Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
En este artículo se detalla cómo determinar si una consulta de PolyBase se beneficia de la delegación de procesos al origen de datos externo. Para obtener más información sobre la inserción externa, consulte computaciones de inserción en PolyBase.
¿Mi consulta se beneficia de un empuje externo?
La computación de empuje mejora el rendimiento de las consultas en fuentes de datos externas. Algunas tareas de cálculo se delegan en el origen de datos externo en lugar de incorporarse a SQL Server. Especialmente en los casos de filtrado e inserción de combinación, la carga de trabajo en la instancia de SQL Server se puede reducir considerablemente.
El cálculo de empuje de PolyBase puede mejorar significativamente el rendimiento de una consulta. Si una consulta de PolyBase se está realizando lentamente, debe determinar si se está produciendo la inserción de la consulta de PolyBase.
Hay tres escenarios diferentes donde se puede observar el pushdown en el plan de ejecución:
- Optimización de predicado de filtro
- Optimización de unión
- Optimización de agregaciones
Nota:
Existen limitaciones sobre lo que se puede delegar a fuentes de datos externas con cálculos de propagación de PolyBase.
- Algunas funciones de T-SQL pueden impedir el pushdown, para obtener más información, consulte Características y limitaciones de PolyBase.
- Para obtener una lista de las funciones de T-SQL que se pueden delegar, consulte Cálculos delegados en PolyBase.
Se han introducido dos nuevas características de SQL Server 2019 (15.x) para permitir a los administradores determinar si se inserta una consulta de PolyBase en el origen de datos externo:
- Ver el plan de ejecución estimado con la marca de seguimiento 6408
- Ver el
read_commanden la vista de administración dinámica sys.dm_exec_external_work
En este artículo se proporcionan detalles sobre cómo usar cada uno de estos dos casos de uso, para cada uno de estos tres escenarios de delegación.
Usar TF6408
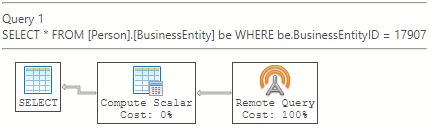
De forma predeterminada, el plan de ejecución estimado no expone el plan de consulta remota y solo ve el objeto del operador de consulta remota. Por ejemplo, un plan de ejecución estimado de SQL Server Management Studio (SSMS):

O bien, en Azure Data Studio:
A partir de SQL Server 2019 (15.x), puede habilitar una nueva marca de seguimiento 6408 globalmente mediante DBCC TRACEON. Por ejemplo:
DBCC TRACEON (6408, -1);
Esta marca de seguimiento solo funciona con planes de ejecución estimados y no tiene ningún efecto en los planes de ejecución reales. Esta marca de seguimiento expone información sobre el operador remote Query que muestra lo que sucede durante la fase de consulta remota.
Los planes de ejecución se leen de derecha a izquierda, como se indica en la dirección de las flechas. Si un operador está a la derecha de otro operador, se dice que lo "precede". Si un operador está a la izquierda de otro operador, se dice que está "detrás" de él.
- En SSMS, resalte la consulta y seleccione Mostrar plan de ejecución estimado en la barra de herramientas o use Ctrl+L.
- En Azure Data Studio, resalte la consulta y seleccione Explicar. A continuación, tenga en cuenta los siguientes escenarios para determinar si se produjo el procesamiento pushdown.
Cada uno de los ejemplos siguientes incluye la salida de SSMS y Azure Data Studio.
Aplicación descendente del predicado de filtro (vista con plan de ejecución)
Tenga en cuenta la consulta siguiente, que usa un predicado de filtro en la cláusula WHERE:
SELECT *
FROM [Person].[BusinessEntity] AS be
WHERE be.BusinessEntityID = 17907;
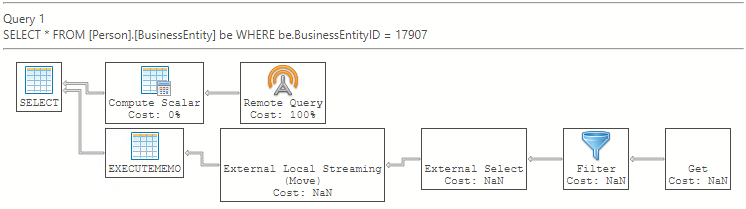
Si se está produciendo la propagación del predicado de filtro, el operador de filtro está antes que el operador externo. Cuando el operador de filtro está antes del operador externo, el filtrado se produjo antes de volver a seleccionarse desde el origen de datos externo, lo que indica que se ha insertado el predicado de filtro.
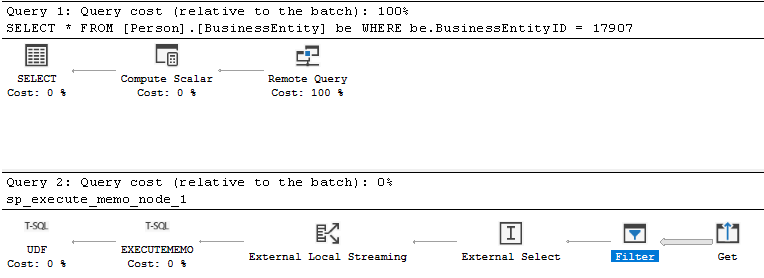
Con la inserción del predicado de filtro (vista con el plan de ejecución)
Con el indicador de seguimiento 6408 habilitado, ahora puedes ver información adicional en el resultado del plan de ejecución estimado. La salida varía entre SSMS y Azure Data Studio.
En SSMS, el plan de consulta remota se muestra en el plan de ejecución estimado como consulta 2 (sp_execute_memo_node_1) y corresponde al operador de consulta remota en la consulta 1. Por ejemplo:
En Azure Data Studio, la ejecución remota de consultas se representa en su lugar como un único plan de consulta. Por ejemplo:
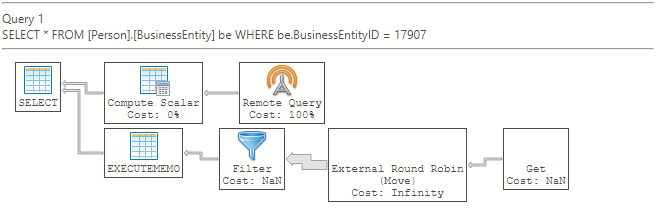
Sin aplicación del predicado de filtro (ver plan de ejecución)
Si no se produce el desplazamiento del predicado de filtro, el filtro se aplicará después del operador externo.
El plan de ejecución estimado de SSMS:

El plan de ejecución estimado de Azure Data Studio:
Optimización de JOIN
Tenga en cuenta la siguiente consulta que utiliza el operador JOIN para dos tablas externas en el mismo origen de datos externo:
SELECT be.BusinessEntityID, bea.AddressID
FROM [Person].[BusinessEntity] AS be
INNER JOIN [Person].[BusinessEntityAddress] AS bea
ON be.BusinessEntityID = bea.BusinessEntityID;
Si el JOIN se traslada al origen de datos externo, el operador JOIN estará antes del operador externo. En este ejemplo, tanto [BusinessEntity] como [BusinessEntityAddress] son tablas externas.
Con el empuje de la unión (vista con el plan de ejecución)
El plan de ejecución estimado de SSMS:
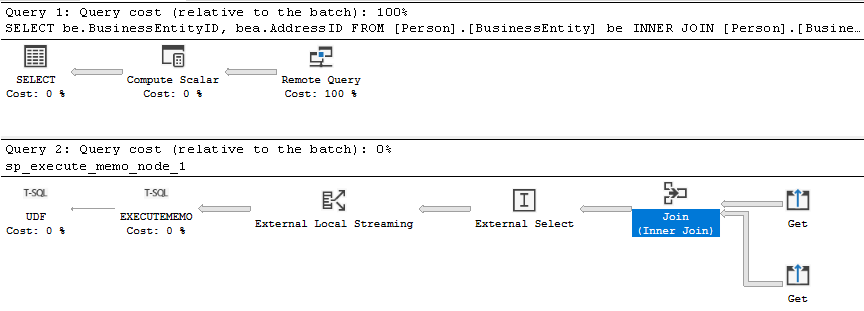
El plan de ejecución estimado de Azure Data Studio:
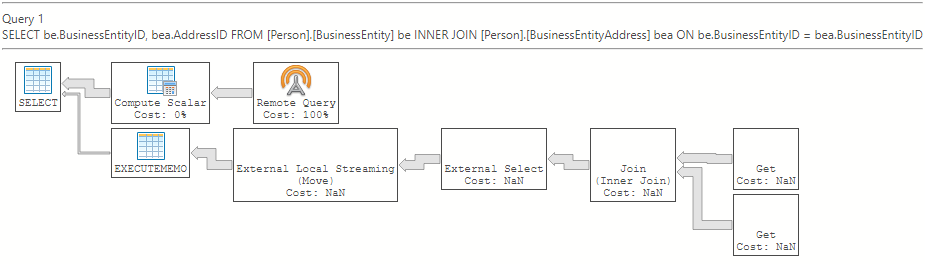
Sin la inserción de la combinación (ver con el plan de ejecución)
Si JOIN no se inserta en el origen de datos externo, el operador JOIN estará posicionado después del operador externo. En SSMS, el operador externo se encuentra en el plan de consulta para sp_execute_memo_node, que se encuentra en el operador de consulta remota de la consulta 1. En Azure Data Studio, el operador Join se encuentra después de los operadores externos.
El plan de ejecución estimado de SSMS:
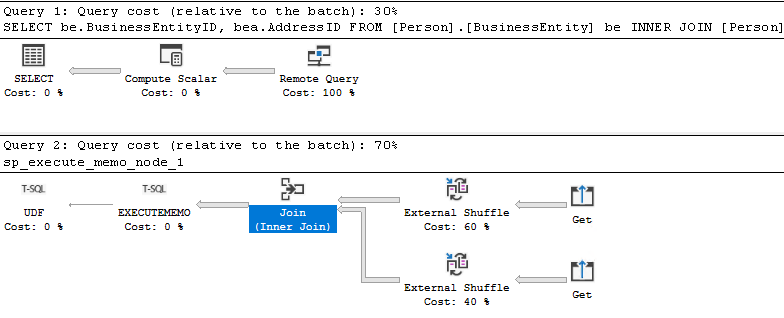
El plan de ejecución estimado de Azure Data Studio:
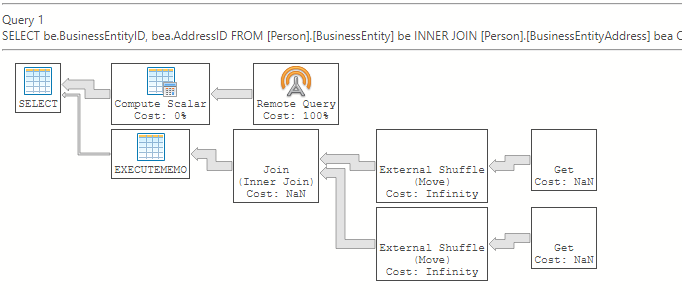
Inserción de agregaciones (vista con plan de ejecución)
Tenga en cuenta la consulta siguiente, que usa una función de agregado:
SELECT SUM([Quantity]) as Quant
FROM [AdventureWorks2022].[Production].[ProductInventory];
Con el desplazamiento de la agregación (vista del plan de ejecución)
Si se está produciendo el "pushdown" de la agregación, el operador de agregación precede al operador externo. Cuando el operador de agregación está antes del operador externo, la agregación se produjo antes de ser seleccionada de nuevo del origen de datos externo, lo que indica que la agregación se ha trasladado hacia abajo.
El plan de ejecución estimado de SSMS:
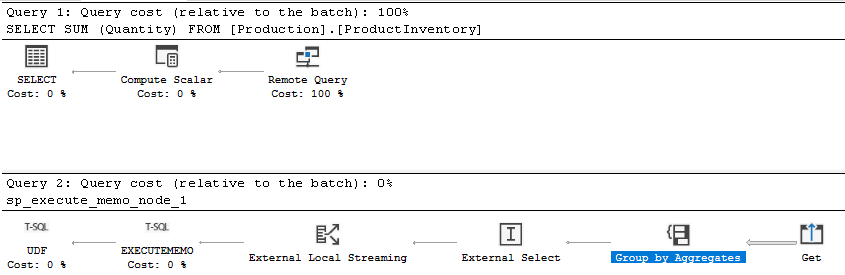
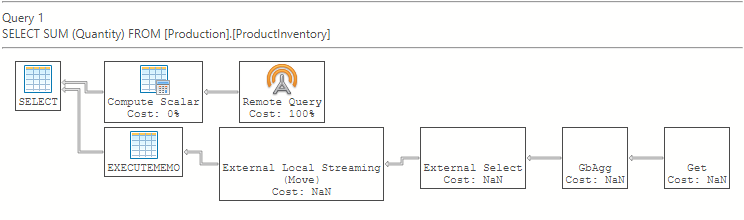
El plan de ejecución estimado de Azure Data Studio:
Sin empuje de agregaciones (vista con plan de ejecución)
Si no se está produciendo la propagación de la agregación, el operador de agregación aparecerá después del operador externo.
El plan de ejecución estimado de SSMS:
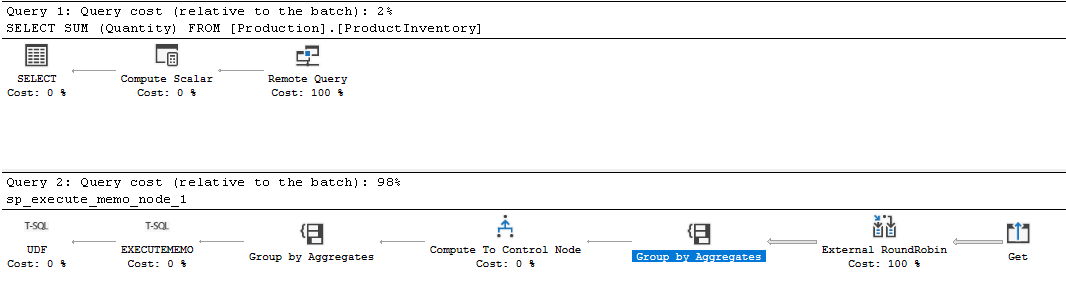
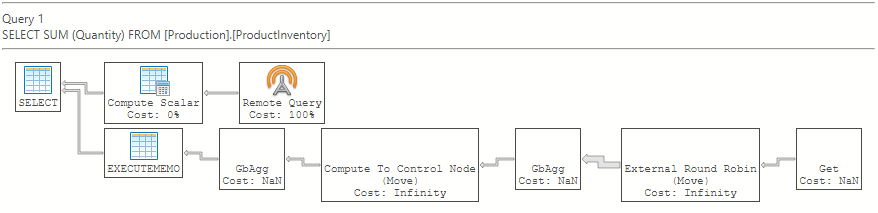
El plan de ejecución estimado de Azure Data Studio:
Uso de DMV
Con SQL Server 2019 (15.x) y versiones posteriores, la columna read_command de sys.dm_exec_external_work DMV muestra la consulta que se envía al origen de datos externo. Esto le permite determinar si se está produciendo un recorrido descendente, pero no expone el plan de ejecución. La visualización de la consulta remota no requiere TF6408.
Nota:
En el caso de Hadoop y Azure Storage, siempre read_command devuelve NULL.
Puede ejecutar la consulta siguiente y usar e start_time/end_timeread_command para identificar la consulta que se está investigando:
SELECT execution_id, start_time, end_time, read_command
FROM sys.dm_exec_external_work
ORDER BY execution_id desc;
Nota:
Una limitación del método sys.dm_exec_external_work es que el read_command campo de la DMV está limitado a 4000 caracteres. Si la consulta es lo suficientemente larga, read_command puede truncarse antes de que veas la cláusula WHERE/JOIN o función de agregación en read_command.
Desplazamiento del predicado de filtro (vista con DMV)
Considere la consulta usada en el ejemplo de predicado de filtro anterior:
SELECT *
FROM [Person].[BusinessEntity] be
WHERE be.BusinessEntityID = 17907;
Con la inserción del filtro (vista con DMV)
Puede determinar si está ocurriendo la propagación del predicado de filtro comprobando el read_command en la vista de gestión dinámica (DMV). Verá algo parecido a este ejemplo:
SELECT [T1_1].[BusinessEntityID] AS [BusinessEntityID], [T1_1].[rowguid] AS [rowguid],
[T1_1].[ModifiedDate] AS [ModifiedDate] FROM
(SELECT [T2_1].[BusinessEntityID] AS [BusinessEntityID], [T2_1].[rowguid] AS [rowguid],
[T2_1].[ModifiedDate] AS [ModifiedDate]
FROM [AdventureWorks2022].[Person].[BusinessEntity] AS T2_1
WHERE ([T2_1].[BusinessEntityID] = CAST ((17907) AS INT))) AS T1_1;
La cláusula WHERE está en el comando enviado al origen de datos externo, lo que significa que el predicado de filtro se está evaluando en el origen de datos externo. El filtrado del conjunto de datos se produjo en el origen de datos externo y polyBase recuperó solo el conjunto de datos filtrado.
Sin aplicación de filtro (vista con DMV)
Si no está ocurriendo la operación de pushdown, verá algo parecido a:
SELECT "BusinessEntityID","rowguid","ModifiedDate" FROM "AdventureWorks2022"."Person"."BusinessEntity"
No hay ninguna cláusula WHERE en el comando enviado al origen de datos externo, por lo que el predicado de filtro no se inserta. El filtrado en todo el conjunto de datos se produjo en SQL Server, después de que PolyBase recuperó el conjunto de datos.
Optimización de JOIN (vista con DMV)
Considere la consulta usada en el ejemplo anterior de JOIN:
SELECT be.BusinessEntityID, bea.AddressID
FROM [Person].[BusinessEntity] be
INNER JOIN [Person].[BusinessEntityAddress] bea ON be.BusinessEntityID = bea.BusinessEntityID;
Con la inserción de la combinación (vista con DMV)
Si JOIN se transfiere a un origen de datos externo, verá algo parecido a:
SELECT [T1_1].[BusinessEntityID] AS [BusinessEntityID], [T1_1].[AddressID] AS [AddressID]
FROM (SELECT [T2_2].[BusinessEntityID] AS [BusinessEntityID], [T2_1].[AddressID] AS [AddressID]
FROM [AdventureWorks2022].[Person].[BusinessEntityAddress] AS T2_1
INNER JOIN [AdventureWorks2022].[Person].[BusinessEntity] AS T2_2
ON ([T2_1].[BusinessEntityID] = [T2_2].[BusinessEntityID])) AS T1_1;
La cláusula JOIN está en el comando enviado al origen de datos externo, por lo que se inserta JOIN. La combinación en el conjunto de datos se produjo en el origen de datos externo y solo el conjunto de datos que coincide con la condición de combinación se recuperó mediante PolyBase.
Sin optimización del join (vista con DMV)
Si no se está produciendo la inserción de la combinación, verá que hay dos consultas diferentes ejecutadas en el origen de datos externo:
SELECT [T1_1].[BusinessEntityID] AS [BusinessEntityID], [T1_1].[AddressID] AS [AddressID]
FROM [AdventureWorks2022].[Person].[BusinessEntityAddress] AS T1_1;
SELECT [T1_1].[BusinessEntityID] AS [BusinessEntityID] FROM [AdventureWorks2022].[Person].[BusinessEntity] AS T1_1;
La combinación de los dos conjuntos de datos se produjo en el lado de SQL Server, después de que PolyBase recupere ambos conjuntos de datos.
Inserción de agregaciones (vista con DMV)
Tenga en cuenta la consulta siguiente, que usa una función de agregado:
SELECT SUM([Quantity]) as Quant
FROM [AdventureWorks2022].[Production].[ProductInventory];
Con despliegue de agregación (vista con DMV)
Si se está produciendo una optimización por pushdown de la agregación, verá la función de agregación en read_command. Por ejemplo:
SELECT [T1_1].[col] AS [col] FROM (SELECT SUM([T2_1].[Quantity]) AS [col]
FROM [AdventureWorks2022].[Production].[ProductInventory] AS T2_1) AS T1_1
La función de agregación está en el comando enviado al origen de datos externo, por lo que la agregación se delega. La agregación se produjo en el origen de datos externo y polyBase recuperó solo el conjunto de datos agregado.
Sin inserción de agregación (vista con DMV)
Si no se está produciendo la transferencia de la agregación, no verá la función de agregación en read_command. Por ejemplo:
SELECT "Quantity" FROM "AdventureWorks2022"."Production"."ProductInventory"
La agregación se realizó en SQL Server, después de recuperar el conjunto de datos no agregado por PolyBase.