नोट
इस पेज तक पहुँच के लिए प्रमाणन की आवश्यकता होती है. आप साइन इन करने या निर्देशिकाओं को बदलने का प्रयास कर सकते हैं.
इस पेज तक पहुँच के लिए प्रमाणन की आवश्यकता होती है. आप निर्देशिकाओं को बदलने का प्रयास कर सकते हैं.
[यह आलेख रिलीज़-पूर्व दस्तावेज़ है और परिवर्तन के अधीन है.]
नया अनुकूलित डायरेक्टलेक सिमेंटिक मॉडल प्रक्रियाओं के तीव्र एवं अधिक मेमोरी-कुशल विश्लेषण की ओर ले जाता है। मेमोरी की बचत करके, आप बड़ी प्रक्रियाओं का विश्लेषण कर सकते हैं और विश्लेषण करने के लिए छोटी फैब्रिक क्षमताओं का उपयोग करके लागत बचा सकते हैं। इसके अलावा, एक अधिक सहज अर्थपूर्ण मॉडल डेटा संरचना का उपयोग किया जाता है, जो आपको कम समय और प्रयास के साथ अंतर्दृष्टि में गहराई से जाने की अनुमति देता है। Power BI
महत्त्वपूर्ण
- यह एक पूर्वावलोकन सुविधा है.
- पूर्वावलोकन सुविधाएँ उत्पादन में उपयोग के लिए नहीं होती हैं और इनकी कार्यक्षमता प्रतिबंधित हो सकती हैं. यह सुविधाएँ आधिकारिक रिलीज़ से पहले उपलब्ध होती हैं ताकि ग्राहक शीघ्र पहुँच प्राप्त कर सकें और प्रतिक्रिया प्रदान कर सकें.
- अधिक जानकारी के लिए, हमारी पूर्वावलोकन शर्तें देखें।
सिमेंटिक मॉडल विवरण
जब कोई प्रक्रिया फैब्रिक वर्कस्पेस पर प्रकाशित होती है, तो यह एक नया सिमेंटिक मॉडल और एक संगत रिपोर्ट बनाती है। यह स्क्रीनशॉट फ़ैब्रिक पर प्रकाशित सिमेंटिक मॉडल संरचना का एक उदाहरण है।
छवि को बड़ा करने के लिए उसके निचले-दाएँ कोने में स्थित आवर्धक कांच का चयन करें।

संबंध
दृश्यों की फ़िल्टरिंग और अंतर्संबंध के लिए आवश्यक संबंध प्रकाशित डेटा मॉडल में पूर्वनिर्धारित हैं। जब तक अन्य डेटा स्रोत कनेक्ट न हों, तब तक मैन्युअल रूप से अधिक संबंध बनाने की आवश्यकता नहीं है। इस परिदृश्य के लिए, Power BI संयुक्त सिमेंटिक मॉडल का उपयोग करें और उस मॉडल के शीर्ष पर संबंध बनाएं।
डेटा मॉडल सारांश
तार्किक दृष्टिकोण से, डेटा मॉडल में कई इकाई उपसमूह शामिल होते हैं जैसा कि इस खंड के पहले पैराग्राफ में दर्शाया गया है।
- प्रक्रिया डेटा: फ़िल्टरिंग और गणना किए गए उपायों के बिना सभी प्रक्रिया-संबंधित डेटा
- दृश्य डेटा: कस्टम विज़ुअल प्रदर्शित करने के लिए प्रक्रिया खनन के लिए आवश्यक पूर्व-गणना डेटा प्रदान करने वाली संस्थाएँ
- सहायता करने वाली संस्थाएँ: अन्य संस्थाएँ जिनकी आवश्यकता है Power BI
उपसमुच्चयों और सम्मिलित संस्थाओं का संक्षिप्त विवरण निम्नलिखित है।
डेटा का प्रसंस्करण
प्रक्रिया डेटा इकाइयों की विषय-वस्तु विशिष्ट परिदृश्यों में बदल जाती है।
- जब प्रक्रिया मॉडल डेटा ताज़ा किया जाता है
- जब कोई नया दृश्य बनाया जाता है
- जब कोई नया कस्टम मीट्रिक बनाया जाता है
- जब कोई उपयोगकर्ता किसी भी प्रक्रिया दृश्य में फ़िल्टरिंग परिभाषा बदलता है
इन संस्थाओं के साथ काम करने से आपको ये सुविधाएं मिलती हैं:
- कच्चे प्रक्रिया डेटा तक पहुँचें
- लागू किए गए फ़िल्टर से प्रभावित प्रक्रिया डेटा
- लागू किए गए फ़िल्टर के आधार पर गणना किए गए मापों तक पहुँचें
| इकाई | विवरण |
|---|---|
| मामले | प्रक्रिया में सभी मामलों और उनकी विशेषताओं की सूची। प्रत्येक केस में एक अद्वितीय केस आईडी डिस्प्ले होता है, और प्रत्येक केस विशेषता के लिए मान होते हैं, जैसा कि मैपिंग सेटअप चरण में परिभाषित किया गया है। संपूर्ण केस जानकारी प्राप्त करने के लिए CaseMetrics इकाई के साथ संयोजित करें. |
| इवेंट | प्रक्रिया में सभी ईवेंट विशेषताओं की सूची. प्रत्येक ईवेंट का एक अद्वितीय ईवेंट पहचानकर्ता सूचकांक होता है, तथा प्रत्येक ईवेंट विशेषता के लिए मान होते हैं, जैसा कि मैपिंग सेटअप चरण में परिभाषित किया गया है। संपूर्ण ईवेंट जानकारी प्राप्त करने के लिए ProcessMapMetrics स्तंभ द्वारा फ़िल्टर की गई इकाई के साथ संयोजित करें। Is_Node |
| केसमेट्रिक्स | निकाय में केस और दृश्य के विशिष्ट संयोजन से संबंधित सभी केस-स्तरीय मीट्रिक्स होते हैं। प्रोसेस माइनिंग डेस्कटॉप ऐप में परिभाषित केस स्तरीय कस्टम मेट्रिक्स इस इकाई में जोड़े गए हैं। Power Automate |
| विशेषताएँमेटाडेटा | इकाई प्रक्रिया मॉडल में इवेंट लॉग डेटा के आयात में परिभाषित सभी केस/ईवेंट-स्तरीय विशेषताओं की परिभाषा रखती है। इसमें इसका डेटाटाइप, विशेषता प्रकार, तथा विशेषता स्तर शामिल होता है, जो या तो केस या इवेंट होता है। |
| खननविशेषताएँ | उपलब्ध खनन विशेषताओं के मान रखता है. चयनित खनन विशेषता के आधार पर प्रक्रिया को विभिन्न परिप्रेक्ष्य से देखने के लिए एक प्रक्रिया दृश्य स्थापित किया जा सकता है। यदि कोई अन्य खनन विशेषता उपलब्ध नहीं है, तो इकाई विशेषता के मान रखती है। Activity |
| दृश्य | Power Automate प्रोसेस माइनिंग डेस्कटॉप ऐप में बनाए गए उपलब्ध (प्रकाशित) दृश्यों की सूची। डेटा सेट पर केवल सार्वजनिक प्रक्रिया दृश्य ही प्रकाशित किए जाते हैं। प्रविष्टियों का उपयोग रिपोर्ट, रिपोर्ट पृष्ठ और विज़ुअल को फ़िल्टर करने के लिए किया जा सकता है ताकि केवल विशिष्ट प्रक्रिया दृश्य से डेटा को देखा जा सके। |
| वेरिएंट | इकाई वेरिएंट और प्रक्रिया दृश्यों के बीच संबंधों को रखती है। यदि फ़िल्टरिंग मानदंड को ध्यान में रखने के बाद किसी विशेष संस्करण को दृश्य में शामिल किया जाता है, तो रिकॉर्ड को शामिल किया जाता है। |
दृश्य डेटा
विज़ुअल डेटा निकायों की पुनर्गणना केवल तभी की जाती है जब प्रक्रिया मॉडल के लिए डेटा रिफ़्रेश होता है.
| इकाई | विवरण |
|---|---|
| प्रोसेसमैपमेट्रिक्स | प्रक्रिया मॉडल में सभी नोड्स और संक्रमणों के लिए समेकित उपाय जो प्रक्रिया मानचित्र कस्टम विज़ुअल में विज़ुअलाइज़ेशन के लिए आवश्यक हैं। यह इकाई ईवेंट (नोड) जानकारी और किनारा (संक्रमण) जानकारी को जोड़ती है - अपने अन्य दृश्यों में ईवेंट या किनारों का उपयोग करने के लिए, Is_Node कॉलम में मान द्वारा फ़िल्टर करें।
प्रोसेस माइनिंग डेस्कटॉप ऐप में परिभाषित इवेंट स्तर के कस्टम मेट्रिक्स इस इकाई में जोड़े गए हैं। Power Automate |
अन्य संस्थाएं
| इकाई | विवरण |
|---|---|
| स्थानीयकरणतालिका | स्थानीयकरण प्रयोजन के लिए आंतरिक तालिका का उपयोग किया गया। |
Power BI समग्र मॉडल
हम अनुशंसा करते हैं कि आप प्रोसेस माइनिंग द्वारा प्रकाशित सिमेंटिक मॉडल के शीर्ष पर कंपोजिट मॉडल का उपयोग करें और इन परिदृश्यों के लिए आवश्यक संशोधन करें: Power BI Power Automate
- आपको अधिक डेटा स्रोत बनाने की आवश्यकता है
- आपको और अधिक निकाय बनाने की आवश्यकता है
- आपको अधिक रिश्ते बनाने की जरूरत है
- आपको अधिक कस्टम DAX (डेटा विश्लेषण अभिव्यक्तियाँ) क्वेरीज़ बनाने की आवश्यकता है
महत्त्वपूर्ण
सिमेंटिक मॉडल डायरेक्टलेक एक्सेस मोड में बनाया जाता है, लेकिन इसका विकल्प स्वचालित पर सेट होता है। इस सेटिंग का अर्थ है कि गैर-इष्टतम DAX क्वेरीज़ का उपयोग करने या संयुक्त मॉडल को गलत तरीके से सेट करने के परिणामस्वरूप DirectQuery मोड पर वापस जाना पड़ सकता है। इसका मतलब यह है कि आपकी रिपोर्ट ख़राब तो नहीं होगी, लेकिन आपको कम प्रदर्शन का अनुभव हो सकता है।
बनाने के बारे में अधिक जानने के लिए Power BI डायरेक्टलेक सिमेंटिक मॉडल के शीर्ष पर समग्र डेटा मॉडल के लिए, यहां जाएं: सिमेंटिक मॉडल या मॉडल पर एक समग्र मॉडल का निर्माण.
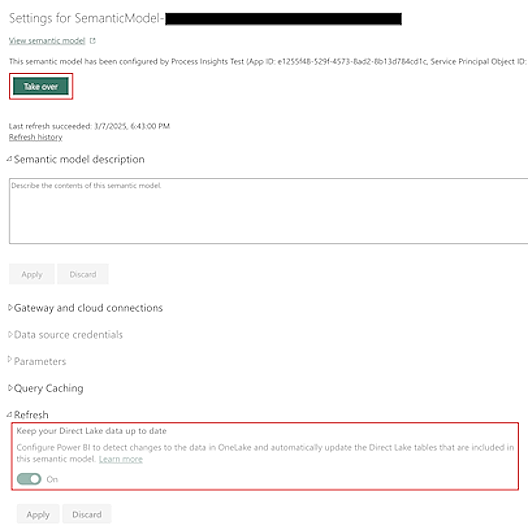
सिमेंटिक मॉडल रिफ्रेश
डिफ़ॉल्ट रूप से, द्वारा प्रदान किया गया सिमेंटिक मॉडल Power Automate प्रक्रिया खनन स्वचालित रूप से अद्यतन रखा.
बड़े डेटासेट के लिए, OneLake में अंतर्निहित तालिकाओं के डेटा रिफ्रेश में अधिक समय लग सकता है। इससे रिपोर्ट में असंगतताएं उत्पन्न हो सकती हैं। यद्यपि डेटा रिफ्रेश के अंत में अंततः एकरूपता होती है (सिमेंटिक मॉडल स्पष्ट रूप से रिफ्रेश होता है), हो सकता है कि आप सिमेंटिक मॉडल की सेटिंग्स स्क्रीन में अपने डायरेक्ट लेक डेटा को अप-टू-डेट रखें फ़्लैग को बंद करके संभावित मध्यवर्ती असंगतताओं को हटाना चाहें।
इस स्क्रीन को अपडेट करने से पहले, आपको सेटिंग्स स्क्रीन के शीर्ष पर टेक ओवर का चयन करके सिमेंटिक मॉडल का स्वामित्व लेना होगा।