Copy and transform data in Snowflake using Azure Data Factory or Azure Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use the Copy activity in Azure Data Factory and Azure Synapse pipelines to copy data from and to Snowflake, and use Data Flow to transform data in Snowflake. For more information, see the introductory article for Data Factory or Azure Synapse Analytics.
Important
The new Snowflake connector provides improved native Snowflake support. If you are using the legacy Snowflake connector in your solution, you are recommended to upgrade your Snowflake connector at your earliest convenience. Refer to this section for details on the difference between the legacy and latest version.
Supported capabilities
This Snowflake connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/sink) | ① ② |
| Mapping data flow (source/sink) | ① |
| Lookup activity | ① ② |
| Script activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
For the Copy activity, this Snowflake connector supports the following functions:
- Copy data from Snowflake that utilizes Snowflake's COPY into [location] command to achieve the best performance.
- Copy data to Snowflake that takes advantage of Snowflake's COPY into [table] command to achieve the best performance. It supports Snowflake on Azure.
- If a proxy is required to connect to Snowflake from a self-hosted Integration Runtime, you must configure the environment variables for HTTP_PROXY and HTTPS_PROXY on the Integration Runtime host.
Prerequisites
If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it. Make sure to add the IP addresses that the self-hosted integration runtime uses to the allowed list.
If your data store is a managed cloud data service, you can use the Azure Integration Runtime. If the access is restricted to IPs that are approved in the firewall rules, you can add Azure Integration Runtime IPs to the allowed list.
The Snowflake account that is used for Source or Sink should have the necessary USAGE access on the database and read/write access on schema and the tables/views under it. In addition, it should also have CREATE STAGE on the schema to be able to create the External stage with SAS URI.
The following Account properties values must be set
| Property | Description | Required | Default |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Specifies whether to require a storage integration object as cloud credentials when creating a named external stage (using CREATE STAGE) to access a private cloud storage location. | FALSE | FALSE |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Specifies whether to require using a named external stage that references a storage integration object as cloud credentials when loading data from or unloading data to a private cloud storage location. | FALSE | FALSE |
For more information about the network security mechanisms and options supported by Data Factory, see Data access strategies.
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
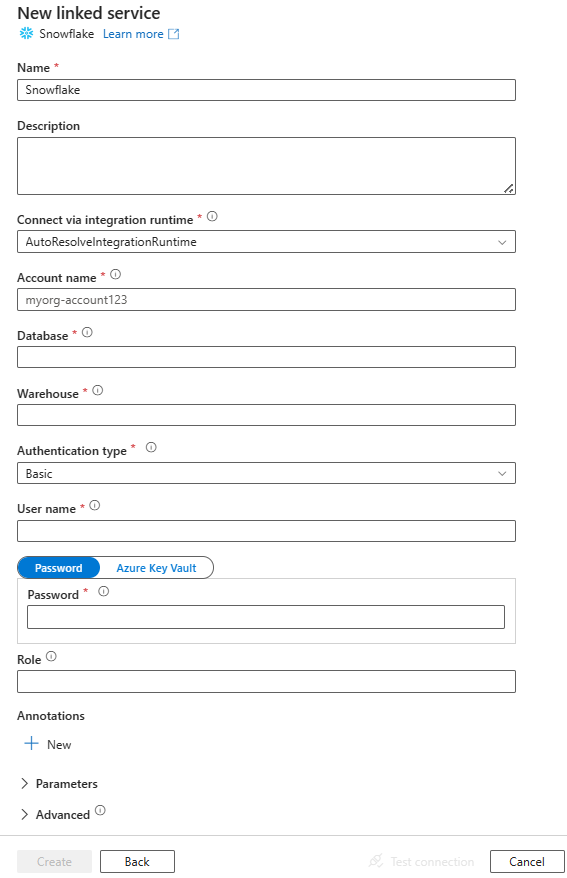
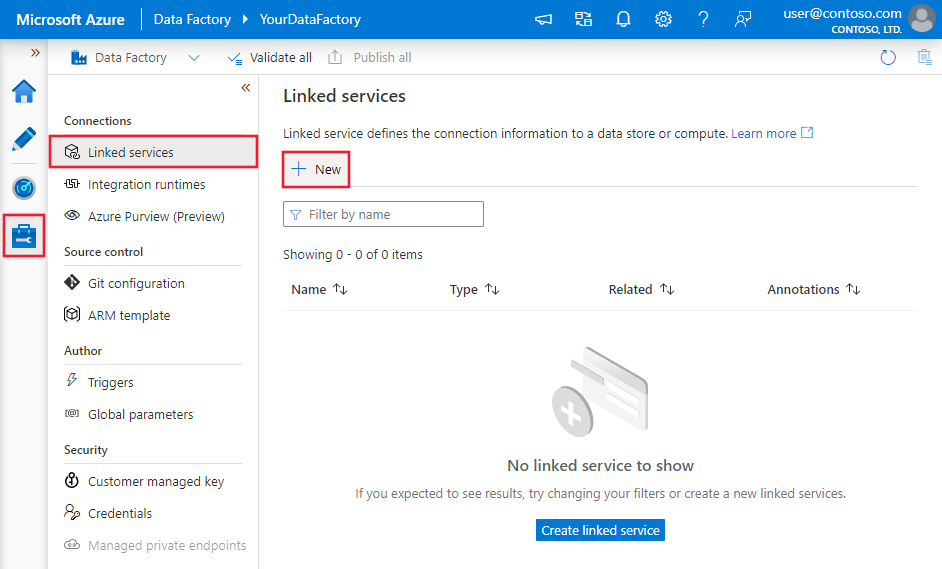
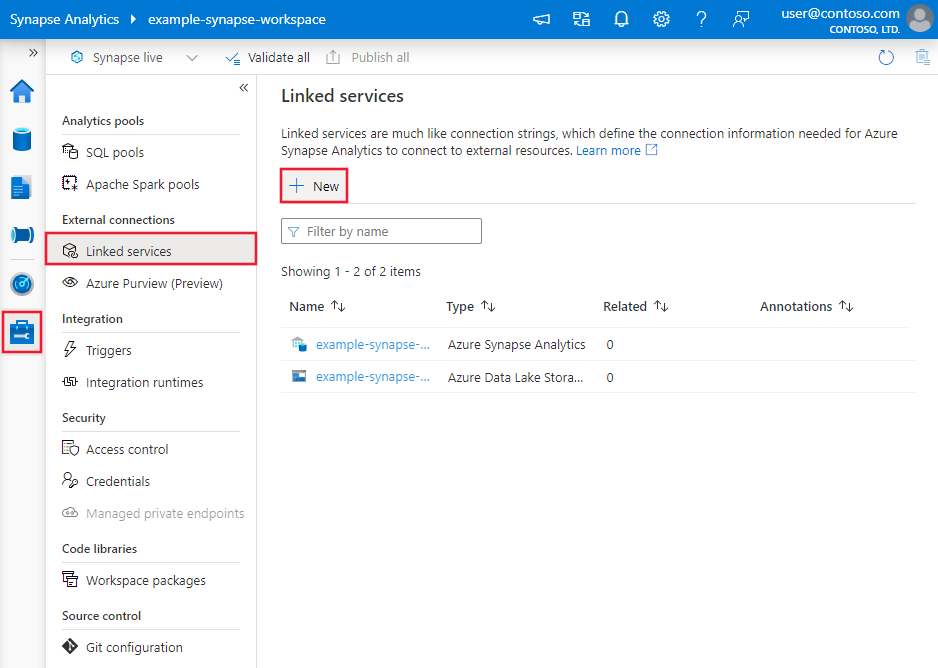
Create a linked service to Snowflake using UI
Use the following steps to create a linked service to Snowflake in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Snowflake and select the Snowflake connector.

Configure the service details, test the connection, and create the new linked service.
Connector configuration details
The following sections provide details about properties that define entities specific to a Snowflake connector.
Linked service properties
These generic properties are supported for the Snowflake linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to SnowflakeV2. | Yes |
| accountIdentifier | The name of the account along with its organization. For example, myorg-account123. | Yes |
| database | The default database used for the session after connecting. | Yes |
| warehouse | The default virtual warehouse used for the session after connecting. | Yes |
| authenticationType | Type of authentication used to connect to the Snowflake service. Allowed values are: Basic (Default) and KeyPair. Refer to corresponding sections below on more properties and examples respectively. | No |
| role | The default security role used for the session after connecting. | No |
| host | The host name of the Snowflake account. For example: contoso.snowflakecomputing.com. .cn is also supported. |
No |
| connectVia | The integration runtime that is used to connect to the data store. You can use the Azure integration runtime or a self-hosted integration runtime (if your data store is located in a private network). If not specified, it uses the default Azure integration runtime. | No |
This Snowflake connector supports the following authentication types. See the corresponding sections for details.
Basic authentication
To use Basic authentication, in addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| user | Login name for the Snowflake user. | Yes |
| password | The password for the Snowflake user. Mark this field as a SecureString type to store it securely. You can also reference a secret stored in Azure Key Vault. | Yes |
Example:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Password in Azure Key Vault:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Note
Mapping Data Flows only supports Basic authentication.
Key pair authentication
To use Key pair authentication, you need to configure and create a key pair authentication user in Snowflake by referring to Key Pair Authentication & Key Pair Rotation. Afterwards, make a note of the private key and the passphrase (optional), which you use to define the linked service.
In addition to the generic properties that are described in the preceding section, specify the following properties:
| Property | Description | Required |
|---|---|---|
| user | Login name for the Snowflake user. | Yes |
| privateKey | The private key used for the key pair authentication. To ensure the private key is valid when sent to Azure Data Factory, and considering that the privateKey file includes newline characters (\n), it's essential to correctly format the privateKey content in its string literal form. This process involves adding \n explicitly to each newline. |
Yes |
| privateKeyPassphrase | The passphrase used for decrypting the private key, if it's encrypted. | No |
Example:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article.
The following properties are supported for the Snowflake dataset.
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to SnowflakeV2Table. | Yes |
| schema | Name of the schema. Note the schema name is case-sensitive. | No for source, yes for sink |
| table | Name of the table/view. Note the table name is case-sensitive. | No for source, yes for sink |
Example:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by the Snowflake source and sink.
Snowflake as the source
Snowflake connector utilizes Snowflake's COPY into [location] command to achieve the best performance.
If sink data store and format are natively supported by the Snowflake COPY command, you can use the Copy activity to directly copy from Snowflake to sink. For details, see Direct copy from Snowflake. Otherwise, use built-in Staged copy from Snowflake.
To copy data from Snowflake, the following properties are supported in the Copy activity source section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy activity source must be set to SnowflakeV2Source. | Yes |
| query | Specifies the SQL query to read data from Snowflake. If the names of the schema, table and columns contain lower case, quote the object identifier in query e.g. select * from "schema"."myTable".Executing stored procedure isn't supported. |
No |
| exportSettings | Advanced settings used to retrieve data from Snowflake. You can configure the ones supported by the COPY into command that the service will pass through when you invoke the statement. | Yes |
Under exportSettings: |
||
| type | The type of export command, set to SnowflakeExportCopyCommand. | Yes |
| storageIntegration | Specify the name of your storage integration that you created in the Snowflake. For the prerequisite steps of using the storage integration, see Configuring a Snowflake storage integration. | No |
| additionalCopyOptions | Additional copy options, provided as a dictionary of key-value pairs. Examples: MAX_FILE_SIZE, OVERWRITE. For more information, see Snowflake Copy Options. | No |
| additionalFormatOptions | Additional file format options that are provided to COPY command as a dictionary of key-value pairs. Examples: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. For more information, see Snowflake Format Type Options. | No |
Note
Make sure you have permission to execute the following command and access the schema INFORMATION_SCHEMA and the table COLUMNS.
COPY INTO <location>
Direct copy from Snowflake
If your sink data store and format meet the criteria described in this section, you can use the Copy activity to directly copy from Snowflake to sink. The service checks the settings and fails the Copy activity run if the following criteria isn't met:
When you specify
storageIntegrationin the source:The sink data store is the Azure Blob Storage that you referred in the external stage in Snowflake. You need to complete the following steps before copying data:
Create an Azure Blob Storage linked service for the sink Azure Blob Storage with any supported authentication types.
Grant at least Storage Blob Data Contributor role to the Snowflake service principal in the sink Azure Blob Storage Access Control (IAM).
When you don't specify
storageIntegrationin the source:The sink linked service is Azure Blob storage with shared access signature authentication. If you want to directly copy data to Azure Data Lake Storage Gen2 in the following supported format, you can create an Azure Blob Storage linked service with SAS authentication against your Azure Data Lake Storage Gen2 account, to avoid using staged copy from Snowflake.
The sink data format is of Parquet, delimited text, or JSON with the following configurations:
- For Parquet format, the compression codec is None, Snappy, or Lzo.
- For delimited text format:
rowDelimiteris \r\n, or any single character.compressioncan be no compression, gzip, bzip2, or deflate.encodingNameis left as default or set to utf-8.quoteCharis double quote, single quote, or empty string (no quote char).
- For JSON format, direct copy only supports the case that source Snowflake table or query result only has single column and the data type of this column is VARIANT, OBJECT, or ARRAY.
compressioncan be no compression, gzip, bzip2, or deflate.encodingNameis left as default or set to utf-8.filePatternin copy activity sink is left as default or set to setOfObjects.
In copy activity source,
additionalColumnsisn't specified.Column mapping isn't specified.
Example:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Staged copy from Snowflake
When your sink data store or format isn't natively compatible with the Snowflake COPY command, as mentioned in the last section, enable the built-in staged copy using an interim Azure Blob storage instance. The staged copy feature also provides you with better throughput. The service exports data from Snowflake into staging storage, then copies the data to sink, and finally cleans up your temporary data from the staging storage. See Staged copy for details about copying data by using staging.
To use this feature, create an Azure Blob storage linked service that refers to the Azure storage account as the interim staging. Then specify the enableStaging and stagingSettings properties in the Copy activity.
When you specify
storageIntegrationin the source, the interim staging Azure Blob Storage should be the one that you referred in the external stage in Snowflake. Ensure that you create an Azure Blob Storage linked service for it with any supported authentication, and grant at least Storage Blob Data Contributor role to the Snowflake service principal in the staging Azure Blob Storage Access Control (IAM).When you don't specify
storageIntegrationin the source, the staging Azure Blob Storage linked service must use shared access signature authentication, as required by the Snowflake COPY command. Make sure you grant proper access permission to Snowflake in the staging Azure Blob Storage. To learn more about this, see this article.
Example:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
When performing a staged copy from Snowflake, it is crucial to set the Sink Copy Behavior to Merge Files. This setting ensures that all partitioned files are correctly handled and merged, preventing the issue where only the last partitioned file is copied.
Example Configuration
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Note
Failing to set the Sink Copy Behavior to Merge Files may result in only the last partitioned file being copied.
Snowflake as sink
Snowflake connector utilizes Snowflake’s COPY into [table] command to achieve the best performance. It supports writing data to Snowflake on Azure.
If source data store and format are natively supported by Snowflake COPY command, you can use the Copy activity to directly copy from source to Snowflake. For details, see Direct copy to Snowflake. Otherwise, use built-in Staged copy to Snowflake.
To copy data to Snowflake, the following properties are supported in the Copy activity sink section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy activity sink, set to SnowflakeV2Sink. | Yes |
| preCopyScript | Specify a SQL query for the Copy activity to run before writing data into Snowflake in each run. Use this property to clean up the preloaded data. | No |
| importSettings | Advanced settings used to write data into Snowflake. You can configure the ones supported by the COPY into command that the service will pass through when you invoke the statement. | Yes |
Under importSettings: |
||
| type | The type of import command, set to SnowflakeImportCopyCommand. | Yes |
| storageIntegration | Specify the name of your storage integration that you created in the Snowflake. For the prerequisite steps of using the storage integration, see Configuring a Snowflake storage integration. | No |
| additionalCopyOptions | Additional copy options, provided as a dictionary of key-value pairs. Examples: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. For more information, see Snowflake Copy Options. | No |
| additionalFormatOptions | Additional file format options provided to the COPY command, provided as a dictionary of key-value pairs. Examples: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. For more information, see Snowflake Format Type Options. | No |
Note
Make sure you have permission to execute the following command and access the schema INFORMATION_SCHEMA and the table COLUMNS.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Direct copy to Snowflake
If your source data store and format meet the criteria described in this section, you can use the Copy activity to directly copy from source to Snowflake. The service checks the settings and fails the Copy activity run if the following criteria isn't met:
When you specify
storageIntegrationin the sink:The source data store is the Azure Blob Storage that you referred in the external stage in Snowflake. You need to complete the following steps before copying data:
Create an Azure Blob Storage linked service for the source Azure Blob Storage with any supported authentication types.
Grant at least Storage Blob Data Reader role to the Snowflake service principal in the source Azure Blob Storage Access Control (IAM).
When you don't specify
storageIntegrationin the sink:The source linked service is Azure Blob storage with shared access signature authentication. If you want to directly copy data from Azure Data Lake Storage Gen2 in the following supported format, you can create an Azure Blob Storage linked service with SAS authentication against your Azure Data Lake Storage Gen2 account, to avoid using staged copy to Snowflake.
The source data format is Parquet, Delimited text, or JSON with the following configurations:
For Parquet format, the compression codec is None, or Snappy.
For delimited text format:
rowDelimiteris \r\n, or any single character. If row delimiter isn't “\r\n”,firstRowAsHeaderneed to be false, andskipLineCountisn't specified.compressioncan be no compression, gzip, bzip2, or deflate.encodingNameis left as default or set to "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255".quoteCharis double quote, single quote, or empty string (no quote char).
For JSON format, direct copy only supports the case that sink Snowflake table only has single column and the data type of this column is VARIANT, OBJECT, or ARRAY.
compressioncan be no compression, gzip, bzip2, or deflate.encodingNameis left as default or set to utf-8.- Column mapping isn't specified.
In the Copy activity source:
additionalColumnsisn't specified.- If your source is a folder,
recursiveis set to true. prefix,modifiedDateTimeStart,modifiedDateTimeEnd, andenablePartitionDiscoveryaren't specified.
Example:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Staged copy to Snowflake
When your source data store or format isn't natively compatible with the Snowflake COPY command, as mentioned in the last section, enable the built-in staged copy using an interim Azure Blob storage instance. The staged copy feature also provides you with better throughput. The service automatically converts the data to meet the data format requirements of Snowflake. It then invokes the COPY command to load data into Snowflake. Finally, it cleans up your temporary data from the blob storage. See Staged copy for details about copying data using staging.
To use this feature, create an Azure Blob storage linked service that refers to the Azure storage account as the interim staging. Then specify the enableStaging and stagingSettings properties in the Copy activity.
When you specify
storageIntegrationin the sink, the interim staging Azure Blob Storage should be the one that you referred in the external stage in Snowflake. Ensure that you create an Azure Blob Storage linked service for it with any supported authentication, and grant at least Storage Blob Data Reader role to the Snowflake service principal in the staging Azure Blob Storage Access Control (IAM).When you don't specify
storageIntegrationin the sink, the staging Azure Blob Storage linked service need to use shared access signature authentication as required by the Snowflake COPY command.
Example:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Mapping data flow properties
When transforming data in mapping data flow, you can read from and write to tables in Snowflake. For more information, see the source transformation and sink transformation in mapping data flows. You can choose to use a Snowflake dataset or an inline dataset as source and sink type.
Source transformation
The below table lists the properties supported by Snowflake source. You can edit these properties in the Source options tab. The connector utilizes Snowflake internal data transfer.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Table | If you select Table as input, data flow will fetch all the data from the table specified in the Snowflake dataset or in the source options when using inline dataset. | No | String | (for inline dataset only) tableName schemaName |
| Query | If you select Query as input, enter a query to fetch data from Snowflake. This setting overrides any table that you've chosen in dataset. If the names of the schema, table and columns contain lower case, quote the object identifier in query e.g. select * from "schema"."myTable". |
No | String | query |
| Enable incremental extract (Preview) | Use this option to tell ADF to only process rows that have changed since the last time that the pipeline executed. | No | Boolean | enableCdc |
| Incremental Column | When using the incremental extract feature, you must choose the date/time/numeric column that you wish to use as the watermark in your source table. | No | String | waterMarkColumn |
| Enable Snowflake Change Tracking (Preview) | This option enables ADF to leverage Snowflake change data capture technology to process only the delta data since the previous pipeline execution. This option automatically loads the delta data with row insert, update and deletion operations without requiring any incremental column. | No | Boolean | enableNativeCdc |
| Net Changes | When using snowflake change tracking, you can use this option to get deduped changed rows or exhaustive changes. Deduped changed rows will show only the latest versions of the rows that have changed since a given point in time, while exhaustive changes will show you all the versions of each row that has changed, including the ones that were deleted or updated. For example, if you update a row, you'll see a delete version and an insert version in exhaustive changes, but only the insert version in deduped changed rows. Depending on your use case, you can choose the option that suits your needs. The default option is false, which means exhaustive changes. | No | Boolean | netChanges |
| Include system Columns | When using snowflake change tracking, you can use the systemColumns option to control whether the metadata stream columns provided by Snowflake are included or excluded in the change tracking output. By default, systemColumns is set to true, which means the metadata stream columns are included. You can set systemColumns to false if you want to exclude them. | No | Boolean | systemColumns |
| Start reading from beginning | Setting this option with incremental extract and change tracking will instruct ADF to read all rows on first execution of a pipeline with incremental extract turned on. | No | Boolean | skipInitialLoad |
Snowflake source script examples
When you use Snowflake dataset as source type, the associated data flow script is:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
If you use inline dataset, the associated data flow script is:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Native Change Tracking
Azure Data Factory now supports a native feature in Snowflake known as change tracking, which involves tracking changes in the form of logs. This feature of snowflake allows us to track the changes in the data over time making it useful for incremental data loading and auditing purpose. To utilize this feature, when you enable Change data capture and select the Snowflake Change Tracking, we create a Stream object for the source table that enables change tracking on source snowflake table. Subsequently, we use the CHANGES clause in our query to fetch only the new or updated data from source table. Also, it's recommended to schedule pipeline such that changes are consumed within interval of data retention time set for snowflake source table else user might see inconsistent behavior in captured changes.
Sink transformation
The below table lists the properties supported by Snowflake sink. You can edit these properties in the Settings tab. When using inline dataset, you'll see additional settings, which are the same as the properties described in dataset properties section. The connector utilizes Snowflake internal data transfer.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Update method | Specify what operations are allowed on your Snowflake destination. To update, upsert, or delete rows, an Alter row transformation is required to tag rows for those actions. |
Yes | true or false |
deletable insertable updateable upsertable |
| Key columns | For updates, upserts and deletes, a key column or columns must be set to determine which row to alter. | No | Array | keys |
| Table action | Determines whether to recreate or remove all rows from the destination table prior to writing. - None: No action will be done to the table. - Recreate: The table will get dropped and recreated. Required if creating a new table dynamically. - Truncate: All rows from the target table will get removed. |
No | true or false |
recreate truncate |
Snowflake sink script examples
When you use Snowflake dataset as sink type, the associated data flow script is:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
If you use inline dataset, the associated data flow script is:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Query Pushdown optimization
By setting the pipeline Logging Level to None, we exclude the transmission of intermediate transformation metrics, preventing potential hindrances to Spark optimizations and enabling query pushdown optimization provided by Snowflake. This pushdown optimization allows substantial performance enhancements for large Snowflake tables with extensive datasets.
Note
We don't support temporary tables in Snowflake, as they are local to the session or user who creates them, making them inaccessible to other sessions and prone to being overwritten as regular tables by Snowflake. While Snowflake offers transient tables as an alternative, which are accessible globally, they require manual deletion, contradicting our primary objective of using Temp tables which is to avoid any delete operations in source schema.
Lookup activity properties
For more information about the properties, see Lookup activity.
Upgrade the Snowflake connector
To upgrade the Snowflake connector, you can do a side-by-side upgrade, or an in-place upgrade.
Side-by-side upgrade
To perform a side-by-side upgrade, complete the following steps:
- Create a new Snowflake linked service and configure it by referring to the linked service properties.
- Create a dataset based on the newly created Snowflake linked service.
- Replace the new linked service and dataset with the existing ones in the pipelines that targets the legacy objects.
In-place upgrade
To perform an in-place upgrade, you need to edit the existing linked service payload and update dataset to use the new linked service.
Update the type from Snowflake to SnowflakeV2.
Modify the linked service payload from its legacy format to the new pattern. You can either fill in each field from the user interface after changing the type mentioned above, or update the payload directly through the JSON Editor. Refer to the Linked service properties section in this article for the supported connection properties. The following examples show the differences in payload for the legacy and new Snowflake linked services:
Legacy Snowflake linked service JSON payload:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }New Snowflake linked service JSON payload:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Update dataset to use the new linked service. You can either create a new dataset based on the newly created linked service, or update an existing dataset's type property from SnowflakeTable to SnowflakeV2Table.
Differences between Snowflake and Snowflake (legacy)
The Snowflake connector offers new functionalities and is compatible with most features of Snowflake (legacy) connector. The table below shows the feature differences between Snowflake and Snowflake (legacy).
| Snowflake | Snowflake (legacy) |
|---|---|
| Support Basic and Key pair authentication. | Support Basic authentication. |
| Script parameters are not supported in Script activity currently. As an alternative, utilize dynamic expressions for script parameters. For more information, see Expressions and functions in Azure Data Factory and Azure Synapse Analytics. | Support script parameters in Script activity. |
| Support BigDecimal in Lookup activity. The NUMBER type, as defined in Snowflake, will be displayed as a string in Lookup activity. | BigDecimal is not supported in Lookup activity. |
Legacy connectionstring property is deprecated in favor of required parameters Account, Warehouse, Database, Schema, and Role |
In the legacy Snowflake connector, the connectionstring property was used to establish a connection. |
Related content
For a list of data stores supported as sources and sinks by Copy activity, see supported data stores and formats.