What is Azure Cosmos DB analytical store?
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Gremlin
Gremlin
Important
Mirroring Azure Cosmos DB in Microsoft Fabric is now available for NoSql API. This feature provides all the capabilities of Azure Synapse Link with better analytical performance, ability to unify your data estate with Fabric OneLake and open access to your data in Delta Parquet format. If you are considering Azure Synapse Link, we recommend that you try mirroring to assess overall fit for your organization. Get started wtih mirroring in Microsoft Fabric.
To get started with Azure Synapse Link, please visit “Getting started with Azure Synapse Link”
Azure Cosmos DB analytical store is a fully isolated column store for enabling large-scale analytics against operational data in your Azure Cosmos DB, without any impact to your transactional workloads.
Azure Cosmos DB transactional store is schema-agnostic, and it allows you to iterate on your transactional applications without having to deal with schema or index management. In contrast to this, Azure Cosmos DB analytical store is schematized to optimize for analytical query performance. This article describes in detailed about analytical storage.
Challenges with large-scale analytics on operational data
The multi-model operational data in an Azure Cosmos DB container is internally stored in an indexed row-based "transactional store". Row store format is designed to allow fast transactional reads and writes in the order-of-milliseconds response times, and operational queries. If your dataset grows large, complex analytical queries can be expensive in terms of provisioned throughput on the data stored in this format. High consumption of provisioned throughput in turn, impacts the performance of transactional workloads that are used by your real-time applications and services.
Traditionally, to analyze large amounts of data, operational data is extracted from Azure Cosmos DB's transactional store and stored in a separate data layer. For example, the data is stored in a data warehouse or data lake in a suitable format. This data is later used for large-scale analytics and analyzed using compute engines such as the Apache Spark clusters. The separation of analytical from operational data results in delays for analysts that want to use the most recent data.
The ETL pipelines also become complex when handling updates to the operational data when compared to handling only newly ingested operational data.
Column-oriented analytical store
Azure Cosmos DB analytical store addresses the complexity and latency challenges that occur with the traditional ETL pipelines. Azure Cosmos DB analytical store can automatically sync your operational data into a separate column store. Column store format is suitable for large-scale analytical queries to be performed in an optimized manner, resulting in improving the latency of such queries.
Using Azure Synapse Link, you can now build no-ETL HTAP solutions by directly linking to Azure Cosmos DB analytical store from Azure Synapse Analytics. It enables you to run near real-time large-scale analytics on your operational data.
Features of analytical store
When you enable analytical store on an Azure Cosmos DB container, a new column-store is internally created based on the operational data in your container. This column store is persisted separately from the row-oriented transactional store for that container, in a storage account that is fully managed by Azure Cosmos DB, in an internal subscription. Customers don't need to spend time with storage administration. The inserts, updates, and deletes to your operational data are automatically synced to analytical store. You don't need the Change Feed or ETL to sync the data.
Column store for analytical workloads on operational data
Analytical workloads typically involve aggregations and sequential scans of selected fields. The data analytical store is stored in a column-major order, allowing values of each field to be serialized together, where applicable. This format reduces the IOPS required to scan or compute statistics over specific fields. It dramatically improves the query response times for scans over large data sets.
For example, if your operational tables are in the following format:
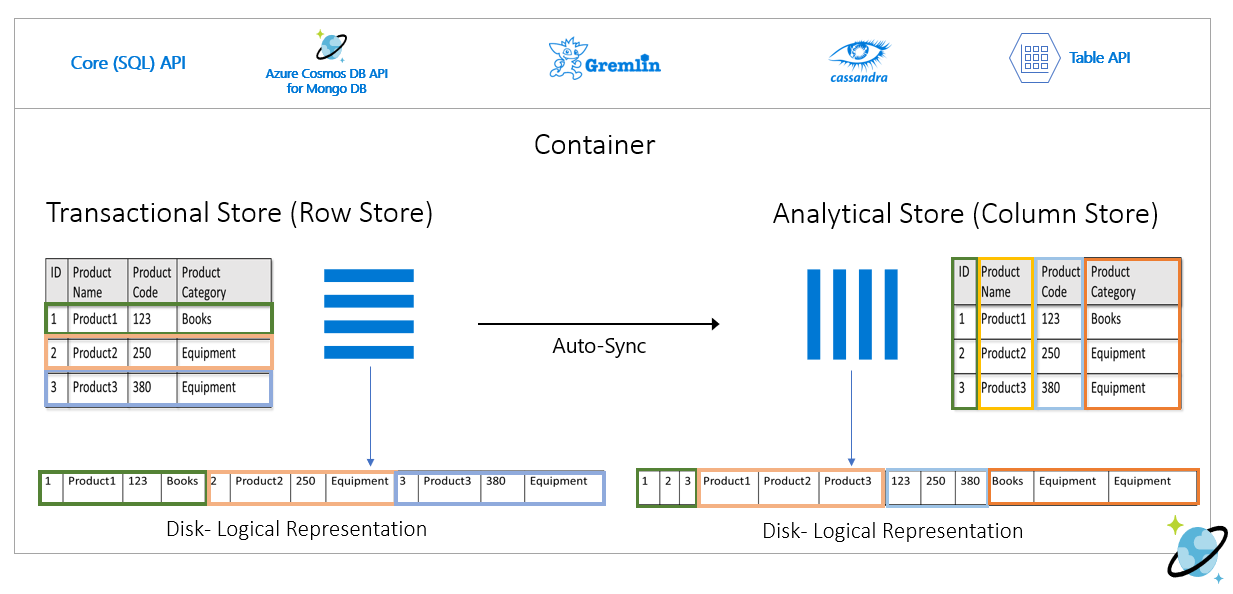
The row store persists the above data in a serialized format, per row, on the disk. This format allows for faster transactional reads, writes, and operational queries, such as, "Return information about Product 1". However, as the dataset grows large and if you want to run complex analytical queries on the data it can be expensive. For example, if you want to get "the sales trends for a product under the category named 'Equipment' across different business units and months", you need to run a complex query. Large scans on this dataset can get expensive in terms of provisioned throughput and can also impact the performance of the transactional workloads powering your real-time applications and services.
Analytical store, which is a column store, is better suited for such queries because it serializes similar fields of data together and reduces the disk IOPS.
The following image shows transactional row store vs. analytical column store in Azure Cosmos DB:
Decoupled performance for analytical workloads
There's no impact on the performance of your transactional workloads due to analytical queries, as the analytical store is separate from the transactional store. Analytical store doesn't need separate request units (RUs) to be allocated.
Auto-Sync
Auto-Sync refers to the fully managed capability of Azure Cosmos DB where the inserts, updates, deletes to operational data are automatically synced from transactional store to analytical store in near real time. Auto-sync latency is usually within 2 minutes. In cases of shared throughput database with a large number of containers, auto-sync latency of individual containers could be higher and take up to 5 minutes.
At the end of each execution of the automatic sync process, your transactional data will be immediately available for Azure Synapse Analytics runtimes:
Azure Synapse Analytics Spark pools can read all data, including the most recent updates, through Spark tables, which are updated automatically, or via the
spark.readcommand, that always reads the last state of the data.Azure Synapse Analytics SQL Serverless pools can read all data, including the most recent updates, through views, which are updated automatically, or via
SELECTtogether with theOPENROWSETcommands, which always reads the latest status of the data.
Note
Your transactional data will be synchronized to analytical store even if your transactional time-to-live (TTL) is smaller than 2 minutes.
Note
Please note that if you delete your container, analytical store is also deleted.
Scalability & elasticity
Azure Cosmos DB transactional store uses horizontal partitioning to elastically scale the storage and throughput without any downtime. Horizontal partitioning in the transactional store provides scalability & elasticity in auto-sync to ensure data is synced to the analytical store in near real time. The data sync happens regardless of the transactional traffic throughput, whether it's 1000 operations/sec or 1 million operations/sec, and it doesn't impact the provisioned throughput in the transactional store.
Automatically handle schema updates
Azure Cosmos DB transactional store is schema-agnostic, and it allows you to iterate on your transactional applications without having to deal with schema or index management. In contrast to this, Azure Cosmos DB analytical store is schematized to optimize for analytical query performance. With the auto-sync capability, Azure Cosmos DB manages the schema inference over the latest updates from the transactional store. It also manages the schema representation in the analytical store out-of-the-box which, includes handling nested data types.
As your schema evolves, and new properties are added over time, the analytical store automatically presents a unionized schema across all historical schemas in the transactional store.
Note
In the context of analytical store, we consider the following structures as property:
- JSON "elements" or "string-value pairs separated by a
:". - JSON objects, delimited by
{and}. - JSON arrays, delimited by
[and].
Schema constraints
The following constraints are applicable on the operational data in Azure Cosmos DB when you enable analytical store to automatically infer and represent the schema correctly:
You can have a maximum of 1000 properties across all nested levels in the document schema and a maximum nesting depth of 127.
- Only the first 1000 properties are represented in the analytical store.
- Only the first 127 nested levels are represented in the analytical store.
- The first level of a JSON document is its
/root level. - Properties in the first level of the document will be represented as columns.
Sample scenarios:
- If your document's first level has 2000 properties, the sync process will represent the first 1000 of them.
- If your documents have five levels with 200 properties in each one, the sync process will represent all properties.
- If your documents have 10 levels with 400 properties in each one, the sync process will fully represent the two first levels and only half of the third level.
The hypothetical document below contains four properties and three levels.
- The levels are
root,myArray, and the nested structure within themyArray. - The properties are
id,myArray,myArray.nested1, andmyArray.nested2. - The analytical store representation will have two columns,
id, andmyArray. You can use Spark or T-SQL functions to also expose the nested structures as columns.
- The levels are
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
While JSON documents (and Azure Cosmos DB collections/containers) are case-sensitive from the uniqueness perspective, analytical store isn't.
- In the same document: Properties names in the same level should be unique when compared case-insensitively. For example, the following JSON document has "Name" and "name" in the same level. While it's a valid JSON document, it doesn't satisfy the uniqueness constraint and hence won't be fully represented in the analytical store. In this example, "Name" and "name" are the same when compared in a case-insensitive manner. Only
"Name": "fred"will be represented in analytical store, because it's the first occurrence. And"name": "john"won't be represented at all.
{"id": 1, "Name": "fred", "name": "john"}- In different documents: Properties in the same level and with the same name, but in different cases, will be represented within the same column, using the name format of the first occurrence. For example, the following JSON documents have
"Name"and"name"in the same level. Since the first document format is"Name", this is what will be used to represent the property name in analytical store. In other words, the column name in analytical store will be"Name". Both"fred"and"john"will be represented, in the"Name"column.
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- In the same document: Properties names in the same level should be unique when compared case-insensitively. For example, the following JSON document has "Name" and "name" in the same level. While it's a valid JSON document, it doesn't satisfy the uniqueness constraint and hence won't be fully represented in the analytical store. In this example, "Name" and "name" are the same when compared in a case-insensitive manner. Only
The first document of the collection defines the initial analytical store schema.
- Documents with more properties than the initial schema will generate new columns in analytical store.
- Columns can't be removed.
- The deletion of all documents in a collection doesn't reset the analytical store schema.
- There's not schema versioning. The last version inferred from transactional store is what you'll see in analytical store.
Currently Azure Synapse Spark can't read properties that contain some special characters in their names, listed below. Azure Synapse SQL serverless isn't affected.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Note
White spaces are also listed in the Spark error message returned when you reach this limitation. But we have added a special treatment for white spaces, please check out more details in the items below.
- If you have properties names using the characters listed above, the alternatives are:
- Change your data model in advance to avoid these characters.
- Since currently we don't support schema reset, you can change your application to add a redundant property with a similar name, avoiding these characters.
- Use Change Feed to create a materialized view of your container without these characters in properties names.
- Use the
dropColumnSpark option to ignore the affected columns and load all other columns into a DataFrame. The syntax is:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark now supports properties with white spaces in their names. For that, you need to use the
allowWhiteSpaceInFieldNamesSpark option to load the affected columns into a DataFrame, keeping the original name. The syntax is:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
The following BSON datatypes aren't supported and won't be represented in analytical store:
- Decimal128
- Regular Expression
- DB Pointer
- JavaScript
- Symbol
- MinKey/MaxKey
When using DateTime strings that follow the ISO 8601 UTC standard, expect the following behavior:
- Spark pools in Azure Synapse represent these columns as
string. - SQL serverless pools in Azure Synapse represent these columns as
varchar(8000).
- Spark pools in Azure Synapse represent these columns as
Properties with
UNIQUEIDENTIFIER (guid)types are represented asstringin analytical store and should be converted toVARCHARin SQL or tostringin Spark for correct visualization.SQL serverless pools in Azure Synapse support result sets with up to 1000 columns, and exposing nested columns also counts towards that limit. It is a good practice to consider this information in your transactional data architecture and modeling.
If you rename a property, in one or many documents, it will be considered a new column. If you execute the same rename in all documents in the collection, all data will be migrated to the new column and the old column will be represented with
NULLvalues.
Schema representation
There are two methods of schema representation in the analytical store, valid for all containers in the database account. They have tradeoffs between the simplicity of query experience versus the convenience of a more inclusive columnar representation for polymorphic schemas.
- Well-defined schema representation, default option for API for NoSQL and Gremlin accounts.
- Full fidelity schema representation, default option for API for MongoDB accounts.
Well-defined schema representation
The well-defined schema representation creates a simple tabular representation of the schema-agnostic data in the transactional store. The well-defined schema representation has the following considerations:
- The first document defines the base schema and properties must always have the same type across all documents. The only exceptions are:
- From
NULLto any other data type. The first non-null occurrence defines the column data type. Any document not following the first non-null datatype won't be represented in analytical store. - From
floattointeger. All documents are represented in analytical store. - From
integertofloat. All documents are represented in analytical store. However, to read this data with Azure Synapse SQL serverless pools, you must use a WITH clause to convert the column tovarchar. And after this initial conversion, it's possible to convert it again to a number. Please check the example below, where num initial value was an integer and the second one was a float.
- From
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Properties that don't follow the base schema data type won't be represented in analytical store. For example, consider the documents below: the first one defined the analytical store base schema. The second document, where
idis"2", doesn't have a well-defined schema since property"code"is a string and the first document has"code"as a number. In this case, the analytical store registers the data type of"code"asintegerfor lifetime of the container. The second document will still be included in analytical store, but its"code"property won't.{"id": "1", "code":123}{"id": "2", "code": "123"}
Note
The condition above doesn't apply for NULL properties. For example, {"a":123} and {"a":NULL} is still well-defined.
Note
The condition above doesn't change if you update "code" of document "1" to a string in your transactional store. In analytical store, "code" will be kept as integer since currently we don't support schema reset.
- Array types must contain a single repeated type. For example,
{"a": ["str",12]}isn't a well-defined schema because the array contains a mix of integer and string types.
Note
If the Azure Cosmos DB analytical store follows the well-defined schema representation and the specification above is violated by certain items, those items won't be included in the analytical store.
Expect different behavior in regard to different types in well-defined schema:
- Spark pools in Azure Synapse represent these values as
undefined. - SQL serverless pools in Azure Synapse represent these values as
NULL.
- Spark pools in Azure Synapse represent these values as
Expect different behavior in regard to explicit
NULLvalues:- Spark pools in Azure Synapse read these values as
0(zero), and asundefinedas soon as the column has a non-null value. - SQL serverless pools in Azure Synapse read these values as
NULL.
- Spark pools in Azure Synapse read these values as
Expect different behavior in regard to missing columns:
- Spark pools in Azure Synapse represent these columns as
undefined. - SQL serverless pools in Azure Synapse represent these columns as
NULL.
- Spark pools in Azure Synapse represent these columns as
Representation challenges workarounds
It is possible that an old document, with an incorrect schema, was used to create your container's analytical store base schema. Based on all the rules presented above, you may be receiving NULL for certain properties when querying your analytical store using Azure Synapse Link. To delete or update the problematic documents won't help because base schema reset isn't currently supported. The possible solutions are:
- To migrate the data to a new container, making sure that all documents have the correct schema.
- To abandon the property with the wrong schema and add a new one with another name that has the correct schema in all documents. Example: You have billions of documents in the Orders container where the status property is a string. But the first document in that container has status defined with integer. So, one document will have status correctly represented and all other documents will have
NULL. You can add the status2 property to all documents and start to use it, instead of the original property.
Full fidelity schema representation
The full fidelity schema representation is designed to handle the full breadth of polymorphic schemas in the schema-agnostic operational data. In this schema representation, no items are dropped from the analytical store even if the well-defined schema constraints (that is no mixed data type fields nor mixed data type arrays) are violated.
This is achieved by translating the leaf properties of the operational data into the analytical store as JSON key-value pairs, where the datatype is the key and the property content is the value. This JSON object representation allows queries without ambiguity, and you can individually analyze each datatype.
In other words, in the full fidelity schema representation, each datatype of each property of each document will generate a key-valuepair in a JSON object for that property. Each of them count as one of the 1000 maximum properties limit.
For example, let's take the following sample document in the transactional store:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
The nested object address is a property in the root level of the document and will be represented as a column. Each leaf property in the address object will be represented as a JSON object: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Unlike the well-defined schema representation, the full fidelity method allows variation in datatypes. If the next document in this collection of the example above has streetNo as a string, it will be represented in analytical store as "streetNo":{"string":15850}. In well-defined schema method, it wouldn't be represented.
Datatypes map for full fidelity schema
Here's a map of MongoDB data types and their representations in the analytical store in full fidelity schema representation. The map below isn't valid for NoSQL API accounts.
| Original data type | Suffix | Example |
|---|---|---|
| Double | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| Binary | ".binary" | 0 |
| Boolean | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| Timestamp | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Document | ".object" | {"a": "a"} |
Expect different behavior in regard to explicit
NULLvalues:- Spark pools in Azure Synapse will read these values as
0(zero). - SQL serverless pools in Azure Synapse will read these values as
NULL.
- Spark pools in Azure Synapse will read these values as
Expect different behavior in regard to missing columns:
- Spark pools in Azure Synapse will represent these columns as
undefined. - SQL serverless pools in Azure Synapse will represent these columns as
NULL.
- Spark pools in Azure Synapse will represent these columns as
Expect different behavior in regard to
timestampvalues:- Spark pools in Azure Synapse will read these values as
TimestampType,DateType, orFloat. It depends on the range and how the timestamp was generated. - SQL Serverless pools in Azure Synapse will read these values as
DATETIME2, ranging from0001-01-01through9999-12-31. Values beyond this range are not supported and will cause an execution failure for your queries. If this is your case, you can:- Remove the column from the query. To keep the representation, you can create a new property mirroring that column but within the supported range. And use it in your queries.
- Use Change Data Capture from analytical store, at no RUs cost, to transform and load the data into a new format, within one of the supported sinks.
- Spark pools in Azure Synapse will read these values as
Using full fidelity schema with Spark
Spark will manage each datatype as a column when loading into a DataFrame. Let's assume a collection with the documents below.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
While the first document has rating as a number and timestamp in utc format, the second document has rating and timestamp as strings. Assuming that this collection was loaded into DataFrame without any data transformation, the output of the df.printSchema() is:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
In well-defined schema representation, both rating and timestamp of the second document wouldn't be represented. In full fidelity schema, you can use the following examples to individually access to each value of each datatype.
In the example below, we can use PySpark to run an aggregation:
df.groupBy(df.item.string).sum().show()
In the example below, we can use PySQL to run another aggregation:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Using full fidelity schema with SQL
You can use the following syntax example, with the same documents of the Spark example above:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
You can implement transformations using cast, convert or any other T-SQL function to manipulate your data. You can also hide complex datatype structures by using views.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Working with MongoDB _id field
MongoDB _id field is fundamental to every collection in MongoDB and originally has a hexadecimal representation. As you can see in the table above, full fidelity schema will preserve its characteristics, creating a challenge for its visualization in Azure Synapse Analytics. For correct visualization, you must convert the _id datatype as below:
Working with MongoDB _id field in Spark
The example below works on Spark 2.x and 3.x versions:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Working with MongoDB _id field in SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Working with MongoDB id field
The id property in MongoDB containers is automatically overridden with the Base64 representation of the "_id" property both in analytical store. The "id" field is intended for internal use by MongoDB applications. Currently, the only workaround is to rename the "id" property to something other than "id".
Full fidelity schema for API for NoSQL or Gremlin accounts
It's possible to use full fidelity Schema for API for NoSQL accounts, instead of the default option, by setting the schema type when enabling Synapse Link on an Azure Cosmos DB account for the first time. Here are the considerations about changing the default schema representation type:
- Currently, if you enable Synapse Link in your NoSQL API account using the Azure portal, it will be enabled as well-defined schema.
- Currently, if you want to use full fidelity schema with NoSQL or Gremlin API accounts, you have to set it at account level in the same CLI or PowerShell command that will enable Synapse Link at account level.
- Currently Azure Cosmos DB for MongoDB isn't compatible with this possibility of changing the schema representation. All MongoDB accounts have full fidelity schema representation type.
- Full Fidelity schema data types map mentioned above isn't valid for NoSQL API accounts that use JSON datatypes. As an example,
floatandintegervalues are represented asnumin analytical store. - It's not possible to reset the schema representation type, from well-defined to full fidelity or vice-versa.
- Currently, containers schemas in analytical store are defined when the container is created, even if Synapse Link has not been enabled in the database account.
- Containers or graphs created before Synapse Link was enabled with full fidelity schema at account level will have well-defined schema.
- Containers or graphs created after Synapse Link was enabled with full fidelity schema at account level will have full fidelity schema.
The schema representation type decision must be made at the same time that Synapse Link is enabled on the account, using Azure CLI or PowerShell.
With the Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Note
In the command above, replace create with update for existing accounts.
With the PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Note
In the command above, replace New-AzCosmosDBAccount with Update-AzCosmosDBAccount for existing accounts.
Analytical Time-to-Live (TTL)
Analytical TTL (ATTL) indicates how long data should be retained in your analytical store, for a container.
Analytical store is enabled when ATTL is set with a value other than NULL and 0. When enabled, inserts, updates, deletes to operational data are automatically synced from transactional store to analytical store, irrespective of the transactional TTL (TTTL) configuration. The retention of this transactional data in analytical store can be controlled at container level by the AnalyticalStoreTimeToLiveInSeconds property.
The possible ATTL configurations are:
If the value is set to
0: the analytical store is disabled and no data is replicated from transactional store to analytical store. Please open a support case to disable analytical store in your containers.If the field is omitted, nothing happens and the previous value is kept.
If the value is set to
-1: the analytical store retains all historical data, irrespective of the retention of the data in the transactional store. This setting indicates that the analytical store has infinite retention of your operational dataIf the value is set to any positive integer
nnumber: items will expire from the analytical storenseconds after their last modified time in the transactional store. This setting can be leveraged if you want to retain your operational data for a limited period of time in the analytical store, irrespective of the retention of the data in the transactional store
Some points to consider:
- After the analytical store is enabled with an ATTL value, it can be updated to a different valid value later.
- While TTTL can be set at the container or item level, ATTL can only be set at the container level currently.
- You can achieve longer retention of your operational data in the analytical store by setting ATTL >= TTTL at the container level.
- The analytical store can be made to mirror the transactional store by setting ATTL = TTTL.
- If you have ATTL bigger than TTTL, at some point in time you'll have data that only exists in analytical store. This data is read only.
- Currently we don't delete any data from analytical store. If you set your ATTL to any positive integer, the data won't be included in your queries and you won't be billed for it. But if you change ATTL back to
-1, all the data will show up again, you will start to be billed for all the data volume.
How to enable analytical store on a container:
From the Azure portal, the ATTL option, when turned on, is set to the default value of -1. You can change this value to 'n' seconds, by navigating to container settings under Data Explorer.
From the Azure Management SDK, Azure Cosmos DB SDKs, PowerShell, or Azure CLI, the ATTL option can be enabled by setting it to either -1 or 'n' seconds.
To learn more, see how to configure analytical TTL on a container.
Cost-effective analytics on historical data
Data tiering refers to the separation of data between storage infrastructures optimized for different scenarios. Thereby improving the overall performance and cost-effectiveness of the end-to-end data stack. With analytical store, Azure Cosmos DB now supports automatic tiering of data from the transactional store to analytical store with different data layouts. With analytical store optimized in terms of storage cost compared to the transactional store, allows you to retain much longer horizons of operational data for historical analysis.
After the analytical store is enabled, based on the data retention needs of the transactional workloads, you can configure transactional TTL property to have records automatically deleted from the transactional store after a certain time period. Similarly, the analytical TTL allows you to manage the lifecycle of data retained in the analytical store, independent from the transactional store. By enabling analytical store and configuring transactional and analytical TTL properties, you can seamlessly tier and define the data retention period for the two stores.
Note
When analytical TTL is set to a value larger than transactional TTL value, your container will have data that only exists in analytical store. This data is read only and currently we don't support document level TTL in analytical store. If your container data may need an update or a delete at some point in time in the future, don't use analytical TTL bigger than transactional TTL. This capability is recommended for data that won't need updates or deletes in the future.
Note
If your scenario doesn't demand physical deletes, you can adopt a logical delete/update approach. Insert in transactional store another version of the same document that only exists in analytical store but needs a logical delete/update. Maybe with a flag indicating that it's a delete or an update of an expired document. Both versions of the same document will co-exist in analytical store, and your application should only consider the last one.
Resilience
Analytical store relies on Azure Storage and offers the following protection against physical failure:
- By default, Azure Cosmos DB database accounts allocate analytical store in Locally Redundant Storage (LRS) accounts. LRS provides at least 99.999999999% (11 nines) durability of objects over a given year.
- If any geo-region of the database account is configured for zone-redundancy, it is allocated in Zone-redundant Storage (ZRS) accounts. You need to enable Availability Zones on a region of their Azure Cosmos DB database account to have analytical data of that region stored in Zone-redundant Storage. ZRS offers durability for storage resources of at least 99.9999999999% (12 9's) over a given year.
For more information about Azure Storage durability, see this link.
Backup
Although analytical store has built-in protection against physical failures, backup can be necessary for accidental deletes or updates in transactional store. In those cases, you can restore a container and use the restored container to backfill the data in the original container, or fully rebuild analytical store if necessary.
Note
Currently analytical store isn't backed up, therefore it can't be restored. Your backup policy can't be planned relying on that.
Synapse Link, and analytical store by consequence, has different compatibility levels with Azure Cosmos DB backup modes:
- Periodic backup mode is fully compatible with Synapse Link and these 2 features can be used in the same database account.
- Synapse Link for database accounts using continuous backup mode is GA.
- Continuous backup mode for Synapse Link enabled accounts is in public preview. Currently, you can't migrate to continuous backup if you disabled Synapse Link on any of your collections in a Cosmos DB account.
Backup policies
There are two possible backup policies and to understand how to use them, the following details about Azure Cosmos DB backups are very important:
- The original container is restored without analytical store in both backup modes.
- Azure Cosmos DB doesn't support containers overwrite from a restore.
Now let's see how to use backup and restores from the analytical store perspective.
Restoring a container with TTTL >= ATTL
When transactional TTL is equal or bigger than analytical TTL, all data in analytical store still exists in transactional store. In case of a restore, you have two possible situations:
- To use the restored container as a replacement for the original container. To rebuild analytical store, just enable Synapse Link at account level and container level.
- To use the restored container as a data source to backfill or update the data in the original container. In this case, analytical store will automatically reflect the data operations.
Restoring a container with TTTL < ATTL
When transactional TTL is smaller than analytical TTL, some data only exists in analytical store and won't be in the restored container. Again, you have two possible situations:
- To use the restored container as a replacement for the original container. In this case, when you enable Synapse Link at container level, only the data that was in transactional store will be included in the new analytical store. But please note that the analytical store of the original container remains available for queries as long as the original container exists. You may want to change your application to query both.
- To use the restored container as a data source to backfill or update the data in the original container:
- Analytical store will automatically reflect the data operations for the data that is in transactional store.
- If you re-insert data that was previously removed from transactional store due to
transactional TTL, this data will be duplicated in analytical store.
Example:
- Container
OnlineOrdershas TTTL set to one month and ATTL set for one year. - When you restore it to
OnlineOrdersNewand turn on analytical store to rebuild it, there will be only one month of data in both transactional and analytical store. - Original container
OnlineOrdersisn't deleted and its analytical store is still available. - New data is only ingested into
OnlineOrdersNew. - Analytical queries will do a UNION ALL from analytical stores while the original data is still relevant.
If you want to delete the original container but don't want to lose its analytical store data, you can persist the analytical store of the original container in another Azure data service. Synapse Analytics has the capability to perform joins between data stored in different locations. An example: A Synapse Analytics query joins analytical store data with external tables located in Azure Blob Storage, Azure Data Lake Store, etc.
It's important to note that the data in the analytical store has a different schema than what exists in the transactional store. While you can generate snapshots of your analytical store data, and export it to any Azure Data service, at no RUs costs, we can't guarantee the use of this snapshot to back feed the transactional store. This process isn't supported.
Global distribution
If you have a globally distributed Azure Cosmos DB account, after you enable analytical store for a container, it will be available in all regions of that account. Any changes to operational data are globally replicated in all regions. You can run analytical queries effectively against the nearest regional copy of your data in Azure Cosmos DB.
Partitioning
Analytical store partitioning is completely independent of partitioning in the transactional store. By default, data in analytical store isn't partitioned. If your analytical queries have frequently used filters, you have the option to partition based on these fields for better query performance. To learn more, see introduction to custom partitioning and how to configure custom partitioning.
Security
Authentication with the analytical store is the same as the transactional store for a given database.
Network isolation using private endpoints - You can control network access to the data in the transactional and analytical stores independently. Network isolation is done using separate managed private endpoints for each store, within managed virtual networks in Azure Synapse workspaces. To learn more, see how to Configure private endpoints for analytical store article.
Data encryption at rest - Your analytical store encryption is enabled by default.
Data encryption with customer-managed keys - You can seamlessly encrypt the data across transactional and analytical stores using the same customer-managed keys in an automatic and transparent manner. Azure Synapse Link only supports configuring customer-managed keys using your Azure Cosmos DB account's managed identity. You must configure your account's managed identity in your Azure Key Vault access policy before enabling Azure Synapse Link on your account. To learn more, see how to Configure customer-managed keys using Azure Cosmos DB accounts' managed identities article.
Note
If you change your database account from First Party to System or User Assigned Identy, and enable Azure Synapse Link in your database account, you won't be able to return to First Party identity since you can't disable Synapse Link from your database account.
Support for multiple Azure Synapse Analytics runtimes
The analytical store is optimized to provide scalability, elasticity, and performance for analytical workloads without any dependency on the compute run-times. The storage technology is self-managed to optimize your analytics workloads without manual efforts.
Data in Azure Cosmos DB analytical store can be queried simultaneously from the different analytics runtimes supported by Azure Synapse Analytics. Azure Synapse Analytics supports Apache Spark and serverless SQL pool with Azure Cosmos DB analytical store.
Note
You can only read from analytical store using Azure Synapse Analytics runtimes. And the opposite is also true, Azure Synapse Analytics runtimes can only read from analytical store. Only the auto-sync process can change data in analytical store. You can write data back to Azure Cosmos DB transactional store using Azure Synapse Analytics Spark pool, using the built-in Azure Cosmos DB OLTP SDK.
Pricing
Analytical store follows a consumption-based pricing model where you're charged for:
Storage: the volume of the data retained in the analytical store every month including historical data as defined by analytical TTL.
Analytical write operations: the fully managed synchronization of operational data updates to the analytical store from the transactional store (auto-sync)
Analytical read operations: the read operations performed against the analytical store from Azure Synapse Analytics Spark pool and serverless SQL pool run times.
Analytical store pricing is separate from the transaction store pricing model. There's no concept of provisioned RUs in the analytical store. See Azure Cosmos DB pricing page for full details on the pricing model for analytical store.
Data in the analytics store can only be accessed through Azure Synapse Link, which is done in the Azure Synapse Analytics runtimes: Azure Synapse Apache Spark pools and Azure Synapse serverless SQL pools. See Azure Synapse Analytics pricing page for full details on the pricing model to access data in analytical store.
In order to get a high-level cost estimate to enable analytical store on an Azure Cosmos DB container, from the analytical store perspective, you can use the Azure Cosmos DB Capacity planner and get an estimate of your analytical storage and write operations costs.
Analytical store read operations estimates aren't included in the Azure Cosmos DB cost calculator since they are a function of your analytical workload. But as a high-level estimate, scan of 1 TB of data in analytical store typically results in 130,000 analytical read operations, and results in a cost of $0.065. As an example, if you use Azure Synapse serverless SQL pools to perform this scan of 1 TB, it will cost $5.00 according to Azure Synapse Analytics pricing page. The final total cost for this 1 TB scan would be $5.065.
While the above estimate is for scanning 1TB of data in analytical store, applying filters reduces the volume of data scanned and this determines the exact number of analytical read operations given the consumption pricing model. A proof-of-concept around the analytical workload would provide a finer estimate of analytical read operations. This estimate doesn't include the cost of Azure Synapse Analytics.
Next steps
To learn more, see the following docs:
Check out the training module on how to Design hybrid transactional and analytical processing using Azure Synapse Analytics
Frequently asked questions about Synapse Link for Azure Cosmos DB