DirectQuery en Power BI
En Power BI Desktop o el servicio Power BI, puede conectarse a muchos orígenes de datos diferentes de diversas maneras. Puede importar datos a Power BI, que es la forma más común de obtener datos. También puede conectarse directamente a algunos datos en su repositorio de origen original, que se denomina DirectQuery. En este artículo se describen principalmente las funcionalidades de DirectQuery.
En este artículo se describe:
- Las distintas opciones de conectividad de datos de Power BI.
- Instrucciones sobre cuándo usar DirectQuery en lugar de importar.
- Limitaciones e implicaciones del uso de DirectQuery.
- Recomendaciones para usar DirectQuery correctamente.
- Cómo diagnosticar problemas de rendimiento de DirectQuery.
El artículo se centra en el flujo de trabajo de DirectQuery al crear un informe en Power BI Desktop, pero también trata la conexión a través de DirectQuery en el servicio Power BI.
Nota
DirectQuery también es una característica de SQL Server Analysis Services. Esa característica comparte muchos detalles con DirectQuery en Power BI, pero también hay diferencias importantes. Este artículo describe principalmente DirectQuery con Power BI, no con SQL Server Analysis Services.
Para obtener más información sobre el uso de DirectQuery con SQL Server Analysis Services, consulte Uso de modelos compuestos en Power BI Desktop. También puedes descargar el PDF DirectQuery en SQL Server 2016 Analysis Services.
Modos de conectividad de datos de Power BI
Power BI se conecta a un gran número de fuentes de datos variadas, como:
- Servicios en línea como Salesforce y Dynamics 365.
- Bases de datos como SQL Server, Access y Amazon Redshift.
- Archivos simples en Excel, JSON y otros formatos.
- Otros orígenes de datos, como Spark, sitios web y Microsoft Exchange.
Puede importar datos de estos orígenes en Power BI. Para algunos orígenes, también puede conectarse mediante DirectQuery. Para obtener un resumen de los orígenes que admiten DirectQuery, consulte Orígenes de datos de Power BI. Los orígenes habilitados para DirectQuery son principalmente orígenes que pueden ofrecer un buen rendimiento de consultas interactivas.
Debe importar datos a Power BI siempre que sea posible. La importación aprovecha el motor de consultas de alto rendimiento de Power BI y ofrece una experiencia completa, altamente interactiva.
Si no puede cumplir sus objetivos mediante la importación de datos, por ejemplo, si los datos cambian con frecuencia y los informes deben reflejar los datos más recientes, considere la posibilidad de usar DirectQuery. DirectQuery solo es viable cuando el origen de datos subyacente puede proporcionar resultados de consulta interactivos en menos de cinco segundos para una consulta agregada típica, y puede controlar la carga de consulta generada. Tenga en cuenta detenidamente las limitaciones e implicaciones del uso de DirectQuery.
Las capacidades de importación y DirectQuery de Power BI evolucionan con el tiempo. Los cambios que proporcionan más flexibilidad al usar los datos importados le permiten importar con más frecuencia y eliminar algunos de los inconvenientes de usar DirectQuery. Independientemente de las mejoras, el rendimiento del orign de datos subyacente es una consideración importante cuando se utiliza DirectQuery. Si un origen de datos subyacente es lento, el uso de DirectQuery para dicho origen sigue siendo inviable.
En las siguientes secciones se tratan las tres opciones para conectarse a los datos: importación, DirectQuery y conexión dinámica. El resto del artículo se centra en DirectQuery.
Importación de conexiones
Al conectarse a un origen de datos como SQL Server e importar datos en Power BI Desktop, están presentes las siguientes condiciones de conectividad:
Al Obtener datos inicialmente, cada conjunto de tablas que seleccione define una consulta que devuelve un conjunto de datos. Puede editar esas consultas antes de cargar los datos, por ejemplo para aplicar filtros, agregar los datos o unir tablas diferentes.
Una vez cargados, todos los datos definidos por las consultas se importan a la caché de Power BI.
La creación de un objeto visual dentro de Power BI Desktop consulta los datos almacenados en caché. El almacén de Power BI garantiza que la consulta sea rápida y que todos los cambios en el objeto visual se reflejen inmediatamente.
Los objetos visuales no reflejan los cambios en los datos subyacentes del almacén de datos. Debe volver a importar para actualizar los datos.
Al publicar el informe en el servicio Power BI como un archivo .pbix se crea y se carga un modelo semántico que incluye los datos importados. A continuación, puede programar la actualización de los datos, por ejemplo, volver a importarlos todos los días. En función de la ubicación del origen de datos original, podría ser necesario configurar una puerta de enlace de datos local para la actualización.
Al abrir un informe existente o crear uno nuevo en el servicio Power BI, se vuelven a consultar los datos importados, lo que garantiza la interactividad.
Puede anclar objetos visuales o páginas de informe completas como iconos de panel en el servicio Power BI. Los iconos se actualizarán automáticamente cada vez que se actualice el modelo semántico subyacente.
Conexiones de DirectQuery
Cuando se usa DirectQuery para conectarse a un origen de datos en Power BI Desktop, están presentes las siguientes condiciones de conectividad de datos:
Use Obtener datos para seleccionar el origen. En el caso de los orígenes relacionales, puede seguir seleccionando un conjunto de tablas que definan una consulta que devuelva lógicamente un conjunto de datos. En el caso de orígenes multidimensionales como SAP Business Warehouse (SAP BW), seleccione solo el origen.
Tras la carga, no se importa ningún dato al almacén de Power BI. En su lugar, cuando construye un objeto visual, Power BI Desktop envía consultas al origen de datos subyacente para recuperar los datos necesarios. El tiempo que se tarda en actualizar el objeto visual depende del rendimiento del origen de datos subyacente.
Los cambios que se hagan en los datos subyacentes no se reflejan de inmediato en los objetos visuales existentes. Todavía es necesario actualizar. Power BI Desktop vuelve a enviar las consultas necesarias para cada objeto visual y actualiza el objeto visual según sea necesario.
Al publicar el informe en el servicio Power BI se crea y se carga un modelo semántico, igual que para la importación. Sin embargo, ese modelo semántico no incluye datos.
Al abrir un informe existente o crear uno nuevo en el servicio Power BI, se consulta el origen de datos subyacente para recuperar los datos necesarios. En función de la ubicación del origen de datos original, podría ser necesario configurar una puerta de enlace de datos local para obtener los datos.
Puede anclar objetos visuales, o páginas de informe completas, como iconos del panel. Para que la apertura de un panel sea rápida, los iconos se actualizan automáticamente según un calendario, por ejemplo cada hora. Puede controlar la frecuencia de actualización en función de la frecuencia con la que cambian los datos y la importancia de ver los datos más recientes.
Cuando abra un panel, los iconos reflejarán los datos en el momento de la última actualización, no necesariamente los cambios más recientes efectuados en el origen subyacente. Puede actualizar un panel abierto para asegurarse de que está actualizado.
Conexiones dinámicas
Al conectarse a SQL Server Analysis Services, puede optar por importar los datos o usar una conexión dinámica con el modelo de datos seleccionado. El uso de una conexión dinámica es similar a DirectQuery. No se importan datos y se consulta el origen de datos subyacente para actualizar los visuales.
Por ejemplo, al usar la importación para conectarse a SQL Server Analysis Services, defina una consulta en el origen de SQL Server Analysis Services externo e importe los datos. Si realiza una conexión dinámica, no define ninguna consulta y todo el modelo externo se muestra en la lista de campos.
Esta situación también se aplica cuando se conecta a los siguientes orígenes, excepto que no hay ninguna opción para importar los datos:
Modelos semánticos de Power BI, por ejemplo conectándose a un modelo semántico de Power BI que ya esté publicado en el servicio, para crear un nuevo informe sobre él.
Microsoft Dataverse.
Cuando publica informes de SQL Server Analysis Services que utilizan conexiones dinámicas, el comportamiento en el servicio Power BI es similar al de los informes DirectQuery en los siguientes aspectos:
Al abrir un informe existente o crear uno nuevo en el servicio Power BI, se consulta el origen subyacente de SQL Server Analysis Services, lo que posiblemente requiera una puerta de enlace de datos local.
Los iconos de panel se actualizan automáticamente según una programación, por ejemplo cada hora.
Una conexión dinámica también difiere de DirectQuery de varias maneras. Por ejemplo, las conexiones dinámicas siempre pasan la identidad del usuario que abre el informe al origen subyacente de SQL Server Analysis Services.
Casos de uso de DirectQuery
La conexión con DirectQuery puede ser útil en los escenarios siguientes. En varios de estos casos, es necesario o beneficioso dejar los datos en su ubicación de origen original.
DirectQuery en Power BI ofrece las mayores ventajas en los siguientes escenarios:
- Los datos cambian con frecuencia y necesita informes casi en tiempo real.
- Debe controlar datos de gran tamaño sin tener que agregarlos previamente.
- El origen subyacente define y aplica reglas de seguridad.
- Se aplican restricciones de soberanía de datos.
- El origen de datos es un origen multidimensional que contiene medidas (como SAP BW).
Los datos cambian con frecuencia y necesita informes casi en tiempo real
Puede actualizar los modelos con los datos importados como máximo una vez por hora o con mayor frecuencia con las suscripciones de Power BI Pro o Power BI Premium. Si los datos cambian constantemente y es necesario que en los informes se muestren los más recientes, es posible que el uso de la importación con actualización programada no satisfaga sus necesidades. Puede transmitir datos en secuencias directamente a Power BI, aunque existen límites en los volúmenes de datos que se admiten en este caso.
El uso de DirectQuery significa que cuando se abre o actualiza un informe o panel siempre se muestran los datos más recientes en el origen. Los iconos de panel también se pueden actualizar con más frecuencia (incluso cada 15 minutos).
El volumen de datos es muy grande
Si los datos son muy grandes, no es factible importarlos todos. DirectQuery no requiere una gran transferencia de datos, porque consulta los datos in situ. Sin embargo, los datos de gran tamaño también pueden hacer que el rendimiento de las consultas contra dicho origen subyacente sea demasiado lento.
No siempre tiene que importar los datos detallados completos. El Editor de Power Query facilita la agregación previa de datos durante la importación. Técnicamente, es posible importar exactamente los datos agregados que necesita para cada objeto visual. Aunque DirectQuery es el enfoque más simple para los datos de gran tamaño, la importación de datos agregados puede ofrecer una solución si el origen de datos subyacente es demasiado lento para DirectQuery.
Estos detalles se relacionan con el uso de Power BI por sí solo. Para obtener más información sobre el uso de modelos grandes en Power BI, consulte modelos semánticos grandes en Power BI Premium. No hay ninguna restricción sobre la frecuencia con que se pueden actualizar los datos.
El origen subyacente define reglas de seguridad
Cuando importa datos, Power BI se conecta al origen de datos utilizando las credenciales de Power BI Desktop del usuario actual, o las credenciales configuradas para la actualización programada desde el servicio Power BI. Al publicar y compartir informes que han importado datos, debe tener cuidado de compartirlos solo con los usuarios autorizados para ver los datos, o debe definir la seguridad a nivel de fila como parte del modelo semántico.
DirectQuery permite que las credenciales de un visor de informes pasen al origen subyacente, que aplica reglas de seguridad. DirectQuery admite el inicio de sesión único (SSO) en los orígenes de datos Azure SQL y, a través de una puerta de enlace de datos, en los servidores SQL locales. Para más información, consulte Introducción al inicio de sesión único (SSO) para puertas de enlace de datos locales en Power BI.
Se aplican restricciones de soberanía de datos
Algunas organizaciones tienen directivas en torno a la soberanía de datos, lo que significa que los datos no pueden salir de las instalaciones de la organización. Estos datos presentan problemas para soluciones basadas en la importación de datos. Con DirectQuery, los datos permanecen en la ubicación de origen subyacente. Sin embargo, incluso con DirectQuery, el servicio Power BI mantiene algunas cachés de datos en el nivel de objeto visual, debido a la actualización programada de los iconos.
El origen de datos subyacente usa medidas
Un origen de datos subyacente, como SAP HANA o SAP BW, contiene medidas. Las medidas significan que los datos importados ya están en un determinado nivel de agregación, tal como se define en la consulta. Un objeto visual que solicita datos en un agregado de nivel superior, como TotalSales por año, agrega aún más el valor agregado. Esta agregación está bien para medidas de adición, como Sum y Min, pero puede ser un problema para las que no son de adición, como Average y DistinctCount.
Obtener fácilmente los datos agregados correctos necesarios para un objeto visual directamente desde el origen requiere el envío de consultas por objeto visual, como en DirectQuery. Cuando se conecta a SAP BW, la elección de DirectQuery permite este tratamiento de las medidas. Para obtener más información, consulte DirectQuery y SAP BW.
Actualmente DirectQuery sobre SAP HANA trata los datos igual que un origen relacional y produce un comportamiento similar a la importación. Para obtener más información, consulte DirectQuery y SAP HANA.
Limitaciones de DirectQuery
El uso de DirectQuery tiene algunas implicaciones potencialmente negativas. Algunas de estas limitaciones difieren ligeramente en función del origen exacto que use. En las secciones siguientes se enumeran las implicaciones generales del uso de DirectQuery y las limitaciones relacionadas con el rendimiento, la seguridad, las transformaciones, el modelado y los informes.
Implicaciones generales
A continuación se indican algunas implicaciones generales y limitaciones del uso de DirectQuery:
Si cambian los datos, debe actualizar para mostrar los datos más recientes. Dado el uso de cachés, no hay garantía de que los objetos visuales muestren siempre los datos más recientes. Por ejemplo, un objeto visual puede mostrar las transacciones realizadas el último día. Un cambio de segmentación podría actualizar el objeto visual para mostrar las transacciones de los últimos dos días, incluidas las transacciones recientes y recién llegadas. Pero devolver la segmentación a su valor original podría provocar que vuelva a mostrar el valor anterior almacenado en caché. Seleccione Actualizar para borrar cualquier caché y actualizar todos los objetos visuales de la página para mostrar los datos más recientes.
Si los datos cambian, no hay garantía de coherencia entre los objetos visuales. los distintos objetos visuales distintos, ya estén en la misma página o en distintas páginas, se pueden actualizar en momentos distintos. Si los datos del origen subyacente cambian, no hay garantía de que cada objeto visual muestre los datos en el mismo momento.
Dado que puede ser necesaria más de una consulta para un mismo objeto visual, por ejemplo, para obtener los detalles y los totales, ni siquiera la coherencia dentro de un mismo objeto visual está garantizada. Garantizar esta coherencia requeriría la sobrecarga de actualizar todos los objetos visuales cada vez que se actualizara alguno, además de utilizar características costosas como el aislamiento de instantáneas en el origen de datos subyacente.
Puede mitigar este problema en gran medida seleccionando Actualizar para actualizar todos los objetos visuales de la página. Incluso para el modo de importación, existe un problema similar de mantenimiento de la coherencia cuando se importan datos de más de una tabla.
Debe actualizar en Power BI Desktop para reflejar los cambios de esquema. Después de publicar un informe, Actualizar en el servicio Power BI actualiza los objetos visuales del informe. Pero si cambia el esquema de origen subyacente, el servicio Power BI no actualiza automáticamente la lista de campos disponibles. Si se eliminan tablas o columnas del origen subyacente, podrían producirse errores de consulta después de la actualización. Para actualizar los campos del modelo para reflejar los cambios, debe abrir el informe en Power BI Desktop y elegir Actualizar.
En cualquier consulta puede aparecer un límite de 1 millón de filas. Hay un límite fijo de 1 millón de filas que puede devolver en una sola consulta al origen subyacente. Por lo general, este límite no tiene implicaciones prácticas, y los objetos visuales no mostrarán tantos puntos. Sin embargo, el límite puede producirse en casos en los que Power BI no optimice completamente las consultas enviadas y solicite algún resultado intermedio que supere el límite.
El límite también puede producirse mientras se crea un objeto virtual en la ruta a un estado final más razonable. Por ejemplo, si se incluye Customer y TotalSalesQuantity se podría alcanzar este límite si hay más de 1 millón de clientes, hasta que aplique algún filtro. El error que devuelve es El conjunto de resultados de una consulta a un origen de datos externa ha superado el tamaño máximo permitido de '1000000' filas.
Nota
Las capacidades Premium permiten superar el límite de un millón de filas. Para obtener más información, vea Número máximo de conjuntos de filas intermedias.
No puede cambiar un modelo de modo importación a modo DirectQuery. Puede cambiar un modelo del modo DirectQuery al modo de importación si importa todos los datos necesarios. No es posible volver al modo DirectQuery, principalmente debido al conjunto de características que el modo DirectQuery no admite. En el caso de los orígenes multidimensionales como SAP BW, tampoco puede pasar del modo DirectQuery al modo de importación, debido al diferente tratamiento de las medidas externas.
Implicaciones de rendimiento y carga
Cuando utilice DirectQuery, la experiencia global dependerá del rendimiento del origen de datos subyacente. Si la actualización de cada objeto visual, por ejemplo, después de cambiar un valor de segmentación, tarda menos de cinco segundos, la experiencia es razonable, aunque puede sentirse lenta en comparación con la respuesta inmediata con los datos importados. Si la lentitud del origen hace que los objetos visuales individuales tarden más de decenas de segundos en actualizarse, la experiencia se vuelve excesivamente pobre. Las consultas pueden incluso agotar el tiempo de espera.
Junto con el rendimiento del origen subyacente, la carga colocada en el origen también afecta al rendimiento. Cada usuario que abre un informe compartido y cada icono del panel que se actualiza, envía al menos una consulta por objeto visual al origen subyacente. El origen debe ser capaz de administrar tal carga de consultas manteniendo un rendimiento razonable.
Implicaciones de seguridad
A menos que el origen de datos subyacente use el inicio de sesión único, un informe de DirectQuery siempre usa las mismas credenciales fijas para conectarse al origen una vez publicada en el servicio Power BI. Inmediatamente después de publicar un informe de DirectQuery, debe configurar las credenciales del usuario que se va a usar. Hasta que no configure las credenciales, al intentar abrir el informe en el servicio Power BI se produce un error.
Una vez que proporcione las credenciales de usuario, Power BI usará esas credenciales para quien abra el informe, igual que para los datos importados. Todos los usuarios ven los mismos datos, a menos que se defina la seguridad de nivel de fila como parte del informe. Debe prestar la misma atención a compartir el informe que para los datos importados, incluso si hay reglas de seguridad definidas en el origen subyacente.
La conexión a modelos semánticos de Power BI y Analysis Services en el modo DirectQuery siempre usa SSO, por lo que la seguridad es similar a las conexiones dinámicas a Analysis Services.
No se pueden usar "credenciales alternativas" al establecer conexiones de DirectQuery con SQL Server desde Power BI Desktop. Sí se pueden usar las credenciales de Windows o de base de datos actuales.
Puede usar varios orígenes de datos en un modelo directQuery mediante modelos compuestos. Cuando se usan varios orígenes de datos, es importante comprender las implicaciones para la seguridad del modo en que los datos van y vienen entre los orígenes de datos subyacentes.
Limitaciones de transformación de datos
DirectQuery limita las transformaciones de datos que puede aplicar en el Editor de Power Query. Con los datos importados, puede aplicar fácilmente un conjunto sofisticado de transformaciones para limpiar y cambiar la forma de los datos antes de usarlos para crear objetos visuales. Por ejemplo, puede analizar documentos JSON o dinamizar datos de una columna a un formulario de fila. Estas transformaciones están más limitadas en DirectQuery.
Al conectarse a un origen de procesamiento analítico en línea (OLAP), como SAP BW, no puede definir ninguna transformación y todo el modelo externo se toma del origen. Para fuentes relacionales como SQL Server, aún puede definir un conjunto de transformaciones por consulta, pero esas transformaciones están limitadas por razones de rendimiento.
Todas las transformaciones se deben aplicar en cada consulta al origen subyacente, en lugar de una vez en la actualización de datos. Las transformaciones deben ser capaces de traducirse razonablemente en una sola consulta nativa. Si utiliza una transformación demasiado compleja, obtendrá un error que le indicará que debe eliminarla o cambiar el modelo de conexión a importación.
Además, el cuadro de diálogo Obtener datos o Editor de Power Query Editor utilizan subselecciones dentro de las consultas que generan y envían para recuperar datos para un objeto visual. Las consultas definidas en el Editor de Power Query deben ser válidas dentro de este contexto. En concreto, no se pueden usar consultas con expresiones de tabla comunes ni consultas que invoquen procedimientos almacenados.
Limitaciones del modelado
En este contexto, el término modelación se refiere a la acción de refinar y enriquecer los datos sin procesar como parte de la elaboración de un informe utilizando los datos. Entre los ejemplos de modelación se incluyen:
- Definir relaciones entre tablas.
- Agregar cálculos nuevos como columnas calculadas y medidas.
- Cambiar nombre y ocultar columnas y medidas.
- Definir jerarquías.
- Definir el formato de columna, el resumen predeterminado y el criterio de ordenación.
- Agrupar valores o agruparlos en clústeres.
Todavía puede realizar muchos de estos enriquecimientos de modelos al usar DirectQuery y usar el principio de enriquecer los datos sin procesar para mejorar el consumo posterior. Sin embargo, algunas capacidades de modelación no están disponibles o son limitadas con DirectQuery. Las limitaciones se aplican para evitar problemas de rendimiento.
Las siguientes limitaciones son comunes a todos los orígenes de DirectQuery. Se pueden aplicar más limitaciones a orígenes individuales.
Sin jerarquía de fechas integrada: con los datos importados, cada columna de fecha/hora también tiene una jerarquía de fechas integrada disponible de manera predeterminada. Por ejemplo, si importa una tabla de pedidos de ventas que incluye una columna OrderDate y usa OrderDate en un objeto visual, puede elegir el nivel de fecha adecuado para usar, como año, mes o día. Esta jerarquía de fechas integrada no está disponible con DirectQuery. Si hay una tabla Fecha disponible en el origen subyacente, como es habitual en muchos almacenes de datos, puede usar las funciones de inteligencia de tiempo de expresiones de análisis de datos (DAX) como de costumbre.
Compatibilidad de fecha y hora solo con el nivel de segundos: en el caso de los modelos semánticos que usan columnas de tiempo, Power BI emite consultas al origen de DirectQuery subyacente solo hasta el nivel de detalle de segundos, no milisegundos. Quite los datos de milisegundos de las columnas de origen.
Limitaciones en las columnas calculadas: las columnas calculadas solo pueden ser intrafilas, es decir, solo pueden referirse a valores de otras columnas de la misma tabla, sin utilizar ninguna función de agregado. Además, las funciones escalares DAX permitidas, como
LEFT(), están limitadas a aquellas funciones que se pueden insertar en el origen subyacente. Las funciones varían en función de las capacidades exactas del origen. Las funciones que no son compatibles no aparecen en la lista de autocompletar cuando se crea la consulta DAX para una columna calculada, y dan lugar a un error si se utilizan.Sin compatibilidad con funciones DAX de elementos primarios y secundarios: en el modo DirectQuery, no es posible usar la familia de funciones
DAX PATH()que generalmente controlan las estructuras de elementos primarios y secundarios, como planes contables o jerarquías de empleados.Sin agrupación en clústeres: cuando se usa DirectQuery, no se puede usar la funcionalidad de agrupación en clústeres para buscar automáticamente grupos.
Limitaciones de informes
Los modelos DirectQuery admiten casi todas las funcionalidades de informes. Siempre que el origen subyacente ofrezca un nivel adecuado de rendimiento, puede usar el mismo conjunto de visualizaciones que para los datos importados.
Una limitación general es que la longitud máxima de los datos de una columna de texto para los modelos semánticos de DirectQuery es de 32 764 caracteres. Informar sobre textos más largos da lugar a un error.
Las siguientes funcionalidades de informes de Power BI pueden causar problemas de rendimiento en informes basados en DirectQuery:
Filtros de medidas: los objetos visuales que usan medidas (o agregados de columnas) pueden contener filtros en esas medidas. Por ejemplo, el siguiente gráfico muestra SalesAmount por Category, pero solo para las categorías con más de 20 millones de ventas.
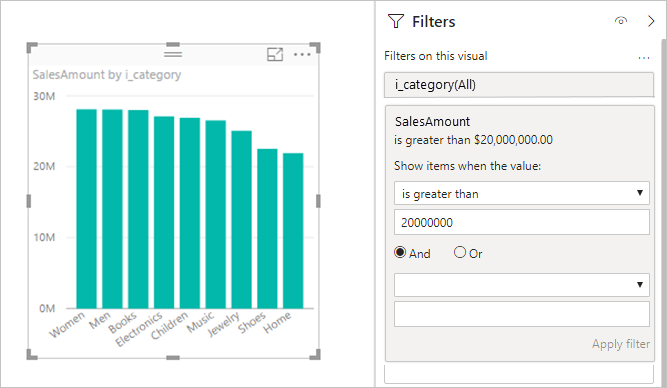
Este enfoque hace que se envíen dos consultas al origen subyacente:
- La primera consulta recupera las categorías que cumplen la condición, SalesAmount superior a 20 millones.
- La segunda consulta recupera los datos necesarios para el objeto visual, que incluyen las categorías que cumplían la condición
WHERE.
Este enfoque tiene por lo general un buen rendimiento si existen cientos o miles de categorías, como en este ejemplo. El rendimiento puede disminuir si el número de categorías es mucho mayor. Se produce un error en la consulta si hay más de un millón de categorías.
Filtros TopN: puede definir filtros avanzados para filtrar solo los valores superiores o inferiores
Nordenados por alguna medida. Por ejemplo, los filtros pueden incluir las 10 categorías principales. Este enfoque vuelve a enviar dos consultas al origen subyacente. Sin embargo, la primera consulta devuelve todas las categorías del origen subyacente y, luego, se determinan los valoresTopNsegún los resultados devueltos. Dependiendo de la cardinalidad de la columna en cuestión, este enfoque puede provocar problemas de rendimiento o fallos en la consulta debido al límite de un millón de filas en los resultados de la consulta.Mediana: cualquier agregación, como
SumoCount Distinct, se envía al origen subyacente. Sin embargo, normalmente el origen subyacente no admite el agregadomedian. Paramedian, los datos detallados se recuperan de la fuente subyacente, y la mediana se calcula a partir de los resultados devueltos. Este enfoque es razonable para calcular la mediana sobre un número relativamente pequeño de resultados.Pueden surgir problemas de rendimiento o errores de consulta si la cardinalidad es grande debido al límite de un millón de filas. Por ejemplo, consultar Población media del país/región podría ser razonable, pero Precio medio de venta podría no serlo.
Filtros de texto avanzados como 'contiene': el filtrado avanzado en una columna de texto permite filtros como
containsybegins with. Estos filtros pueden producir un rendimiento deteriorado para algunos orígenes de datos. En concreto, no use el filtro predeterminadocontainssi necesita una coincidencia exacta. Si bien los resultados podrían ser iguales, según los datos reales, el rendimiento podría ser completamente distinto a causa del uso de índices.Segmentaciones de selección múltiple: de manera predeterminada, las segmentaciones solo permiten realizar una sola selección. Permitir la selección múltiple en los filtros puede causar problemas de rendimiento. Por ejemplo, si el usuario selecciona los 10 productos de interés, cada nueva selección hace que las consultas se envíen al origen. Aunque el usuario puede seleccionar el elemento siguiente antes de que se complete la consulta, este enfoque se traduce en una carga adicional en el origen subyacente.
Totales en objetos visuales de tablas: de manera predeterminada, las tablas y matrices muestran totales y subtotales. En muchos casos, obtener los valores de estos totales requiere el envío de consultas independientes al origen subyacente. Este requisito se aplica siempre que utilice la agregación
DistinctCount, o en todos los casos que utilice DirectQuery sobre SAP BW o SAP HANA. Puede desactivar estos totales mediante el panel Formato.
Recomendaciones de DirectQuery
En esta sección se proporcionan instrucciones de alto nivel sobre cómo usar DirectQuery correctamente, dadas sus implicaciones.
Rendimiento del origen de datos subyacente
Valide que los objetos visuales simples se actualicen en un plazo de cinco segundos para proporcionar una experiencia interactiva razonable. Si los objetos visuales tardan más de 30 segundos en actualizarse, es probable que más problemas después de la publicación del informe hagan que la solución no se pueda trabajar.
Si las consultas son lentas, examine las consultas enviadas al origen subyacente y el motivo de la lentitud. Para obtener más información, consulte Diagnóstico de rendimiento.
En este artículo no se analiza el amplio rango de recomendaciones de optimización de base de datos en el conjunto completo de los orígenes subyacentes potenciales. Los siguientes procedimientos estándar de bases de datos se aplican a la mayoría de las situaciones:
Para mejorar el rendimiento, base las relaciones en columnas enteras en lugar de combinar columnas de otros tipos de datos.
Cree los índices adecuados. La creación de índices suele implicar el uso de índices de almacenes de columnas en orígenes que los admitan, por ejemplo SQL Server.
Actualice las estadísticas necesarias en el origen.
Diseño de modelos
Al definir el modelo, siga estas instrucciones:
Evite consultas complejas en Editor de Power Query. El Editor de Power Query traduce una consulta compleja en una única consulta SQL. La consulta única aparece en la subselección de todas las consultas enviadas a esa tabla. Si esa consulta es compleja, podría generar problemas de rendimiento en cada consulta enviada. Puede obtener la consulta SQL real para un conjunto de pasos haciendo clic con el botón derecho en el último paso bajo Pasos aplicados en el Editor de Power Query y seleccionando Ver consulta nativa.
Simplifique las medidas. Al menos al principio, limite las medidas a simples agregados. Si las medidas funcionan de forma satisfactoria, puede definir medidas más complejas, pero prestar atención al rendimiento.
Evite relaciones en las columnas calculadas. En las bases de datos en las que es necesario realizar combinaciones de varias columnas, Power BI no permite basar las relaciones en varias columnas como clave principal o clave externa. La solución común es concatenar las columnas entre sí con una columna calculada y basar la combinación en esa columna.
Esta solución es razonable para los datos importados, pero en el caso de DirectQuery, genera una combinación en una expresión. Ese resultado suele impedir el uso de cualquier índice y conduce a un rendimiento deficiente. La única solución es realmente materializar las columnas múltiples en una sola columna en el origen de datos subyacente.
Evite relaciones en columnas de tipo 'uniqueidentifier'. Power BI no admite de forma nativa un tipo de datos
uniqueidentifier. Definir una relación entre columnasuniqueidentifierda como resultado una consulta con una unión que implica una conversión. Al igual que en el caso anterior, esto normalmente genera un rendimiento deficiente. La única solución es materializar columnas de un tipo alternativo en el origen de datos subyacente.Oculte la columna "to" en las relaciones. La columna
toen las relaciones suele ser la clave principal de la tablato. Esa columna debe estar oculta, pero si está oculta, no aparece en la lista de campos y no se puede usar en los objetos visuales. A menudo, las columnas en las que se basan las relaciones son en realidad columnas del sistema, por ejemplo claves sustitutas en un almacén de datos. Todavía es mejor ocultar estas columnas.Si la columna tiene significado, introduzca una columna calculada que sea visible y que tenga una expresión simple de ser igual a la clave principal, por ejemplo:
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...Examine todas las columnas calculadas y los cambios de tipo de datos. Puede usar tablas calculadas al usar DirectQuery con modelos compuestos. Estas funcionalidades no son necesariamente dañinas, pero dan lugar a consultas que contienen expresiones en lugar de referencias simples a columnas. Esas consultas pueden hacer que no se utilicen los índices.
Evite el filtrado cruzado bidireccional en las relaciones. El uso de filtros cruzados bidireccionales puede dar lugar a sentencias de consulta que no funcionen bien. Para obtener más información sobre el filtrado cruzado bidireccional, consulte Habilitar el filtrado cruzado bidireccional para DirectQuery en Power BI Desktop o descargue las notas del producto sobre Filtrado cruzado bidireccional. Los ejemplos del documento son para SQL Server Analysis Services, pero los puntos fundamentales también se aplican a Power BI.
Experimente con la configuración Asumir integridad referencial. El ajuste Asumir integridad referencial en las relaciones permite que las consultas utilicen sentencias
INNER JOINen lugar deOUTER JOIN. Esta instrucción suele mejorar el rendimiento de la consulta, aunque depende de las características específicas del origen de datos.No use el filtrado de fechas relativas en el Editor de Power Query. Es posible definir el filtrado de fechas relativas en Editor de Power Query. Por ejemplo, puede filtrar a las filas cuya fecha se encuentre en los últimos 14 días.
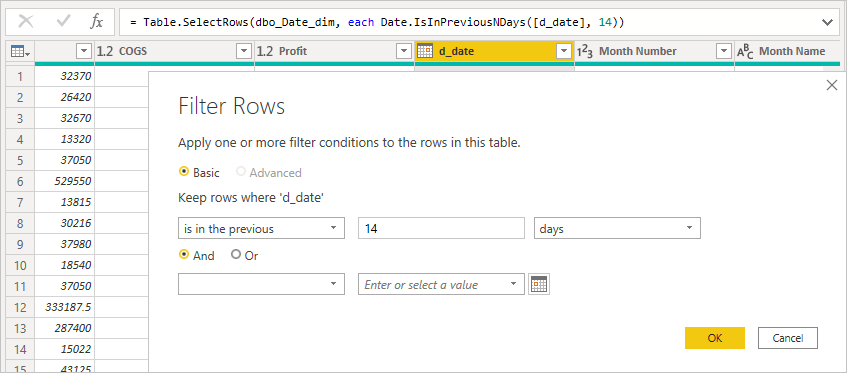
Sin embargo, este filtro se traduce en un filtro basado en una fecha fija, como la hora en que se creó la consulta, como puede ver en la consulta nativa.

Es probable que estos datos no sean los que usted desea. Para asegurarse de que el filtro se aplica en función de la fecha en el momento en que se ejecuta el informe, aplique el filtro de fecha en el informe. Puede crear una columna calculada que calcule el número de días hace mediante la función
DAX DATE()y usar esa columna calculada en el filtro.
Diseño del informe
Al crear un informe que use una conexión DirectQuery, siga estas instrucciones:
Considere usar las opciones de reducción de consultas: Power BI proporciona opciones de informe para enviar menos consultas y para desactivar ciertas interacciones que causan una mala experiencia si las consultas resultantes tardan mucho tiempo en ejecutarse. Estas opciones se aplican cuando interactúa con su informe en Power BI Desktop, y también se aplican cuando los usuarios consumen el informe en el servicio Power BI.
Para acceder a estas opciones en Power BI Desktop, vaya a Archivo>Opciones y configuración>Opciones, y seleccione Reducción de consulta. .
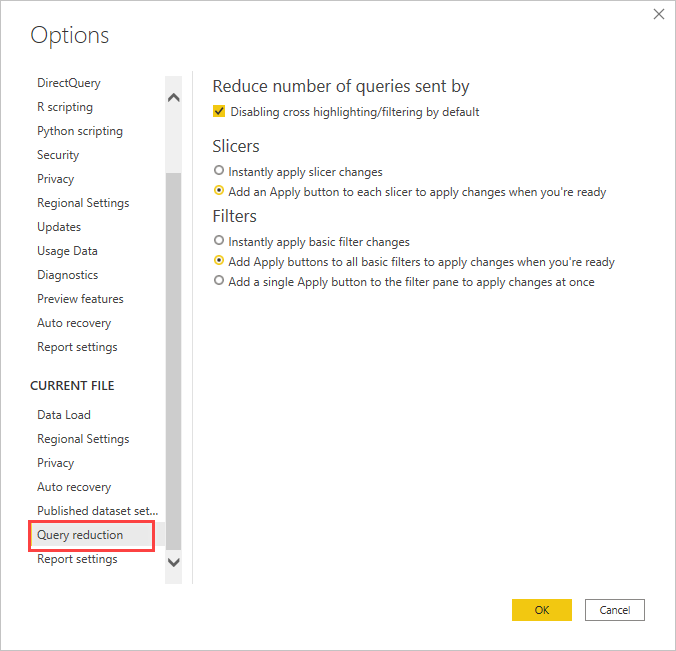
Las selecciones de la pantalla Reducción de consultas permiten mostrar un botón Aplicar para segmentaciones o selecciones de filtro. No se enviará ninguna consulta hasta que seleccione el botón Aplicar en el filtro o la segmentación. A continuación, las consultas usan las selecciones para filtrar los datos. Este botón le permite realizar varias selecciones de segmentación y filtros antes de aplicarlas.
Aplique primero los filtros: siempre aplique los filtros correspondientes al comienzo de la creación de un objeto visual. Por ejemplo, en lugar de arrastrar TotalSalesAmount y ProductName, y luego filtrar por un año determinado, aplique el filtro en Year al principio.
Cada paso de la creación de un objeto visual envía una consulta. Aunque es posible hacer otro cambio antes de completar la primera consulta, este enfoque todavía deja una carga innecesaria en el origen subyacente. La aplicación de filtros al comienzo suele hacer que esas consultas intermedias sean menos costosas. Si no se aplican los filtros a tiempo, se puede llegar al límite de un millón de filas.
Limite la cantidad de objetos visuales de una página: cuando abre una página o cambia un filtro o una segmentación a nivel de página, se actualizan todos los objetos visuales de una página. Hay un límite en el número de consultas paralelas. A medida que aumenta el número de objetos visuales, algunos objetos visuales se actualizan en serie, lo que aumenta el tiempo necesario para actualizar la página. Por lo tanto, es mejor limitar el número de objetos visuales en una sola página y, en su lugar, tener más páginas, más sencillas.
Considere desactivar la interacción entre objetos visuales: de manera predeterminada, las visualizaciones en una página de informe pueden usarse para el filtro cruzado y el resaltado cruzado de las demás visualizaciones en la página. Por ejemplo, si selecciona 1999 en el gráfico circular, el gráfico de columnas mostrará el resaltado cruzado de las ventas por categoría para 1999.
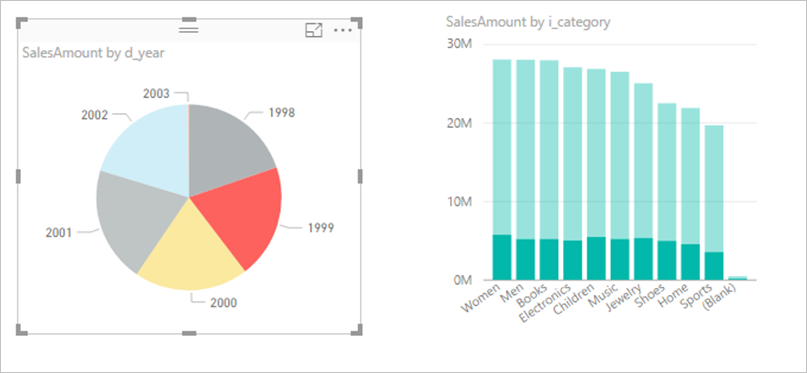
El filtrado cruzado y el resaltado cruzado de DirectQuery requieren el envío de consultas al origen subyacente. Debe desactivar esta interacción si el tiempo necesario para responder a las selecciones de los usuarios es excesivamente largo.
Puede utilizar los ajustes de Reducción de consultas para desactivar el resaltado cruzado en todo el informe o en cada caso. Para más información, vea Aplicación de un filtro cruzado entre objetos visuales de un informe de Power BI.
Número máximo de conexiones
Puede establecer el número máximo de conexiones que abre DirectQuery para cada origen de datos subyacente, lo que controla el número de consultas enviadas al mismo tiempo a cada origen de datos.
DirectQuery abre un número máximo predeterminado de 10 conexiones simultáneas. Para cambiar el número máximo para el archivo actual en Power BI Desktop, vaya a Archivo>Opciones y configuración>Opciones, y seleccione DirectQuery en la sección Archivo actual del panel izquierdo.
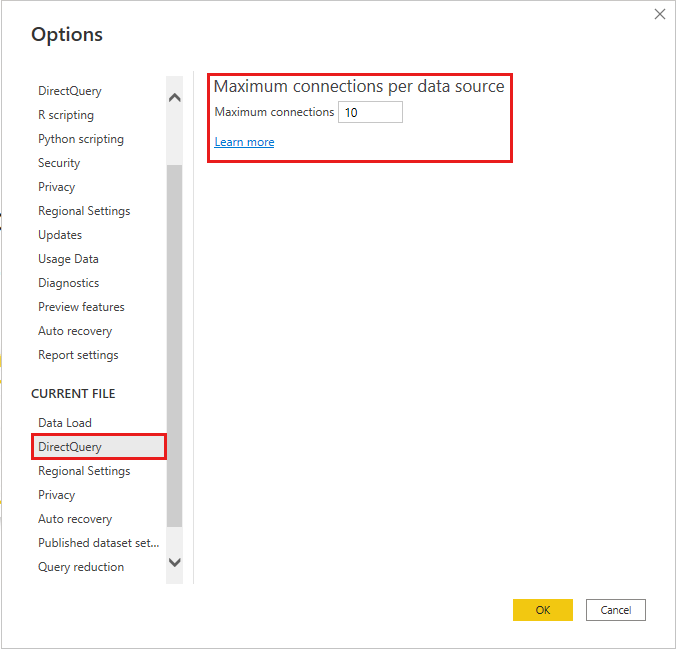
Esta opción solo se habilita cuando hay al menos un origen de DirectQuery en el informe actual. El valor se aplica a todos los orígenes de DirectQuery y a los nuevos orígenes de DirectQuery agregados al informe.
Aumentar el valor de Número máximo de conexiones por origen de datos permite enviar más consultas, hasta el número máximo especificado, al origen de datos subyacente. Este enfoque resulta útil cuando muchos objetos visuales están en una sola página o muchos usuarios tienen acceso a un informe al mismo tiempo. Una vez alcanzado el número máximo de conexiones, las consultas siguientes se ponen en cola hasta que haya disponible una conexión. Un límite más alto supone una mayor carga para el origen subyacente, por lo que no se garantiza que el ajuste mejore el rendimiento general.
Una vez que publique un informe en el servicio Power BI, el número máximo de consultas simultáneas también depende de los límites fijos establecidos en el entorno de destino donde se publica el informe. Power BI, Power BI Premium y Power BI Report Server imponen límites diferentes. En la tabla siguiente se enumeran los límites superiores de las conexiones activas por origen de datos para cada entorno de Power BI. Estos límites se aplican a los orígenes de datos en la nube y locales, como SQL Server, Oracle y Teradata.
| Entorno | Límite superior por origen de datos |
|---|---|
| Power BI Pro | 10 conexiones activas |
| Power BI Premium | Depende de la limitación de la SKU del modelo semántico |
| Power BI Report Server | 10 conexiones activas |
Nota
La configuración del número máximo de conexiones de DirectQuery se aplica a todos los orígenes de DirectQuery al habilitar los metadatos mejorados, que es lo predeterminado para todos los modelos creados en Power BI Desktop.
DirectQuery en el servicio Power BI
Todos los orígenes de datos de DirectQuery se admiten desde Power BI Desktop y algunos orígenes también están disponibles directamente desde el servicio Power BI. Un usuario empresarial puede utilizar Power BI para conectarse a sus datos en Salesforce, por ejemplo, y obtener inmediatamente un panel, sin necesidad de utilizar Power BI Desktop.
Solo los dos orígenes habilitados para DirectQuery siguientes están disponibles directamente en el servicio Power BI:
- Spark
- Azure Synapse Analytics (anteriormente SQL Data Warehouse)
Incluso para estos dos orígenes, sigue siendo mejor iniciar el uso de DirectQuery en Power BI Desktop. Aunque es fácil establecer inicialmente la conexión en el servicio Power BI, existen limitaciones para mejorar aún más el informe resultante. Por ejemplo, en el servicio no es posible crear ningún cálculo, ni utilizar muchas funciones analíticas, ni actualizar los metadatos para reflejar los cambios en el esquema subyacente.
El rendimiento de un informe de DirectQuery en el servicio Power BI depende del grado de carga colocado en el origen de datos subyacente. La carga depende de:
- Número de usuarios que comparten el informe y el panel.
- La complejidad del informe.
- Si el informe define la seguridad de nivel de fila.
Comportamiento de los informes en el servicio Power BI
Al abrir un informe en el servicio Power BI, todos los objetos visuales de la página visible actualmente se actualizan. Cada objeto visual requerirá al menos una consulta al origen de datos subyacente. Puede que algunos objetos visuales requieran más de una consulta. Por ejemplo, un objeto visual podría mostrar valores agregados de dos tablas de hechos distintas, contener una medida más compleja o contener totales de una medida no de adición, como Count Distinct. Al pasar a una nueva página se actualizan esos objetos visuales. La actualización envía un nuevo conjunto de consultas al origen subyacente.
Cada interacción del usuario en el informe podría hacer que se actualicen los objetos visuales. Por ejemplo, la selección de otro valor en una segmentación requiere enviar un nuevo conjunto de consultas para actualizar todos los objetos visuales afectados. Lo mismo sucede cuando se selecciona un objeto visual para el resaltado cruzado de otros objetos visuales o para cambiar un filtro. De manera similar, la creación o edición de un informe requiere que se envíen consultas para cada paso de la ruta de acceso para generar el objeto visual final.
Hay algún tipo de almacenamiento en caché de los resultados en caché. La actualización de un objeto visual es instantánea si recientemente se han obtenido exactamente los mismos resultados. Si se define seguridad de nivel de fila, estas cachés no se comparten entre los usuarios.
El uso de DirectQuery impone algunas limitaciones importantes en algunas de las funcionalidades que ofrece el servicio Power BI para los informes publicados:
No se admiten conclusiones rápidas: las conclusiones rápidas de Power BI buscan en distintos subconjuntos del modelo semántico al tiempo que aplican un conjunto de algoritmos sofisticados para detectar información de posible interés. Dado que las conclusiones rápidas requieren consultas de alto rendimiento, esta característica no está disponible en los modelos semánticos que usan DirectQuery.
El uso de Explorar en Excel da como resultado un rendimiento deficiente: puede explorar un modelo semántico mediante la funcionalidad Explorar en Excel, que le permite crear tablas dinámicas y gráficos dinámicos en Excel. Esta funcionalidad es compatible con modelos semánticos que usan DirectQuery, pero el rendimiento es más lento que crear objetos visuales en Power BI. Si usar Excel es importante para sus escenarios, tenga en cuenta este problema al decidir si se debe usar DirectQuery.
Excel no muestra jerarquías: por ejemplo, cuando se usa Analizar en Excel, Excel no muestra las jerarquías definidas en los modelos de Azure Analysis Services o en los modelos semánticos de Power BI que utilizan DirectQuery.
Actualización del panel
En el servicio Power BI, puede anclar objetos visuales individuales o páginas completas a paneles como iconos. Los iconos basados en modelos semánticos de DirectQuery se actualizan automáticamente mediante el envío de consultas a los orígenes de datos subyacentes según una programación. De manera predeterminada, los modelos semánticos se actualizan cada hora, pero puede configurar la actualización entre semanal y cada 15 minutos como parte de la configuración del modelo semántico.
Si no se define ninguna seguridad a nivel de fila en el modelo, cada icono se actualiza una sola vez y los resultados se comparten entre todos los usuarios. Si usa seguridad de nivel de fila, cada icono requiere que se envíen consultas independientes por usuario al origen subyacente.
Puede haber un gran efecto multiplicador. Un panel con 10 iconos, compartido con 100 usuarios, creado sobre un modelo semántico que utiliza DirectQuery con seguridad a nivel de fila, da lugar a que se envíen al menos 1000 consultas al origen de datos subyacente por cada actualización. Tenga muy en cuenta el uso de la seguridad de nivel de filas y la configuración del calendario de actualización.
Tiempos de espera de las consultas
Un tiempo de espera de cuatro minutos se aplica a las consultas individuales en el servicio Power BI. Se produce un error en las consultas que tardan más de cuatro minutos. Este límite pretende evitar problemas causados por tiempos de ejecución demasiado largos. Solo debe usar DirectQuery para orígenes que puedan proporcionar rendimiento interactivo de consultas.
Cuando se alcanza el límite de tiempo de espera, los objetos visuales no se cargan con el siguiente error: The query has exceeded the available resources. Try filtering to decrease the amount of data requested. The XML for Analysis request timed out before it was completed. Timeout value: 225 sec.
Diagnóstico de rendimiento
Esta sección describe cómo diagnosticar problemas de rendimiento o cómo obtener información más detallada para optimizar sus informes.
Empiece a diagnosticar los problemas de rendimiento en Power BI Desktop, en lugar de en el servicio Power BI. Los problemas de rendimiento suelen basarse en el rendimiento del origen subyacente. Puede identificar y diagnosticar más fácilmente los problemas en el entorno más aislado de Power BI Desktop.
Este enfoque elimina inicialmente determinados componentes, como la puerta de enlace de Power BI. Si los problemas de rendimiento no se producen en Power BI Desktop, puede investigar los detalles del informe en el servicio Power BI.
El analizador de rendimiento de Power BI Desktop es una herramienta útil para identificar problemas. Intente aislar cualquier problema a un solo objeto visual, en lugar de a muchos objetos visuales en una página. Si un único objeto visual de una página de Power BI Desktop va lento, utilice el Analizador de rendimiento para analizar las consultas que Power BI Desktop envía al origen subyacente.
También puede ver seguimientos e información de diagnóstico que emiten algunos orígenes de datos subyacentes. Incluso si no hay seguimientos del origen, el archivo de seguimiento puede contener detalles útiles sobre cómo se ejecuta una consulta y cómo puede mejorarla. Puede usar el siguiente proceso para ver las consultas que Power BI envía y sus tiempos de ejecución.
Uso de SQL Server Profiler para ver consultas
De manera predeterminada, Power BI Desktop registra los eventos que se producen durante una sesión determinada en un archivo de seguimiento llamado FlightRecorderCurrent.trc. El archivo de seguimiento se encuentra en la carpeta Power BI Desktop del usuario actual, en una carpeta denominada AnalysisServicesWorkspaces.
Para algunos orígenes de DirectQuery, este archivo de seguimiento incluye todas las consultas enviadas al origen de datos subyacente. Los orígenes de datos siguientes envían consultas al registro:
- SQL Server
- Azure SQL Database
- Azure Synapse Analytics (anteriormente SQL Data Warehouse)
- Oracle
- Teradatos
- SAP HANA
Puede leer los archivos de seguimiento utilizando el SQL Server Profiler, que forma parte de la descarga gratuita de SQL Server Management Studio.
Para abrir el archivo de seguimiento de la sesión actual:
Durante una sesión de Power BI Desktop, seleccione Archivo>Opciones y ajustes>Opciones y, a continuación, seleccione Diagnósticos.
En Recopilación del volcado de memoria, seleccione Abrir carpeta de volcado de memoria o seguimiento.
Se abre la carpeta Power BI Desktop\Traces.
Vaya a la carpeta principal y, a continuación, a la carpeta AnalysisServicesWorkspaces, que contiene una carpeta de área de trabajo para cada instancia abierta de Power BI Desktop. El nombre de estas carpetas incluye un sufijo de entero, como AnalysisServicesWorkspace2058279583. La carpeta de área de trabajo se elimina cuando finaliza la sesión de Power BI Desktop asociada.
Dentro de la carpeta del área de trabajo de la sesión actual de Power BI, la carpeta \Data contiene el archivo de seguimiento FlightRecorderCurrent.trc. Tome nota de la ubicación.
Abra SQL Server Profiler y seleccione Archivo>Abrir>Archivo de seguimiento.
Vaya a o escriba la ruta de acceso al archivo de seguimiento de la sesión actual de Power BI y abra FlightRecorderCurrent.trc.
SQL Server Profiler muestra todos los eventos de la sesión actual. En la captura de pantalla siguiente se resalta un grupo de eventos para una consulta. Cada grupo de consulta tiene los siguientes eventos:
Un evento
Query BeginyQuery End, que representan el inicio y el final de una consulta DAX generada al cambiar un objeto visual o un filtro en la interfaz de usuario de Power BI, o a partir del filtrado o la transformación de datos en el Power Query Editor.Uno o más pares de eventos
DirectQuery BeginyDirectQuery End, que representan consultas enviadas al origen de datos subyacente como parte de la evaluación de la consulta DAX.

Se pueden ejecutar varias consultas DAX en paralelo, por lo que se pueden intercalar eventos de distintos grupos. Puede utilizar el valor ActivityID para determinar qué eventos pertenecen al mismo grupo.
Las columnas siguientes también son de interés:
- TextData: el detalle textual del evento. Para los eventos
Query BeginyQuery End, el detalle es la consulta DAX. En el caso de los eventosDirectQuery BeginyDirectQuery End, el detalle es la consulta SQL enviada al origen subyacente. TextData para el evento seleccionado actualmente también aparece en el panel de la parte inferior de la pantalla. - EndTime: cuándo se completó el evento.
- Duration: la duración, en milisegundos, que tardó en ejecutarse la consulta DAX o SQL.
- Error: si se ha producido un error, en cuyo caso el evento también se muestra en rojo.
Para capturar un seguimiento para ayudar a diagnosticar un posible problema de rendimiento:
Abra una sesión única de Power BI Desktop, para evitar la confusión de tener varias carpetas de área de trabajo.
Realice el conjunto de acciones de interés en Power BI Desktop. Incluya algunas acciones más, para asegurarse de que los eventos de interés se vierten en el archivo de seguimiento.
Abra SQL Server Profiler y examine el seguimiento. Recuerde que al cerrar Power BI Desktop, se elimina el archivo de seguimiento. Además, las acciones adicionales en Power BI Desktop no aparecen inmediatamente. Debe cerrar y volver a abrir el archivo de seguimiento para ver nuevos eventos.
Mantenga sesiones individuales razonablemente pequeñas, quizás 10 segundos de acciones, no cientos. Este enfoque facilita la interpretación del archivo de seguimiento. También hay un límite en el tamaño del archivo de seguimiento. En el caso de las sesiones largas, existe la posibilidad de descartar los eventos iniciales.
Descripción del formato de las consultas
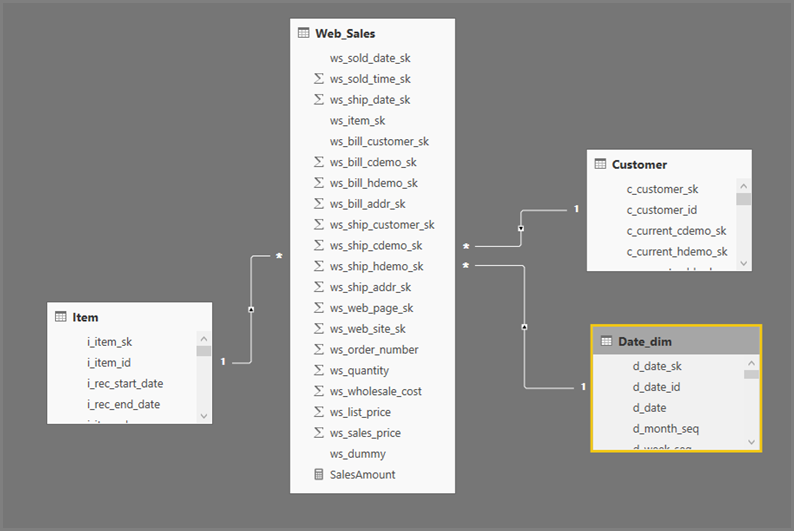
El formato general de las consultas de Power BI Desktop usa subselecciones para cada tabla a la que hacen referencia. La consulta del Power Query Editor define las consultas de la subselección. Por ejemplo, suponga que tiene las siguientes tablas TPC-DS en SQL Server:
Ejecutando la siguiente consulta:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Da como resultado el siguiente objeto visual en Power BI:
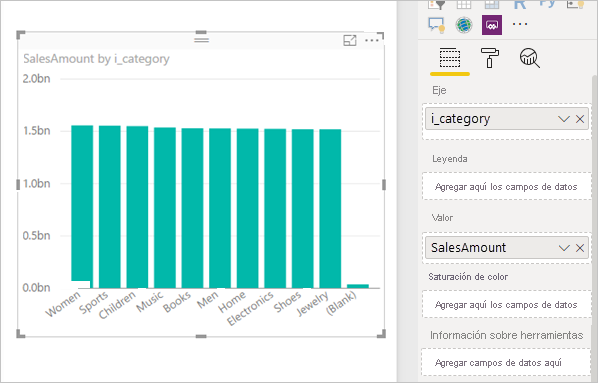
Al actualizar ese objeto visual, se genera la consulta SQL en la imagen siguiente. Hay tres consultas de subselección para Web_Sales, Itemy Date_dim, que devuelven todas las columnas de la tabla respectiva, aunque el objeto visual haga referencia solo a cuatro columnas.
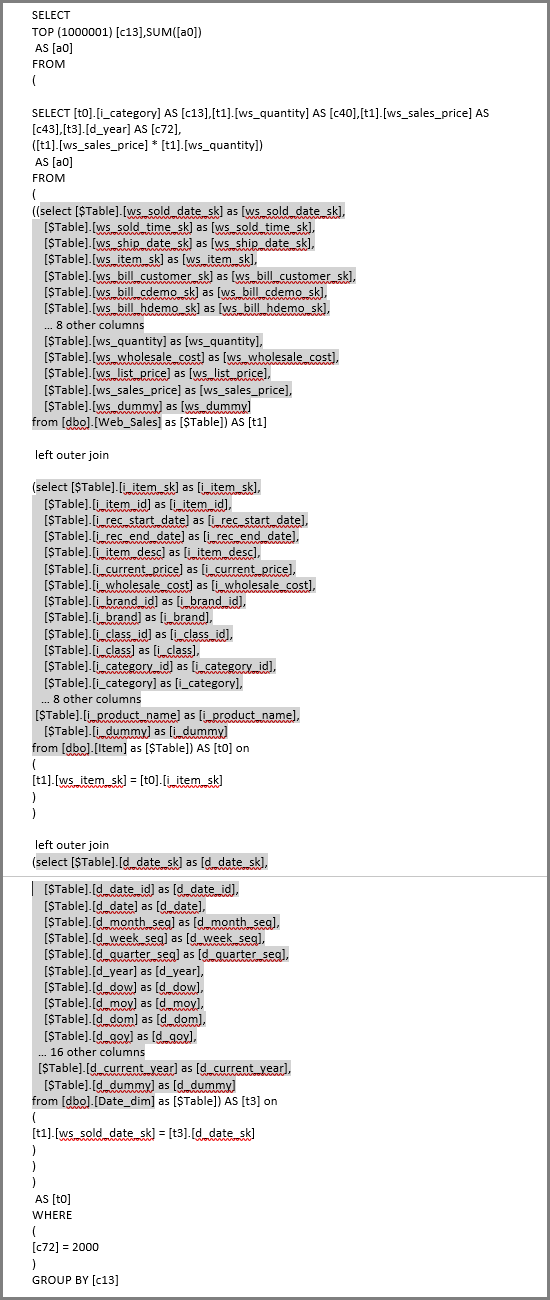
Editor de Power Query define las consultas de subselección exactas. Este uso de consultas de subselección no se ha mostrado para afectar al rendimiento de los orígenes de datos compatibles con DirectQuery. Los orígenes de datos como SQL Server optimizan las referencias a las otras columnas.
Power BI usa este patrón porque el analista proporciona directamente la consulta SQL. Power BI usa la consulta como se proporciona, sin ningún intento de reescribirla.
Contenido relacionado
Para obtener más información sobre DirectQuery en Power BI, consulte:
En este artículo se describen aspectos de DirectQuery que son comunes entre todos los orígenes de datos. Consulte los siguientes artículos para obtener más información sobre orígenes específicos: