e poden ter funcionalidade restrinxida. Estas funcionalidades están dispoñibles antes da versión oficial para que os clientes poidan obter acceso a elas rápido e fornecer comentarios.
- Para obter máis información, consulta as nosas condicións de vista previa.
Descrición do modelo semántico
Cando se publica un proceso no espazo de traballo de Fabric, créase un novo modelo semántico e un informe correspondente. Esta captura de pantalla é un exemplo dunha estrutura de modelo semántico publicada en Fabric.
Selecciona a lupa na esquina inferior dereita da imaxe para ampliala.

Relacións
As relacións necesarias para o filtrado e a interconectividade dos elementos visuais están predefinidas no modelo de datos publicado. Non é necesario crear manualmente máis relacións a menos que haxa outras fontes de datos conectadas. Para este escenario, use o modelo semántico composto e constrúa relacións sobre ese modelo. Power BI
Resumo do modelo de datos
Desde unha perspectiva lóxica, o modelo de datos consta de moitos subconxuntos de entidades como se describe no primeiro parágrafo desta sección.
- Datos do proceso: Todos os datos relacionados co proceso sen filtrar nin as medidas calculadas
- Datos visuais: Entidades que fornecen datos precalculados necesarios para a visualización de elementos visuais personalizados de minería de procesos
- Entidades de axuda: Outras entidades necesarias para Power BI
A continuación móstrase unha breve descrición dos subconxuntos e das entidades incluídas.
Datos do proceso
O contido das entidades de datos de proceso cambia en escenarios específicos.
- Cando se actualizan os datos do modelo de proceso
- Cando se crea unha nova vista
- Cando se crea unha nova métrica personalizada
- Cando un usuario cambia a definición de filtrado en calquera vista de proceso
Traballar con estas entidades permíteche:
- Acceder aos datos brutos do proceso
- Datos de proceso influenciados polos filtros aplicados
- Acceda ás medidas calculadas en función dos filtros aplicados
| Entidad | Descripción |
|---|---|
| Casos | Lista de todos os casos e os seus atributos no proceso. Cada caso contén unha visualización única de ID de caso e valores para cada un dos atributos do caso, tal e como se define no paso de configuración da asignación. Combínao coa entidade CaseMetrics para obter información completa do caso. |
| Eventos | Lista de todos os atributos do evento no proceso. Cada evento ten un índice identificador de evento único e valores para cada un dos atributos do evento, tal e como se define no paso de configuración do mapeo. Combínao coa entidade ProcessMapMetrics filtrada por Is_Node columna para obter información completa do evento. |
| CaseMetrics | A entidade contén todas as métricas a nivel de caso relacionadas cunha combinación específica de caso e vista. Engádense a esta entidade as métricas personalizadas a nivel de caso definidas na Power Automate aplicación de escritorio Process Mining. |
| AtributosMetadatos | A entidade contén a definición de todos os atributos a nivel de caso/evento tal e como se definen na importación dos datos do rexistro de eventos no modelo de proceso. Inclúe o seu tipo de datos, tipo de atributo e nivel de atributo, xa sexa caso ou evento. |
| Atributos de minería | Contén valores dos atributos de minería dispoñibles. Pódese configurar unha vista de proceso para observalo desde diferentes perspectivas segundo o atributo de minería seleccionado. Se non hai ningún outro atributo de minería dispoñible, a entidade mantén os valores do atributo Activity . |
| Visualizacións | Lista de vistas dispoñibles (publicadas) creadas na aplicación de escritorio Process Mining. Power Automate Só se publican no conxunto de datos as vistas de procesos públicos. As entradas pódense usar para filtrar informes, páxinas de informes e elementos visuais para visualizar só os datos da vista de proceso específica. |
| Variantes | A entidade mantén as relacións entre as variantes e as vistas do proceso. Inclúese un rexistro se unha variante concreta se inclúe nunha vista despois de ter en conta os criterios de filtrado. |
Datos visuais
As entidades de datos visuais só se recalculan cando hai unha actualización de datos para o modelo de proceso.
| Entidad | Descripción |
|---|---|
| Métricas de mapa de procesos | Medidas agregadas para todos os nodos e transicións no modelo de proceso que son necesarias para a visualización no visual personalizado do mapa de procesos. Esta entidade combina información de eventos (nó) e información de bordos (transición); para usar os eventos ou bordos nos teus outros elementos visuais, filtra polo valor na columna Is_Node .
Engádense a esta entidade as métricas personalizadas de nivel de evento definidas na Power Automate aplicación de escritorio Process Mining. |
Outras entidades
| Entidad | Descripción |
|---|---|
| Táboa de localización | Táboa interna empregada para fins de localización. |
Power BI modelo composto
Recomendámosche que uses o modelo composto sobre o modelo semántico publicado por Process Mining e que crees alí as modificacións necesarias para estes escenarios: Power BI Power Automate
- Necesitas crear máis fontes de datos
- Necesitas crear máis entidades
- Necesitas crear máis relacións
- Necesitas crear máis consultas DAX (expresións de análise de datos) personalizadas
Importante
O modelo semántico créase no modo de acceso DirectLake, pero a súa opción está definida como Automático. Esta configuración significa que o uso de consultas DAX non óptimas ou a configuración incorrecta dun modelo composto pode provocar unha volta ao modo DirectQuery. Isto significa que o teu informe non fallará, pero é posible que experimentes un rendemento inferior.
Para saber máis sobre a creación Power BI modelos de datos compostos sobre os modelos semánticos de DirectLake, vaia a: Construción de modelos compostos sobre un modelo semántico ou un modelo .
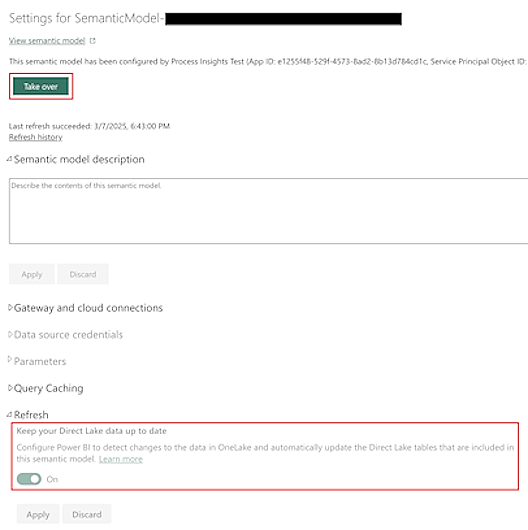
Actualización do modelo semántico
Por defecto, o modelo semántico proporcionado por Power Automate Minería de procesos mantense actualizada automaticamente.
Para conxuntos de datos grandes, a actualización dos datos das táboas subxacentes en OneLake pode levar máis tempo. Isto pode causar posibles inconsistencias no informe. Aínda que finalmente haxa coherencia ao final da actualización dos datos (o modelo semántico actualízase explicitamente), pode que queiras eliminar as posibles inconsistencias intermedias desactivando a marca Manter os datos de Direct Lake actualizados na pantalla Configuración do modelo semántico.
Antes de actualizar esta pantalla, debes facerte cargo do modelo semántico seleccionando Asumir o control na parte superior da pantalla Configuración .