लागत कार्यों के साथ मॉडल त्रुटियों को कम करें
सीखने की प्रक्रिया बार-बार एक मॉडल को बदल देती है जब तक कि वह उच्च-गुणवत्ता वाले अनुमान नहीं लगा सकता। यह निर्धारित करने के लिए कि एक मॉडल कितना अच्छा प्रदर्शन कर रहा है, सीखने की प्रक्रिया लागत फ़ंक्शन के रूप में गणित का उपयोग करती है। लागत फ़ंक्शन को एक उद्देश्य फ़ंक्शन के रूप में भी जाना जाता है। यह समझने के लिए कि लागत फ़ंक्शन क्या है, आइए इसे थोड़ा तोड़ दें।
त्रुटि, लागत और हानि
पर्यवेक्षित सीखने में, त्रुटि, लागत और हानि सभी गलतियों की संख्या को संदर्भित करते हैं जो एक मॉडल एक या अधिक लेबल की भविष्यवाणी करने में करता है।
मशीन लर्निंग में इन तीन शब्दों का उपयोग शिथिल रूप से किया जाता है, जिससे कुछ भ्रम पैदा हो सकता है। सादगी के लिए, हम उन्हें यहां परस्पर उपयोग करते हैं। लागत की गणना गणित के माध्यम से की जाती है; यह गुणात्मक निर्णय नहीं है। उदाहरण के लिए, यदि कोई मॉडल 40°F के दैनिक तापमान की भविष्यवाणी करता है, लेकिन वास्तविक मान 35°F है, तो हम कह सकते हैं कि इसमें 5°F की त्रुटि है।
लागत को कम करना हमारा लक्ष्य है
क्योंकि लागत इंगित करती है कि एक मॉडल कितनी बुरी तरह से काम करता है, हमारा लक्ष्य शून्य लागत है। दूसरे शब्दों में, हम मॉडल को प्रशिक्षित करना चाहते हैं कि कोई गलती न हो। यह विचार अक्सर असंभव होता है, हालांकि, इसके बजाय हम मॉडल को कम से कम लागत संभव बनाने के लिए प्रशिक्षण का थोड़ा और अस्पष्ट लक्ष्य निर्धारित करते हैं।
इस लक्ष्य के कारण, हम लागत की गणना कैसे करते हैं, यह तय करता है कि मॉडल क्या सीखने की कोशिश करता है। पिछले उदाहरण में, हमने लागत को तापमान का अनुमान लगाने में त्रुटि के रूप में परिभाषित किया था।
लागत फ़ंक्शन क्या है?
पर्यवेक्षित सीखने में, एक लागत फ़ंक्शन कोड का एक छोटा टुकड़ा है जो एक मॉडल की भविष्यवाणी और अपेक्षित लेबल से लागत की गणना करता है: सही उत्तर। उदाहरण के लिए, हमारे पिछले अभ्यास में, हमने भविष्यवाणी त्रुटियों की गणना करके, उन्हें चौकोर करके और उन्हें जोड़कर लागत की गणना की।
लागत फ़ंक्शन लागत की गणना करने के बाद, हम जानते हैं कि मॉडल अच्छा प्रदर्शन कर रहा है या नहीं। यदि यह अच्छा प्रदर्शन कर रहा है, तो हम प्रशिक्षण बंद करने का विकल्प चुन सकते हैं। यदि नहीं, तो हम ऑप्टिमाइज़र को लागत की जानकारी पास कर सकते हैं, जो मॉडल के लिए नए मापदंडों का चयन करने के लिए इस जानकारी का उपयोग करता है।
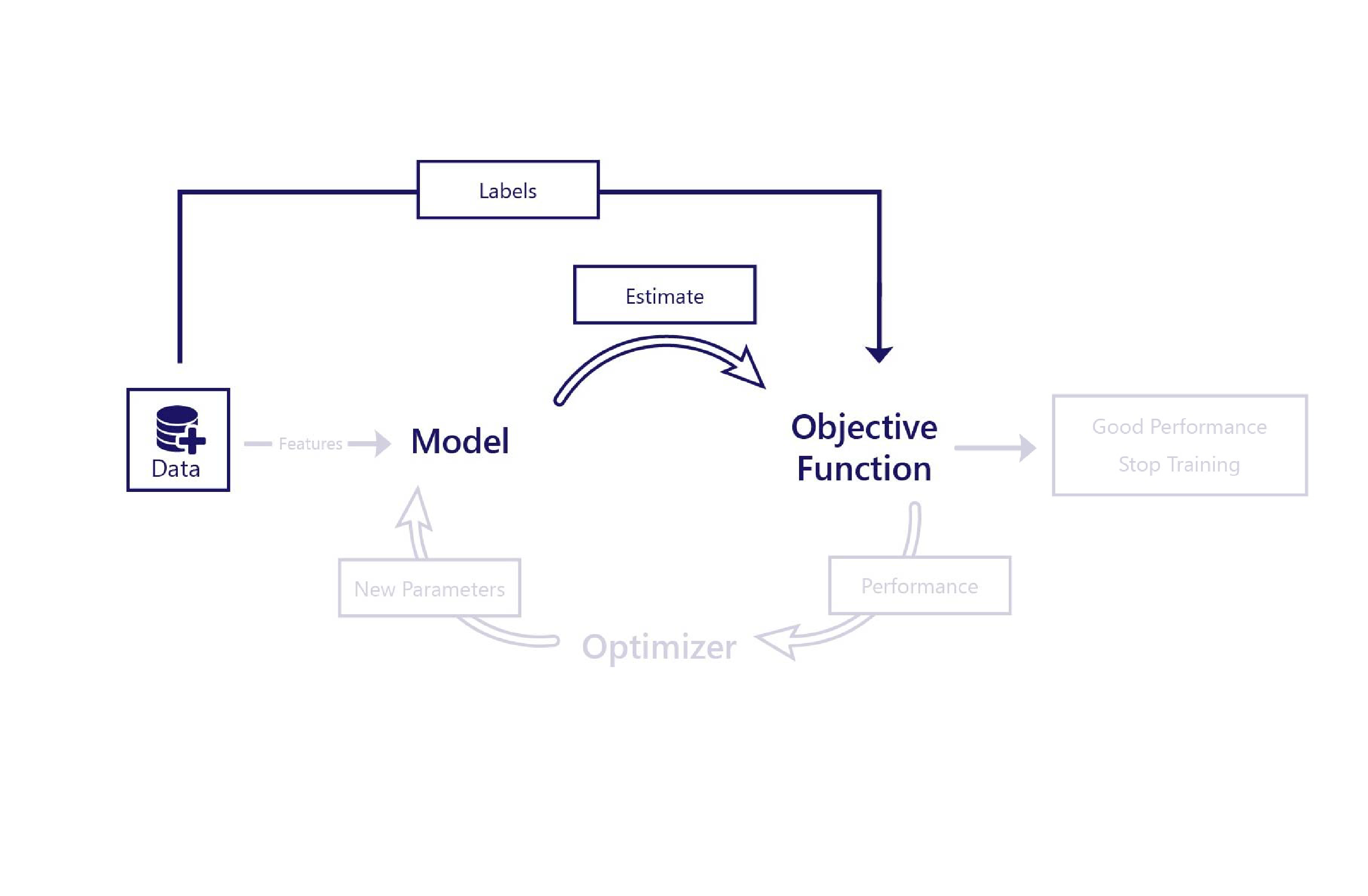
प्रशिक्षण के दौरान, विभिन्न लागत कार्य बदल सकते हैं कि प्रशिक्षण में कितना समय लगता है, या यह कितनी अच्छी तरह काम करता है। उदाहरण के लिए, यदि लागत फ़ंक्शन हमेशा बताता है कि त्रुटियां छोटी हैं, तो ऑप्टिमाइज़र मॉडल में केवल छोटे बदलाव करता है। एक अन्य उदाहरण के रूप में, यदि लागत फ़ंक्शन कुछ गलतियाँ होने पर बड़े मान लौटाता है। फिर, ऑप्टिमाइज़र मॉडल में बदलाव करता है, ताकि वह इस प्रकार की गलतियाँ न करे।
एक आकार-फिट-सभी लागत फ़ंक्शन नहीं है। कौन सा सबसे अच्छा है यह इस बात पर निर्भर करता है कि हम क्या हासिल करने की कोशिश कर रहे हैं। हमें अक्सर एक परिणाम प्राप्त करने के लिए लागत कार्यों के साथ प्रयोग करने की आवश्यकता होती है जिससे हम खुश हैं। अगले अभ्यास में, हम इस प्रयोग करेंगे.