Antipattern del database occupato
L'esecuzione del processo di offload in un server del database può causarne una perdita significativa di tempo nell'operazione di esecuzione del codice, invece che in quella di rispondere alle richieste per archiviare e recuperare i dati.
Descrizione del problema
Molti sistemi di database possono eseguire il codice. Alcuni esempi comprendono stored procedure e trigger. Spesso, è più efficiente eseguire questa elaborazione vicino ai dati, invece che trasmettere i dati a un'applicazione del client per l'elaborazione. Tuttavia, un uso eccessivo di queste funzionalità può danneggiare le prestazioni, per diversi motivi:
- Il server del database può impiegare troppo tempo per l'elaborazione, invece che accettare nuove richieste dei client e recuperare i dati.
- Un database è in genere una risorsa condivisa, pertanto può diventare un collo di bottiglia durante i periodi di utilizzo elevato.
- I costi di runtime possono essere eccessivi se l'archivio dati è a consumo. Ciò vale in particolar modo per i servizi dei database gestiti. Ad esempio, per Database SQL di Azure vengono addebitate le Unità di transazione di database (DTU).
- I database hanno una capacità limitata per la scalabilità verticale e non è facile ridimensionare orizzontalmente un database. Di conseguenza, potrebbe essere consigliabile spostare l'elaborazione in una risorsa di calcolo, ad esempio un'app della macchina virtuale o del servizio app, per cui è possibile aumentare facilmente il numero di istanze.
In genere questo antipattern si verifica perché:
- Il database viene visualizzato come un servizio piuttosto che come un repository. Un'applicazione può usare il server del database per formattare i dati (ad esempio, convertendoli in XML), per modificare i dati di tipo stringa o per eseguire calcoli complessi.
- Gli sviluppatori provano a scrivere query i cui risultati possano essere mostrati direttamente agli utenti. Una query potrebbe ad esempio combinare campi o formattare date, ore e valuta in base alle impostazioni locali.
- Gli sviluppatori stanno cercando di correggere l'antipattern di recupero estraneo trasferendo i calcoli al database.
- Stored procedure vengono usate per incapsulare la logica di business, probabilmente perché sono considerate più facili da gestire e aggiornare.
Nell'esempio seguente si recuperano i 20 ordini di maggior valore per un'area di vendita specifica e formatta i risultati nel formato XML. Usa le funzioni Transact-SQL per analizzare i dati e convertire i risultati in formato XML. L'esempio completo è disponibile qui.
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
Chiaramente, si tratta di query complesse. Come verrà visualizzato in un secondo momento, si passerà a usare le risorse di elaborazione significative nel server del database.
Come risolvere il problema
Spostare l'elaborazione dal server del database ad altri livelli di applicazione. Idealmente, è necessario limitare il database all'esecuzione delle operazioni di accesso ai dati, usando solo le funzionalità per cui il database è ottimizzato, ad esempio l'aggregazione in un sistema RDBMS.
Ad esempio, il codice Transact-SQL precedente può essere sostituito con un'istruzione che recupera semplicemente i dati da elaborare.
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
L'applicazione usa quindi le API di .NET Framework System.Xml.Linq per formattare i risultati in formato XML.
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
Nota
Questo codice è alquanto complesso. Per una nuova applicazione, è preferibile usare una libreria di serializzazione. Tuttavia, il presupposto è che il team di sviluppo esegua il refactoring di un'applicazione esistente, pertanto il metodo deve restituire lo stesso formato del codice originale.
Considerazioni
Molti sistemi di database sono altamente ottimizzati per eseguire determinati tipi di elaborazione dei dati, ad esempio calcolando i valori di aggregazione in grandi set di dati. Non spostare questi tipi di elaborazione fuori dal database.
Evitare di spostare l'elaborazione se ciò porta il database a trasferire molti più dati attraverso la rete. Vedere l'antipattern di recupero estraneo.
Se si sposta l'elaborazione in un livello di applicazione, potrebbe essere necessario aumentare il numero di istanze per tale livello per gestire il lavoro aggiuntivo.
Come rilevare il problema
I sintomi di un database occupato comprendono una diminuzione sproporzionata dei tempi di risposta e della velocità effettiva nelle operazioni che accedono al database.
Per provare a identificare questo problema è possibile eseguire la procedura seguente:
Usare il monitoraggio delle prestazioni per identificare quanto tempo impiega il sistema di produzione per eseguire l'attività del database.
Esaminare il lavoro eseguito dal database durante tali periodi.
Se si ritiene che delle operazioni particolari potrebbero portare una quantità eccessiva attività nel database, eseguire un test di carico in un ambiente controllato. Ogni test deve eseguire una combinazione delle operazioni sospette con un carico utente variabile. Esaminare i dati di telemetria dal test di carico per osservare come viene usato il database.
Se l'attività del database rivela un'elaborazione significativa ma un traffico di dati minimo, esaminare il codice sorgente per determinare se è possibile ottimizzare l'elaborazione eseguita altrove.
Se il volume dell'attività del database è insufficiente o i tempi di risposta sono relativamente veloci, allora un database occupato non è dovuto a un problema nelle prestazioni.
Diagnosi di esempio
Le sezioni seguenti applicano questa procedura all'applicazione di esempio descritta in precedenza.
Monitorare il volume dell'attività del database
Il grafico seguente mostra i risultati dell'esecuzione di un test di carico rispetto all'applicazione di esempio, usando un carico del passaggio per un massimo di 50 utenti simultanei. Il volume di richieste raggiunge rapidamente un limite e rimane su quel livello, mentre il tempo medio di risposta viene incrementato costantemente. Per queste due metriche viene usata una scala logaritmica.
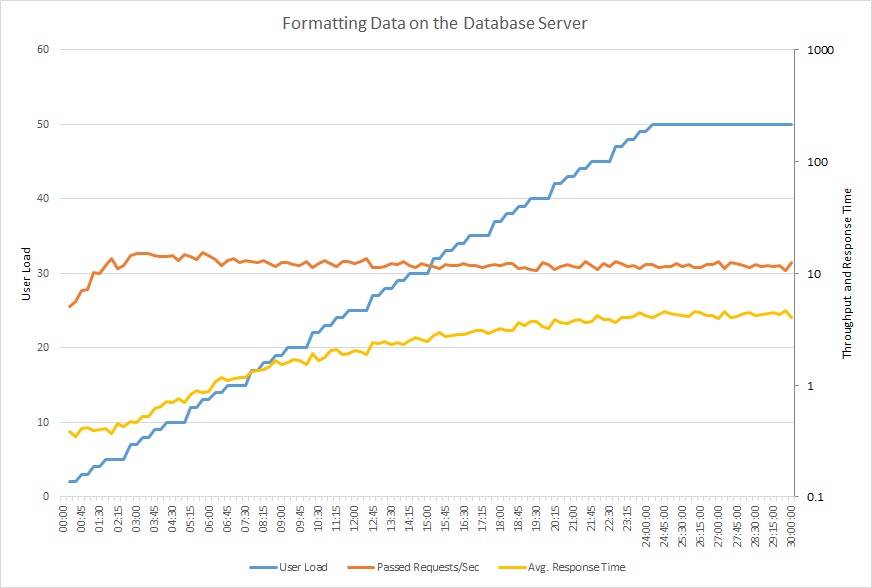
Questo grafico a linee mostra il carico utente, le richieste al secondo e il tempo medio di risposta. Il grafico mostra che il tempo di risposta aumenta con l'aumento del carico.
Il grafico successivo mostra l'utilizzo della CPU e delle DTU come percentuale delle quote del servizio. Le DTU forniscono una misura delle prestazioni dell'elaborazione del database. Il grafico mostra che sia l'uso della CPU sia quello della DTU raggiungono rapidamente il 100%.
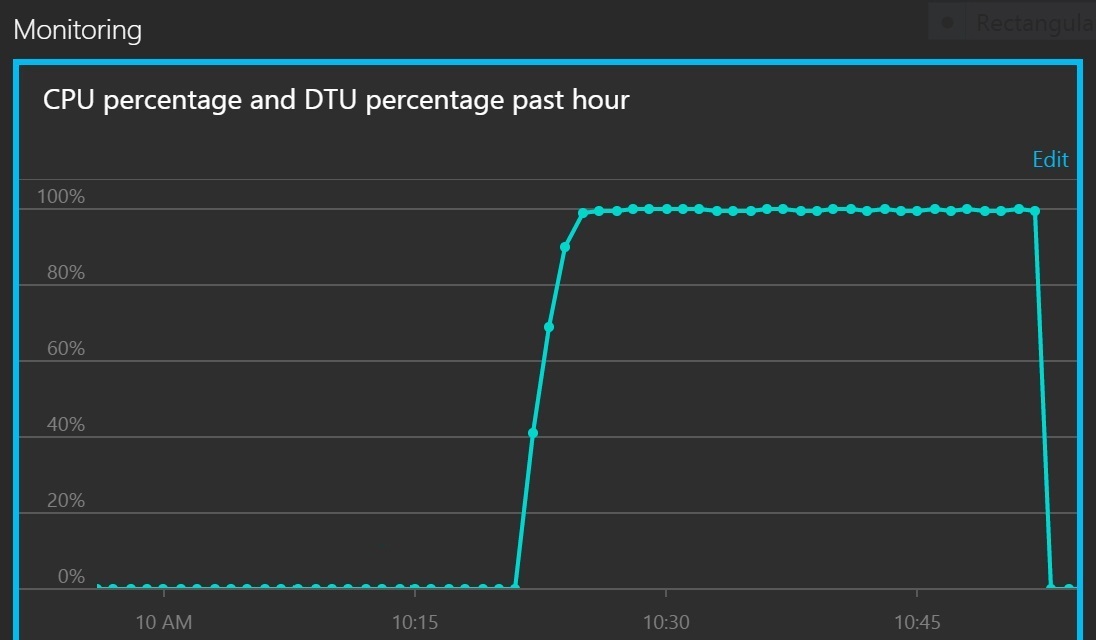
Questo grafico a linee mostra la percentuale CPU e la percentuale DTU nel corso del tempo. Il grafico mostra che entrambe le percentuali raggiungono rapidamente il 100%.
Esaminare il lavoro eseguito dal database
È possibile che le attività eseguite dal database siano vere operazioni di accesso ai dati, piuttosto che elaborazioni, pertanto è importante comprendere le istruzioni SQL in esecuzione mentre il database è occupato. Monitorare il sistema per acquisire il traffico SQL e correlare le operazioni SQL con le richieste dell'applicazione.
Se le operazioni del database sono esclusivamente operazioni di accesso ai dati, senza numerose attività di elaborazione, allora il problema potrebbe essere il Recupero estraneo.
Implementare la soluzione e verificare il risultato
Il grafico seguente mostra un test di carico tramite il codice aggiornato. La velocità effettiva è significativamente più elevata, oltre 400 richieste al secondo rispetto alle 12 precedenti. Il tempo di risposta medio è di molto inferiore, appena sopra gli 0,1 secondi rispetto ai più di 4 secondi.
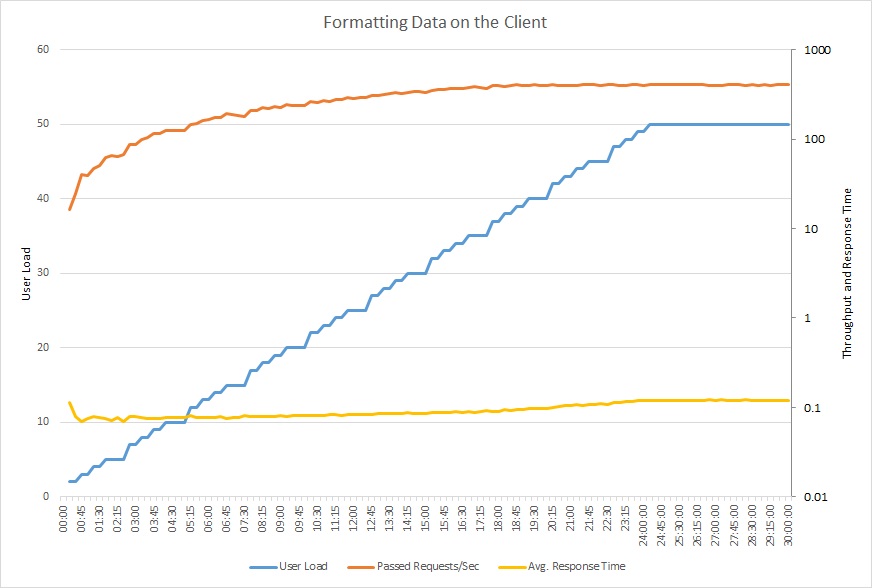
Questo grafico a linee mostra il carico utente, le richieste al secondo e il tempo medio di risposta. Il grafico mostra che il tempo di risposta rimane approssimativamente costante durante l'intero test di carico.
L'utilizzo della CPU e della DTU mostra che il sistema ha impiegato più tempo per raggiungere la saturazione, nonostante l'aumento della velocità.
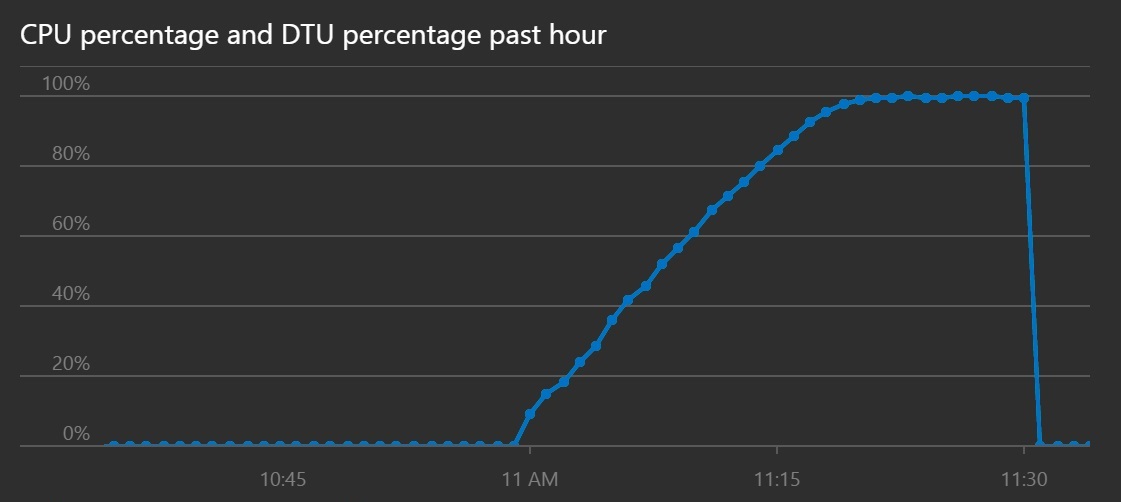
Questo grafico a linee mostra la percentuale CPU e la percentuale DTU nel corso del tempo. Il grafico mostra che entrambe e percentuali impiegano più tempo per raggiungere il 100% rispetto a prima.
Risorse correlate
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per