Get started with prompt flow
This article walks you through the main user journey of using prompt flow in Azure Machine Learning studio. You learn how to enable prompt flow in your Azure Machine Learning workspace, create and develop a prompt flow, test and evaluate the flow, and then deploy it to production.
Prerequisites
- An Azure Machine Learning workspace. The default storage for the workspace must be blob type.
- An Azure OpenAI account, or an existing Azure OpenAI connection with a deployment. For more information, see Create a resource and deploy a model using Azure OpenAI.
Note
If you want to secure your prompt flow with a virtual network, also follow the instructions at Secure prompt flow with workspace managed virtual network.
Set up a connection
A connection helps securely store and manage secret keys or other sensitive credentials required for interacting with Large Language Models (LLM) and other external tools such as Azure Content Safety. Connection resources are shared with all members in the workspace.
To check if you already have an Azure OpenAI connection, select Prompt flow from the Azure Machine Learning studio left menu and then select the Connections tab on the Prompt flow screen.
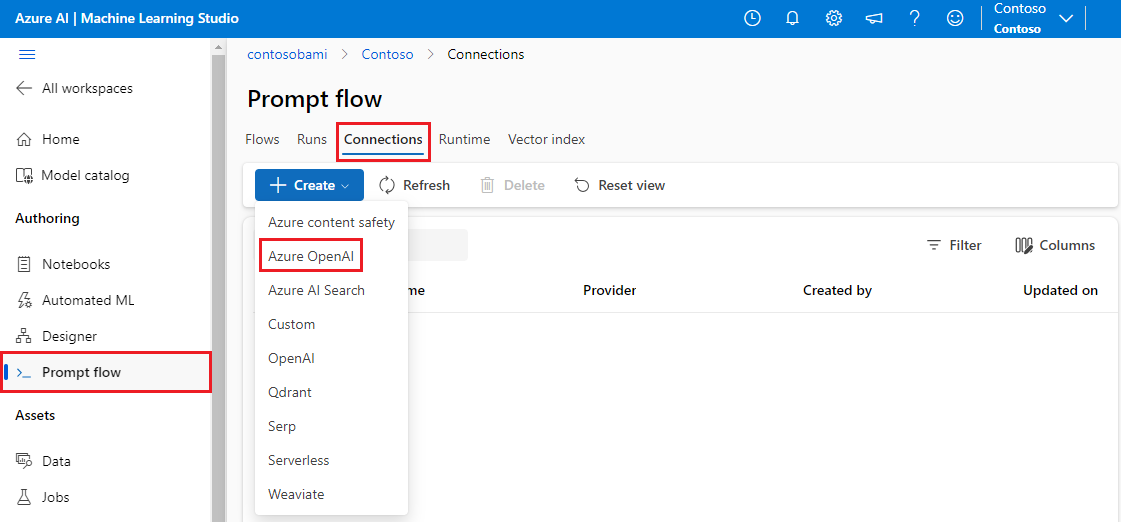
If you already see a connection whose provider is AzureOpenAI, you can skip the rest of this setup process. Note that this connection must have a deployment to be able to run the LLM nodes in the example flow. For more information, see Deploy a model.
If you don't have an Azure OpenAI connection, select Create and then select AzureOpenAI from the dropdown menu.
In the Add Azure OpenAI connection pane, provide a name for the connection, select your Subscription ID and Azure OpenAI Account Name, and provide an Auth Mode and API information.
Prompt flow supports either API Key or Microsoft Entra ID authentication for Azure OpenAI resources. For this tutorial, select API key under Auth Mode.

To get the API information, go to the Chat playground in the Azure OpenAI portal and select your Azure OpenAI resource name. Copy the Key and paste it into the API key field in the Add Azure OpenAI connection form, and copy the Endpoint and paste it into the API base field in the form.

For information about Microsoft Entra ID authentication, see How to configure Azure OpenAI Service with Microsoft Entra ID authentication.
After you fill out all fields, select Save to create the connection.
The connection must be associated with a deployment before you can run the LLM nodes in the example flow. To create the deployment, see Deploy a model.



Create and develop your prompt flow
In the Flows tab of the Prompt flow home page, select Create to create the prompt flow. The Create a new flow page shows flow types you can create, built-in samples you can clone to create a flow, and ways to import a flow.
Clone from a sample
In the Explore gallery, you can browse the built-in samples and select View detail on any tile to preview whether it's suitable for your scenario.
This tutorial uses the Web Classification sample to walk through the main user journey. Web Classification is a flow demonstrating multiclass classification with a LLM. Given a URL, the flow classifies the URL into a web category with just a few shots, simple summarization, and classification prompts. For example, given a URL https://www.imdb.com, it classifies the URL into Movie.
To clone the sample, select Clone on the Web Classification tile.

The Clone flow pane shows the location to store your flow within your workspace fileshare storage. You can customize the folder if you want. Then select Clone.
The cloned flow opens in the authoring UI. You can select the Edit pencil icon to edit flow details like name, description, and tags.
Start the compute session
A compute session is necessary for flow execution. The compute session manages the computing resources required for the application to run, including a Docker image that contains all necessary dependency packages.
On the flow authoring page, start a compute session by selecting Start compute session.

Inspect the flow authoring page
The compute session can take a few minutes to start. While the compute session is starting, view the parts of the flow authoring page.
The Flow or flatten view on the left side of the page is the main working area, where you can author the flow by adding or removing nodes, editing and running nodes inline, or editing prompts. In the Inputs and Outputs sections, you can view, add or remove, and edit inputs and outputs.
When you cloned the current Web Classification sample, the inputs and outputs were already set. The input schema for the flow is
name: url; type: string, a URL of string type. You can change the preset input value to another value likehttps://www.imdb.commanually.Files at top right shows the folder and file structure of the flow. Each flow folder contains a flow.dag.yaml file, source code files, and system folders. You can create, upload, or download files for testing, deployment, or collaboration.
The Graph view at lower right is for visualizing what the flow looks like. You can zoom in or out, or use auto layout.
You can edit files inline in the Flow or flatten view, or you can turn on the Raw file mode toggle and select a file from Files to open the file in a tab for editing.

For this sample, the input is a URL to classify. The flow uses a Python script to fetch text content from the URL, uses LLM to summarize the text content in 100 words, and classifies based on the URL and summarized text content. A Python script then converts LLM output into a dictionary. The prepare_examples node feeds a few example shots to the classification node's prompt.
Set up LLM nodes
For each LLM node, you need to select a Connection to set the LLM API keys. Select your Azure OpenAI connection.
Depending on the connection type, you must select a deployment_name or a model from the dropdown list. For an Azure OpenAI connection, select a deployment. If you don't have a deployment, create one in the Azure OpenAI portal by following instructions at Deploy a model.
Note
If you use an OpenAI connection rather than an Azure OpenAI connection, you need to select a model rather than a deployment in the Connection field.
For this example, make sure the API type is chat, because the provided prompt example is for the chat API. For more information about the difference between the chat and completion APIs, see Develop a flow.

Set up connections for both of the LLM nodes in the flow, summarize_text_content and classify_with_llm.
Run a single node
To test and debug a single node, select the Run icon at the top of a node in the Flow view. You can expand Inputs and change the flow input URL to test the node behavior for different URLs.
The run status appears at the top of the node. After the run completes, run output appears in the node Output section.

The Graph view also shows the single run node status.
Run fetch_text_content_from_url and then run summarize_text_content to check if the flow can successfully fetch content from the web and summarize the web content.
Run the whole flow
To test and debug the whole flow, select Run at the top of the screen. You can change the flow input URL to test how the flow behaves for different URLs.

Check the run status and output of each node.
View flow outputs
You can also set flow outputs to check outputs of multiple nodes in one place. Flow outputs help you:
- Check bulk test results in a single table.
- Define evaluation interface mapping.
- Set deployment response schema.
In the cloned sample, the category and evidence flow outputs are already set.
Select View outputs in the top banner or the top menu bar to view detailed input, output, flow execution, and orchestration information.

On the Outputs tab of the Outputs screen, note that the flow predicts the input URL with a category and evidence.

Select the Trace tab on the Outputs screen and then select flow under node name to see detailed flow overview information in the right pane. Expand flow and select any step to see detailed information for that step.




Test and evaluate
After the flow runs successfully with a single row of data, test whether it performs well with a large set of data. You can run a bulk test and optionally add an evaluation flow, and then check the results.
You need to prepare test data first. Azure Machine Learning supports CSV, TSV, and JSONL file formats for data.
- Go to GitHub and download data.csv, the golden dataset for the Web Classification sample.
Use the Batch run & Evaluate wizard to configure and submit a batch run and optionally an evaluation method. Evaluation methods are also flows, which use Python or LLM to calculate metrics like accuracy and relevance score.
Select Evaluate from the top menu of your flow authoring page.
On the Basic settings screen, change the Run display name if desired, add an optional Run description and Tags, and then select Next.
On the Batch run settings screen, select Add new data. On the Add data screen, provide a Name for the dataset, select Browse to upload the data.csv file you downloaded, and then select Add.
After you upload the data, or if your workspace has another dataset you want to use, search for and choose the dataset from the dropdown list to preview the first five rows.
The Input mapping feature supports mapping your flow input to any data column in your dataset, even if the column names don't match.
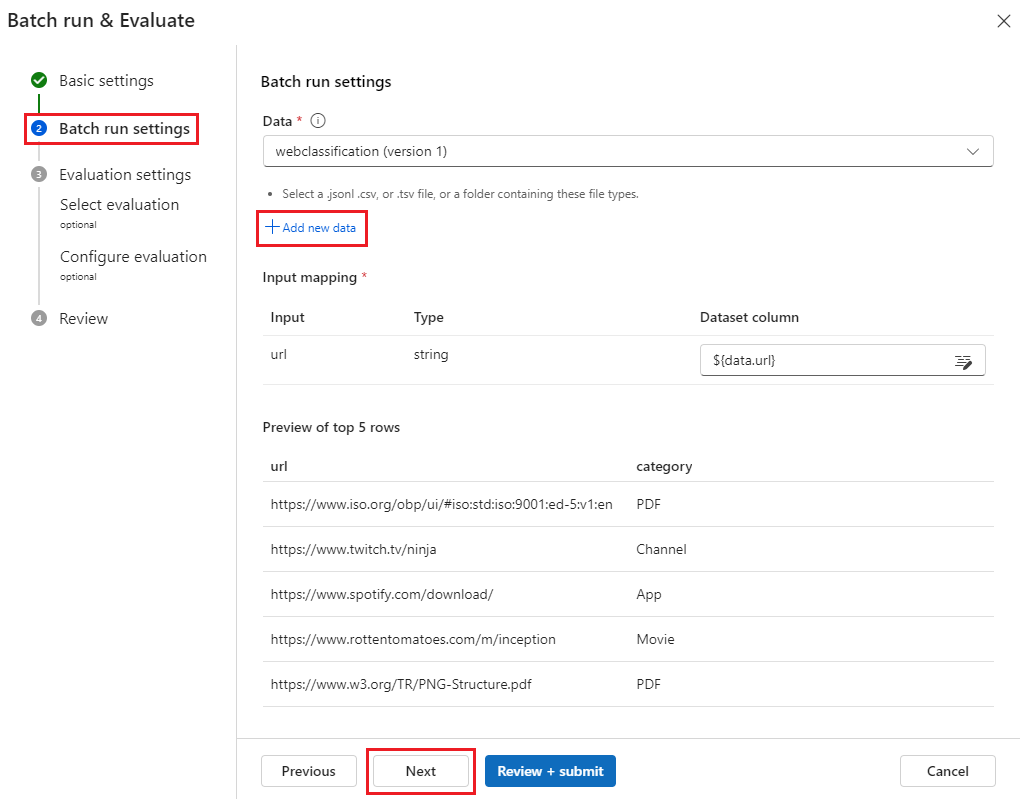
Select Next to optionally select one or multiple evaluation methods. The Select evaluation page shows built-in and customized evaluation flows. To see how the metrics are defined for built-in evaluation methods, you can select More details on the method's tile.
Web Classification is a classification scenario, so select Classification Accuracy Evaluation to use for evaluation, and then select Next.

On the Configure evaluation screen, set Evaluation input mapping to map groundtruth to flow input ${data.category} and map prediction to flow output ${run.outputs.category}.

Select Review + submit and then select Submit to submit a batch run and the selected evaluation method.



Check results
When your run submits successfully, select View run list to view run status on the prompt flow Runs page. The batch run might take a while to finish. You can select Refresh to load the latest status.
After the batch run completes, select the check next to the run and then select Visualize outputs to view the result of your batch run.

On the Visualize outputs screen, enable the eye icon next to the child run to append evaluation results to the table of batch run results. You can see the total token count and overall accuracy. The Output table shows the results for each row of data: input, flow output, system metrics, and evaluation result of Correct or Incorrect.

In the Output table, you can:
- Adjust column width, hide or unhide columns, or change column order.
- Select Export to Download current page as a CSV file or Download data export script as a Jupyter notebook file you can run to download outputs locally.
- Select the View details icon next to any row to open the Trace view showing the complete details for that row.
Accuracy isn't the only metric that can evaluate a classification task. For example, you can also use recall to evaluate. To run other evaluations, select Evaluate next to Visualize outputs on the Runs page, and select other evaluation methods.
Deploy as an endpoint
After you build and test a flow, you can deploy it as an endpoint so that you can invoke the endpoint for real-time inference.
Configure the endpoint
On the batch Runs page, select the run name link, and on the run detail page, select Deploy on the top menu bar to open the deployment wizard.
On the Basic settings page, specify an Endpoint name and Deployment name and select a Virtual machine type and Instance count.
You can select Next to configure advanced Endpoint, Deployment, and Outputs & connections settings. For this example, use the default settings.
Select Review + Create and then select Create to start the deployment.
Test the endpoint
You can go to your endpoint detail page from the notification, or by selecting Endpoints in the studio left navigation and selecting your endpoint from the Real-time endpoints tab. It takes several minutes to deploy the endpoint. After the endpoint is deployed successfully, you can test it in the Test tab.
Put the URL you want to test in the input box, and select Test. You see the result predicted by your endpoint.
Clean up resources
To conserve compute resources and costs, you can stop your compute session if you're done using it for now. Select the running session and then select Stop compute session.
You can also stop a compute instance by selecting Compute from the studio left navigation, selecting your compute instance in the Compute instances list, and selecting Stop.
If you don't plan to use any of the resources that you created in this tutorial, you can delete them so they don't incur charges. In the Azure portal, search for and select Resource groups. From the list, select the resource group that contains the resources you created, and then select Delete resource group from the top menu on the resource group page.