Implementación de clústeres de macrodatos de SQL Server con alta disponibilidad
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
Dado que los clústeres de macrodatos de SQL Server se encuentran en Kubernetes como aplicaciones en contenedores y usan características como los conjuntos con estado y el almacenamiento persistente, esta infraestructura tiene supervisión de estado integrada, detección de errores y mecanismos de conmutación por error que los componentes de los clústeres aprovechan para mantener el estado del servicio. Para mayor confiabilidad, también puede configurar la instancia maestra de SQL Server o un nodo de nombre HDFS y servicios compartidos de Spark para realizar la implementación con réplicas adicionales en una configuración de alta disponibilidad. La supervisión, la detección de errores y la conmutación automática por error se administran mediante el servicio de administración de clústeres de macrodatos, es decir, el servicio de control. Este servicio se proporciona sin intervención del usuario, desde la configuración del grupo de disponibilidad y la configuración de puntos de conexión de creación de reflejo de la base de datos, hasta la incorporación de bases de datos al grupo de disponibilidad, o conmutación por error y coordinación de actualizaciones.
En la imagen siguiente se refleja cómo se implementa un grupo de disponibilidad en un clúster de macrodatos de SQL Server:
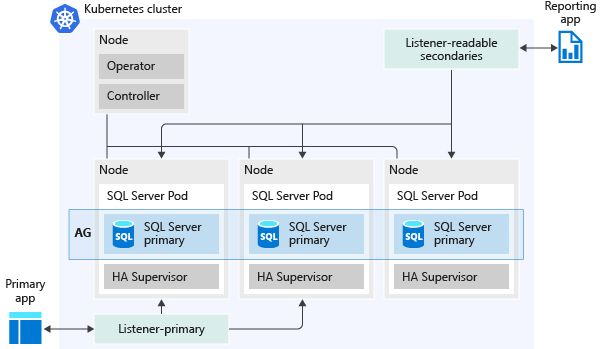
Estas son algunas de las funcionalidades que habilitan los grupos de disponibilidad:
Si la configuración de alta disponibilidad se especifica en el archivo de configuración de implementación, se crea un único grupo de disponibilidad denominado
containedag. De forma predeterminada,containedagtiene tres réplicas, incluida la principal. Todas las operaciones CRUD del grupo de disponibilidad se administran internamente, incluida la creación del grupo de disponibilidad o la unión de réplicas al grupo de disponibilidad creado. No se pueden crear grupos de disponibilidad adicionales en la instancia maestra de SQL Server de un clúster de macrodatos.Todas las bases de datos se agregan automáticamente al grupo de disponibilidad, incluidas todas las bases de datos del usuario y el sistema, como
masterymsdb. Esta funcionalidad proporciona una vista de un solo sistema de las réplicas del grupo de disponibilidad. Se usan otras bases de datos modelo (model_replicatedmasterymodel_msdb) para inicializar la parte replicada de las bases de datos del sistema. Además de estas bases de datos, aparecen las bases de datoscontainedag_masterycontainedag_msdbsi se conecta directamente a la instancia. Las bases de datoscontainedagrepresentanmasterymsdbdentro del grupo de disponibilidad.Importante
Las bases de datos que se crean en la instancia como resultado de un flujo de trabajo, como la asociación de una base de datos, no se agregan automáticamente al grupo de disponibilidad. Los administradores de Clústeres de macrodatos de SQL Server tendrán que hacerlo manualmente. Para obtener información sobre cómo habilitar un punto de conexión temporal a la base de datos maestra de la instancia de SQL Server, vea Conexión a la instancia de SQL Server. Antes de la versión SQL Server 2019 CU2, las bases de datos que se creaban como resultado de una instrucción RESTORE tenían el mismo comportamiento y era necesario agregarlas manualmente al grupo de disponibilidad contenido.
Las bases de datos de configuración de PolyBase no se incluyen en el grupo de disponibilidad porque contienen metadatos de nivel de instancia específicos de cada réplica.
Se aprovisiona automáticamente un punto de conexión externo para conectarse a las bases de datos del grupo de disponibilidad. Este punto de conexión
master-svc-externaldesempeña el rol de escucha de grupo de disponibilidad.Se aprovisiona un segundo punto de conexión externo para las conexiones de solo lectura a las réplicas secundarias para escalar horizontalmente las cargas de trabajo de lectura.
Implementación
Para implementar la instancia maestra de SQL Server en un grupo de disponibilidad:
- Habilite la característica
hadr - Especifique el número de réplicas del grupo de disponibilidad (el mínimo es 3)
- Configure los detalles del segundo punto de conexión externo creado para las conexiones a las réplicas secundarias de solo lectura
Puede usar los perfiles de configuración integrados aks-dev-test-ha o kubeadm-prod para empezar a personalizar el clúster de macrodatos. Estos perfiles incluyen la configuración necesaria relativa a los recursos que permiten configurar alta disponibilidad extra. Por ejemplo, a continuación hay una sección del archivo de configuración bdc.json que es relevante para habilitar grupos de disponibilidad para la instancia maestra de SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
En los pasos siguientes se ve un ejemplo de cómo iniciar desde el perfil aks-dev-test-ha y personalizar la configuración de implementación del clúster de macrodatos. En el caso de una implementación en un clúster de kubeadm se aplican pasos similares, pero asegúrese de usar NodePort como el serviceType en la sección endpoints.
Clone el perfil de destino
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haOpcionalmente, realice cualquier modificación en el perfil personalizado según sea necesario.
Inicie la implementación del clúster mediante el perfil de configuración de clúster creado anteriormente
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Conectarse a bases de datos de SQL Server en el grupo de disponibilidad
En función del tipo de carga de trabajo que quiera ejecutar en la instancia maestra de SQL Server, puede conectarse a las bases de datos de la réplica principal en el caso de las cargas de trabajo de lectura y escritura o a las bases de datos de las réplicas secundarias en el caso del tipo de cargas de trabajo de solo lectura. Este es un esquema de cada tipo de conexión:
Conexión a las bases de datos de la réplica principal
En el caso de las conexiones a la réplica principal, use el punto de conexión sql-server-master. Este punto de conexión también es el cliente de escucha del grupo de disponibilidad. Al usar este punto de conexión, todas las conexiones se encuentran en el contexto de bases de datos del grupo de disponibilidad. Por ejemplo, una conexión predeterminada que use este punto de conexión da lugar a la conexión a la base de datos master del grupo de disponibilidad, no a la base de datos master de la instancia de SQL Server. Ejecute este comando para buscar el punto de conexión:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Nota
Pueden producirse eventos de conmutación por error durante una ejecución de consulta distribuida que acceda a datos de orígenes de datos remotos como HDFS o un grupo de datos. Como procedimiento recomendado, las aplicaciones deben diseñarse con lógica de reintento de conexión en caso de desconexiones producidas por una conmutación por error.
Conexión a las bases de datos de las réplicas secundarias
En el caso de las conexiones de solo lectura a las bases de datos de las réplicas secundarias, use el punto de conexión sql-server-master-readonly. Este punto de conexión actúa como un equilibrador de carga en todas las réplicas secundarias. Al usar este punto de conexión, todas las conexiones se encuentran en el contexto de bases de datos del grupo de disponibilidad. Por ejemplo, una conexión predeterminada que use este punto de conexión da lugar a la conexión a la base de datos master del grupo de disponibilidad, no a la base de datos master de la instancia de SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Conectarse a la instancia de SQL Server
En determinadas operaciones, como el establecimiento de configuraciones de nivel de servidor o la incorporación manual de una base de datos al grupo de disponibilidad, debe conectarse a la instancia de SQL Server. Antes de SQL Server 2019 CU2, operaciones como sp_configure, RESTORE DATABASE o cualquier DDL de grupos de disponibilidad requieren este tipo de conexión. De forma predeterminada, el clúster de macrodatos no incluye un punto de conexión que habilite la conexión de la instancia, así que debe exponer este punto de conexión de forma manual.
Importante
El punto de conexión expuesto para las conexiones de la instancia de SQL Server solo admite autenticación SQL, incluso en clústeres en los que Active Directory está habilitado. De forma predeterminada, durante la implementación de un clúster de macrodatos, el inicio de sesión sa está deshabilitado y se aprovisiona un nuevo inicio de sesión sysadmin basado en los valores proporcionados en el momento de la implementación para las variables de entorno AZDATA_USERNAME y AZDATA_PASSWORD.
Importante
El DDL del grupo de disponibilidad contenido es exclusivamente autoadministrado en BDC. No se admite ningún intento ( de usuario externo) de quitar el disponibilidad contenida o el punto de conexión de creación de reflejo de la base de datos y puede dar lugar a un estado de BDC irrecuperable.
Este es un ejemplo que muestra cómo exponer este punto de conexión y luego agregar la base de datos creada con un flujo de trabajo de restauración al grupo de disponibilidad. Se aplican instrucciones similares para configurar una conexión a la instancia maestra de SQL Server cuando se quieren cambiar las configuraciones de servidor con sp_configure.
Nota
A partir de SQL Server 2019 CU2, las bases de datos creadas como resultado de un flujo de trabajo de restauración se agregan automáticamente al grupo de disponibilidad contenido.
Determine el pod que hospeda la réplica principal; para ello, conéctese al punto de conexión
sql-server-mastery ejecute:SELECT @@SERVERNAMEExponga el punto de conexión externo mediante la creación de un nuevo servicio Kubernetes
En el caso de un clúster de
kubeadm, ejecute el comando siguiente. ReemplacepodNamepor el nombre del servidor devuelto en el paso anterior,serviceNamepor el nombre preferido para el servicio Kubernetes creado ynamespaceName* por el nombre del clúster de macrodatos.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortEn el caso de un clúster de AKS, ejecute el mismo comando, con la salvedad de que el tipo de servicio creado es
LoadBalancer. Por ejemplo:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerEste es un ejemplo de este comando en ejecución en AKS, donde el pod que hospeda la réplica principal es
master-0:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerObtenga la dirección IP del servicio Kubernetes creado:
kubectl get services -n <namespaceName>
Importante
Como procedimiento recomendado, debe limpiar mediante la eliminación del servicio Kubernetes creado anteriormente al ejecutar este comando:
kubectl delete svc master-sql-0 -n mssql-cluster
Agregue la base de datos al grupo de disponibilidad.
Para que la base de datos se agregue al grupo de disponibilidad, debe ejecutarse en el modelo de recuperación completa y debe realizarse una copia de seguridad del registro. Use la dirección IP del servicio Kubernetes creado anteriormente y conéctese a la instancia de SQL Server, luego ejecute las instrucciones de T-SQL como se muestra a continuación.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>En el ejemplo siguiente se agrega una base de datos denominada
salesrestaurada en la instancia:ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Restricciones conocidas
Estos son los problemas y las limitaciones conocidos de los grupos de disponibilidad contenidos de la instancia maestra de SQL Server en el clúster de macrodatos:
- La configuración de alta disponibilidad debe crearse al implementar el clúster de macrodatos. No se puede habilitar la configuración de alta disponibilidad con grupos de disponibilidad después de la implementación. En este momento, la configuración habilitada solo es para las réplicas de confirmación sincrónicas.
Advertencia
La actualización del modo de sincronización a la confirmación asincrónica para cualquiera de las réplicas en la confirmación de cuórum producirá una configuración de alta disponibilidad no válida. Trabajar con esta configuración conlleva un riesgo de pérdida de datos, ya que, en caso de que se produzcan eventos de error que afecten a la réplica principal, no se desencadena una conmutación por error automática y el usuario debe aceptar este riesgo al emitir la conmutación por error manual.
- Para restaurar de forma correcta una base de datos habilitada para TDE a partir de una copia de seguridad creada en otro servidor, debe asegurarse de que los certificados necesarios se restauren tanto en la instancia maestra de SQL Server como en el grupo de disponibilidad maestro contenido. Aquí puede ver un ejemplo de cómo realizar una copia de seguridad de los certificados y restaurarlos.
- Determinadas operaciones, como la ejecución de la configuración de servidor con
sp_configure, requieren una conexión a la base de datosmasterde la instancia de SQL Server, no amasterdel grupo de disponibilidad. No se puede usar el punto de conexión principal correspondiente. Siga las instrucciones para exponer un punto de conexión y conectarse a la instancia de SQL Server y ejecutarsp_configure. Solo se puede usar autenticación SQL cuando se expone manualmente el punto de conexión para conectarse a la base de datosmasterde la instancia de SQL Server. - Aunque la base de datos msdb independiente se incluye en el grupo de disponibilidad y los trabajos del Agente SQL se replican ahí, los trabajos solo se ejecutan según una programación en la réplica principal.
- La característica de replicación no es compatible con los grupos de disponibilidad contenidos. Las instancias de SQL Server que forman parte de un grupo de disponibilidad contenido no funcionan como distribuidor ni publicador, ya sea en el nivel de instancia o en el nivel de grupo de disponibilidad contenido.
- No se admite agregar grupos de archivos al crear la base de datos. Como solución alternativa, puede crear primero la base de datos y, luego, emitir una instrucción ALTER DATABASE para agregar grupos de archivos.
- Antes de SQL Server 2019 CU2, las bases de datos creadas como resultado de flujos de trabajo distintos a
CREATE DATABASEyRESTORE DATABASE, comoCREATE DATABASE FROM SNAPSHOT, no se agregan automáticamente al grupo de disponibilidad. Conéctese a la instancia y agregue la base de datos al grupo de disponibilidad manualmente. - Actualmente, Service Broker y Correo electrónico de base de datos no se admiten en clústeres de macrodatos implementados con alta disponibilidad.
Pasos siguientes
- Para más información sobre cómo usar archivos de configuración en implementaciones de clústeres de macrodatos, vea Cómo implementar Clústeres de macrodatos de SQL Server en Kubernetes.
- Para obtener más información sobre la característica de grupos de disponibilidad para SQL Server, vea Información general de los grupos de disponibilidad AlwaysOn (SQL Server).
Comentarios
Proximamente: Ao longo de 2024, retiraremos gradualmente GitHub Issues como mecanismo de comentarios sobre o contido e substituirémolo por un novo sistema de comentarios. Para obter máis información, consulte: https://aka.ms/ContentUserFeedback.
Enviar e ver os comentarios