Copy data from Amazon Redshift using Azure Data Factory or Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use the Copy Activity in Azure Data Factory and Synapse Analytics pipelines to copy data from an Amazon Redshift. It builds on the copy activity overview article that presents a general overview of copy activity.
Supported capabilities
This Amazon Redshift connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/-) | ① ② |
| Lookup activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores that are supported as sources or sinks by the copy activity, see the Supported data stores table.
Specifically, this Amazon Redshift connector supports retrieving data from Redshift using query or built-in Redshift UNLOAD support.
The connector supports the Windows versions in this article.
Tip
To achieve the best performance when copying large amounts of data from Redshift, consider using the built-in Redshift UNLOAD through Amazon S3. See Use UNLOAD to copy data from Amazon Redshift section for details.
Prerequisites
- If you are copying data to an on-premises data store using Self-hosted Integration Runtime, grant Integration Runtime (use IP address of the machine) the access to Amazon Redshift cluster. See Authorize access to the cluster for instructions.
- If you are copying data to an Azure data store, see Azure Data Center IP Ranges for the Compute IP address and SQL ranges used by the Azure data centers.
Getting started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
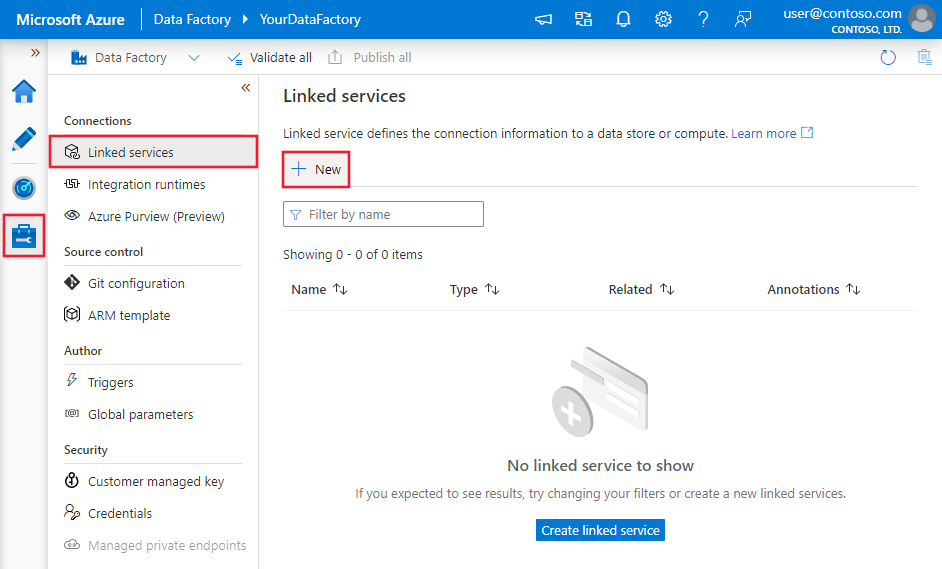
Create a linked service to Amazon Redshift using UI
Use the following steps to create a linked service to Amazon Redshift in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Amazon and select the Amazon Redshift connector.

Configure the service details, test the connection, and create the new linked service.

Connector configuration details
The following sections provide details about properties that are used to define Data Factory entities specific to Amazon Redshift connector.
Linked service properties
The following properties are supported for Amazon Redshift linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to: AmazonRedshift | Yes |
| server | IP address or host name of the Amazon Redshift server. | Yes |
| port | The number of the TCP port that the Amazon Redshift server uses to listen for client connections. | No, default is 5439 |
| database | Name of the Amazon Redshift database. | Yes |
| username | Name of user who has access to the database. | Yes |
| password | Password for the user account. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. | Yes |
| connectVia | The Integration Runtime to be used to connect to the data store. You can use Azure Integration Runtime or Self-hosted Integration Runtime (if your data store is located in private network). If not specified, it uses the default Azure Integration Runtime. | No |
Example:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the datasets article. This section provides a list of properties supported by Amazon Redshift dataset.
To copy data from Amazon Redshift, the following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to: AmazonRedshiftTable | Yes |
| schema | Name of the schema. | No (if "query" in activity source is specified) |
| table | Name of the table. | No (if "query" in activity source is specified) |
| tableName | Name of the table with schema. This property is supported for backward compatibility. Use schema and table for new workload. |
No (if "query" in activity source is specified) |
Example
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
If you were using RelationalTable typed dataset, it is still supported as-is, while you are suggested to use the new one going forward.
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by Amazon Redshift source.
Amazon Redshift as source
To copy data from Amazon Redshift, set the source type in the copy activity to AmazonRedshiftSource. The following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to: AmazonRedshiftSource | Yes |
| query | Use the custom query to read data. For example: select * from MyTable. | No (if "tableName" in dataset is specified) |
| redshiftUnloadSettings | Property group when using Amazon Redshift UNLOAD. | No |
| s3LinkedServiceName | Refers to an Amazon S3 to-be-used as an interim store by specifying a linked service name of "AmazonS3" type. | Yes if using UNLOAD |
| bucketName | Indicate the S3 bucket to store the interim data. If not provided, the service generates it automatically. | Yes if using UNLOAD |
Example: Amazon Redshift source in copy activity using UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Learn more on how to use UNLOAD to copy data from Amazon Redshift efficiently from next section.
Use UNLOAD to copy data from Amazon Redshift
UNLOAD is a mechanism provided by Amazon Redshift, which can unload the results of a query to one or more files on Amazon Simple Storage Service (Amazon S3). It is the way recommended by Amazon for copying large data set from Redshift.
Example: copy data from Amazon Redshift to Azure Synapse Analytics using UNLOAD, staged copy and PolyBase
For this sample use case, copy activity unloads data from Amazon Redshift to Amazon S3 as configured in "redshiftUnloadSettings", and then copy data from Amazon S3 to Azure Blob as specified in "stagingSettings", lastly use PolyBase to load data into Azure Synapse Analytics. All the interim format is handled by copy activity properly.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Data type mapping for Amazon Redshift
When copying data from Amazon Redshift, the following mappings are used from Amazon Redshift data types to interim data types used internally within the service. See Schema and data type mappings to learn about how copy activity maps the source schema and data type to the sink.
| Amazon Redshift data type | Interim service data type |
|---|---|
| BIGINT | Int64 |
| BOOLEAN | String |
| CHAR | String |
| DATE | DateTime |
| DECIMAL | Decimal |
| DOUBLE PRECISION | Double |
| INTEGER | Int32 |
| REAL | Single |
| SMALLINT | Int16 |
| TEXT | String |
| TIMESTAMP | DateTime |
| VARCHAR | String |
Lookup activity properties
To learn details about the properties, check Lookup activity.
Related content
For a list of data stores supported as sources and sinks by the copy activity, see supported data stores.